分布式计算确实需要在很多 GPU 上训练,但你见过在排名第一的超算上训练深度模型,在 2.76 万块 V100 GPU 训练模型的方法吗?重要的是,通过新的通信策略,这么多 GPU 还能实现近线性的加速比,橡树岭国家实验室和英伟达等机构的这项研究真的 Amazing。
论文链接:https://arxiv.org/pdf/1909.11150.pdf
在这篇论文中,研究者介绍了同步分布式 DL 中一种新型通信策略,它主要由梯度缩减编排和梯度张量分组策略组成。这些新技术令计算和通信之间产生了最完美的重叠,并且完成了近线性的 GPU 扩展。
也就是说,在 Summit 超算中,它能使用 2.76 万块 V 100 GPU 高效地训练模型,且扩展系数达到了惊人的 0.93。0.93 是个什么概念?我们可以通过 TensorFlow 的官方 Benchmark 了解一番。如下所示,60 块 GPU 理想情况下能获得 60 倍的加速,但是以前 TF 训练 ResNet-152 只能获得 50 倍的加速。
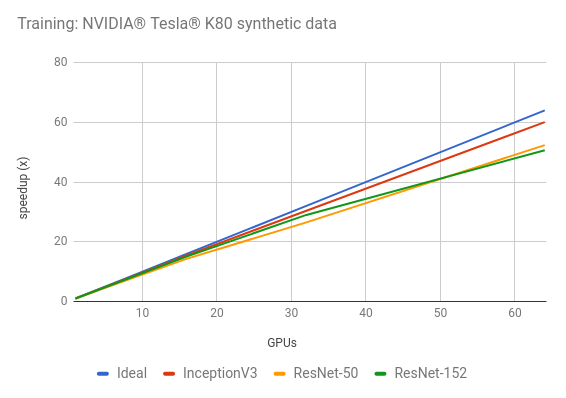
图片来源:https://www.tensorflow.org/guide/performance/benchmarks
这还只是 60 块 GPU,它的扩展系数就只有 0.83。此外,如果 GPU 扩展到 1000 乃至更多,那么这个系数还会急剧下降。
