作者 | 周岩,夕小瑶,霍华德,留德华叫兽
本文经授权转自公众号:运筹OR帷幄
导读:随着计算机行业的发展,人工智能和数据科学近几年成为了学术和工业界关注的热点。特别是这些年人工智能的发展日新月异,每天都有新的模型和算法在发布。那么无论多么眼花缭乱的算法,最后落到实处还是需要合适的数据集做支撑。数据是否合适可以直接影响一个算法的效果,对于专门做算法研究的同学,可能更多的选择公认的 benchmark 来测试算法,如 MINST、ImageNet 等。而对于做特定领域问题研究的同学更需要特定场景或者条件下的数据集,如工业过程数据、NLP、推荐系统等,那么这时更好的办法可能是自建一些数据集来验证自己的研究。
针对以上的问题,本篇文章就如何选择适合自己算法的数据集以及如何创建机器学习数据集作一些讨论,希望能为各位同学提供帮助。
1 如何选择数据集并做合理预处理
1.1 数据集的选择
数据是人工智能算法发展的基础,“没有免费的午餐”是学界公认的道理,任何算法都不能脱离数据或者应用场景来谈效果的好坏。对于做算法的小伙伴来说,虽然在研究算法的创新,但是如何选择和利用数据集是研究的基础,再优秀的算法也要通过数据来评估它的效果。算法的最终目的是要拟合这种趋势或者分布,不同的数据集的特征分布是不同的,甚至同一个数据集划分方式和比例的不同都也会使得特征的分布存在差异,因此找到合适的数据并做好适当的预处理,可以更加体现算法的能力,使得研究更具说服力。
目前机器学习的数据集种类包含图像数据,时序数据,离散数据等,而不同数据集对应的任务可以分类、回归或者两者兼顾。那么我们在研究过程中选择数据集除了一些如 MNIST 等经典数据集外,还需要根据自身模型特点选择具有相应特征的数据。
另外,数据集的大小也是需要考虑的一个因素。一般来讲,一些经典的早期的数据集包含的数据量都比较少,更适合小规模的模型。而近年来随着算力的增强和大数据技术的普及,近年的数据集普遍会包含更多的数据,大规模数据集所包含的数据加全面,模型训练的效果会更好,但是同样在训练中也会相对更加耗时。
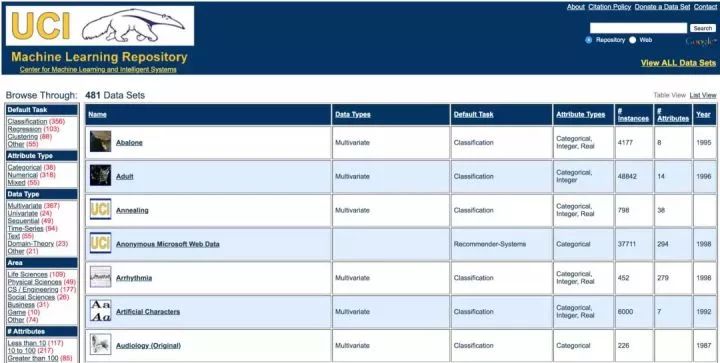
因此选择数据集还是需要根据自己的需要来选择,比较经典的数据集网站可以参考 UCI 数据集(archive.ics.uci.edu/ml/),或者从 kaggle 上找一些需要的数据集。
1.2 数据集的利用
如果选择开源的数据集作为研究基础,那么就会面临两个问题:
开源的数据集往往是作者根据当时的研究需求而构建的数据集,数据的特征可能并不严格符合当前研究的要求,那么我们可能就需要做一些格式转换,或者特征填充。例如我们需要对城市的出租车活动的范围进行统计,但是以 Roma/taxi 为例,数据集中所包含的地点是以经纬度坐标来体现的,如果需要经纬度对应的区域信息,可以通过 google map 的反向请求进行爬虫(当然需要一定的反爬虫机制)来补充相关的信息。另外一个例子是当需要对一些视频数据进行分类时,我们往往需要通过 OpenCV 等框架对其进行动作提取等操作,最终转化为分类模型所能识别的时序数据。因此,开源数据集虽然可以节省一些我们打造数据集的工作,但是也不是可以“拿来主义”的,仍然需要我们花很多功夫去研究才能加以利用。当然,一些行业熟悉的开源数据集不仅是大家公认的平均算法的标准,并且可以在 Github 上找到很多相应的处理方法,这样也可以节省很多时间。虽然目前的计算能力很高,但是对于一些研究领域而言,仍然有很多小规模的模型在研究。那么对于一些规模较大的数据就无法完全利用,这就产生了如何筛选数据的问题。一般来说,我们可以假设一个高质量的数据集是已经划分好训练集和测试集的,而且不同类别的数据分布也是平衡的。因此,同样可以假设训练集和测试集的数据分布具有很高的相似性,可以保证训练集和测试集直接的关联性。那么这种情况下可以根据模型大小,随机从训练集和测试集中选取相同比例的数据进行测试,这个比例可以通过反复的试验来确定。但是如果上述假设有不成立的条件,就需要对数据进行更仔细的筛选了,但是核心思想就是一定要保证我们选取的子数据集具有同原来数据集一样的泛化能力。
