作者:林晓胜
本文转自公众号:猪栏守望者
在昨天的盛大party后,《乐队的夏天》终于顺利收官。这个燃爆了整个夏天的综艺是否是今年最火的综艺节目虽然不得而知,但是不可否认,将乐队和摇滚又重新带到了公众面前。
至少对于我,很感谢有这么一个节目,可以让我接触到不同类型的音乐,认识这么多优秀的乐队,知道坚持做自己喜欢的事是一件多么幸福的事。

在昨天的终结篇中,马东根据现场的投票,顺利颁发出了杀出重围的5只最高票乐队。
当然,每个人心中一定都有一只自己觉得最强的乐队,我也一样。所以,我决定爬取所有场次参赛歌曲的投票数据,用python进行一次分析。然后参考数据分析的结果,给出我心目中,或许更加公允的另外一份Hot5名单。

当然,我也希望这份分析结果能够解答我自己对于乐队的夏天的一些疑问,比如,痛仰乐队的我愿意为何表现不佳?一直被专业乐迷和其他乐队奉为偶像的海龟先生,为什么最终止步5强?
还有一些有趣的小结论,一起看看吧!
数据分析数据分析,没有数据就没有分析。
网络上没有公开的详细得票、排名数据,只好自己整理了。首先购买爱奇艺会员,不然很长时间都消耗在广告上了。然后用2倍速播放(这么听歌还挺带感的),然后看到这一幕,按住锁屏和音量键+,咔嚓,数据收集到了!

最后手机相册就变成现在这样👇

最后再填到一个Excel表里面,数据就有啦!
它大概长这个样子👇
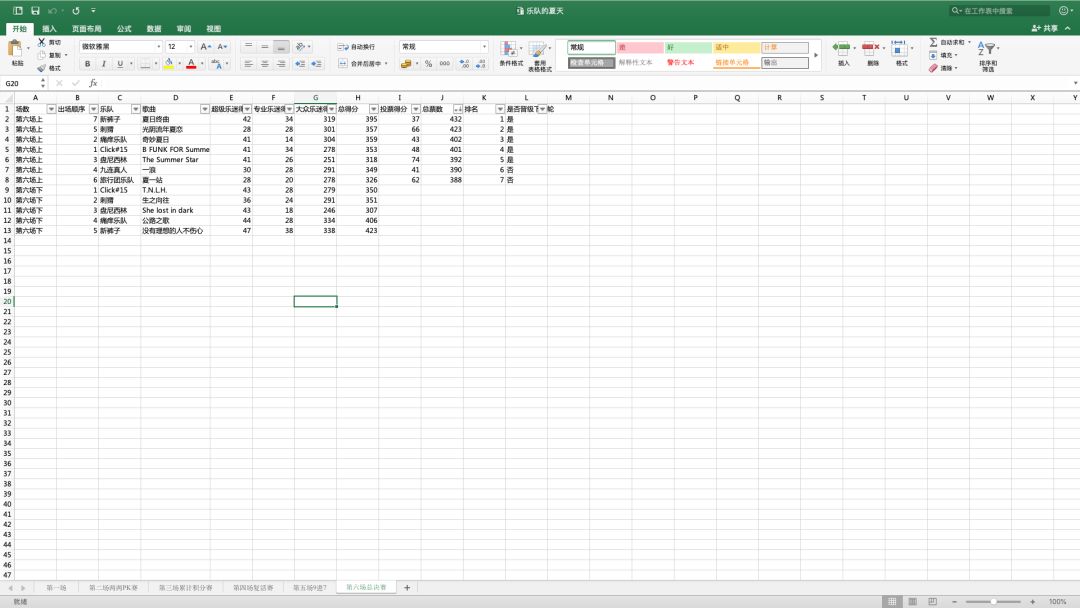
一共有6个sheet,对应6场比赛,字段分别是:[场数, 出场顺序, 乐队, 歌曲, 超级乐迷得分, 专业乐迷得分, 大众乐迷得分, 总得分, 排名, 是否晋级下一轮]
在读取数据之前,先导入分析的工具包
import pandas as pdimport numpy as npimport matplotlib.pyplot as plt
为了显得有一点点审美,我用取色器取了乐队的夏天主KV上面的颜色,便于后面可视化来使用。

# 配置乐队的夏天主题色purple = (0.22,0.09,0.59)
环境设置完了,第一步是导入数据
# 读取数据data1 = pd.read_excel('/.../乐队的夏天.xlsx','第一场')data2 = pd.read_excel('/.../乐队的夏天.xlsx','第二场两两PK赛')data3 = pd.read_excel('/.../乐队的夏天.xlsx','第三场累计积分赛')data4 = pd.read_excel('/.../乐队的夏天.xlsx','第四场复活赛')data5 = pd.read_excel('/.../乐队的夏天.xlsx','第五场9进7')data6 = pd.read_excel('/.../乐队的夏天.xlsx','第六场总决赛')
观察一下数据吧。
# 观察数据data1.info()data1.head()

