目前,机器学习的主流方法分为:监督学习,无监督学习和强化学习。本文作为入门,向大家介绍一下第一种方法,即监督学习(supervised learning)。
监督学习是从标记(特征和标签)的训练数据来推断一个功能的机器学习任务,它的核心同样是在训练数据集中找规律(构建模型),然后再把这个规律应用于预测未知数据的结果中去。
举个例子,给出一个训练数据集如下:
0 × 1 = 0
0 × 0 = 0
0 × (-1) = 0
0 × 1/3 = 0
0 × √2 = 0
......
观察上面给出的公式,这组数据是有标记的,其中特征是等式左边的“0×一个数(包括正整数、0、负整数、分数、无理数)”,标签是等式右边的结果“0”,从已知的这些特征和标签,我们可以推断出一个可能的规律(模型),即“0×一个实数=0”。
现在给出一个未知数据集如下,需要预测出计算结果:
0 × 2 = ?
0 × (-3) = ?
0 × 1/4 = ?
0 × √3 = ?
......
根据上面训练出的规律(模型),我们可以很容易地计算出这些未知数据的结果,也就是0。
上面这个过程,就是一个监督学习的过程,总结起来可以分为三个步骤,
① 在训练数据集中提取特征(学习),即找规律;
② 找到一个规律(模型);
③ 根据这个规律(模型)对未知数据进行预测。
常见的监督学习算法包括分类与回归,下面会配合代码实例进行介绍。在正式讲解之前,先科普一下算法的概念。
算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出。
如果一个算法有缺陷,或不适合于某个问题,执行这个算法将不会解决这个问题。不同的算法可能用不同的时间、空间或效率来完成同样的任务。一个算法的优劣可以用空间复杂度(一个算法在运行过程中临时占用存储空间大小的量度)与时间复杂度(运行时间)来衡量。
简单理解的话,算法就是把解决问题的逻辑和方法,转换成代码指令的过程。
【工具】Python 3
【数据】tushare.pro
【注】本文注重的是方法的讲解,请大家灵活掌握。
分类算法(classification algorithm),顾名思义,解决的就是分类问题,可以是二分类,也可以是多分类。
二分类(binary classification)是指有两个类别,比如判断某个生物是不是人类,结果有两个,是人类和不是人类,而多分类(multi-class classification)就是有多个类别 ,比如判断菜市场里的某一个东西,是属于蔬菜,水果还是肉。
下面就介绍监督学习中解决分类问题的一个算法,叫KNN算法(K-Nearest Neighbor),也叫K-邻近算法。它的的核心思想是,如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
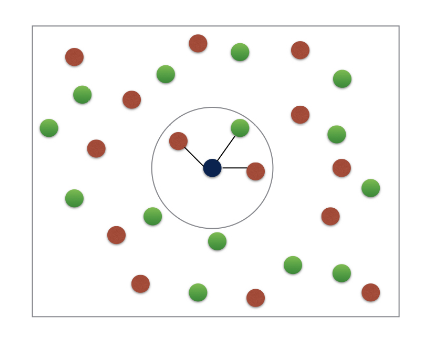
如上图,假设k=3,现在要预测中间的蓝色球是属于棕色和绿色中的哪一类,根据KNN算法,找到距离它最近的3个球,即图中用圆圈起来的3个,我们发现其中有2个是棕色(占多数),1个是绿色,所以得出结论,它应该属于棕色球那一类。

同理,当k=5的时候,得出的结论是,它应该属于绿色球那一类。
这里我们在找最邻近的点时,是用肉眼观察得到的,如果用数学公式表示,就是计算两点间的距离,然后找出值最小的k个,以二维坐标为例,公式如下:
我们可以导入sklearn.neighbors模块中KNN类实现该算法,先利用训练集数据构建模型,再用测试集数据进行预测。
关于划分训练集和测试集的内容,已经在文章《机器学习必备技能之“数据预处理”》中进行了介绍,感兴趣的小伙伴可以再温习一下。
import tushare as ts
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
pd.set_option("expand_frame_repr", False)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
ts.set_token('your token')
pro = ts.pro_api()
df = ts.pro_bar(ts_code='000002.SZ', adj='qfq', start_date='20190101', end_date='20190930')
df.sort_values('trade_date', inplace=True)
df['trade_date'] = pd.to_datetime(df['trade_date'])
df.set_index('trade_date', inplace=True)
df = df[['close']]
print(df.head())
close
trade_date
2019-01-02 22.97
2019-01-03 23.14
2019-01-04 23.97
2019-01-07 24.08
2019-01-08 24.03
df['1d_future_close'] = df['close'].shift(-1)
df['1d_close_future_pct'] = df['1d_future_close'].pct_change(1)
df['1d_close_pct'] = df['close'].pct_change(1)
df['ma5'] = df['close'].rolling(5).mean()
df['ma5_close_pct'] = df['ma5'].pct_change(1)