尽管近来很多分布式训练策略也能达到近线性扩展,例如 Ring All Reduce 或刘霁等研究者提出的 DoubleSqueeze(ICML 2019) 等等,但如这篇论文能在超算、在 2.76 万块 V 100 GPU 上实现近线性的加速性能,还是非常少见。
此外,重要的是,研究者展示了大规模分布式 DL 训练在科学计算问题中的强大能力,它能更合理地利用超算的能力。本文并不重点介绍这一部分,感兴趣的读者可查阅原论文。
什么是分布式训练
直观上,分布式训练只不过是由一块 GPU 扩展到多块 GPU,但随之而来的是各种问题:模型、数据怎么分割?梯度怎么传播、模型怎么更新?
在分布式计算中,一般我们可以将不同的计算机视为不同的计算节点,它们通过互联网相连而组成整个计算集群。现在重要的就是找到一种方法将计算力与模型训练相「结合」,也就是分布式策略。最直观的两种策略可能就是模型并行与数据并行,它们从不同的角度思考如何分割模型训练过程。
其中模型并行指的是从逻辑上将模型分割为不同的部分,然后再部署到不同的计算节点,就像 AlexNet 那样。这种方式主要解决的是模型参数量过大等耗显存的情况。数据并行指的是将数据集分割为不同的子模块,然后馈送到不同的节点中。与模型不同,数据天然就是可并行的,因此实践中大部分问题都采用数据并行策略。
在数据并行中,具体还有多种并行策略,例如同步 SGD 和异步 SGD 等。它们是最常见的分布式训练方法,TensorFlow、PyTorch 等框架都可以直接调用这几种模式。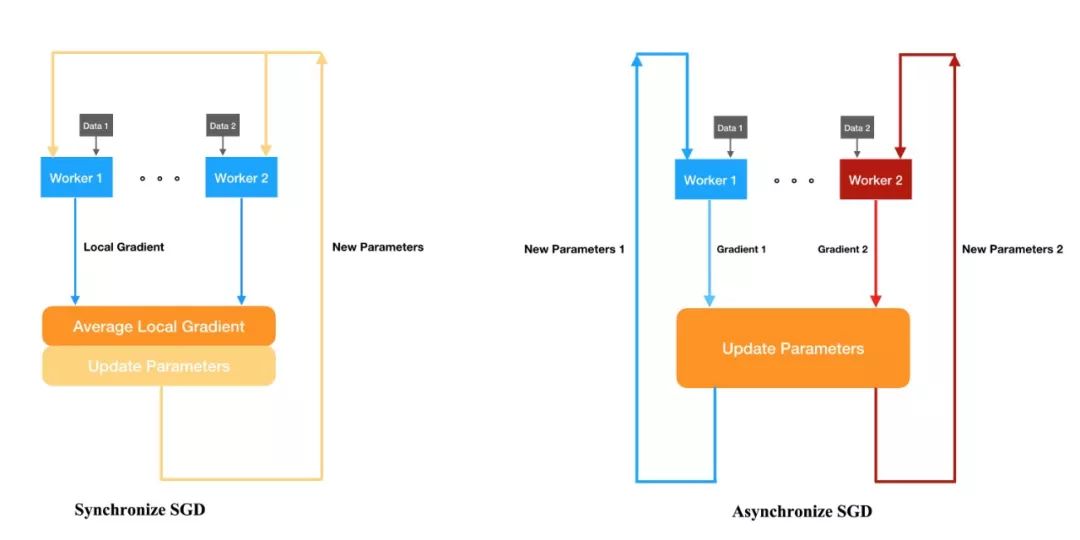