以第一场的数据为例为例,可以看到字段和数据的行数,其中得分有(31-27=4)行数据为空,进入第三步。
竟然有空数据,先看看是怎么回事。

# 可以看到有四只乐队是没有得分和排名的,把他们列出来
data1[data1['总得分'].isnull()]
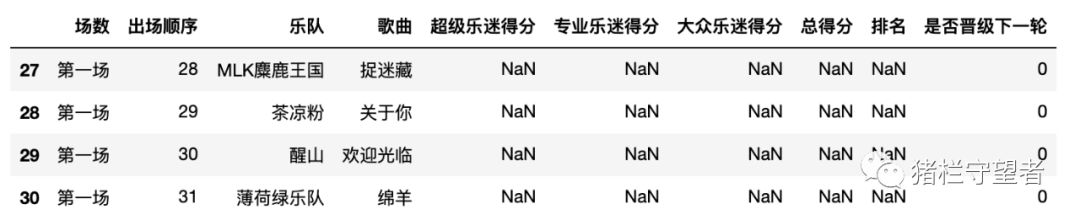
所以其实是有31只乐队表演的,但这四只乐队因为被剪掉了,所以没有具体成绩的数据,怎么办呢,只好把你们删了。
data1 = data1.dropna(axis = 0)
此外第六场的总票数还没有给出,也有一部分空值,但不影响分析这样就完成了,因为数据是自己手动录入的,所以其它没什么问题了,可以开始分析了。
整体的分析思路遵循从整体到局部的顺序,分为乐队和歌曲两个部分,再细分超级乐迷,专业乐迷和大众乐迷三个角度。同时会展示乐队在每期比赛的排名升降情况。

另外由于每场比赛的总票数不同,不同评委票数比例不同,为了使得不同场次之间的得票数据具备可比性,需要用到两种数据标准化的方法,分别是:
Z_score 标准分
0-1 normalization 归一分
Z_score标准分的计算方法是用“(该乐队当场得分-当场所有乐队得分的平均数)/ 当场所有乐队得分的标准差”计算得到:
# 标准分函数定义def z_score_normalize(series): mean = series.mean() std_dv = series.std() return series.apply(lambda x:(x - mean) / std_dv) competition = [data1,data2,data3,data4,data5,data6]for period in competition: period['超级乐迷得分_标准分'] = z_score_normalize(period['超级乐迷得分']) period['专业乐迷得分_标准分'] = z_score_normalize(period['专业乐迷得分']) period['大众乐迷得分_标准分'
] = z_score_normalize(period['大众乐迷得分']) period['总得分_标准分'] = z_score_normalize(period['总得分'])
0-1 normalization 归一分的计算方法是用“乐队得票数/总票数”计算得到,也等于常说的得票率:
# 定义归一化的函数def normalize(series,x_max): return series.apply(lambda x: x/x_max)for data in [data1,data2,data5,data6]: data['超级乐迷_归一分'] = normalize(data['超级乐迷得分'],50)data3['超级乐迷_归一分'] = normalize(data3['超级乐迷得分'],60)data4['超级乐迷_归一分'] = normalize(data4['超级乐迷得分'],40)for data in [data1,data2,data3,data4,data5,data6]: data['专业乐迷_归一分'] = normalize(data['专业乐迷得分'],40) for data in [data1,data2]: data['大众乐迷_归一分'] = normalize(data['大众乐迷得分'],100)for data in [data3,data4,data5,data6]: data['大众乐迷_归一分'] = normalize(data['大众乐迷得分'],360)
做完上面两步,再把每场的数据拼成一个表,大功告成。(此处省略拼接代码)


首先我们分析乐队,通过27只乐队在目前5场比赛中所表演的曲目的总得分的标准分的平均分,来衡量乐队的整体表现。
这个数据首先反映乐队的歌在该场比赛中的表现,其次结合多场比赛歌曲的表现,体现乐队的整体成绩。
# 按照乐队这个标签分类计算,计算方式是平均值,计算字段是总得分_标准分,然后按照总得分_标准分排列total_score_mean = total_score.groupby(['乐队'])[['总得分_标准分']].mean().sort_values( by = '总得分_标准分',ascending = False)total_score_mean

