
作者:Michael Galarnyk
翻译:李润嘉
校对:和中华
本文约3600字,建议阅读15分钟。
本教程介绍了用于分类的决策树,即分类树,包括分类树的结构,分类树如何进行预测,使用scikit-learn构造分类树,以及超参数的调整。
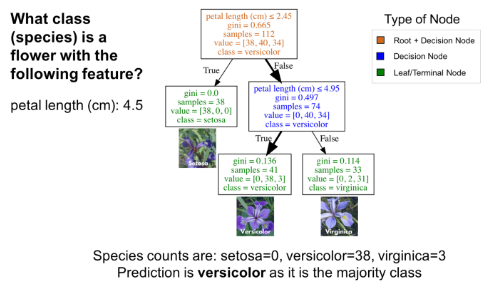
由于各种原因,决策树一种流行的监督学习方法。决策树的优点包括,它既可以用于回归,也可用于分类,易于解释并且不需要特征缩放。它也有一些缺点,比如容易过拟合。本教程介绍了用于分类的决策树,也被称为分类树。与往常一样,本教程中用到的代码可以在我的github(结构,预测)中找到,我们开始吧!分类和回归树(CART)是由Leo Breiman引入的,用一种于解决分类或回归预测建模问题的决策树算法。本文只介绍分类树。从本质上讲,分类树将分类转化为一系列问题。下图是在IRIS数据集(花卉种类)上训练的一个分类树。根节点(棕色)和决策节点(蓝色)中包含了用于分裂子节点的问题。根节点即为最顶端的决策节点。换句话说,它就是你遍历分类树的起点。叶子节点(绿色),也叫做终端节点,它们不再分裂成更多节点。在叶节点处,通过多数投票决定分类。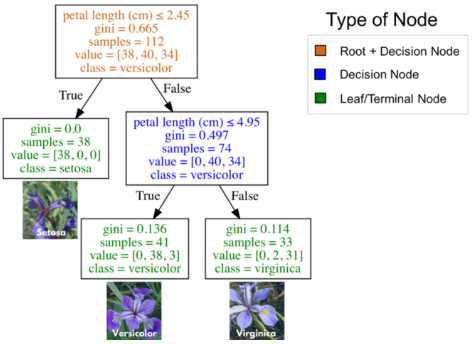
将三个花卉品种(IRIS数据集)一一进行分类的分类树
使用分类树,要从根节点(棕色)开始,逐层遍历整棵树,直到到达叶节点(终端节点)。如下图所示的分类树,假设你有一朵花瓣长度为4.5cm的花,想对它进行分类。首先从根节点开始,先回答“花瓣长度(单位:cm)≤ 2.45吗?”因为宽度大于2.45,所以回答否。然后进入下一个决策节点,回答“花瓣长度(单位:cm)≤ 4.95吗?”。答案为是,所以你可以预测这朵花的品种为变色鸢尾(versicolor)。这就是一个简单的例子。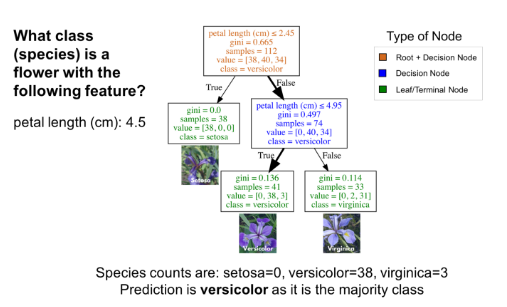
分类树从数据中学到了一系列“如果…那么…”的问题,其中每个问题都涉及到一个特征和一个分割节点。从下图的局部树(A)可看出,问题“花瓣长度(单位:cm)≤ 2.45”将数据基于某个值(本例中为2.45)分成两个部分。这个数值叫做分割点。对分割点而言,一个好的值(使得信息增益最大)可将类与类之间分离开。观察下图中的B部分可知,位于分割点左侧的所有点都被归为山鸢尾类(setosa),右侧的所有点则被归为变色鸢尾类(versicolor)。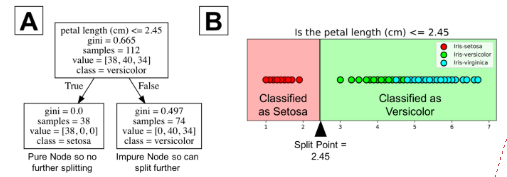
从图中可看出,山鸢尾类(setosa)中所有的38个点都已被正确分类。它是一个纯节点。分类树在纯节点上不会分裂。它不再产生信息增益。但是不纯节点可以进一步分裂。观察图B的右侧可知,许多点被错误归类到了变色鸢尾类(versicolor)。换而言之,它包含了分属于两个不同类(setosa和versicolor)的点。分类树是个贪婪算法,这意味着它会默认一直分裂直到得到纯节点。而且,该算法会为不纯节点选择最佳分割点(我们会在下节介绍数学方法)。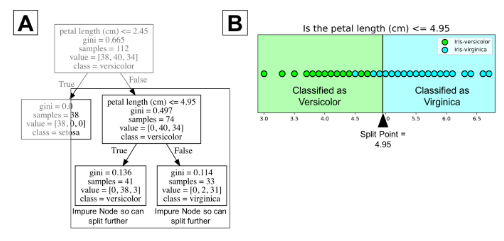
在上图中,树的最大深度为2。树的深度是对一棵树在进行预测之前可分裂次数的度量。树可进行多次分裂,直到树的纯度越来越高。多次重复此过程,会导致树的深度越来越大,节点越来越多。这会引起对训练数据的过拟合。幸运的是, 大多数分类树的实现都允许控制树的最大深度,从而减少过拟合。换而言之,可以通过设置决策树的最大深度从而阻止树的生长超过某个特定深度。可通过下图直观地了解最大深度。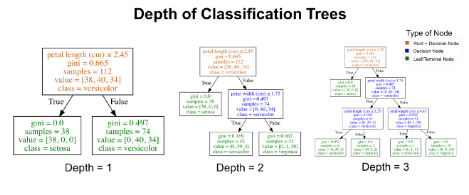