同步 SGD 与异步 SGD 的更新过程,其中同步 SGD 会等所有服务器完成计算,异步 SGD 不同的服务器会独立更新参数。
数据并行的问题在哪?
尽管数据并行是使用最广泛的方法,但它缺点也非常明显。作为一种分布式策略,数据并行需要的通信量非常大,需要在训练过程中执行阻塞通信集合来同步 DNN 梯度。在单个训练步骤中,计算和通信操作之间的次优重叠会带来通信开销,或造成数据并行分布式深度学习效率低下。
在使用 10 到 100 块 GPU/TPU 加速器的中小规模系统中,由于系统噪声和负载变化的存在,这些扩展低效可能很难检测并得到系统地优化。然而,需要注意的是,即使只是 5-10% 的扩展低效也会在大量训练步骤和训练过程中积累,从而进一步加深深度学习对环境的破坏。
数据并行实现的扩展低效在大规模系统中表现最为明显,如在 1000-10000 块芯片的加速系统中,很多分布式策略会产生大量损失。在本文中,研究者提出,超级计算机是开发和测试能实现数据并行近线性扩展的梯度缩减策略的理想系统。
将数据并行扩展到大规模的超级计算机系统也是由后者的传统负载(包括科学的数值模拟)推动的。尤其重要的是,将深度学习应用到科学模拟中来加速执行、减少算力需求,通常需要使用 DNN 来逼近长期存在的逆问题的解。在本文中,研究者通过改进梯度缩减策略展示了这一方向的第一步。
用超算测测数据并行
