
向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
斯坦福大学CS224n(全称:深度学习与自然语言处理)是自然语言处理领域很受欢迎的课程,由 Chris Manning 和 Richard Socher 主讲。
但是自 2017 年以来,NLP 有了很多重大的变化,包括 Transformer 和预训练语言模型等。以前开放的是 17 年年初的课程,很多激动人心的前沿模型都没有介绍,而今年年初 CS224n 终于开始更新 19 年课程的视频。
这门课程为深入学习NLP应用的前沿研究提供了深入的探索。课程最后的项目将涉及训练复杂的循环神经网络并将其应用于大型NLP问题。
在模型方面,将涵盖词向量表示,基于窗口的神经网络,循环神经网络,长短期记忆模型,递归神经网络,卷积神经网络以及一些涉及 memory component 的非常新的模型。
课程视频、Pytorch实现代码获取方式:
最新(2019)斯坦福CS224n深度学习自然语言处理课程(视频+笔记+2017年合集)
2019斯坦福CS224n深度学习自然语言处理笔记(2)分类模型与神经网络
2019斯坦福CS224n深度学习自然语言处理笔记(1)Word2Vec与Glove
主要介绍了什么是自然语言处理,以及自然语言处理中最基础的工作——如果和表示词的意思的相关工作。接下来,主要介绍一下分类模型和神经网络,并以命名实体识别举例说明神经网络的运行过程。最后简要介绍一下矩阵运算。
1. 什么是分类?
为了给没有基础的同学介绍一下背景,这里首先简要介绍一下分类。所谓的分类就是给定输入X,通过分类模型后,获得输出y,其中y是一个离散的值(可能有2个值,也可能有10个值),有多少值就是多少个类别。这个过程就是分类。
其过程实现在机器学习中,一般使用softmax(多分类)和logist(二分类)。
1.1 logist(二分类)
一般的,如果一个模型是二分类模型时,可以使用逻辑斯蒂回归Logsit进行二分类,唯一需要注意的是,我们使用逻辑斯蒂回归时,给出的结果是概率(0-1之间的数),需要我们最后做转换后,才能进行二分类。
1.2 softmax(多分类)
对于softmax之前没有太多的介绍,这里详细讲述一番。softmax函数是用来处理多分类的,可以说,它是logist的一般形式。但是和逻辑斯蒂回归又有些许不同。
1.2.1 softmax函数
我们首先给出softmax函数的样子:
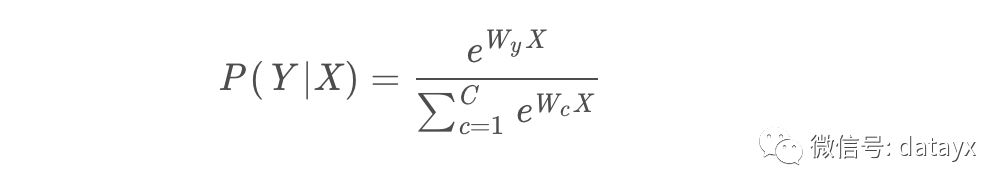
值得注意的是,这里的W有C个,其中C为类型的数量,也就是说,它相当于训练了多个二分类的模型,但是该如何在同一个模型中融合呢?softmax函数的融合办法是,让所有的类别预测的概率取对数后归一,这样会使得概率越大的类型的概率趋近于1,其他的类别概率趋向于0。
1.2.2 独热编码
在具体的操作中,我们一般把多分类的类别使用独热(one-hot)编码,在训练预料中,类别标签中只有1个类别为1,其余为零,分别表示该类型的概率。而在预测的时候,则会有一个较大的类别趋近于1,其他的都是趋近于0的。以三分类为例,真实值的类别为2。

1.2.3 交叉熵
这样,我们在训练模型时,仍然采用最大化正确概率的思想,这里使用交叉熵作为损失(Loss)函数来实现。
交叉熵的公式如下:

2.神经网络模型
神经网络模型来源于生物学中对于神经元的模拟,生物学中神经元结构如下图:
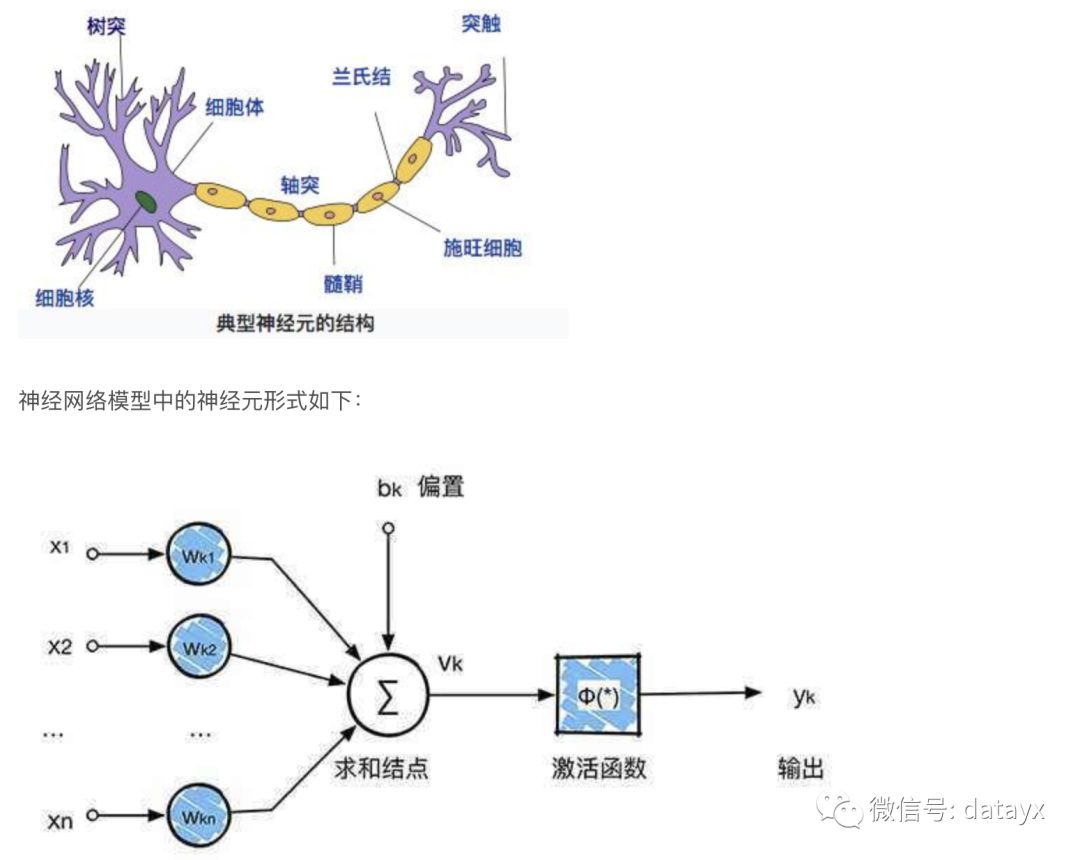

