后台回复【入门资料】
送你十本Python电子书

文 | 杨英明
推荐 | 编程派公众号
微信号:codingpy
上一节,我在一个Django项目中集成了 基于WeRoBot的微信公众号后台,成功与服务器完成了对接,并且可以对用户的任意消息做出响应(回复一个“hello”),简单来说,就是搭建起了一个开发框架。
这一节中,我将继续用 WeRoBot 在这个开发框架上扩展一些功能,让公众号的交互丰富起来,思来想去,我挑了三个相对简单的功能进行实现:简单的聊天功能,天气查询,讲笑话。
下面是实现这三个功能的过程和心得记录,分享给大家。
简单的聊天机器人
原理:文本匹配
WeRoBot 也有微信机器人的意思,你可以使用它定制公众号的响应。
WeRoBot中有这么一个消息处理函数
@robot.text
def echo(message):
return message.content
他只能响应用户发送过来的 文本消息。
文本消息存储在参数 message 变量中,我们可以通过 msg=message.content 取出用户发过来的消息的文本。
(详情见官方文档:WeRoBot官方文档)
而通过对消息文本 msg进行匹配,我们可以为公众号加入简单的聊天功能。
机器人代码如下:
@robot.text
def echo(message):
try:
# 提取消息
msg = message.content.strip().lower().encode('utf8')
# 解析消息
if re.compile(".*?你好.*?").match(msg) or\
re.compile(".*?嗨.*?").match(msg) or\
re.compile(".*?哈喽.*?").match(msg) or\
re.compile(".*?hello.*?").match(msg) or\
re.compile(".*?hi.*?").match(msg) or\
re.compile(".*?who are you.*?"
).match(msg) or\
re.compile(".*?你是谁.*?").match(msg) or\
re.compile(".*?你的名字.*?").match(msg) or\
re.compile(".*?什么名字.*?").match(msg) :
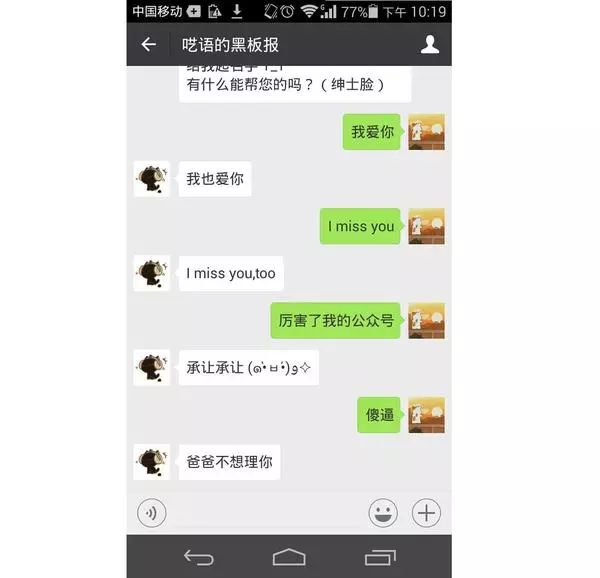
return "你好~\n我是呓语的管家机器人,主人还没给我起名字 T_T\n有什么能帮您的吗?(绅士脸)"
elif re.compile(
".*?厉害.*?").match(msg):
return '承让承让 (๑•̀ㅂ•́)ﻭ✧'
elif re.compile(".*?想你.*?").match(msg):
return '我也想你'
elif re.compile(".*?miss you.*?").match(msg):
return 'I miss you,too'
elif re.compile(".*?我爱你.*?").match(
msg):
return '我也爱你'
elif re.compile(".*?love you.*?").match(msg):
return 'I love you,too'
elif re.compile(".*?美女.*?").match(msg):
return '我是男生哦♂'
elif re.compile(".*?帅哥.*?").match(msg):
return '谢谢夸奖 (๑•̀ㅂ•́)ﻭ✧'
elif re.compile(".*?傻逼.*?").match(msg):
return '爸爸不想理你'
except Exception as e:
print e
运行效果:
“天气查询” 功能实现
原理:封装城市解析接口,调用百度天气API
要实现天气查询功能其实比较简单,网上不少现成的API,不过到底选哪一家的API是个值得商榷的问题,因为我们选取的API最好要 稳定、信息丰富、免费、准确。
接口的稳定性毋庸置疑,如果用着用着接口提供方突然不提供服务,你还要临时换接口,维护成本高。