本文中展示的所有测量数据都是在橡树岭国家实验室的超级计算机 Summit 上得到的,它也是目前世界上计算速度排名第一的超级计算机。
Summit 系统包含 256 个机架,上面遍布 IBM Power System AC922 计算节点(总共有大约 4600 个节点),每个计算节点配有 2 个 IBM POWER9 CPU 和 6 块 NVIDIA V100 GPU。
研究者着眼于一个用于 DNN 分布式训练的数据并行方法。目前规模最大的分布式 DNN 训练是由 Kurth 等人(2018)实施的,用来在气候模拟数据上学习一个分割任务。他们使用一个修改过的 DNN 分割模型(DeepLabV3),该模型的单个 GPU 计算性能可以达到 38.45 TFLOP_16(16 指的是 float 16 精度),相当于 V100 GPU 理论峰值速度的 31%。
在下图 1 中,研究者测量了分级 allreduce 多达 1024 个 Summit 节点的扩展效率。这种次线性扩展非常明显,原因在于大型节点上的 worker 协作低效,导致通信和计算之间的重叠较差。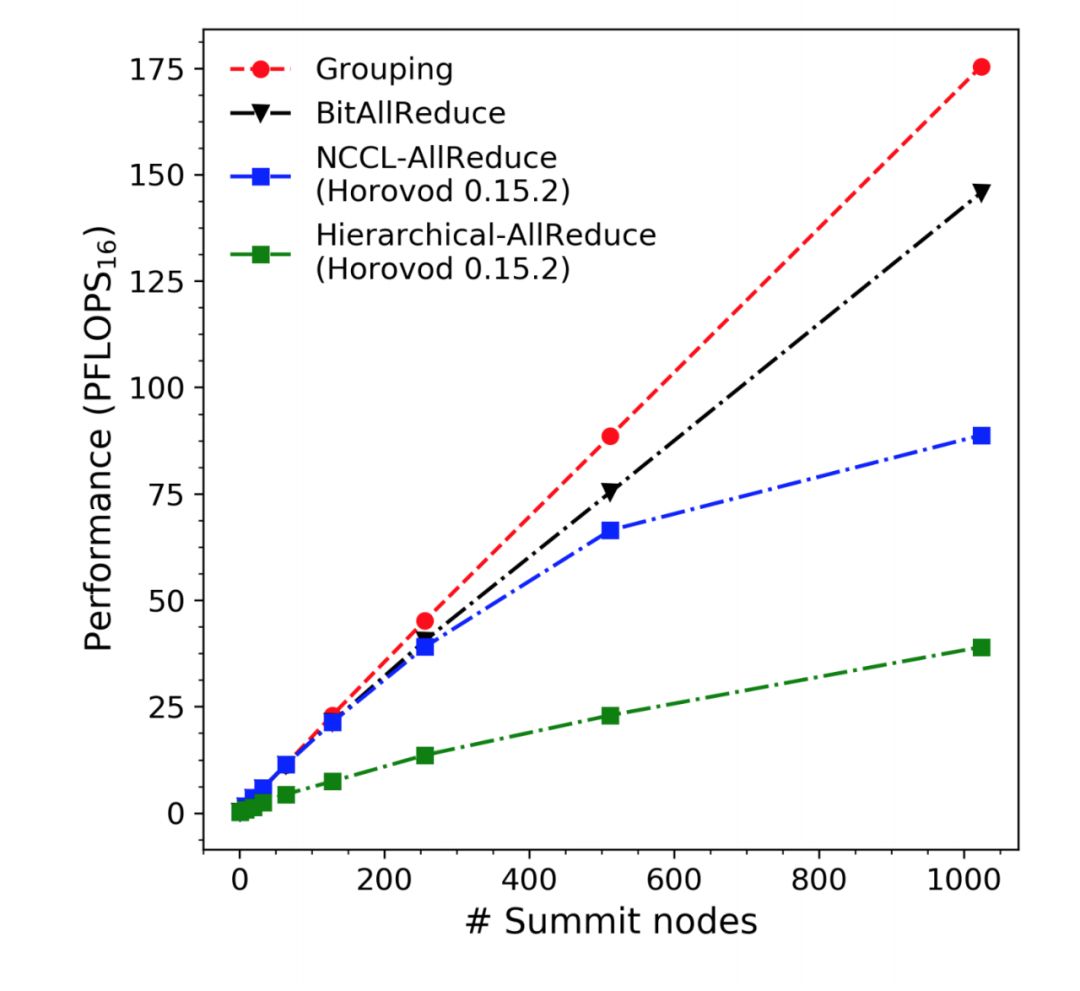
要在超算这种超大规模算力上实现近线性的扩展,那么就需要构建更好的分布式策略。研究者表示,他们主要的贡献即实现了新的梯度缩减(gradient reduction)策略,从而在计算与通信之间实现了最优的重叠,这令 GPU 扩展性能达到了新的 SOTA。