df.dropna(inplace=True)
feature_names = ['当前涨跌幅方向', 'ma5当前涨跌幅方向']
df.loc[df['1d_close_future_pct'] > 0, '未来1d涨跌幅方向'] = '上涨'
df.loc[df['1d_close_future_pct'] <= 0, '未来1d涨跌幅方向'] = '下跌'
df.loc[df['1d_close_pct'] > 0, '当前涨跌幅方向'] = 1
df.loc[df['1d_close_pct'] <= 0, '当前涨跌幅方向'] = 0
df.loc[df['ma5_close_pct'] > 0, 'ma5当前涨跌幅方向'] = 1
df.loc[df['ma5_close_pct'] <= 0, 'ma5当前涨跌幅方向'] = 0
feature_and_target_cols = ['未来1d涨跌幅方向'] + feature_names
df = df[feature_and_target_cols]
print(df.head())
未来1d涨跌幅方向 当前涨跌幅方向 ma5当前涨跌幅方向
trade_date
2019-01-09 下跌 1.0 1.0
2019-01-10 上涨 0.0 1.0
2019-01-11 下跌 1.0 1.0
2019-01-14 上涨 0.0 0.0
2019-01-15 上涨 1.0
1.0
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
y = df['未来1d涨跌幅方向'].values
X = df.drop('未来1d涨跌幅方向', axis=1).values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
knn = KNeighborsClassifier(n_neighbors=6)
knn.fit(X_train, y_train)
new_prediction = knn.predict(X_test)
print("Prediction: {}".format(new_prediction))
print(knn.score(X_test, y_test))
Prediction: ['上涨' '下跌' '上涨' '上涨' '上涨' '上涨' '上涨' '上涨' '下跌' '上涨' '上涨' '上涨' '上涨' '上涨'
'上涨' '上涨' '上涨' '上涨' '上涨' '上涨' '上涨' '上涨' '上涨' '上涨' '下跌' '下跌' '下跌' '上涨'
'上涨'
'上涨' '上涨' '上涨' '下跌' '上涨' '下跌' '上涨']
0.5555555555555556
上面的示例中用的是k=6,我们也可以尝试选取不同的k,再来看看预测的效果。
import numpy as np
neighbors = np.arange(1, 15)
train_accuracy = np.empty(len(neighbors))
test_accuracy = np.empty(len(neighbors))
for i, k in enumerate(neighbors):
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
train_accuracy[i] = knn.score(X_train, y_train)
test_accuracy[i] = knn.score(X_test, y_test)
print(train_accuracy)
print(test_accuracy)
plt.title('k-NN: Varying Number of Neighbors')
plt.plot(neighbors, test_accuracy, label='测试集预测准确度')
plt.plot(neighbors, train_accuracy, label='训练集预测准确度')
plt.legend()
plt.xlabel('k的取值')
plt.ylabel('准确度')
plt.show()
[0.46099291 0.4751773 0.53900709 0.4964539 0.4964539 0.4964539
0.53900709 0.53900709 0.53900709 0.53900709 0.53900709
0.53900709
0.53900709 0.53900709]
[0.36111111 0.47222222 0.63888889 0.55555556 0.55555556 0.55555556
0.63888889 0.63888889 0.63888889 0.63888889 0.63888889 0.63888889
0.63888889 0.63888889]
另一类监督学习的算法是回归(regression),适用于当预测值为连续值的情况,比如预测股票的价格。
有关线性回归的内容,在文章《数据科学必备基础之线性回归》中已经介绍得很详细了,这里就简单回顾一下,本文会拓展一些新的内容,包括K折交叉验证法和正则化的线性回归:Lasso回归和岭回归。
首先,从tushare.pro导入数据,并做一些数据探索EDA(Exploratory Data Analysis)工作。
