
作者:沂水寒城,CSDN博客专家,个人研究方向:机器学习、深度学习、NLP、CV
Blog: http://yishuihancheng.blog.csdn.net
推荐系统在我们日常生活中发挥着非常重要的作用,相信实际从事过推荐相关的工程项目的人或多或少都会看多《推荐系统实践》这本书,我也是读者之一,个人感觉对于推荐系统的入门来说这本书籍还是不错的资料。很多商场、大厂的推荐系统都是很复杂也是很强大的,大多是基于深度学习来设计强有力的计算系统,我在上一篇文章《基于surprise的图书、电影推荐系统》中基于surprise模块实现了图书、电影的推荐系统设计与实现,今天这一篇文章主要是介绍一下深度学习的推荐系统项目实践,基于深度学习实现音乐的推荐。
项目整体架构示意图如下图所示:
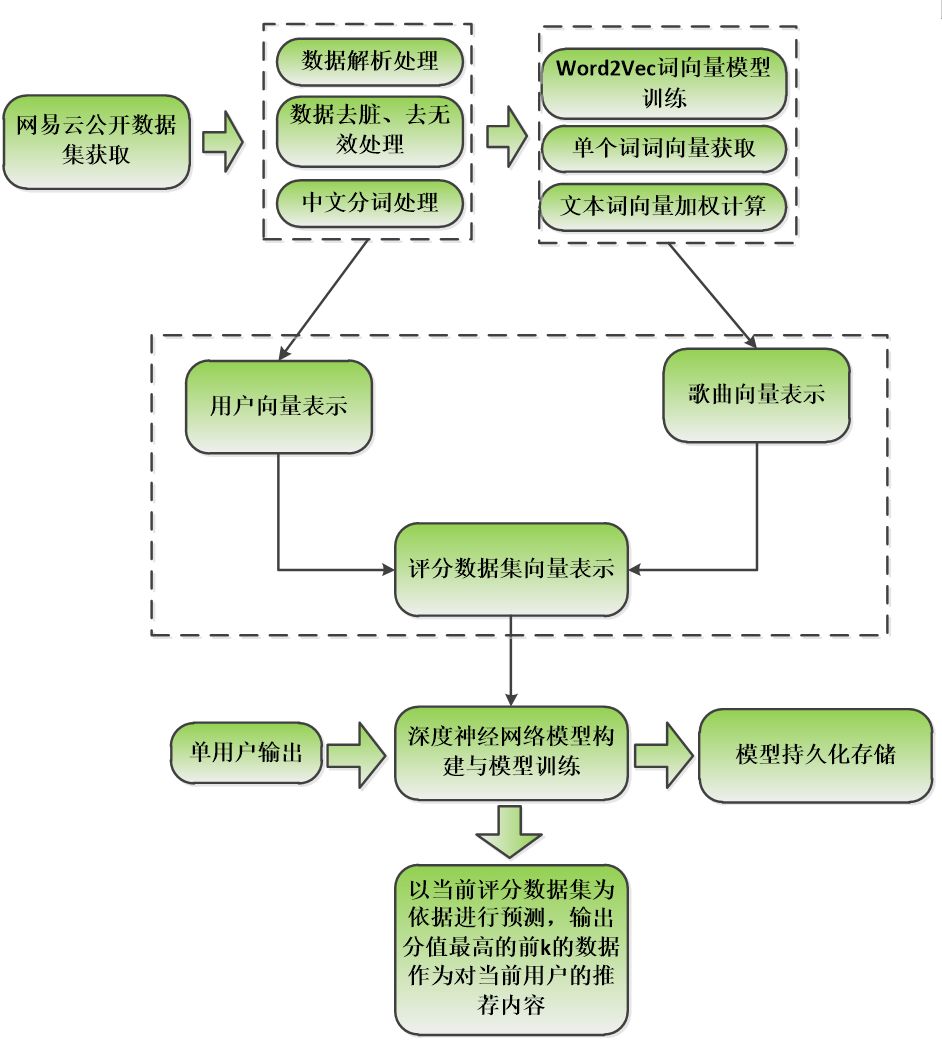
本文的音乐数据是基于网易音乐数据进行的,项目主要包括:网易云音乐数据爬取、数据预处理、文本向量化处理、数据集构建与深度学习模型训练、歌曲推荐几个部分。
接下来会针对上面几个主要的步骤进行说明,由于网易云音乐数据目前已经限定不让爬取所以这里就不再对爬虫进行介绍。
一、数据预处理
这一部分内容比较简单,具体的代码实现如下:
def dataPre(one_line):
'''
去脏、去无效数据
'''
with open('stopwords.txt') as f:
stopwords_list=[one.strip() for one in f.readlines() if one]
sigmod_list=[',','。'
,'(',')','-','——','\n','“','”','*','#','《','》','、','[',']','(',')','-',
'.','/','】','【','……','!','!',':',':','…','@','~@','~','「一」','「','」',
'?','"','?','~','_',' ',';','◆','①','②','③','④','⑤','⑥','⑦'
,'⑧','⑨','⑩',
'⑾','⑿','⒀','⒁','⒂','"',' ','/','·','…','!!!','】','!',',',
'。','[',']','【','、','?','/^/^','/^','”',')','(','~','》','《','。。。',
'=','⑻','⑴','⑵','⑶','⑷','⑸','⑹','⑺','…','|']
for one_sigmod in sigmod_list:
one_line=one_line.replace(one_sigmod,'')
return one_line
def seg(one_content):
'''
分词并去除停用词
one_content:单条企业名称数据
stopwords:停用词列表
'''
stopwords=[]
segs=jieba.cut(one_content,cut_all=False)
segs=[w.encode('utf8') for w in list(segs)]
seg_set=set(set(segs)-set(stopwords))
return list(seg_set)
主要就是去除爬取得到的文本数据中的脏数据、无效字符等,之后对中文歌曲名称进行分词处理。
二、文本向量化处理
该部分主要是借助于word2vec向量化工具,对上一阶段处理得到的文本语料数据进行词向量训练与文本加权向量化计算的工作,具体的代码实现如下所示:
def word2vecModel(con_list,model_path='my.model'):
'''
参数解释:
1.sentences:可以是一个List,对于大语料集,建议使用BrownCorpus,Text8Corpus或·ineSentence构建。
2.sg: 用于设置训练算法,默认为0,对应CBOW算法;sg=1则采用skip-gram算法。
3.size:是指输出的词的向量维数,默认为100。大的size需要更多的训练数据,但是效果会更好. 推荐值为几十到几百。
4.window:为训练的窗口大小,8表示每个词考虑前8个词与后8个词(实际代码中还有一个随机选窗口的过程,窗口大小<=5),默认值为5。