直观而言,梯度缩减策略包括(1)轻量级的服务器协调技术(BitAllReduce)、(2)梯度张量分组策略(Grouping)。这两种编排策略从不同层面提升了用 Horovod 实现的分布式深度学习性能。
BitAllReduce 和 Grouping 对 GPU 扩展效率的影响分别在图 1 中用黑线和红线显示。同时,它们带来了超过 8 倍的缩放效率(图 1、2)。这些梯度缩减策略与计算平台无关,并且不对节点的连通网络拓扑结构进行任何假设。
图 2:Horovod 时间线展示了通过编排 Bitvector Allreduce 和 Grouping 带来的提升,其中蓝色的垂直线为环(cycle)标记。
首先,Bitvector Allreduce 修正了通过集合(collective)进行梯度张量缩减的协调方式(参见图 3)。Bitvector Allreduce 的主要思想是使用缓存的元数据,并令它与每个梯度张量相关联,从而允许本地访问每个 MPI-rank,以全局地协调执行集合操作(collective operation)。从本质上讲,我们用单个集合(Bitvector 上的 MPI Allreduce)替换了 Horovod 的原始服务器策略(请参见图 3b)。
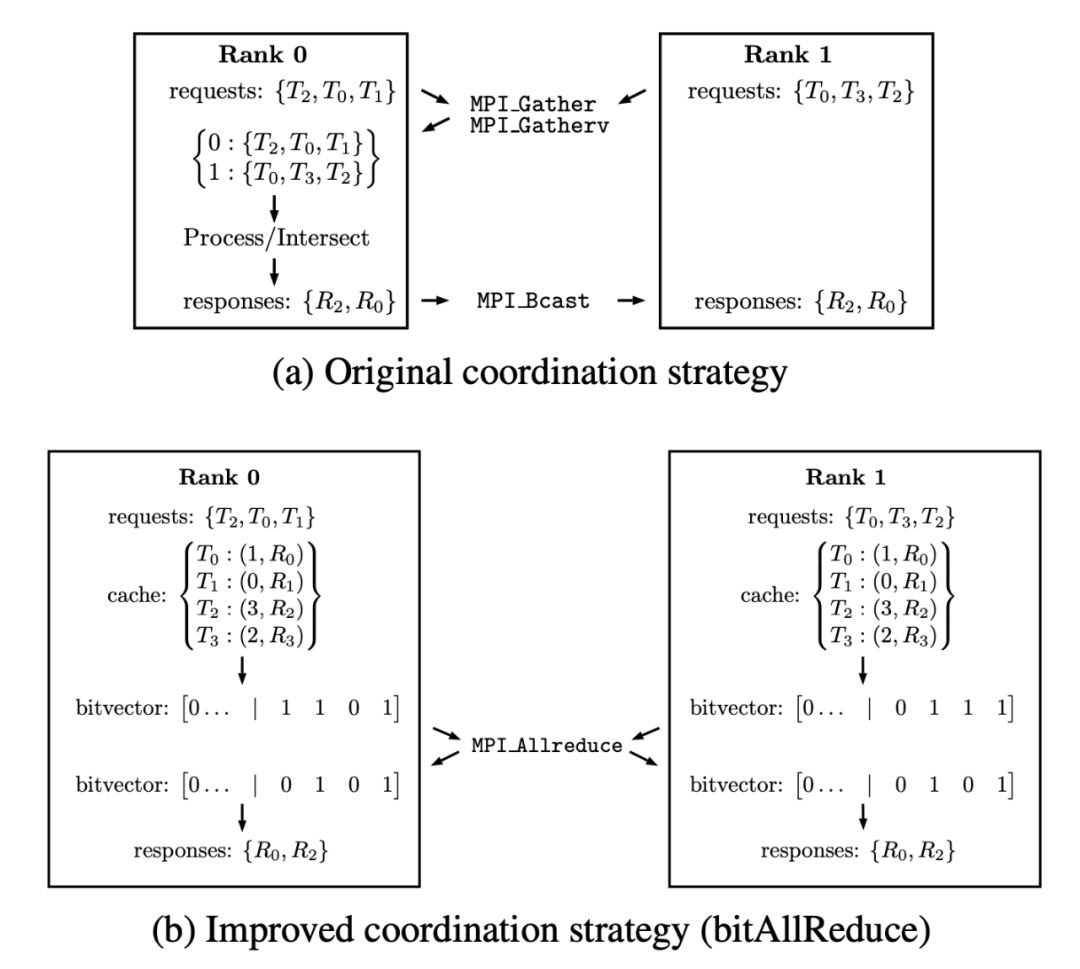