2 如何打造高质量的数据集
这部分内容我们主要引用一下知乎问题:如何打造高质量的机器学习数据集?(https://www.zhihu.com/question/333074061)下高赞的和我们相关版块主编的一些回答。核心观点:数据集的建立可以通过远程监督的方式快速获得更多数据。这里用举了一个微博文本情感分类的问题为例。这个问题是我提的,我来抛砖引玉一下,希望能引出大家更多更棒的方法。介绍一个我觉得比较惊艳的方法。远程监督获取新浪微博的情感分类数据
这个方法来自于 Twitter 的情感分类,最早提出这个方法的来自于下面这篇论文:Twitter Sentiment Classification using Distant Supervisionhttps://www-cs.stanford.edu/people/alecmgo/papers/TwitterDistantSupervision09.pdf
这篇文章提出了 Distant Supervision 的方法来做 Twitter 的情感分类,基本思想是用标签符号来判断文本的情感极性,如':)'表示开心,':('表示悲伤。因此我们一样可以用收集一批微博标签符号去标注新浪微博。 但这些标签符号标注的微博不一定是真的正例或者负例。因此还是带有噪音的数据,最好需要人工标注一部分去人工标注去验证一下。
但这些标签符号标注的微博不一定是真的正例或者负例。因此还是带有噪音的数据,最好需要人工标注一部分去人工标注去验证一下。情感倾向点互信息
新浪微博表情符号众多,每个表情符号表达正负感情的能力是不同的,不同表情表达正向、负向感情的能力也是不同的,因此需要对表情符号的感情表达能力进行排序。点间互信息(PMI)主要用于计算词语间的语义相似度,基本思想是统计两个词语在文本中同时出现的概率,如果概率越大,其相关性就越紧密,关联度越高。情感倾向点互信息算法(Semantic Orientation Pointwise Mutual Information, SO-PMI)是将 PMI 方法引入计算词语的情感倾向(Semantic Orientation,简称SO)中,从而达到捕获情感词的目地。基于点间互信息SO-PMI 算法的基本思想是:首先分别选用一组褒义词 P-words 跟一组贬义词N-words 作为种子词。这些情感词必须是倾向性非常明显,而且极具领域代表性的词语。若把一个词语 word 跟 Pwords 的点间互信息减去 word 跟Nwords 的点间互信息会得到一个差值,就可以根据该差值判断词语word的情感倾向。我们可以利用情感倾向点互信息 SO-PMI 来计算表情与正向/负向感情词之间的情感倾向: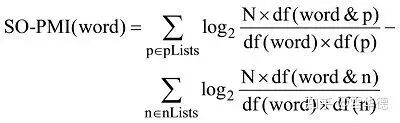 感谢 HowNet 情感词典,有 836 个正向情感词和 1254 个负向情感词,由此我们可以计算表情标签的情感倾向点互信息。通常情况下,将 0 作为 SO-PMI 算法的阀值,我们可以得到下面三种情况:
感谢 HowNet 情感词典,有 836 个正向情感词和 1254 个负向情感词,由此我们可以计算表情标签的情感倾向点互信息。通常情况下,将 0 作为 SO-PMI 算法的阀值,我们可以得到下面三种情况:- SO-PMI(word)> 0;为正面倾向,即褒义表情
- SO-PMI(word)= 0;为中性倾向,即中性表情
- SO-PMI(word)< 0;为负面倾向,即贬义表情
用情感符号标注新浪微博
