
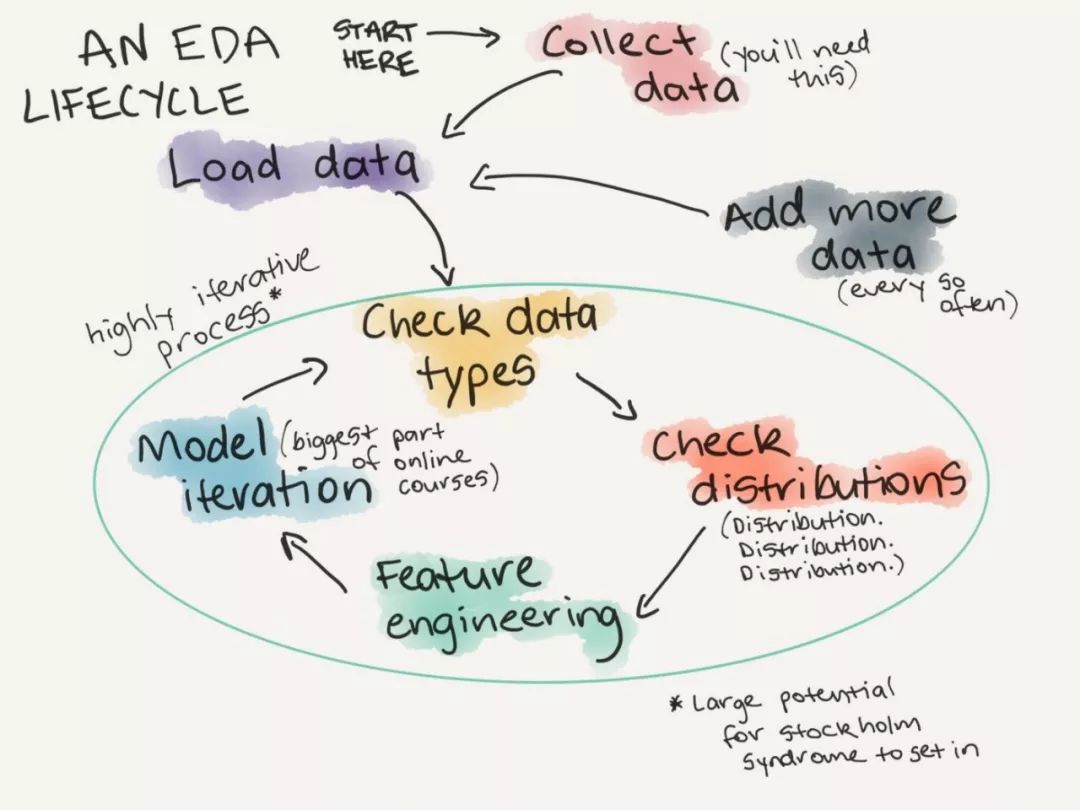
1 请重视你的数据
全方位了解你的数据,从数据的获取,到载入和编码,以及如何迭代的获取数据,之后去确认数据类型、数据分布,到进行特征提取。我们往往对如何构建一个好的模型关注更多,却忽视了对数据本身的校验和分析,先了解待处理数据本身的特点和背景知识,能够为你节省时间。
2 及时沟通很重要
不要憋大招式的沟通,要及时和团队成员以及相关客户跟进进展。每次将要沟通的事件限制在3-4点,讲清楚自己做了什么,为什么要这么做,以及基于当下的进展,接下来要做什么。
3 选择效果稳定的,而不是最新最热的模型
4 仅仅教科书上的知识是不够
AI的实践不只终止于训练出一个效果不错的模型,还涉及到如何将模型部署,如何让更多人方便得使用。机器学习工程师作为当今万金油的职业,不仅需要懂机器学习,还需要熟悉所应用行业的背景知识,了解收集到的数据特性。
5 花20%的时间学习新事物,80%的时间做核心项目
6 不要盲目追逐新技术
每10篇讲述新技术的论文,只有一篇会被阅读,而真正被用到的就更少了。每年看似那么多革命性的新技术,但大多只来自几个公司,几个实验室。与其盲目追逐新技术、新模型,不如打好基础,深刻理解核心的概念及原理,并灵活的对其加以应用。
7 对自己的结果时刻保持怀疑和批判的态度
当你面对的选择,是尝试新的技术或对当前已有的技能加以利用时,可以通过质疑自己的结果来帮助你选择。
当你用熟悉的模型得出不错的结果,并将其汇报给客户时,你要反复检查结果的正确性,并确保模型在任何时候都能用,即没有出现数据泄漏。而当你去尝试不熟悉的方法来改进模型时,你就是在探索了。合理的时间分配是,7:2:1,即花70%的时间用熟悉的工具完成核心项目,20%的时间改进模型,10%的时间去尝试一些不太可能成功,但可能收益很大的方法。
8 先构建一个可行的toy model,在简化的环境下论证其可行性
9 当遇到问题时,试着和你的同事去解释该问题的前因后果
10 不要从头构建模型
除了极少数特殊的场景,机器学习做的不外乎分类、回归、时间序列的预测、推荐等。尽可能使用成熟的框架和工具,使用自动化的流程,例如autoML,从前人已经训练好的模型开始,而不要重新造轮子。从头开始,100%自己构建的模型,大多数情况远不如成熟工具效果好。
11 编码能力优于数学
只需要了解基础的线性代数、微积分,大多数模型你便会明白。成熟的框架会将数学计算隐藏起来。对于机器学习工程师,提升编码能力的优先级高于学好数学。
12 前一年的工作经验对于下一年基本为0
机器学习的进展特别快,新的包和框架层出不穷。不要抱着自己固有的工作经验不放,不变的唯有统计概率的基础知识和理解。
本文部分译自medium,译者Peter。原文链接https://towardsdatascience.com/12-things-i-learned-during-my-first-year-as-a-machine-learning-engineer-2991573a9195。