图 3:协调策略对比,3a:在原始协调策略中,Rank 0:(i) 收集请求 T_n;(ii) 确定所有等级中的通用请求;(iii) 构建关联响应 R_n; (iv) 将响应的有序列表广播到所有等级的执行过程中。3b:改进后的协调策略,每一个等级都检查响应是不是在缓存中,并相应地在 Bitvector 中的设置位。
其次,研究者引入了「分组」方案,它将梯度张量看做图着色算法。本质上来说,每一个 MPI 等级根据它的计算依赖性图对节点进行上色,其中节点就等于梯度张量。然后,我们就能根据不同的颜色将梯度张量分组(如图 4 所示)。然后,仅针对所有等级上都已经准备完全的组进行集合操作(Collective operation)。「分组」的优势之一是使用户能够灵活地以开发 DNN 模型体系结构的方式制定集合,从而实现更高的效率。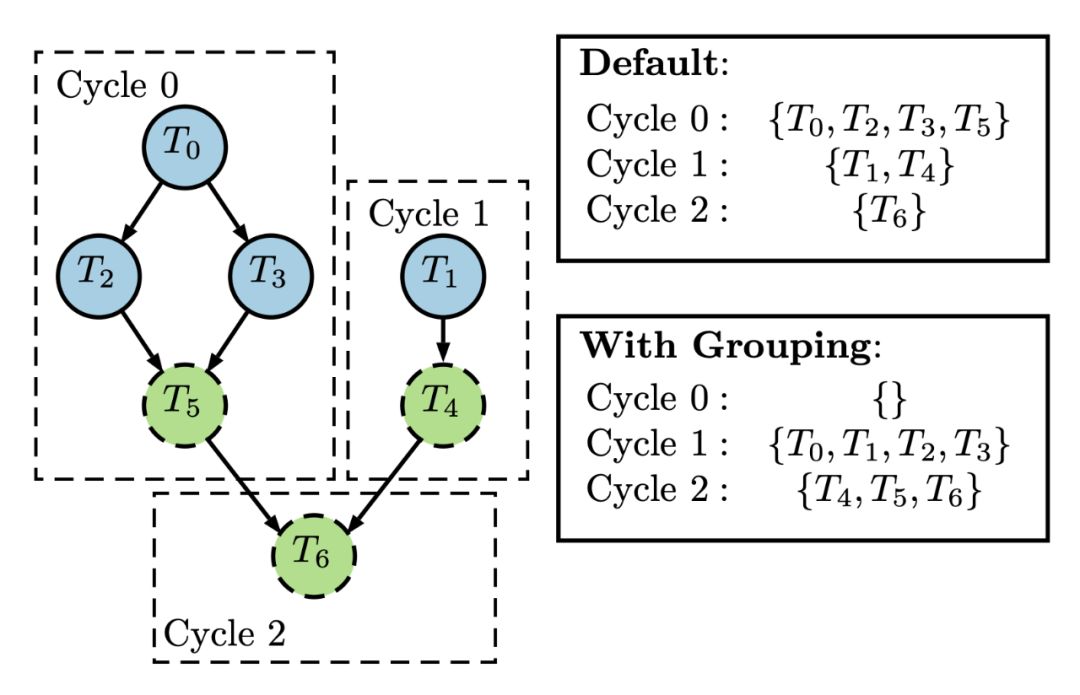
图 4:分组图示。左侧展示了由生成请求 T_n 构建的任务图,其中不同的任务为不同的节点,该任务图通过虚线框表示 Horovod 在三个子环中可见的请求。节点通过不同的颜色表示任务可以分为两组:蓝色实线的节点和绿色虚线的节点。
最后,研究者发现 Grouping 和 Bitvector Allreduce 能独立地使用,但是联合使用能获得更多的性能提升。这里只是简要介绍了梯度缩减策略的思想,更多的实现细节可以查阅原论文第四章节。
超级计算机上执行应用程序效率的一个重要指标是测得的功耗。特别是,使用 Allreduce 这样的阻塞集合,会导致在 GPU / CPU 上执行的所有操作停止,直到返回来自集合的结果。