本节解答了信息增益、基尼指数和熵是如何计算出来的。
在本节,你可以了解到什么是分类树中根节点/决策节点的最佳分割点。决策树在某个特征和相对应的分割点上进行分裂,从而根据给定的准则(本例中为基尼指数或熵)产生最大的信息增益(IG)。可以将信息增益简单定义为:IG = 分裂前的信息(父) – 分裂后的信息(子)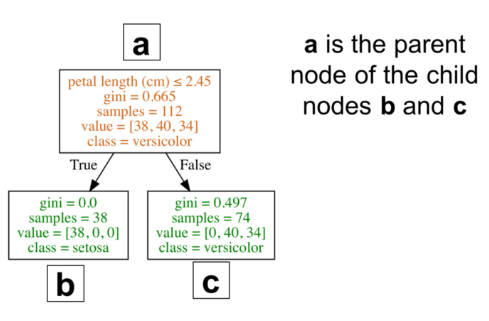
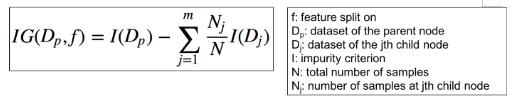
因为分类树是二元分裂,上述公式可以简化为以下公式。

为了更好的理解这些公式,下图展示了如何使用基尼指数准则计算决策树的信息增益。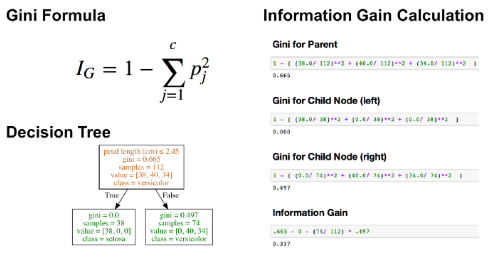
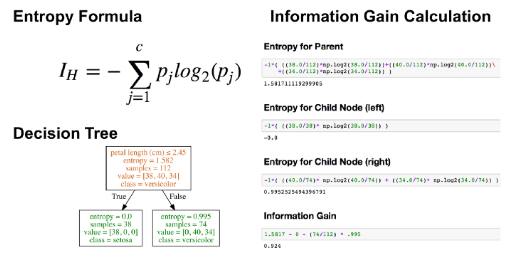
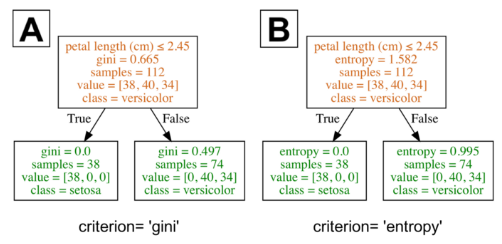
我不打算对细节进行过多的阐述,但是你应当知道,不同的不纯度度量(基尼指数和熵)通常会产生相似的结果。下图就展示了基尼指数和熵是极其相似的不纯度度量。我猜测,基尼指数之所以是scikit-learn的默认值,是因为熵的计算过程略慢一些(因为它使用了对数)。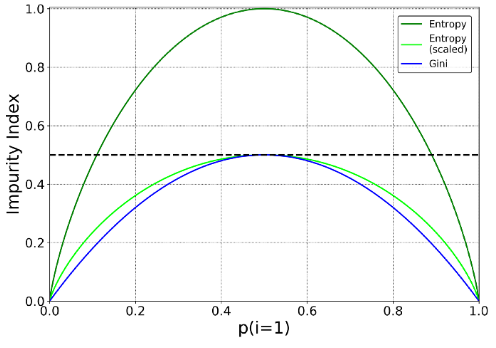
不同的不纯度度量(基尼指数和熵)通常会产生相似的结果。感谢Data Science StackExchange 和 Sebastian Raschka为本图提供的灵感。
在结束本节之前,我应注明,各种决策树算法彼此不同。比较流行的算法有ID3,C4.5和CART。Scikit-learn使用了CART算法的优化版本。你可以点击此处了解它的时间复杂度。我们在上节介绍了分类树的理论。之所以需要学习如何使用某个编程语言来实现决策树,是因为处理数据可以帮助我们来理解算法。Iris数据集是scikit-learn自带的数据集之一,不需要从外部网站下载。通过下列代码载入数据。import pandas as pd
from sklearn.datasets import load_iris
data = load_iris()
df = pd.DataFrame(data.data, columns=data.feature_names)
df['target'] = data.target
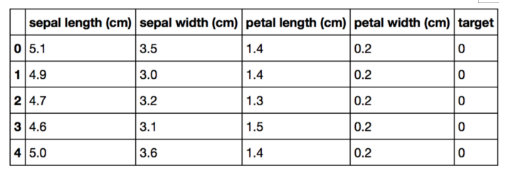
原始Pandas df(特征和目标)
下述代码将75%的数据划分到为训练集,25%的数据划分到测试集合。X_train, X_test, Y_train, Y_test = train_test_split(df[data.feature_names], df['target'], random_state=0)
图中的颜色标注了数据框df中的数据划分到了哪类(X_train, X_test, Y_train, Y_test)变量
注意,决策树的优点之一是,你不需要标准化你的数据,这与PCA和逻辑回归不同,没有标准化的数据对它们的影响非常大。在scikit-learn中,所有的机器学习模型都被封装为Python中的类。from sklearn.tree import DecisionTreeClassifier