根据 SO-PMI 值,最终可以敲定 14 个置信度很高的情感符号,其中 7 个正向感情符号,7 个负向情感符号:
 正向微博 = 含有正情感符号且不含任何负情感符号的微博负向微博 = 含有负情感符号且不含任何正情感符号的微博从情感符号标注的正向微博和负向微博中随机抽取一些数据进行人工标注,最终发现情感符号标注的数据准确率接近 90%,这说明用表情符号标注的数据还是不错的~当然还要提醒一点,数据使用前把表情符号从文本中移除,否则模型很容易学到你远程监督这个数据背后隐藏的 bias 的,移除表情符号后模型会更加从文本方面去理解和分类,避免过拟合,利于提高泛化性。
正向微博 = 含有正情感符号且不含任何负情感符号的微博负向微博 = 含有负情感符号且不含任何正情感符号的微博从情感符号标注的正向微博和负向微博中随机抽取一些数据进行人工标注,最终发现情感符号标注的数据准确率接近 90%,这说明用表情符号标注的数据还是不错的~当然还要提醒一点,数据使用前把表情符号从文本中移除,否则模型很容易学到你远程监督这个数据背后隐藏的 bias 的,移除表情符号后模型会更加从文本方面去理解和分类,避免过拟合,利于提高泛化性。2.2 作者知乎id:夕小瑶
核心观点:高质量数据集构建不容易,但是途径和方法有很多种。这里的回答比较全面从基本工具,获取类型和一些经验心得。无论是做研究还是解决业务问题,做数据集都是绕不开的问题。不过这个问题有点大了,分享一点 NLP 领域的数据集构建的血和泪吧。很多刚入行的同学觉得发布一个数据集是最容易灌水的了,燃鹅如果你真的做过就会发现,随意产生一个 数据集很容易,但是若以解决实际问题或让大家能在上面磕盐玩耍为目的,来产生一个能用的、质量高 的、难度适中的数据集一点都不容易。
由于没有很刻意的研究过这个问题,所以就分享几个个人觉得比较重要的点吧,分别是:
刚入坑的一些小伙伴可能会以为“高质量”=“超级干净”,于是为了追求“高质量”而疯狂的预处理,最后哭了。做数据集一般有两种动机:一种是为了 research,也就是为了造福广大研究人员以及推动领域的进步; 另一种,就是为了使用数据驱动的方法来优化业务指标,或解决项目中实实在在存在的问题。这两个看似不太相关的目的背后对“高质量”的定义确是非常相近的,那就是:只不过,对后一种目的来说,问题一般来源于线上系统 一般来说,在做数据集之前一般已经存在一套系统了(为了让系统冷启动,一般先开发一套规则驱动的 系统),系统上线后自然会产生日志,分析其中的 badcase 便可以知道哪些问题是现有系统搞不定的, 这些问题就可以考虑使用数据驱动的方法来解决,于是需要做数据集了。而解决这些问题就是你做数据集的第一目标啦。而对于前一种目的来说,问题一般来源于学术界的研究现状。现阶段的 NLP 研究多为数据驱动的,甚至说数据集驱动的。虽然这不是一个好现象,不过也不得不承认 很大程度上推动了 NLP 的发展和研究热潮。当现有的数据集无法 cover 领域痛点,或无法发挥数学工具潜力,或已经被解决掉的时候,就需要一个新的数据集,更确切的说是新的 benchmark 了。
换句话说,还有哪些问题是行业痛点问题?或可以进一步挖掘现阶段数学工具的潜力?或现有数学工具的 现发展阶段还没法很好的解决该问题?这应该是做一个高质量数据集前首先要考虑的问题。想想2015年的SNLI[1]、2016年的SQuAD[2]、2018年的GLUE[3], CoQA[4],再到如今的 SuperGLUE[5], MRQA,都是问题驱动的,当现有数据集不足以 cover 问题痛点或无法满足数学工具潜力, 或上一个问题已经被解决的差不多的时候,就会有新的数据集冒出来解决下一个痛点问题。在明确要解决的问题后,数据集的质量也就保障了一半,剩下的一半就要看这个数据集怎么做啦。这里面 最关键的问题是数据与标签来源的选择,以及预处理程度的把握。除此之外,迭代闭环的构建以及对复杂 NLP 任务的处理也会对问题解决的效率和质量产生非常重要的影响。下面开始依次介绍基本工具 :