贴一部分成绩出来
然后把这个结果可视化看看。
# 对乐队总得分_标准分做可视化y = np.arange(len(total_score_mean.index))x = np.array(list(total_score_mean['总得分_标准分']))fig,ax = plt.subplots(figsize = (12,12))
total_score_mean.plot.barh(ax=ax,alpha=0.7,title='27只乐队场均表现',color = 'g')for a,b in zip(x,y): plt.text(a, b, '%.2f' % a, ha='center', va= 'center',fontsize=12)ax.grid(False)
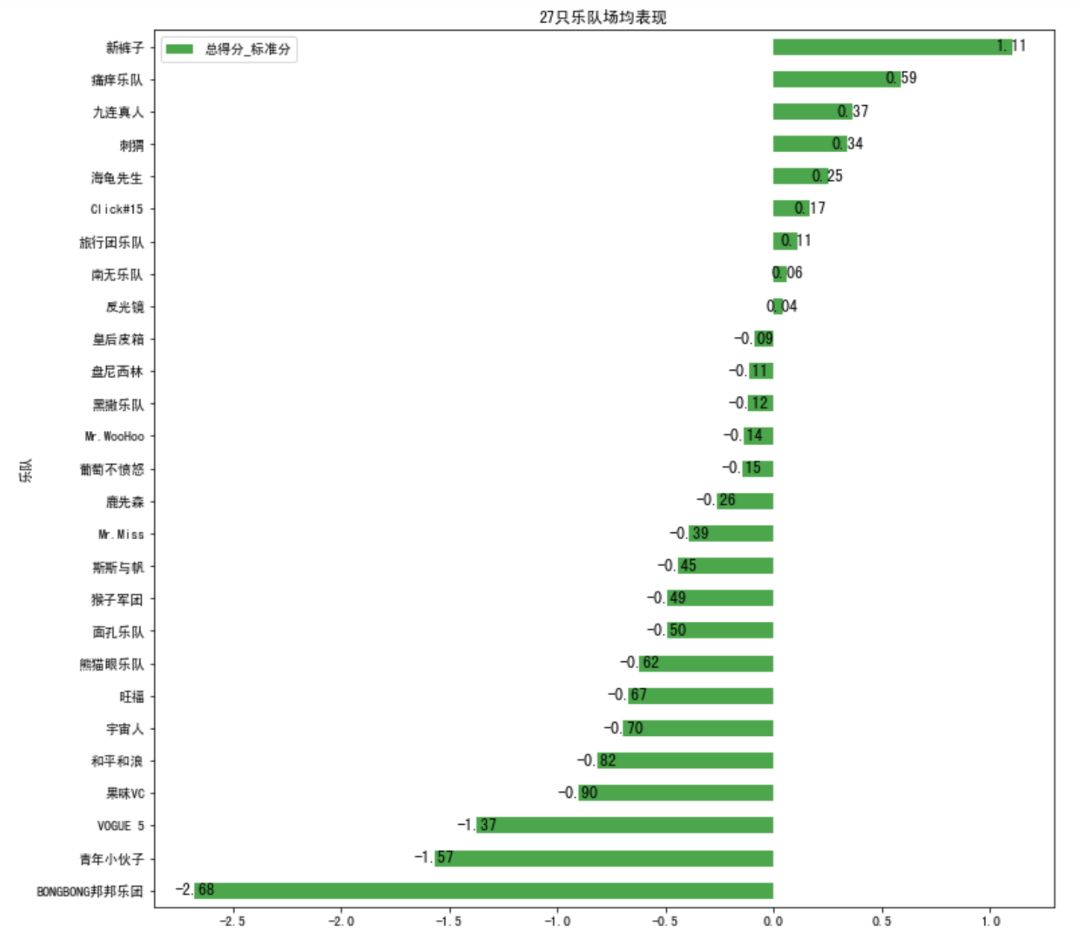
新裤子排名第一,这也是在意料之中,“生命因你而火热”,“花火”这几首歌在朋友圈都爆了,其他的像刺猬、九连真人、盘尼西林、旅行团、Click#15都表现很稳定,在目前的晋级名单中。但有两支乐队比较奇怪,一个是一度被淘汰的痛仰乐队,竟然排在第二,另一个是一直在线,还把痛仰PK掉的面孔,排名甚至不在前10。