下图 5 展示了作者使用 Bitvector Allreduce 和 Grouping 进行分布式训练时 Summit 上主要硬件组件的功耗。
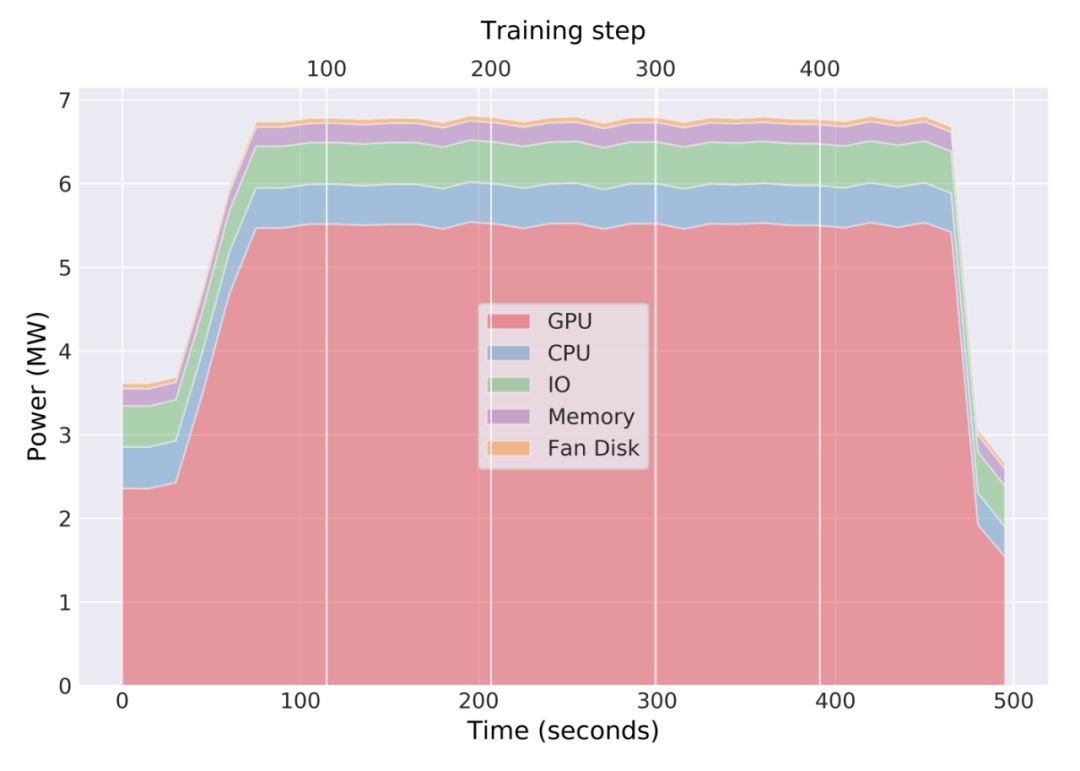
图 5:在 4600 个节点上进行分布式训练时,Summit 的功耗分析。功耗信息收集自一次分布式训练中 Summit 的主要硬件组件(GPU,CPU 等)。
除了功耗之外,作者还使用新的梯度缩减策略概述了分布式训练的计算性能。给出的性能测量均包括:(1)I / O(数据读取和模型检查点的写入),(2)DNN 正向和反向传播执行的计算,以及(3)嵌入计算图中的通信运算。
在表 1 中,作者使用前面描述的性能评估方法,总结了在单个 Summit 节点上执行应用(一个训练步)时的数学运算、时间以及整体性能。
最后,使用第 2.3 节中描述的通信策略,研究者们能够在分布式深度学习期间(图 6)在 4600 个节点上实现 0.93 的扩展效率,并达到 1.54(2)(2.15(2)))EFLOPS_16。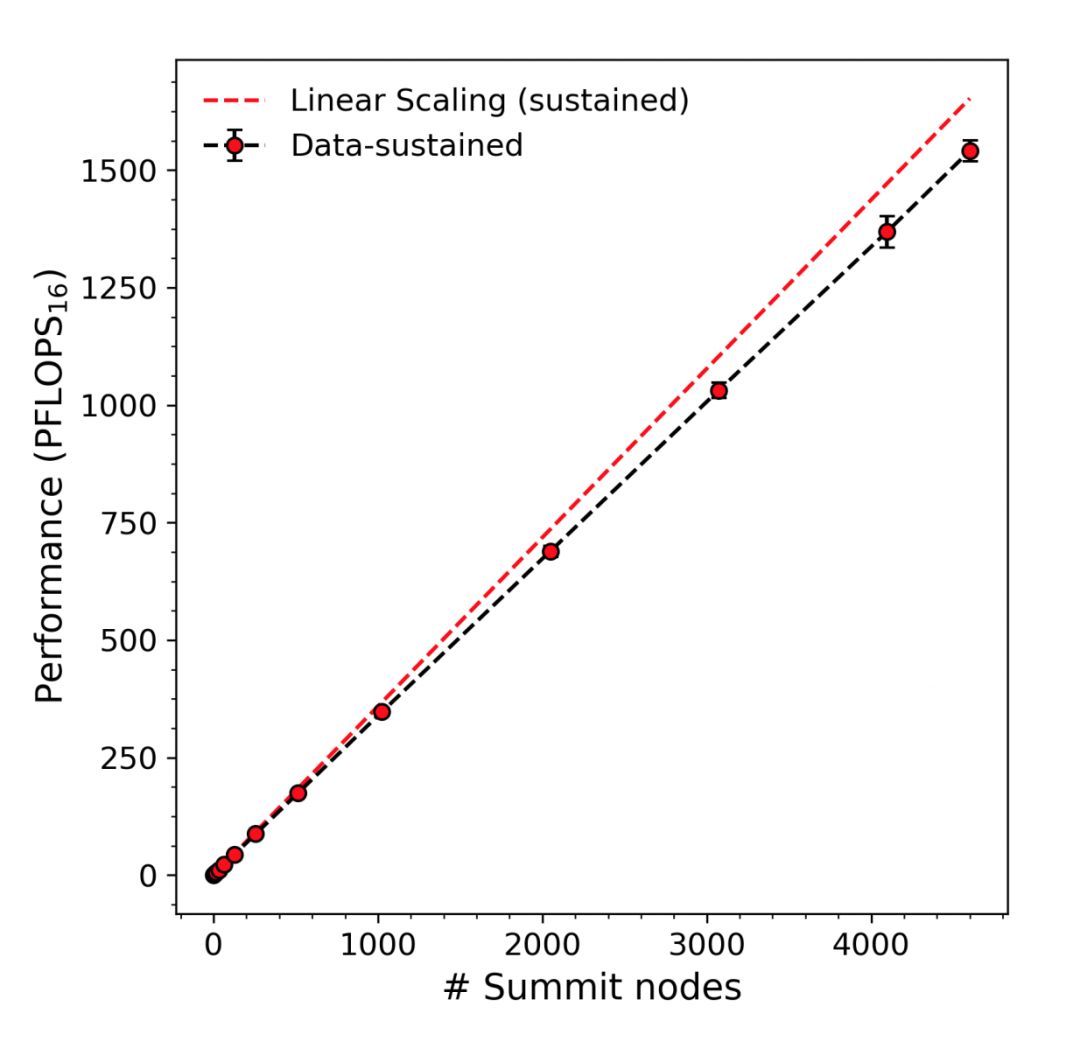
图 6:使用改进的梯度缩减策略扩展至 27,600 个 V100 GPU 时分布式深度学习的扩展效率和持续性能
想要了解更多资讯,请扫描下方二维码,关注机器学习研究会

转自:机器之心