所谓工欲善其事必先利其器,只要不是太着急,在做数据集之前先掌握一些好用的工具和 tricks,可以大大减少无谓的重复和低效劳动,提高迭代效率。- github:写爬虫和清洗最原始数据之前先在 github 找一下 正则表达式 文本清洗利器,不解释
- Hadoop/Spark:千万级以上的语料就别去为难你的小服务器了
- vim:分析样本专用。数据集只有几万或一二十万的话,vim 性能一般还是够用的,不过默认的 vim 配置是比较鸡 肋和反人类的,需要事先熟悉和配置好。要是跟 vim 过不去,其他带正则搜索和高亮显示的性能别太差的编 辑器也 ok
- awk,grep,cut,wc 等命令行工具:分析样本专用。数据集大了,你的 vim 就罢工了,当然你要是跟这些命令过不去也可以在 ipython 里玩,只 不过写代码效率更低,而且分析结果保存起来更麻烦一些,再就是别来open(file).readlines() 这种神操作就好
- ipython + screen/tmux:在分析一些重要的数据集统计特性如样本长度分布时,开个 vim 写 python 脚本会很低效,数据集一大的话反复 IO 更是让人无法忍受的。因此开个 ipython 把数据集或采样的一部分数据集load 进内存里,再进行各种分析会高效的多。另外为了避免 ssh 断开后从头重来,可以把 ipython 挂在 screen 或者 tmux 窗口里。当然, load 进来的数据比较多时,记得时不时的 del 一下无用的中间结果,以免把服务器内存撑爆。哦对,记得了 解一些常用的 magic 命令如 %save,可以很方便的对复杂操作进行备份。
数据与标签来源:
对数据集质量产生第二关键影响的就是数据和标签来源的选择了。其中数据可以通过人工构造、撰写的方式来产生,也可以从互联网上爬取或对公开数据集进行二次加工得到;标签同样可以人工标注,也可以远程监督的方式来获取。最容易想到的方式就是数据和标签都来源于人工啦,可惜小夕并没有资金去众包平台上帮你们积累经验,对于很多相对简单的NLP任务,数据一般在互联网上总能找到合适的,但是也有一些任务的数据 很难在互联网上接触到,一般情况下只能人工精心构造(比如自然语言推理,任务型对话中的大部分子任 务,分词、NER、抽取等一些序列标注任务)。如果有小伙伴想系统的学习标注,小夕推荐一本之前在图 书馆刷过一半的一本书,叫《Natural Language Annotation》,中文名貌似叫《自然语言标注:用于机 器学习》。这本书写的挺赞的,还因此怼过一次不太会标注的 PM 小姐姐(希望她不会看我知乎 hhhh还好对于大部分 nlp 任务而言,基本都能从互联网上找到合适的数据源,或在已有的公开数据集的基础上加 以改造就可以产生。如果要自己爬,英文语料的话可以通过国外的 twitter、quora、wiki、reddit等网站按需爬取甚至直接下载,官方提供的数据获取脚本满足不了需求的话可以在 github 上自己搜下,基本总能找到一些奇奇怪怪的第三方爬虫绕过限制(emmm怎么有种教别人犯罪的感觉)。如果目标数据是中文,当然国内也会有微 博、贴吧、豆瓣、百度百科、知乎等网站坐等被爬啦。当然啦,Twitter、微博、贴吧这类网站的缺点就是灌水内容太多,爬完记得去 github 找相应的预处理脚本 瘦瘦身(注意别用那些太过浮夸的脚本,处理的太干净可能会有问题,后面会讲原因哦)讲真,自己爬数据真是 dirty work 超级超级多,尤其是你要爬的数据量灰常大或者去爬一些不那么主流的网 站的时候!所以小夕更加推荐的还是先从现有的数据集想办法啦,拿来现成的然后一顿改改改绝对可以省不少力!