# 把痛仰的成绩拉出来看一下 total_score[total_score['乐队'] == '痛仰乐队']
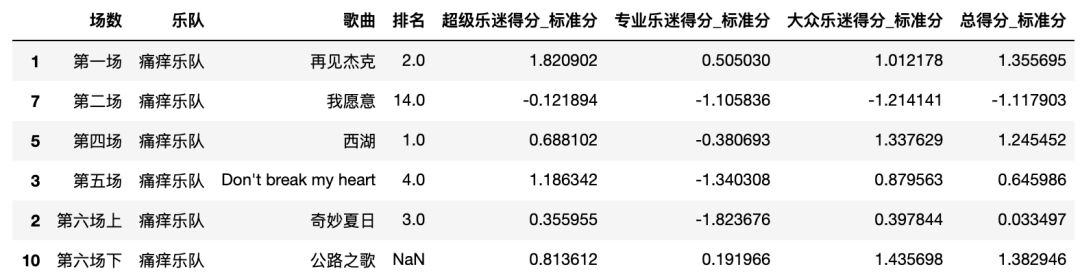
“再见杰克”和“西湖”都在当轮比赛中取得非常突出的表现,但“我愿意”真的可惜了。
total_score[total_score['乐队'] == '面孔乐队']
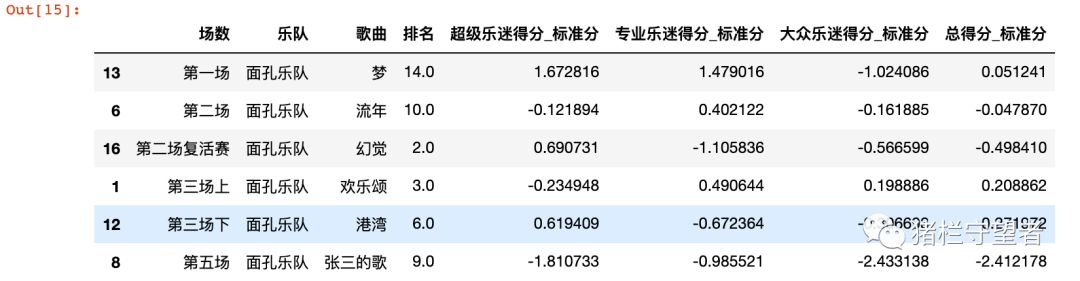
较于其他只表演了一场但排名中等的队伍,面孔因被“张三的歌”垫底,一举拖垮,也因此惨遭淘汰。
接下来我想研究,在超级乐迷、专业乐迷和大众乐迷各自眼里,哪些乐队是他们喜欢的,他们共同喜欢的,和差异很大的乐队分别是哪些?
# 代码逻辑和前面选总得分作为计算字段的逻辑一样,只不过这次选取单个群体得分作为指标super_score_mean = total_score.groupby(['乐队'])[['超级乐迷得分_标准分']].mean().sort_values( by = '超级乐迷得分_标准分')pro_score_mean = total_score.groupby(['乐队'])[['专业乐迷得分_标准分']].mean().sort_values( by = '专业乐迷得分_标准分')public_score_mean = total_score.groupby(['乐队'])[['大众乐迷得分_标准分']].mean().sort_values( by = '大众乐迷得分_标准分')
对前5的乐队进行数据可视化。
fig,ax = plt.subplots(1,3,figsize = (16,6))super_score_mean.tail(5).plot.barh(ax=ax[0],color = '#dc2624',alpha=0.7,title='超级乐迷心中TOP5',grid=False)pro_score_mean.tail(5).plot.barh(ax=ax[1],color = '#2b4750',alpha=0.7,title='专业乐迷心中TOP5',grid=False)public_score_mean.tail(5).plot.barh(ax=ax[2],color = '#649E7D',alpha=0.7,title='大众乐迷心中TOP5',grid=False)
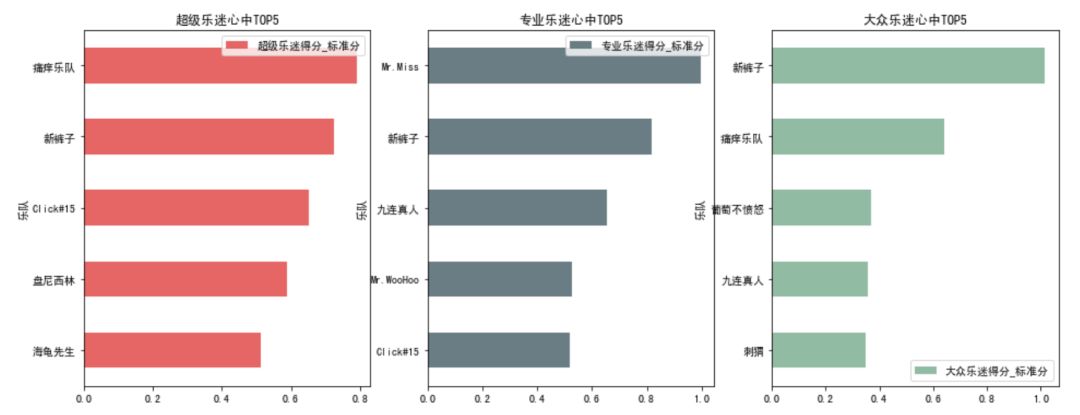
同时在三个群体中位列心目前五的乐队是:“新裤子”。
下面一起来读绕口令:
在超级乐迷心中前五,但不在专业乐迷心中的前五乐队是:
{'海龟先生', '盘尼西林', '痛仰乐队'}
在超级乐迷心中前五,但不在大众乐迷心中的前五乐队是:
{'Click#15', '海龟先生', '盘尼西林'}
在专业乐迷心中前五,但不在超级乐迷心中的前五乐队是:
{'Mr.WooHoo', 'Mr.Miss', '九连真人'}
在专业乐迷心中前五,但不在大众乐迷心中的前五乐队是:
{'Mr.WooHoo', 'Mr.Miss', 'Click#15'}
在大众乐迷心中前五,但不在超级乐迷心中的前五乐队是:
{'九连真人', '葡萄不愤怒', '刺猬'}
在大众乐迷心中前五,但不在专业乐迷心中的前五乐队是:
{'刺猬', '葡萄不愤怒', '痛仰乐队'}
PART II :乐队的排名就像人生,它会起起落落落落落
接下来对比较熟悉的9只乐队的每期排名做可视化,直观地展现他们在每期表现的升降。