在下列代码中,我通过设定max_depth=2来预剪枝我的树,从而确保它的深度不会超过2。请注意,这个教程的下一节将介绍如何为你的树选择恰当的max_depth值。还需注意,在下列代码中,我设定random_state=0,所以你也可以得到和我一样的结果。clf = DecisionTreeClassifier(max_depth = 2,
random_state = 0)
该模型将学习X (sepal length, sepal width, petal length, and petal width) 和 Y(species of iris)之间的关系。clf.fit(X_train, Y_train)
# Predict for 1 observation
clf.predict(X_test.iloc[0].values.reshape(1, -1))
# Predict for multiple observations
clf.predict(X_test[0:10])
尽管有许多评估模型性能的方式(精度,召回率,F1得分,ROC曲线等),我们还是保持简单的基调,使用准确率作为评估的标准。准确率的定义为:(正确预测的比例):正确预测的数量/总数据量# The score method returns the accuracy of the model
score = clf.score(X_test, Y_test)
print(score)
寻找max_depth最优值的过程就是调整模型的过程。下列代码输出了不同max_depth值所对应的决策树的准确率。# List of values to try for max_depth:
max_depth_range = list(range(1, 6))
# List to store the accuracy for each value of max_depth:
accuracy = []
for depth in max_depth_range:
clf = DecisionTreeClassifier(max_depth = depth,
random_state = 0)
clf.fit(X_train, Y_train)
score = clf.score(X_test, Y_test)
accuracy.append(score)
由下图可看出,当max_depth的值大于或等于3时,模型的准确率最高,所以选择max_depth=3,在准确率同样高的情况下,模型的复杂度最低。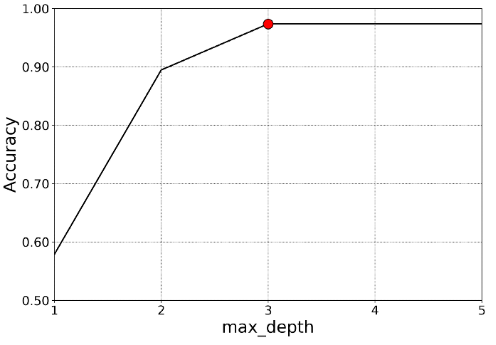
选择max_depth=3因为此时模型的精确率高且复杂度较低。
你需要谨记,max_depth和决策树的深度并不是一回事。Max_depth是对决策树进行预剪枝的一个方法。换而言之,如果一棵树在某个深度纯度已经足够高,将会停止分裂。下图分别展示了当max_depth的值为3,4,5时的决策树。由下图可知,max_depth为4和5时的决策树是一模一样的。它们的深度相同。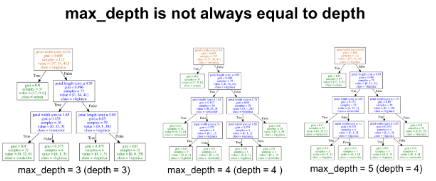
请观察我们是如何得到两棵一模一样的树