其实很多数据集都是这样“偷懒”做成的,比如早期 Socher 把只有 1 万样本的情感分类数据集 MR[16] 用 parser 将 MR 里的句子给分解为短语、子句等,再分别标注,于是就变成了 20 多万样本量、多粒度的 SST[17] 最近也恰好刷到一篇做文本风格控制的 paper[18],同样也是用了 parser,将 Yelp 情 感分类数据集 [19] 拆解后疯狂加工,变成了结构->文本的风格化文本生成数据集(parser真是个造数据集 的好东西)。总之,玩过一次就知道,改比爬方便多啦在打标签方面,最容易想到的当然还是花钱众包,不用说了,下一个方法。更加经济可用的方法就是远程监督了,这方面的可玩性就非常大啦,脑洞有多大,标注质量就会有多高!做好远程监督的前提就是提一个靠谱的假设,比如“给定一个 query-answer pair,如果 answer string 在搜索引擎召回的某 document 出现,那么该document可以回答该query”,于是有了机器阅读理解数据集 TriviaQA[6]、searchQA[7];再比如“一条Twitter中包含的emoji可以反映这条Twitter的(细粒度)情感”, 于是有了情感分类数据集TwitterSentiment[8] 和情感可控对话生成数据集 Mojitalk[9]。如果不放心的话,自己采样一些样本,粗略统计一下你提出的假设成立的样本占比,只要大部分情况下成 立就是有希望的,而后再对假设增加一些细节性的约束(比如 TriviaQA 里的 answer 必须在 doc 中高频出现;mojitalk 里的带多媒体信息的 Twitter 直接丢掉,多 emoji 时只看最高频的 emoji 等,在一个靠谱的假设下,经过几番小迭代往往就可以一个能用的数据集啦。总之,玩好远程监督也就是要掌握逆向思维,忘掉“标注”这个词,把思维改成“握着标签找数据“。适可而止的预处理
其实在做数据集这个事情上,有“洁癖”并不是一件好事,尤其是当语料的 lexical diversity & semantic richness 比较强的时候,一条看似让数据集更干净的正则表达式很可能沙雕了一些跟类别标签相关的有效模式,导致一些本来成立的X->Y的映射关系因此消失了
减少了模型对抗噪声的学习机会,你无法消除所有噪声,但是却消除了很多模型识别噪声适应噪声的学习机会这方面小夕一把辛酸泪呀,曾经花了半下午时间写了几十条清洗规则,结果model 更难收敛以及开发集表 现更差了。最终发现数据量和模型都不是太小的情况下,遵从最少预处理原则一般就够了,除了一些常规操作(比如滤掉HTML标签、URL、脱敏、去重、截断等),小夕一般只对如下情况进行处理:导致了“标签泄漏”,这种情况容易发生在任务简单、标签典型的场合,数据源比较多时尤其容易踩坑。比如你任务的目标是让模型通过文本语义判断情感,那就不要对 emoji、颜文字手下留情了,严格控制它们在 数据集中的比例。导致了样本过长,比如连续 100 个相同的 emoji、哈、啊等样本中出现了预留的功能词(比如 BERT 中的 [UNK],[PAD],[CLS],[SEP] 之类的)当然,如果你的数据集是生成任务相关,记得滤掉黄反内容=,=。对于一些高频错别字,一堆点点点之类的 让你觉得 dirty 的东西,没特殊需求的话就放过它们吧。。。