# 导入沪深300指数、平安银行的日线涨跌幅数据
hs300 = pro.index_daily(ts_code='399300.SZ', start_date='20190101', end_date='20190930')[['trade_date', 'pct_chg']]
df_000001 = ts.pro_bar(ts_code='000001.SZ', adj='qfq', start_date='20190101', end_date='20190930')[['trade_date', 'pct_chg']]
df = pd.merge(hs300, df_000001, how='left', on='trade_date', sort=True, suffixes=['_hs300', '_000001'])
df.iloc[:, 1:] = df.iloc[:, 1:] / 100
df['trade_date'] = pd.to_datetime(df['trade_date'])
df.set_index('trade_date', inplace=True)
print(df.head())
print(df.info())
pct_chg_hs300 pct_chg_000001
trade_date
2019-01-02 -0.013658 -0.0205
2019-01-03 -0.001580 0.0099
2019-01-04 0.023958 0.0512
2019-01-07 0.006070 -0.0010
2019-01-08 -0.002161 -0.0083
'pandas.core.frame.DataFrame'>
DatetimeIndex: 183 entries, 2019-01
-02 to 2019-09-30
Data columns (total 2 columns):
pct_chg_hs300 183 non-null float64
pct_chg_000001 183 non-null float64
dtypes: float64(2)
memory usage: 4.3 KB
None
# 画图:查看相关性
plt.figure()
sns.heatmap(df.corr(), annot=True, square=True, cmap='RdYlGn')
plt.show()
从sklearn.linear_model模块调用LinearRegression类做线性回归。
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
import numpy as np
y = df['pct_chg_hs300'].values
X = df['pct_chg_000001'].values
print("转换前y的维度: {}".format(y.shape))
print("转换前X的维度: {}".format(X.shape))
y = y.reshape(-1, 1)
X = X.reshape(-1, 1)
print("转换后y的维度: {}".format(y.shape))
print("转换后X的维度: {}".format(X.shape))
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
reg_all = LinearRegression()
reg_all.fit(X_train, y_train)
y_pred = reg_all.predict(X_test)
print("R^2: {}".format(reg_all.score(X_test, y_test)))
pct_chg_hs300 pct_chg_000001
trade_date
2019-01-02 -0.013658 -0.0205
2019-01-03 -0.001580 0.0099
2019-01-04 0.023958 0.0512
2019-01-07 0.006070 -0.0010
2019-01-08 -0.002161 -0.0083
转换前y的维度: (183,)
转换前X的维度: (183,)
转换后y的维度: (183, 1)
转换后X的维度: (183, 1)
R^2: 0.617019402603039
决定系数R^2是线性回归算法的评价指标,它
是回归平方和与总离差平方和的比值,表示总离差平方和中可以由回归平方和解释的比例。R^2的值介于0-1之间,越接近1,则说明回归拟合效果越好,数学公式如下:
上例中计算出的R^2约等于0.6,是通过划分一次训练集和测试集进行回归得到的评价结果,但这里有一个值得思考的问题是,单次的评价结果不够可靠,因此,下面介绍一个交叉验证的方法:K折交叉验证法。
该方法的原理是,把数据集平均分成k份,每次用其中的一份1/k作为测试集,剩下的部分作为训练集,按照顺序遍历,直到全部数据都覆盖到为止,如下图所示:
每次划分出的训练集和测试集都计算一个R^2,一共有k个R^2,取它们的平均值作为最终的评价指标,这样得到的结果更具有代表性。
可以通过调用sklearn.model_selection模块中的cross_val_score方法实现这一功能。
from sklearn.model_selection import cross_val_score
reg = LinearRegression()
cv_scores = cross_val_score(reg, X, y, cv=5)
print(cv_scores)