新裤子的发挥是较为稳定的,除了第三场上和Cindy合作的音乐形式较为新颖,让观众一时难以接受之外,在各个场次都获得非常靠前的成绩。同样稳定的还有九连真人,一直稳稳的在中间,此外第二场改编李宗盛大哥的凡人歌,现场炸裂,表现超出期待。
表现越来越好的有两只乐队:刺猬和Click#15
刺猬可谓是低开高走,复活赛中凭借白日梦蓝稳稳防守住黑撒乐队的挑战,女神赛中和斯斯与帆的合作更是获得了全场最佳。Click#15虽然在第二场和面孔的PK赛中被淘汰,但又杀了回来,而且第五场演绎beyond的碑面派对,首次赢得第一名。
另外面孔乐队的处境一直比较尴尬,看他们的音乐对这一代人确实存在一些隔阂。
最后还有我很喜欢的乐队,海龟先生。第一场比赛在31只乐队中位列第一,后面他们做了许多创意,还有想通过音乐表达自己的想法,可惜没有被buy in.
对乐队的分析暂时告一段落,接下来看看歌曲。
PART III :如果你只有十首歌的时间,我建议你听这些歌
通过前面提到的归一化计算,可以得到一下数据

首先对数据整体有一个把握
# 看看数据整体的描述total_nor_score.describe()# 运用箱型图可以看到各组给分的分布,其中蓝线是平均分,圆圈是最小值fig,ax = plt.subplots(1,1,figsize = (8,4))total_nor_score.boxplot(ax = ax,grid=False)
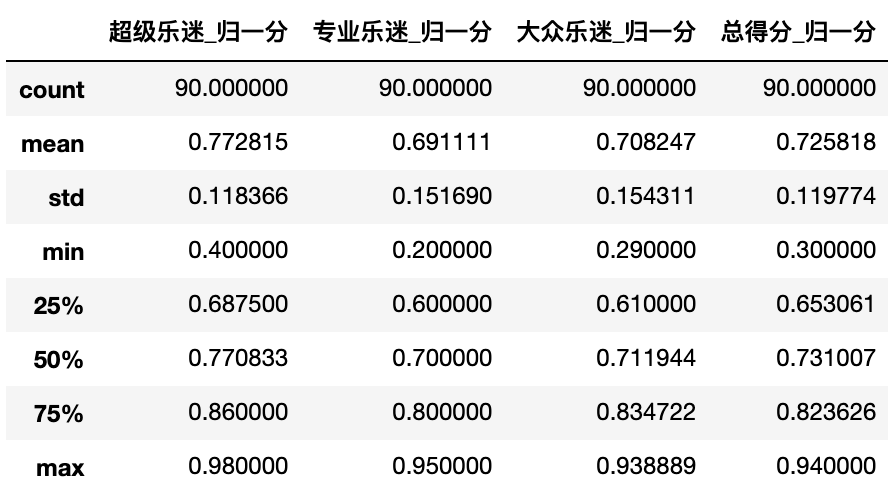
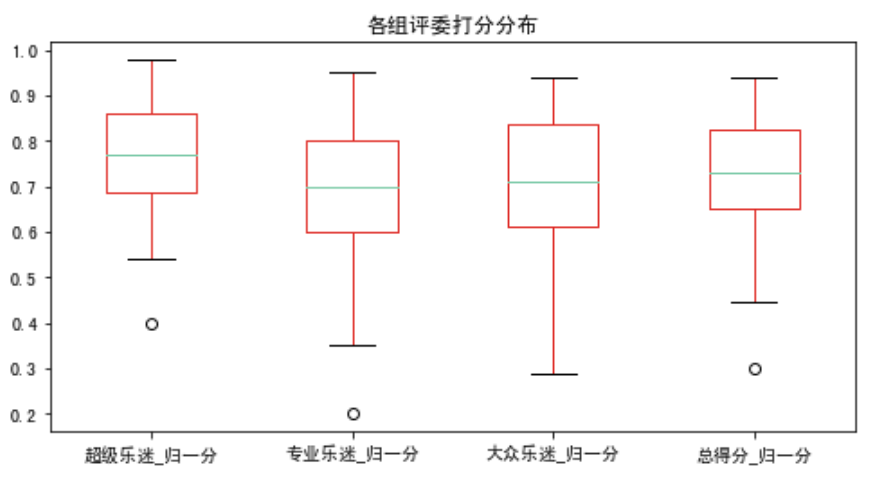
从上面的图和数据不难看出,超级乐迷给分的范围相对较高,也就是所谓的手松,而专业乐迷擅长给低分,最低的时候只给出了20%比例的票,大众乐迷相对克制,最高分也仅仅给出了93%的票,所谓的众口难调。总得分的平均数是0.72,意味着所有歌曲平均下来能拿到72%的票,也是挺不容易的。
再来看看,得票率前10的歌曲吧!