使用的天气接口最好能提供比较丰富的天气信息,比如最高温、最低温、实时温度、未来X天的温度、PM2.5值、风力风向、天气情况等等,这样展示给用户的信息会比较全面。
免费更不用说,刚开始维护公众号能找到免费的优质服务就不掏腰包,毕竟够用就行。
接口提供的天气信息一定要准确,如果信息不准确,这个服务也就没有了价值。
秉承着以上原则筛选网上的天气API,下面分享几个我尝试过的:
中国天气网的API是中国气象局提供的,应该是最官方的,但是用起来有各种问题,提供的天气信息也不够丰富,不推荐使用。
心知天气 专业提供天气服务的公司,网站界面高大上,文档详细,服务稳定,使用舒服,唯一的缺点是免费版只提供全国地级市的天气查询,像我们这儿一个小小县城就没法查询 _(:3」∠)_。
百度天气API,目前在使用的,以上条件基本都符合,稳定性待观察,刚开始用。需要申请AccessKey,我直接用了一个博客上分享的(因为自己的ak使用有问题,无法正确请求到天气信息,论坛上很多人反映这个问题),博客链接见:百度天气接口api - 简书。【来自后期的提示:该AK已过期】
顺便贴上知乎上关于天气API的讨论:网上的天气 API 哪一个更加可靠?
我封装了“解析消息中包含的城市”接口,由于代码太长,就不在这里帖出来了,感兴趣的,可以在浏览器中输入这段url 或者直接点击尝试:
http://www.yangyingming.com/api/parse_city/?msg=蒋介石预见到中央红军的意图,在红军前往湘西的必经之路上集结大量兵力组成四道封锁线。10月21日晚,中央红军在赣县王母渡至信丰县一带突破国民革命军第一道封锁线,25日全部渡过信丰河,携大量辎重沿粤赣、湘粤、湘桂边缓慢西行。1934年11月5日至8日,突破了广东城口与湖南汝城之间的第二道封锁线。13日至15日,在郴县、良田、宜章、乐昌之间突破第三道封锁线。25日,中央红军决定从兴安、全州之间西渡湘江。中央红军面对国民革命军全面进攻,于1934年11月27日至12月1日历时5天,从广西兴安县至全州县间,才渡过湘江,突破第四道封锁线。湘江战役之后,出发时的八万余中央红军仅剩下3万余人。
它会返回msg参数中包含的所有城市名称。
我将它集成到了天气查询功能中,使其显得更加智能。
下面是天气查询的代码:
#coding=utf8
from werobot import WeRoBot
from werobot.replies import WeChatReply, TextReply, ImageReply, MusicReply
import re
import urllib,urllib2
import logging
import json
timeout
=30 # 超时时间
bdkey = 'FK9mkfdQsloEngodbFl4FeY3' # 百度天气ak
def get_citys_in_msg(msg):
# 获取消息中包含的城市
api_url = 'http://www.yangyingming.com/api/parse_city?%s'%(urllib.urlencode({'msg':msg}))
citys = get_html(api_url,timeout=timeout)
return citys
def get_weather(city):
# 获取天气数据
url = 'http://api.map.baidu.com/telematics/v3/weather'
param = urllib.urlencode({
'location':city,
'ak':bdkey,
'output':'json',
})
api_url = '%s?%s'%(url,param)
wdata = get_html(api_url
,timeout=timeout)
return wdata
@robot.text
def echo(message):
if re.compile(".*?天气.*?").match(msg):
res_msg = ''
# 取出该消息中包含的所有城市
citys = get_citys_in_msg(msg).split(',')
# 获得每一座城市的天气状况
if citys[0]=='':
return '亲爱的,你想知道哪座城市的天气呢?'