那么,神经网络模型与逻辑斯蒂回归有什么不同?
相比较传统的逻辑斯蒂回归,最基础的神经网络就已经具有两个方面的进步,第一个进步是多个神经元(cell)可以认为是多个逻辑斯蒂回归同时运行,每个神经元都可以得到一个划分界面。第二个进步则是多层化,多个神经元的层叠就可以获得更细致的划分。第三个进步是拥有激活函数可以使得整个模型呈现非线性。
第一个进步可以说是可以从不同角度对同一事物进行特征捕捉,所谓横看成岭侧成峰,但是像我们双眼一样,使用不同角度才能够看到事物的真正面貌。这是普通神经网络的第一个进步。第二个进步则是可以使得判定条件更丰富,即每多一层,就可以在该层次上进一步划分类型。第三个进步则是使用了激活函数,使得函数可以区分非线性数据,就像曾经说的,它可以使得数据划分界限变得弯曲,从而能够更好的拟合数据类型的分布。
第一个进步的图像化表示为如下图所示,每多一个神经元,就可以多一道分割线:
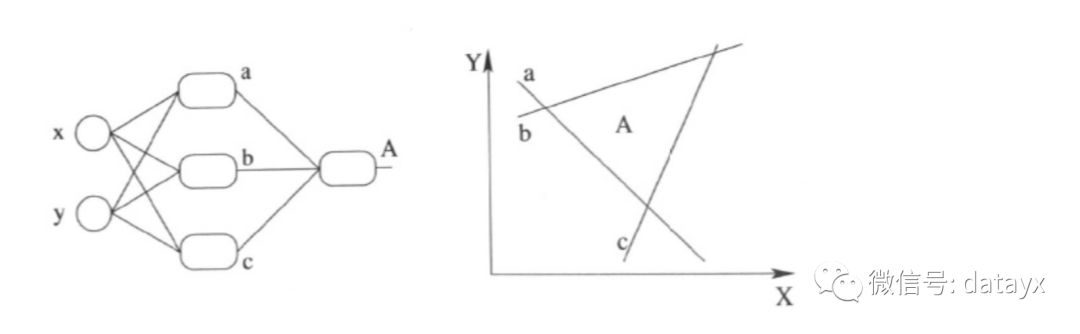
第二个进步还是上图所示,只不过多层的结果可以使得判定层次化,例如A的作用其实就是在已划分的7个界面上重新定义每块区域上的类型。若再多一层,可以继续对于已划分的区域进一步划分。
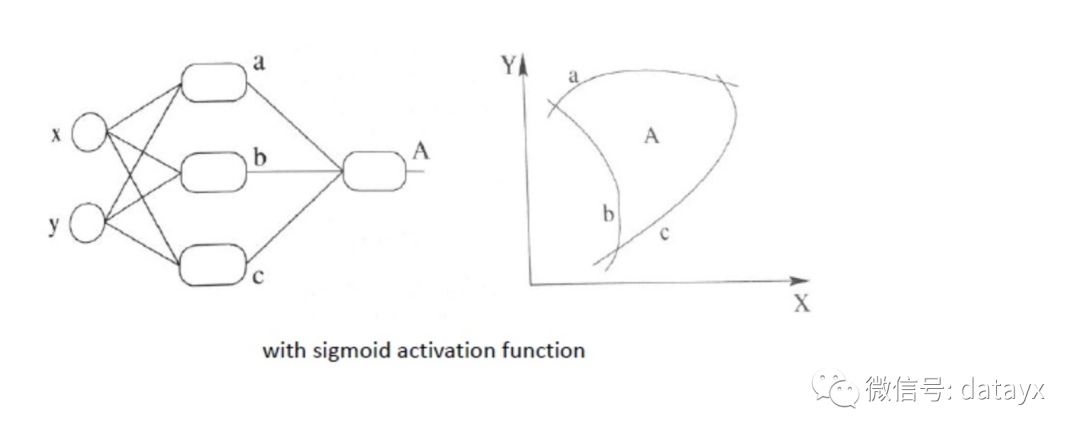
第三个进步则是使得划分平面变为曲线,如下图所示,这样,对于数据的拟合更加切实际,而且也能解决线性不可分等问题。
3. 命名实体识别(NER)
由于英文中不需要进行分词,因此直接使用命名实体识别进行神经网络模型举例,这里列举出原PPT中的例子(由于网上其他例子均不直观)。

命名实体识别的任务就是在给出的一个文本中,找到实体并区分其实体是人名(PER)、地名(LOC)、组织名(ORG)等。看起来是不是挺简单的。
命名实体具有以下作用:
追踪某一特别的实体的文章(比如包含“四川凉山”的文章,肯定都是和四川凉山火灾大致相关的文章,在这里向牺牲的英雄致敬!)
用于问答,比如问火灾是在哪里发生的?回答凉山。
构建实体之间的关系,比如小说里各个角色之间的关系等。
其他各种槽填充任务(多轮对话的任务中可以使用)
命名实体识别的方法有很多,包括基于规则方法、基于特征匹配方法,和基于神经网络的方法。
1. 基于规则的方法:
利用手工编写的规则,将文本与规则进行匹配来识别出命名实体。例如,对于中文来说,“说”、“老师”等词语可作为人名的下文,“大学”、“医院”等词语可作为组织机构名的结尾,还可以利用到词性、句法信息。在构建规则的过程中往往需要大量的语言学知识,不同语言的识别规则不尽相同,而且需要谨慎处理规则之间的冲突问题;此外,构建规则的过程费时费力、可移植性不好。
2. 基于特征模板的方法:
统计机器学习方法将 NER 视作序列标注任务,利用大规模语料来学习出标注模型,从而对句子的各个位置进行标注。常用的应用到 NER 任务中的模型包括生成式模型HMM、判别式模型CRF等。比较流行的方法是特征模板 + CRF的方案:特征模板通常是人工定义的一些二值特征函数,试图挖掘命名实体内部以及上下文的构成特点。对于句子中的给定位置来说,提特征的位置是一个窗口,即上下文位置。而且,不同的特征模板之间可以进行组合来形成一个新的特征模板。CRF的优点在于其为一个位置进行标注的过程中可以利用到此前已经标注的信息,利用Viterbi解码来得到最优序列。对句子中的各个位置提取特征时,满足条件的特征取值为1,不满足条件的特征取值为0;然后把特征喂给CRF,training阶段建模标签的转移,进而在inference阶段为测试句子的各个位置做标注。
3. 基于神经网络的方法:
近年来,随着硬件能力的发展以及词的分布式表示(word embedding)的出现,神经网络成为可以有效处理许多NLP任务的模型。这类方法对于序列标注任务(如CWS、POS、NER)的处理方式是类似的,将token从离散one-hot表示映射到低维空间中成为稠密的embedding,随后将句子的embedding序列输入到RNN中,用神经网络自动提取特征,Softmax来预测每个token的标签。这种方法使得模型的训练成为一个端到端的整体过程,而非传统的pipeline,不依赖特征工程,是一种数据驱动的方法;但网络变种多、对参数设置依赖大,模型可解释性差。此外,这种方法的一个缺点是对每个token打标签的过程中是独立的分类,不能直接利用上文已经预测的标签(只能靠隐状态传递上文信息),进而导致预测出的标签序列可能是非法的,例如标签B-PER后面是不可能紧跟着I-LOC的,但Softmax不会利用到这个信息。
学界提出了 LSTM-CRF 模型做序列标注。在LSTM层后接入CRF层来做句子级别的标签预测,使得标注过程不再是对各个token独立分类。在英文NER任务中先使用LSTM来为每个单词由字母构造词并拼接到词向量后再输入到LSTM中,以捕捉单词的前后缀等字母形态特征。关于神经网络方法做NER,可以看博客
https://www.cnblogs.com/robert-dlut/p/6847401.html
这里我们介绍最为简单的一种方法,根据窗口的词向量进行中心词是否是实体,其模型如下:

这样问题就转换为,给定5个单词,判断中心单词是什么类型即可。像上一章中讲的一样,使用词向量作为输入,然后使用softmax进行多分类即可。接下来将要介绍如何使用梯度下降法进行训练。
3.1 梯度下降(手动)
这里使用手算梯度下降,来清楚了解具体是如何运算的,下一步则是自动的反向传播。
首先,若有一个输入,一个输出:




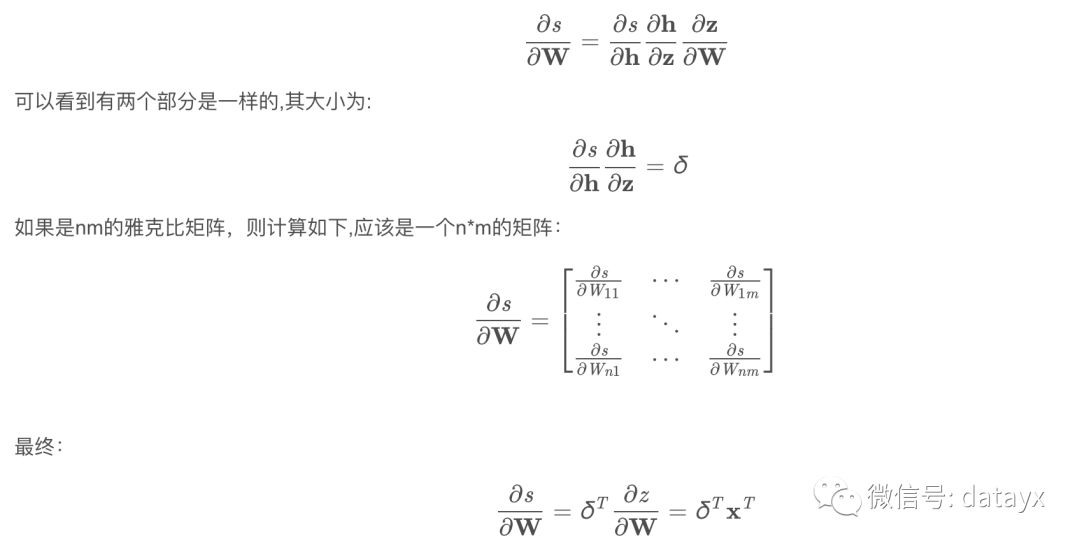
这里硬核较多,需要仔细阅读才能够理解。
阿里云双11大促 服务器ECS 数据库 全场1折
活动地址

1核2G1M,86一年,¥229三年
2核4G3M,¥799三年
2核8G5M,¥1399三年
......
阅读过本文的人还看了以下文章:
分享《深度学习入门:基于Python的理论与实现》高清中文版PDF+源代码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
《深度学习之pytorch》pdf+附书源码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
《Python数据分析与挖掘实战》PDF+完整源码
汽车行业完整知识图谱项目实战视频(全23课)
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
笔记、代码清晰易懂!李航《统计学习方法》最新资源全套!
《神经网络与深度学习》最新2018版中英PDF+源码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

长按图片,识别二维码,点关注
AI项目体验
https://loveai.tech