top10_songs = total_nor_score.sort_values(by = '总得分_归一分').tail(10)top10_songs.plot.barh(x='歌曲',y='总得分_归一分',color=purple)print('截止第六期,最受欢迎的10首歌分别是:\n',list(top10_songs['歌曲']))
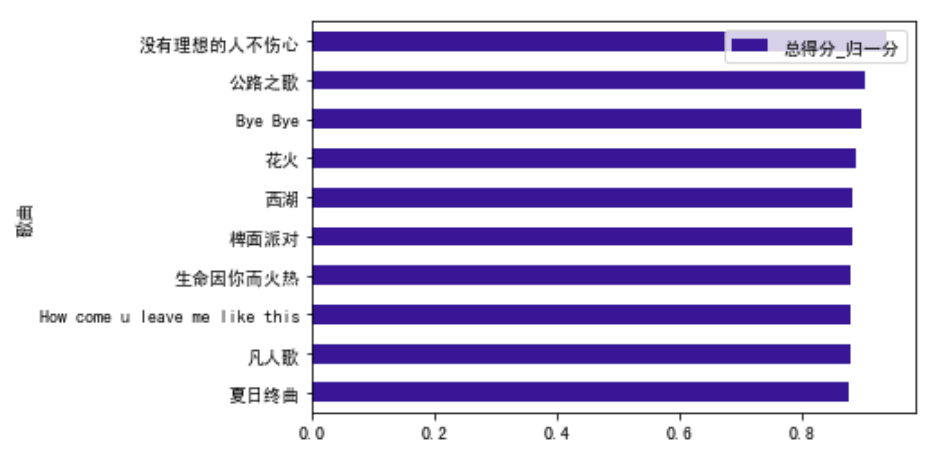
截止第六期,最受欢迎的10首歌分别是:
下面看看在每组评委心目中前10的歌曲:
total_nor_score.sort_values(by = '超级乐迷_归一分').tail(10).plot.barh(x='歌曲',y='超级乐迷_归一分',color=red)total_nor_score.sort_values(by = '专业乐迷_归一分').tail(10).plot.barh(x='歌曲',y='专业乐迷_归一分',color=yellow)
total_nor_score.sort_values(by = '大众乐迷_归一分').tail(10).plot.barh(x='歌曲',y='大众乐迷_归一分',color=green)
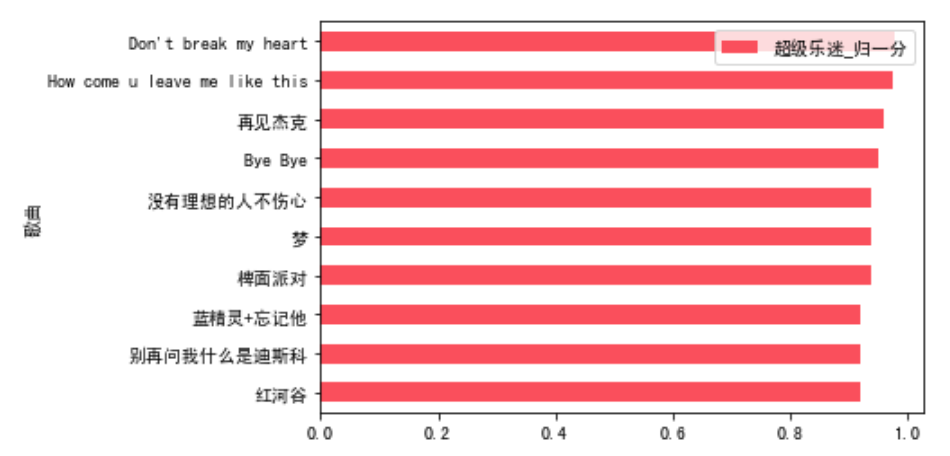
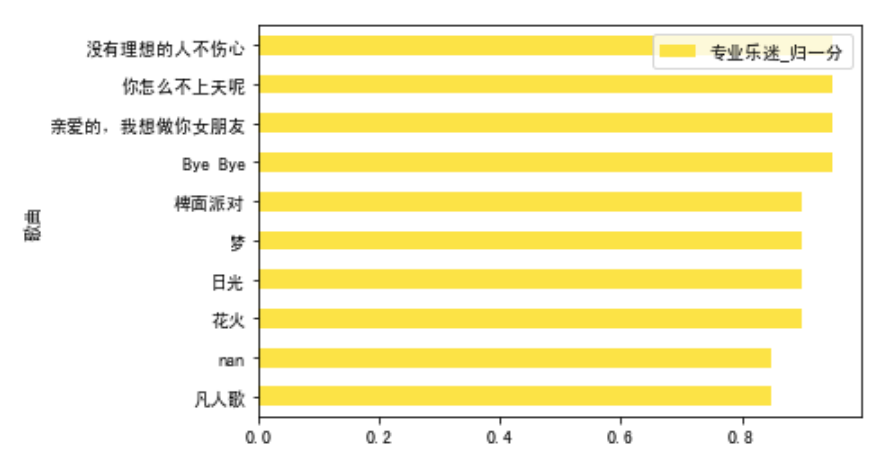
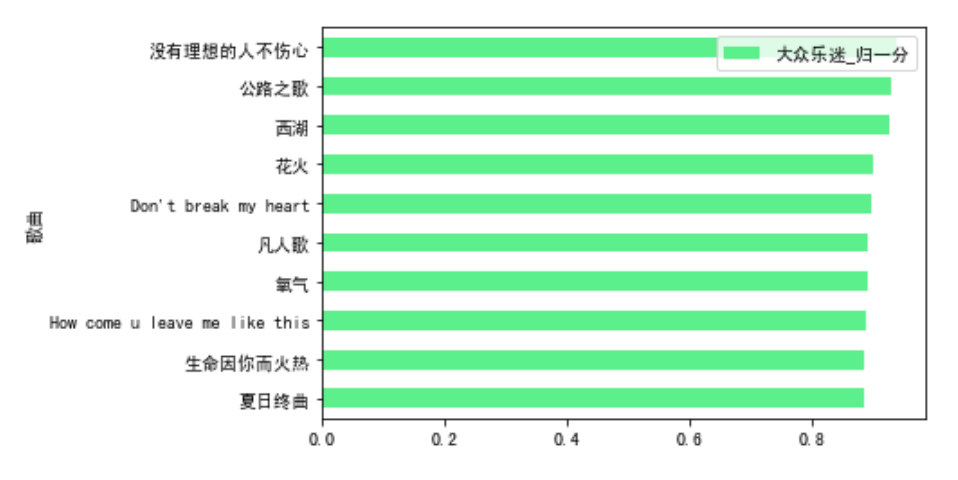
超级乐迷最喜欢“Don't break my heart”,专业乐迷和大众乐迷最喜欢“没有理想的人不伤心”。
PART IIII:灵魂拷问:“我愿意”为什么跳水?谁在不喜欢海龟先生?
整体回顾完了,最后单独分析两个问题。第一个是为什么“我愿意”这首歌表现不好呢?
total_nor_score[total_nor_score['歌曲'] == '我愿意']