'''
model=word2vec.Word2Vec(con_list,sg=1,size=100,window=5,min_count=1
,
negative=3,sample=0.001, hs=1,workers=4)
model.save(model_path)
return con_list,model
def song2Vec(data='music/songName.txt',model_path='music/song2Vec.model'):
'''
对歌曲名称分词后构建word2vec模型
'''
with open(data) as f:
data_list=[one.strip() for one in f.readlines() if one]
data=[]
for i in range(len(data_list)):
musicId,content=data_list[i].split('|#|')
con_list=content.split('/')
data.append(con_list)
word2vecModel(data,model_path=model_path)
上述代码完成了文本的向量化计算工作。单个文本的加权向量化计算方式如下:
def getDocVec(model,word_list=['很','好吃','团鱼'
],w_list=[0.12,0.53,0.35]):
'''
生成单个文本内容的向量(所有词向量加权求和)
'''
vec=np.array([0]*100,dtype='float32')
for i in range(len(word_list)):
vec+=model[word_list[i]]*w_list[i]
return vec
到此,文本的向量化计算就完成了。
三、数据集构建与深度学习模型训练
推荐系统需要有标注的样本集数据来帮助模型进行前期知识的学习,音乐歌曲推荐也是一样的道理,想要神经网络模型能够准确地进行歌曲推荐,首先就需要给它输入一批量的推荐标注数据进行学习和计算。
数据集创建具体实现如下所示:
def createVector(songVec='music/song2Vec.json',save_path='music/dataset.json'):
'''
构建样本集
'''
with open(songVec) as S:
song_vector=json.load(S)
with open('music/score.csv') as f:
data_list=[one.strip().split(',') for one in f.readlines() if one]
vector=[]
for i in range(len(data_list)):
one_list=[]
userId,songId,rating,T=data_list[i]
try:
songV=song_vector[songId]
one_list+=songV
one_list.append(int(str(int(float(rating)/20)).split('.')[0].strip()))
vector.append(one_list)
except:
pass
with open(save_path,'wb') as f:
f.write(json.dumps(vector))
完成了音乐推荐数据集的创建工作后就可以搭建深度学习模型进行学习计算了,模型搭建的具体实现如下所示:
def deepModel(data='dataset.json',saveDir='model/'):
'''
深度学习网络模型
'''
if not os.path.exists(saveDir):
os.makedirs(saveDir)
scaler,X_train,X_test,y_train,y_test=getVector(data=data)
model=Sequential()
model.add(Dense(1024,input_dim=X_train.shape[1]))
model.add(Dropout(0.3))