else:
for city in citys:
if res_msg!='':
res_msg += '\n\n'
wdata = get_weather(city)
wdata = json.loads(wdata)
if wdata['status']=='success':
index = wdata['results'][0]['index']
pm25 = wdata['results'][0]['pm25']
w = wdata['results'][0]['weather_data']
today = w[0]
future = w[1:] # 未来几天的预报
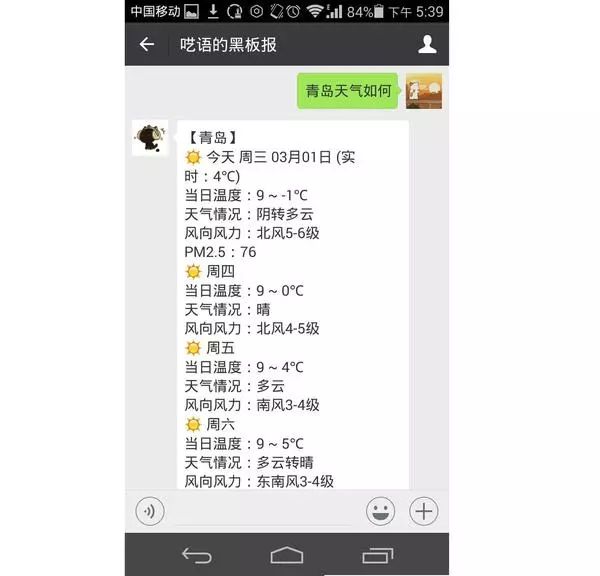
res_msg += '【%s】\n☀ 今天 %s\n当日温度:%s\n天气情况:%s\n风向风力:%s\nPM2.5:%s'%\
(city,today['date'].encode('utf8'),today['temperature'].encode('utf8'),today['weather'].encode('utf8'),today['wind'].encode('utf8'),pm25.encode('utf8'))
for today in future:
res_msg += '\n☀ %s\n当日温度:%s\n天气情况:%s\n风向风力:%s'
%\
(today['date'].encode('utf8'),today['temperature'].encode('utf8'),today['weather'].encode('utf8'),today['wind'].encode('utf8'))
res_msg += '\n【温馨提示】'
for i in index:
res_msg += '\n❤ %s:%s\n%s'%\
(i
['tipt'].encode('utf8'),i['zs'].encode('utf8'),i['des'].encode('utf8'))
else:
res_msg += '没有找到%s的天气信息'%city
return res_msg
运行效果:
“讲个段子” 功能实现
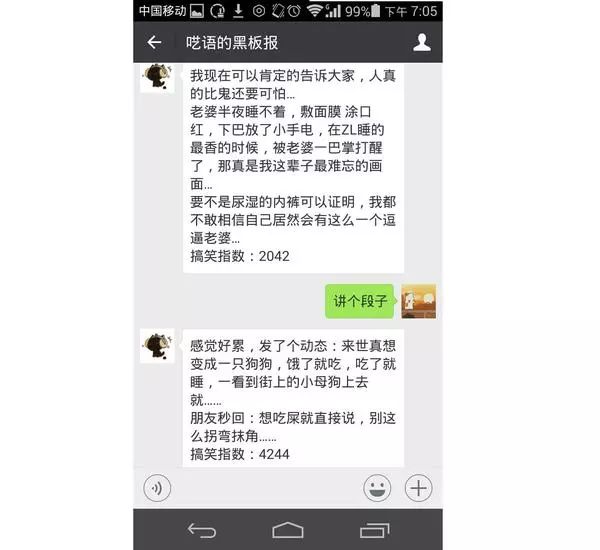
“讲个段子”应用场景是这样的:在你烦心的时候,在公众号中输入“xxx,讲个段子”,它便会机智的回复一个段子给你,让你在愁眉紧锁之余也能轻松一下。
实现这个功能大体需要两个步骤:接口实现 和 微信后台调用逻辑。
和天气查询不同,我打算自己实现这个接口,原理是编写一个脚本定期抓取糗事百科上的段子,存储在服务器的数据库中,再编写接口函数,用于从数据库中随机抽取段子并返回。
以下是实现这个功能的步骤:
1、创建数据库表
作用:在数据库(mysql)中创建用于存储段子的表
create table `qiushi_joke`
(
`id` int(11) NOT NULL AUTO_INCREMENT PRIMARY KEY,
`username` varchar(128) NOT NULL,
`content` varchar(1024) NOT NULL,
`laugh_num` int(11) NOT NULL,
`comment_num` int(11) NOT NULL,
`imgurl` varchar(255) DEFAULT NULL
) DEFAULT CHARSET=utf8;
2、编写段子抓取脚本
作用:抓取糗事百科官网“文本”栏目下所有页面的段子,存储在数据库中(只存储之前没出现过的段子,避免重复)。
#coding=utf-8
import urllib
import urllib2
import re
import MySQLdb
import time
timeout=5 # 超时时间
host = 'http://www.qiushibaike.com' # 糗事百科主页面
target = 'text'
# 糗事百科的"文字"栏目
min_laugh_num = 500 # 好笑数低于该值,不保留
min_joke_num = 10 # 一次性最少抓到的笑话个数
# 数据库设置
username = 'YOUR_USERNAME' # 你的数据库用户名
password = 'YOUR_PASSWORD' # 你的数据库密码
dbname = 'YOUR_DB' # 你创建的表所在的数据库
dbport = 3306
def get_html(url,timeout=None
):
# 获取指定url的html源码
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6' }
request = urllib2.Request(url,headers=headers)
response = urllib2.urlopen(request,timeout=timeout)
except urllib2.HTTPError,e:
time.