可以看到虽然在节目中,矛头似乎指向了专业乐迷,但实际上,专业乐迷给票的比例比大众乐迷是要高的,真正不喜欢的是大众乐迷,只给出了一半的票数。

第二个问题是,谁在不喜欢海龟先生?

total_nor_score_t = pd.merge(total_nor_score, total_score[['乐队','歌曲']], on='歌曲')total_nor_score_t[total_nor_score_t['乐队'] == '海龟先生']
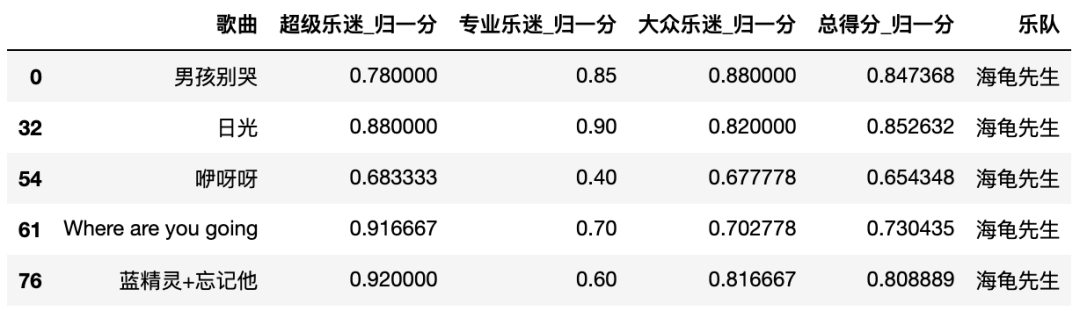
“咿呀呀”这首歌拖累了海龟的整体平均分,而在这首歌中,专业乐迷给票的比例是最低的。
看看每组分别对海龟先生的作品给出的平均分:
total_nor_score_t[total_nor_score_t['乐队'] == '海龟先生'].mean()超级乐迷_归一分 0.836000
专业乐迷_归一分 0.690000
大众乐迷_归一分 0.779444
总得分_归一分 0.778734
可以看到是专业乐迷,所以李红旗啊,如果专业乐迷们说什么喜欢你们,你们千万不要相信。
PART IV:不要情感,拒绝同情票,我只想告诉你真相
最后,我说出我心目中真正的Hot5,感谢你坚持看到这里!