(真想彻底消除它们的话就换数据源啊喂,不 要妄想以一人之力对抗广大人民群众产生的辣鸡!!)无论是人工标注的还是远程监督标注的,数据集看起来做好了不代表就是可用的,如果标注的噪声太大或 者标签边界太过模糊(大量标注错误,或标注规则写的太松、太模糊,导致人都分不清某几个类别之间的 区别),很可能再复杂的模型都在这份数据集上无法收敛;反之,如果数据集中有“标签泄漏”(比如你用 emoji 远程监督构造了情感分类数据集,最后却忘了滤掉emoji)或标签与内容有非常直接的映射关系(类 别太过具体或标注规则写的太死),那就会导致一个非常简单的模型都会轻易的把这个数据集刷到近乎满 分,那这个模型学到的知识基本是没有什么实际意义的,换言之,这么简单直接的任务其实几条规则几行 代码就搞定了,完全没必要做数据驱动的模型训练。因此绝对不要抱着将数据集一次做成的心态,而是要尽早构造一个“生成数据集->跑baseline->badcase study->更新策略->重新生成数据集”的闭环。注意,baseline别选的太麻烦(那种对各种超参敏感的模型 还是算了吧),最好是已被普遍验证有效的、有开源代码的、上手轻松的、基本不用调参就效果还可以的 模型(比如 BERT 系列)。这里要注意侧重点,在迭代的早期,让 baseline 能在你的数据集上正常收敛是第一目标,中期则是关注 baseline 在开发集上的表现,表现太好要留意标签泄漏或数据泄漏( X 中出现了 Y ,或忘记去重),表现太 差调调参,后期则是更多关注 badcase了,看看 badcase 中更多的是样本问题(标注噪声)还是真的模型能力不够。关于复杂NLP任务
当然啦,上面其实都说的比较宽泛,其实在不同的 NLP 问题上做数据集可能会很不一样。像一些简单 NLP 任务如文本分类等基于上面的基本原则就差不多了,但是一些复杂 NLP 任务如任务型对话、知识图谱相关, 哪怕完全人工产生和标注都不好做的。比如任务型对话相关的数据集,很难使用远程监督这种偷懒的方式来构造,样本和标签的产生可能都很难 脱离人力标注。有兴趣的小伙伴可以参考MultiWOZ[10]这个数据集(cover了DST、act-to-text generation和context-to-text generation这三个任务型对话中的子任务)的paper,里面对machinemachine方式(如M2M[11])、machine-human(如DSTC系列12[14])、human-human(如ATIS[15], WOZ 系列[10])这三种协同构造任务型对话数据集的方式总结的很到位,会让你感受到产出一个高质量的 任务完成型对话数据集是一个很有挑战的工作,自己从头摸索的话可能到头来只会收获一脸懵逼。所以面对一些比较复杂的 NLP 任务的时候,一定一定要记得先精读一下最新最权威的数据集的 paper,这类 数据集的构建经验可能整个知乎也找不到几篇的。2.3 作者知乎id:留德华叫兽
核心观点:主要从视觉角度出发谈了一下数据的获取途径和制作问题。我目前在车厂无人驾驶部门的职责之一便是研发无人驾驶感知算法的数据集的半自动标注算法。再具体一点就是计算机视觉领域的:语义分割(Semantic Segmentation) 和 全景分割 (Panoptic Segmentation)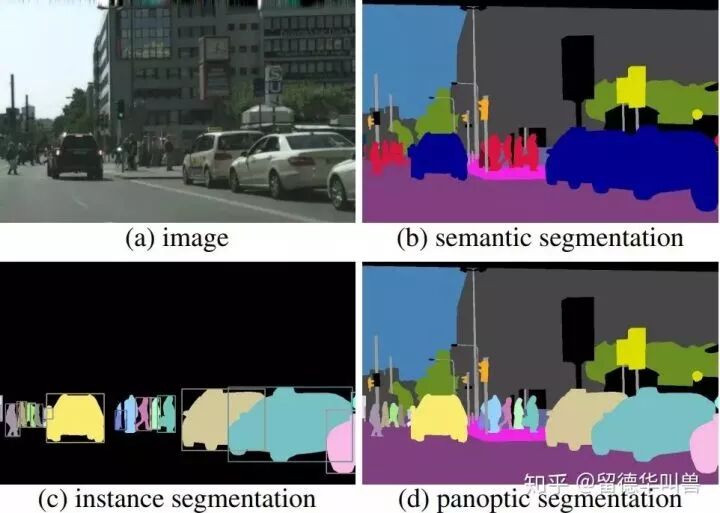 它们或许是数据标注领域成本最高的俩个任务(按德国最低工资标准,高达100人民币/图),它们的具体定义可以见上图 。