sleep(2)
print e
raise Exception,'[Error] 遇到HTTP 503 错误,程序休眠了一下……'
except Exception,e:
raise Exception,'[Error] get_html()获取源码失败\n%s'%e
return response.read()
def getPagesum():
# 获取总页数
try:
url = '%s/%s'%(host,target)
html = get_html(url,timeout)
pattern = re.compile(r'(.*?).*?.*?
items = re.findall(pattern,html)
except Exception,e:
raise Exception,'[Error] getPagesum()获取总页数失败\n%s'%e
return int(items[-1])
def connectMySQL():
# 连接mysql数据库
conn = MySQLdb.connect(
host='localhost',
port=dbport,
user=username,
passwd=password,
db=dbname,
charset='utf8',
)
return conn
def getJokes():
# 抓取糗事百科的段子
# 获取总页数
print '开始抓取……'
try:
pagesum = getPagesum()
except Exception,e:
print e
return []
joke_list = []
# 开始爬取
for page in range(1,pagesum+1):
print '当前页数:',page
url = '%s/%s/page/%d/'%(host,target,page)
try:
html = get_html(
url,timeout)
except Exception,e:
print e
print '抓取出错,跳过第%s页'%page
continue
print '正在匹配……'
pattern = re.compile('.*?(.*?)
.*?.*?(.*?).*?
(.*?)(.*?).*?(.*?)',re.S)
items = re.findall(pattern,html)
# 匹配到段子
for item in items:
joke = {}
joke['username'] = item[0].strip()
joke['content'] = item[1].strip().replace('
','\n').replace('"','\"')
joke['imgsrc']
= re.findall(',item[2])
if len(joke['imgsrc'])==0:
joke['imgsrc'] = ''
joke['laugh_num']= int(item[3].strip())
joke['comment_num'] = int(item[4].strip())
info = '用户名:%s\n内容:\n%s\n图片地址:%s\n好笑数:%d\n评论数:%d\n'%\
( joke['username'] , joke['content'] , joke['imgsrc'] , joke['laugh_num'] , joke['comment_num'] )
if joke['imgsrc']=='' and joke['laugh_num'] > min_laugh_num:
print len(joke_list)
print info
joke_list.append(joke)
return joke_list
def save2mysql(joke_list):
# 将抓取的段子存入数据库
conn = connectMySQL()
cur = conn.cursor()
for i,joke in enumerate(joke_list):
print
'正在插入第%d条段子……'%(i+1)
sql = 'select 1 from qiushi_joke where content = "%s" limit 1; '%(joke['content'])
isExist = cur.execute(sql)
if isExist==1:
print '-> 该段子已存在于数据库!放弃插入!'