model.add(Dense(1024,activation='linear'
))
model.add(Dropout(0.3))
model.add(Dense(1024,activation='sigmoid'))
model.add(Dropout(0.3))
model.add(Dense(1,activation='tanh'))
optimizer=Adam(lr=0.002,beta_1=0.9,beta_2=0.999,epsilon=1e-08)
model.compile(loss='mae',optimizer=optimizer)
early_stopping=EarlyStopping(monitor='val_loss',patience=20)
checkpointer=ModelCheckpoint(filepath=saveDir+'checkpointer.hdf5',verbose=1,save_best_only=True)
history=model.fit(X_train,y_train,batch_size=128,epochs=50,validation_split=0.3,verbose=1,shuffle=True,
callbacks=[checkpointer,early_stopping])
model.save(saveDir+'music.model')
print(model_summary)
使用Keras完成需要的神经网络模型的搭建是很方便快捷的一项工作,这里你可以随意修改你需要的神经单元个数或者是神经网络的深度,使用任何你想用的优化器、激活函数和评价函数也都是可以的,不同的组合可以得到不同的计算结果。
由于数据量的不一,这里的训练时间可能会很短或者是非常长,建议模型的训练过程就放在服务器上面去吧。下面简单贴一下我的模型训练过程截图:
四、歌曲推荐
完成了上面的一系列工作之后,这里就进入到音乐推荐系统的最后一步了,就是进行音乐推荐。
具体的实现如下:
def singleUserRecommend(userId='2230728513',model_path='results/music/DL/DL.model'):
'''
输入用户id,输出推荐的内容
'''
one_song_list=user_song[userId]
no_listen_list=[one for one in song if one not in one_song_list]
userVec=user_vector[userId]
one_no_dict={}
for one_no in no_listen_list:
one=[]
one+=user_vector[userId]
one+=song_vector[one_no]
X=np.array([one])
score=model.predict(X)
y_pre=score.tolist()[0]
one_no_dict[one_no]=y_pre
one_no_sorted=sorted(one_no_dict.items(),key=lambda e:e[1],reverse=True)
recommend_id_list=[one[0] for one in one_no_sorted][:10]
for oneId in recommend_id_list:
print('songId: ',oneId)
print('songName: ',song_dict[oneId])
上述功能实现了对指定输入的用户id,推荐其还未听过的可能的最感兴趣的歌曲,实例测试结果输出如下所示:
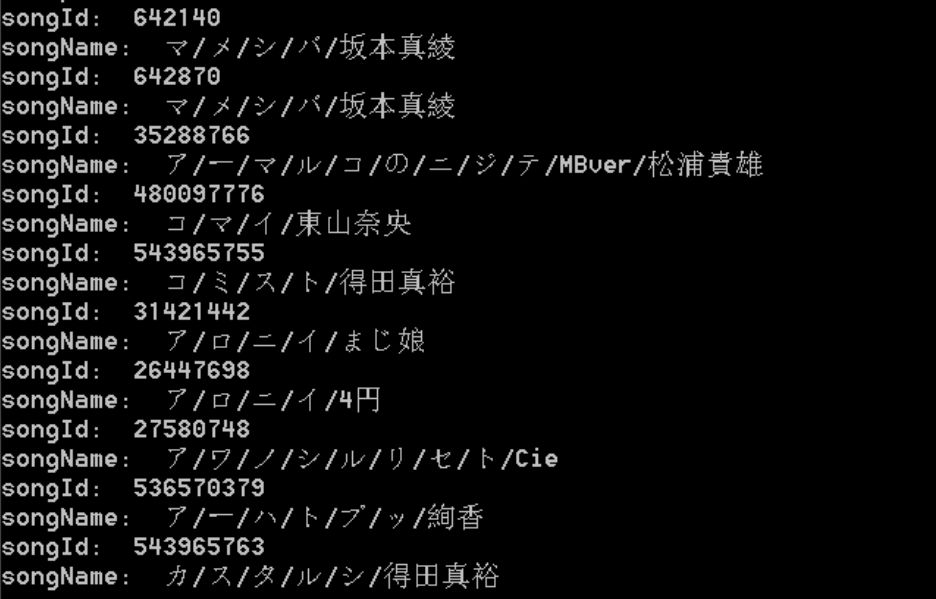
看来这位用户是比较喜欢日文歌曲的人啊~
到这里本文的工作就结束了,很高兴在自己温习回顾知识的同时能写下点分享的东西出来,如果说您觉得我的内容还可以或者是对您有所启发、帮助,还希望得到您的鼓励支持,谢谢!
赞 赏 作 者

Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。

▼ 点击成为社区注册会员 「在看」一下,一起PY