print("Average 5-Fold CV Score: {}".format(np.mean(cv_scores)))
[ 0.65150783 0.68547646 0.70675209 0.47252459 -0.19022462]
Average 5-Fold CV Score: 0.4652072684893508
首先,我们要明确的是,正则化(regularization)的目的是防止模型过拟合。
回到文章最开头的例子,我们找到的规律是“0×一个实数=0”,如果过拟合的话,极端情况下,只有当未知数据和已知数据完全一样的时候,才能得到正确解,比如出现0×1,可以得到结果0,但是给出0×2,就不会算了。而正则化的作用,就是为了解决这类问题。
明确了正则化的目的,它的概念就会容易理解一些,简单来说,正则化就是通过“某种手段”,解决模型过拟合问题的过程。这里的“某种手段”具体是什么,下面会通过实例进行介绍,至于为什么这个概念的名字叫正则化,大家就不要过分纠结啦。
在文章《机器学习必备技能之“统计思维2.0”》中我们介绍过最小二乘法OLS的优化思路,本质是最小化“预测值和真实值之间误差的平方和”(引号里的内容是一个损失函数),也即最小化损失函数(loss function)。
正则化就是在最小化损失函数公式中添加一个系数惩罚项,这个系数惩罚项可以理解为一个约束条件,目的是防止模型过拟合。
还是回到文章最开始的那个例子,我们希望通过添加系数惩罚项,让过拟合的规律0×1=0更具有普遍性,变成“0×一个实数=0”。
为了达到上述目的,可以使用不同的正则化方法,即添加不同的系数惩罚项,下面我们就介绍两个正则化的线性回归:岭回归和Lasso回归。
岭回归,也叫L2正则化,它的损失函数的数学公式如下:
当惩罚项展开公式中的常数项α=0时,问题则变为求解普通最小二乘法。
岭回归的原理是通过使回归系数变小,解决过拟合问题。以含有两个特征为例,图示如下,有约束条件的最优解一般是在切点,可以看到,图中的切点位置在未惩罚的最小值X的左下方,加入惩罚项后,两个系数都有所缩小。
# 从tushare.pro导入数据(过程省略)
print(df.head())
print(df.info())
pct_chg_hs300 pct_chg_000001 pct_chg_000002
trade_date
20190102 -0.013658 -0.0205 0.0031
20190103 -0.001580 0.0099 0.0074
20190104 0.023958 0.0512 0.0359
20190107 0.006070 -0.0010 0.0046
20190108 -0.002161 -0.0083 -0.0021
'pandas.core.frame.DataFrame'>
Index: 183 entries, 20190102 to 20190930
Data columns (total 3 columns):
pct_chg_hs300 183 non-null float64
pct_chg_000001 183 non-null float64
pct_chg_000002 183 non-null float64
dtypes: float64(3)
memory usage: 5.7+ KB
None
#
from sklearn.linear_model import LinearRegression
reg_all = LinearRegression()
reg_all.fit(X, y)
linear_coef = reg_all.coef_
print
("OLS回归系数:", linear_coef)
OLS回归系数: [[0.35175507 0.26499475]]
#
from sklearn.linear_model import Ridge
# 创建特征和标签
y = df[['pct_chg_hs300']].values
X = df[['pct_chg_000001', 'pct_chg_000002']].values
# 创建ridge回归模型
ridge = Ridge(alpha=0.4, normalize=True)
ridge.fit(X, y)
# 计算系数
ridge_coef = ridge.coef_
print("岭回归系数:", ridge_coef)
岭回归系数: [[0.26394455 0.23546054]]
Lasso回归,也叫L1正则化,它的损失函数的数学公式如下:
Lasso回归的原理是通过使一些回归系数等于0,解决过拟合问题。同样以含有两个特征为例,切点位置落在特征2轴上,此时特征1的回归系数等于0,这样也实现了特征选择,删去了一些不重要的特征。
from sklearn.linear_model import Lasso
lasso = Lasso(alpha=0.4, normalize=True)
lasso.fit(X, y)
lasso_coef = lasso.coef_
print("Lasso回归系数:", lasso_coef)
Lasso回归系数: [0. 0.]
03
总结
本文作为机器学习算法的入门篇,介绍了什么是监督学习,以及常见的两种监督学习算法,即分类与回归。在分类算法中,重点介绍了KNN算法,在回归算法中,则重点介绍了K折交叉验证法,以及正则化的线性回归,包括岭回归和Lasso回归。
对本文Python源代码有兴趣的同学,请在公众号发送消息关键字“监督学习1”获得下载地址。