else:
sql = 'insert into qiushi_joke (`username`,`content`,`laugh_num`,`comment_num`,`imgurl`) values ("%s","%s","%d",
"%d","%s")'%\
(
joke['username'] , joke['content'] , joke['laugh_num'] , joke['comment_num'] , joke['imgsrc'] )
cur.execute(sql)
print '正在提交以上所有操作……'
conn.commit()
cur.close()
conn.close()
def main():
# 主程序
try:
while True:
joke_list = getJokes()
if len(joke_list)>=min_joke_num: # 抓取到至少min_joke_num条笑话才行
break
time.sleep(2)
save2mysql(joke_list)
except
Exception,e:
print e
if __name__=='__main__':
main()
运行效果:
3、cron定期运行脚本
作用:定期抓取优质段子,存入数据库
步骤:
在命令行中运行
crontab-e
在编辑页面加入新的计划任务
*/10 * * * * /root/workspace/BLOG_VENV/bin/
python/root/workspace/crawler/craw_jokes.py
这里解释一下上面这条命令的意思:
*/10 * * * * ----> 代表每10分钟执行一次后面的命令。五个“*”分别代表“分 时 日 月 周”,如果在第一个“*”后面加上除号/和一个数字N,代表每N分钟执行一次后面的命令。以上是crontab计划任务时间控制的格式。
/root/workspace/BLOG_VENV/bin/python ----> 这个是我的python解释器的地址
/root/workspace/crawler/craw_jokes.py ----> 这是我们上一节所写的脚本的存放地址
以上命令合起来就是:每十分钟抓取糗事百科,将优质段子存入数据库。
好了,段子我们有了,接下来我们只要写一个接口函数,每次调用便从数据库中随机取出一条段子,并以json的格式返回(json是一种表示和存储数据的形式,和字典类似)。
4、接口函数实现
作用:每次调用,从数据库中随机取出一条段子,以json的格式返回。
前言:代码集成在django中,不想在django中使用的可以适当修改代码。
代码:
from django.http import HttpResponse
import MySQLdb
import random
import json
# 公共部分
# 数据库设置
username = 'YOUR_USERNAME' # 你的数据库用户名
password = 'YOUR_PASSWORD' # 你的数据库密码
dbname = 'YOUR_DB' # 你创建的表所在的数据库
dbport = 3306
# 数据库连接函数
def connectMySQL():
# 连接mysql数据库
conn = MySQLdb.
connect(
host='localhost',
port=dbport,
user=username,
passwd=password,
db=dbname,
charset='utf8',
)
return conn
# 接口部分
# 返回一条糗事百科上的段子
def get_joke(
request):
response = ''
try:
# 连接数据库
conn = connectMySQL()
cur = conn.cursor()
# 生成随机抓取id
sql = 'select count(*) from qiushi_joke'
cur.execute(sql)
joke_sum = cur.fetchone()[0]
joke_idx = random.randint(1,joke_sum)
# 抓取该id的段子数据
sql = 'select * from qiushi_joke where id=%d'%joke_idx
cur.execute(sql)
joke = {}
joke['id'],joke['username'],joke['content'],joke['laugh_num'],joke['comment_num'],joke['imgurl']
= cur.fetchone()
response = json.dumps(joke,ensure_ascii=False)
# 关闭数据库连接
cur.close()
conn.close()
except Exception as e:
print e
return HttpResponse(response)
前端接口封装好之后,可以在浏览器中输入以下url测试这个接口:
http://www.yangyingming.com/api/get_joke/
每次刷新都会返回不同的段子。
5、集成在微信机器人中
作用:将“讲个段子”功能集成到微信机器人的聊天功能中,用户在聊天窗口发送“讲个段子”类似的消息时,随机回复一条段子。
代码:
@robot.text
def echo(message):
if re.compile(".*?笑话.*?").match(msg) or\
re.compile(".*?段子.*?").match(msg):
apiurl = "http://www.yangyingming.com/api/get_joke"
response = get_html(apiurl,timeout
=timeout)
joke = json.loads(response)
return '%s\n搞笑指数:%d'%(joke['content'].encode('utf8'),joke['laugh_num'])
运行效果:
以上,就是我的微信公众号开发中 简单的聊天功能,天气查询,讲笑话 三个功能的实现过程,在这里分享给大家,欢迎吐槽!
参考资料
python中cursor操作数据库
Python中的random模块
原文:http://yangyingming.com/article/364/
回复下方「关键词」,获取优质资源
回复关键词「 pybook03」,立即获取主页君与小伙伴一起翻译的《Think Python 2e》电子版
回复关键词「入门资料」,立即获取主页君整理的 10 本 Python 入门书的电子版
回复关键词「m」,立即获取Python精选优质文章合集
回复关键词「book 数字」,将数字替换成 0 及以上数字,有惊喜好礼哦~
推荐阅读
题图:pexels,CC0 授权。