如果想知道你训练的决策树的深度是多少,可以使用get_depth方法。除此之外,可以通过get_n_leaves方法得到叶子节点的数量。尽管本教程已经介绍了一些选择准则(基尼指数,熵等)和树的max_depth,请记住你也可以调整要分裂的节点的最小样本(min_samples_leaf),最大叶子节点数量(max_leaf_nodes)等。分类树的优点之一是,它们相对易于解释。基于scikit-learn的分类树可以计算出特征的重要性,即在给定特征上分裂而导致基尼指数或熵减小的总量。Scikit-learn对每个特征输出一个0和1之间的数值。所有特征的重要性之和为1。下列代码展示了在决策树模型中每个特征的重要性。importances = pd.DataFrame({'feature':X_train.columns,'importance':np.round(clf.feature_importances_,3)})
importances = importances.sort_values('importance',ascending=False)
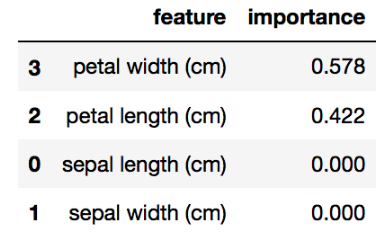
在上述例子中(iris的某个特定的训练集测试集划分),花瓣宽度的特征重要性权重最高。我们可以通过察看相应的决策树来确认。
这个决策树仅基于两个特征进行分裂,分别是花瓣宽度(单位:cm)和花瓣长度(单位:cm)请注意,如果一个特征的重要性分值较低,也并不意味着这个特征对预测而言不重要,只是说明在树的较早阶段,它未被选择到。该特征也可能与另一个信息量较高的特征完全相同或高度相关。特征重要性值不能说明它们对哪个类别具有很好的预测性,也不会说明可能影响预测的特征之间的关系。要注意的是,在进行交叉验证或类似的验证时,可以使用来自不同训练集测试集划分的特征重要性值的平均值。虽然这篇文章只介绍了用于分类的决策树,但请随意阅读我的其他文章《用于回归的决策树(Python)》。分类和回归树(CART)是一个相对较老的技术(1984),是更复杂的技术的基础。决策树的主要缺点之一是它们通常不是最准确的算法。部分原因是决策树是一种高方差算法,这意味着训练数据中的不同划分会导致非常不同的树。如果您对本教程有任何疑问或想法,请随时通过以下评论或通过Twitter与我们联系。Michael Galarnyk是一名数据科学家和企业培训师。他目前在Scripps翻译研究所工作。
您可以在:
Twitter(https://twitter.com/GalarnykMichael)Medium(https://medium.com/@GalarnykMichael)GitHub(https://github.com/mGalarnyk)上找到他。
原文标题:
Understanding Decision Trees for Classification in Python
原文链接:
https://www.kdnuggets.com/2019/08/understanding-decision-trees-classification-python.htm
编辑:于腾凯
校对:林亦霖
李润嘉,首都师范大学应用统计硕士在读。对数据科学和机器学习兴趣浓厚,语言学习爱好者。立志做一个有趣的人,学想学的知识,去想去的地方,敢想敢做,不枉岁月。
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
 点击“阅读原文”拥抱组织
点击“阅读原文”拥抱组织