它们或许是数据标注领域成本最高的俩个任务(按德国最低工资标准,高达100人民币/图),它们的具体定义可以见上图 。
一、标注任务
语义分割: 对图片中每一个像素标注其类别(如:汽车、行人、道路等) 全景分割:对于每一个像素,在语义分割的基础上再区分目标instance物体(如:汽车1、汽车2、 行人5等)二、标注格式
通常标注结果还是存成图片的常见格式(如: png) 图片的每一个通道存储不同信息(用数字1-255表示) 例如第一通道存储:该像素所属类别 第二通道:如果该像素属于目标物体,他属于第几个instance 第三通道:通常是0或1,1表示该像素是可以驾驶的区域,0反之三、开源数据集
- Cityscapes(戴姆勒公司、德国马普所、TU Darmstadt): cityscapes-dataset.com/
- Mapillary Vistas (丰田、Lytf等赞助):mapillary.com/dataset/v... Kitti
- Dataset (德国KIT和丰田芝加哥研究所): cvlibs.net/datasets/kit...
四、数据集的成本和作用
- 成本:据 Cityscapes 官方,标注一张该数据集中的语义分割平均需要 1.5小时!!!德国最低工资是 9 欧元左右/小时,因此在德国标注一张语义分割图片的成本超过 13 欧元(约合 100 块人民币)!!
- 重要性:
深度学习需要大量精细标注的数据作为“燃料” 保守 L3 要能够上路 需要至少几百万张标注精细的训练图片人工智能时代,谁拥有数据谁就拥有源源不断的燃料 数据集也成为无人驾驶公司和主机厂的兵家必争之地
手动标注一张语义分割像素级别的图片平均需要 1.5 小时 有没有什么更智能的办法提高标注效率呢?专注于优化算法的以下略探 12 :1. ScribbleSup: Scribble-Supervised Convolutional Networks for ...2. Weakly-and Semi-Supervised Panoptic Segmentation3. Fast Interactive Object Annotation With Curve-GCN其中 paper 1 和 2 是用涂鸦和画方框的方式与图片交互,Paper 3 是用描物体边界的方式标注软件的一般流程是:标注者输入交互信息-算法自动标注-标注者修改-算法标注 直到标注者满意为止。Paper 1 和 2 还 report 了只进行一次交互(标注时间为几十秒) 图像分割优化算法结合深度学习 CNN 便可以达到相较于精细标注 95% 的精度。
六、结语
数据标注是如今深度学习获得巨大成功的基石,从 Feifei Li 创建 ImageNet(1 千多万张、2 万多类别图片)开始,数据集便成为计算机视觉的一个热点话题,而伴随着数据集的各种 challenge 和刷榜单,也成为 CV 领域发顶会的标配。希望“无偿”使用公开数据集的研究者和业界从业 都能尊重数据集创作者的汗水。人工智能的从业者也能认可那些幕后做着重复枯燥标记工作者的付出。