第六期也就是决赛的这一期,临时增加了一轮投票环节,在歌手演出结束后,一人一票,投出你喜欢的乐队。两轮票数相加得到总票数,前五名的留下。
最终成绩如下:
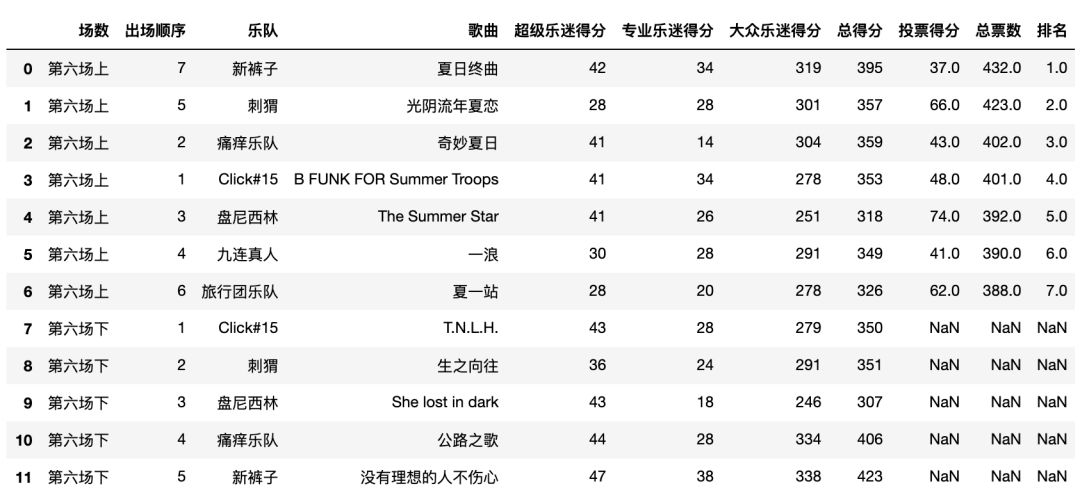
新的规则带来很大的争议,有人会给出“同情票”,使得真正的排名不能体现乐队的实力。
因此,我心目中的Hot5应该是结合每场每首歌的成绩,不考虑作品以外单独的投票的干扰来评判。因此选用前面提到的标准分的方法来计算最后决赛夜的7只乐队全部六场成绩,得到最终的排名。
# 选中7只队伍final_7 = ['新裤子','痛仰乐队','九连真人','Click#15','刺猬','盘尼西林','旅行团乐队']# 分别计算标准分final_7_total_score = total_score_mean.loc[final_7,].sort_values(by='总得分_标准分')# 可视化fig,ax = plt.subplots(1,1,figsize = (10,20))final_7_total_score.plot.barh(ax=ax,color = yellow,alpha=0.7,title='我心中Hot5',grid=False)
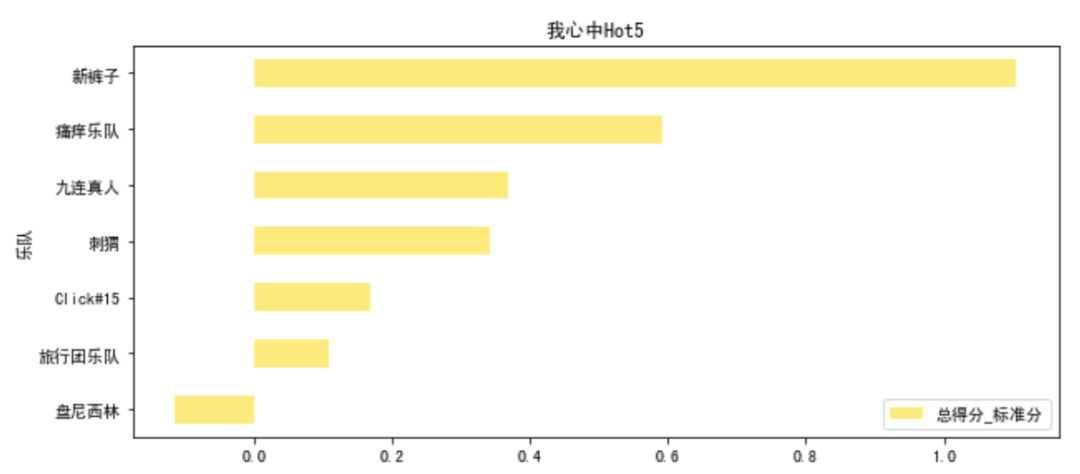
从这个结果来看,其实盘尼西林是排在最后一位的,但因为增加了投票而被捞了回来。赛制的改变,使得结果有人欢喜有人愁。
但不管结局,排名,还是很高兴,这个夏天遇见这么多好听的音乐,同时也用数据更好的察觉一些真相。

点击文末阅读原文可以前往github获取完整代码
后台回复“乐队”获得数据源









