
向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
斯坦福大学CS224n(全称:深度学习与自然语言处理)是自然语言处理领域很受欢迎的课程,由 Chris Manning 和 Richard Socher 主讲。
但是自 2017 年以来,NLP 有了很多重大的变化,包括 Transformer 和预训练语言模型等。以前开放的是 17 年年初的课程,很多激动人心的前沿模型都没有介绍,而今年年初 CS224n 终于开始更新 19 年课程的视频。
这门课程为深入学习NLP应用的前沿研究提供了深入的探索。课程最后的项目将涉及训练复杂的循环神经网络并将其应用于大型NLP问题。
在模型方面,将涵盖词向量表示,基于窗口的神经网络,循环神经网络,长短期记忆模型,递归神经网络,卷积神经网络以及一些涉及 memory component 的非常新的模型。
课程视频、Pytorch实现代码获取方式:
最新(2019)斯坦福CS224n深度学习自然语言处理课程(视频+笔记+2017年合集)
2019斯坦福CS224n深度学习自然语言处理笔记(1)——绪论与Word2Vec
本文内容整理自2019年斯坦福CS224n深度学习自然语言处理课程,其笔记为本人听课心得,重点在于对于知识内容的思考,并非课程原文笔记,应称为课后笔记。
1.绪论
在本堂课中,其基础技能需要懂得并应用:Ipython,numpy和Pytorch。其他的关于自然语言处理和深度学习,上了这堂课,你就会了解。
2. 语言的来源
语言,语言是传递信息的声音和文字,是人类沟通的主要方式(其他方式包括图像、触感等)。它作为人类文明的载体,距今已有5000多年的历史。如此古老的本领,在历史的长河之中,没有出现质的改变(功能没有改变,方式没有改变)。
在信息和信息传播活动,人类历史中共有五次巨大变革:
第一次:语言的诞生,是历史上最伟大的信息技术革命,语言使人类描述信息、交流信息的方式得到了大大的改进.
第二次:文字的诞生,为了便于交流和长期存储信息,就要创造一些符号代表语言,这些符号经过相当长的一段时间后逐渐演变成文字,并固定下来.
第三次:印刷术的诞生,使得知识可以大量生产、存储和流通,进一步扩大了信息交流的范围.
第四次:电磁波的应用,电磁波的应用使得信息传递的速度大大提高.
第五次:计算机技术的应用,使人们对信息的处理能力、处理速度产生了飞跃.
然而,当今自然语言(人类使用的语言,包含以上第一次、第二次革命的结果),相较于当今5G的网络传播速度(第五次革命),是相当的缓慢,但是仍然被我们人类广泛使用,那这是为什么?这是因为语言虽然说的东西少,但是听的内容多。这其中的信息增益,来源于对于世界的认知。
所谓的意思(Meaning)指两个方面,一方面是单词本身的意思(Representation for words),另一方面是使用单词想要表达的意思(Express by using words)。例如,我渴了。句子本身是说我缺少水分,而另一个含义是,你需要给我倒杯水。这是使用这句话想要表达的意思。
从语言学角度来说,文字等价于符号(signifier),也就是符号化所要表示的意思(signified the idea thing)。从这个角度讲,符号学派的理论就自然站得住脚。
3. 符号理论的表示及运算方法
基于符号理论,一个比较著名的应用是WordNet,NLTK工具包中包含这个应用,它将单词之间的关系描述为同义词和上位词(synonym set and hypernyms), 也就是什么是什么的关系。这样就能够很好的解决不同符号所表示的不同含义及其之间的关系。在中文中,也存在同样的工具(知网,即HowNet),不是大家所熟知的论文检索网站。
这样,WordNet就可以获得层次化的单词间的关系,但是同样存在以下几个问题:
缺少细微差别,一词多义
无法添加新的含义
构建过程过于主观
在文本表示上,如上所讲,已经有一定的方法,接下来需要解决的是如何进行语言间的运算(计算机要做的事)。
传统的自然语言处理(NLP)方式中,将单词看作为离散的符号(discrete symbols),就像一个词典一样,一个词对应一个编号,更一般的,使用独热(One-Hot)编码的形式。这样,符号就可以转换为数值进行运算。
同样的,该种方法同样存在一些问题,例如,词汇表太大,英文词汇超过50万个。不能够计算相似度(一种方法是使用wordnet,另一种方法就想去学习一种基于向量的表示方式)
那么,如何去基于单词向量本身学习呢?在1957年,一种理论提出:词汇的含义来源于其上下文(word’s means is given by it’s context)。跟随着这个思路,从神经语言模型(2003)到Word2Vec(2013)的道路就都说的通了。
神经网络模型的目的是,将单词进行分布式表示,即把词映射到一个向量空间中,使得相似的词拥有相似的位置。Word2Vec模型具有以下特点:
拥有大规模语料库
词使用分布式向量表示
对于每一个文本,均有一个中心词和一个上下文。
使用相似度计算中心词和上下文的概率
下面就是“硬核”Word2Vec的推导过程。
4. Word2Vec推导过程
我们使用Skip-Gram模型举例说明,
首先,Word2Vec同样使用极大似然估计,就像我们上面所说,它需要使得给定中心词,使得上下文词出现概率最大,即:

其中o表示目标词,V表示词表。其含义为,上面为两个词的矩阵的乘积最大,下面为正则项。这就有点像softmax函数一样。此处,我们先穿插一点,可以看到,其实这种计算方法就是使得越共现的词,向量乘积越大,乘积越大,则概率越大。最终会实现和某一个词的相关词和其都相似,就使得这些相关词向量更加相似。


首先想到为什么不直接使用词共现矩阵,然后提出SVD的解决方法。在比较了基于统计和直接预测两种方法后,提出Glove模型。接着对于词向量的评估方法和一词多义问题提出相应的解决方法。
1. 为什么不直接使用词共现矩阵获得词向量?
在上一节中,最后提出一个问题,为什么不直接使用词共现矩阵获得词向量?
1.1 词共现矩阵方法(窗口统计和全局统计)
其方法有2种,第一种是局部窗口,只统计在它附近窗口内的词,第二种方法是全文词共现,这就是所说的LSA方法,从而能够获得主题信息。
根据例子我们可以发现,直接使用词共现是由以下4个缺陷:
词表大小会不断增长
高维空间需要大量的空间存储
数据稀疏
不够健壮(鲁棒性差,鲁棒=robust)
1.2 解决上述问题方法——SVD
所以,其解决办法思路是,能不能找到一个固定的,低维的矩阵来把词共现的意思蕴含其中呢?于是就是用了降维方法。常用的降维方法就是奇异值分解(Singular Value Decomposition, SVD),之所以叫做奇异值,就是因为它来源于积分方程(设A为mn阶矩阵,q=min(m,n),AA的q个非负特征值的算术平方根叫作A的奇异值。)。最初不是这个名字,而是为标准乘子(canonical multipliers),也就是标准型上的对角元素。这里我们扯远了。
奇异值分解方法如下:

U和V是正交的。
当然,这仍然会有之前出现的一些问题,例如高频词(the,has,have)等,统计方法是否科学等。其解决方法如下:
最高频率设定阈值,如100
使用皮尔逊系数取代频率,并将负数置为0
使用倾斜窗口采样更多的词
等等
其结果也大致可看。
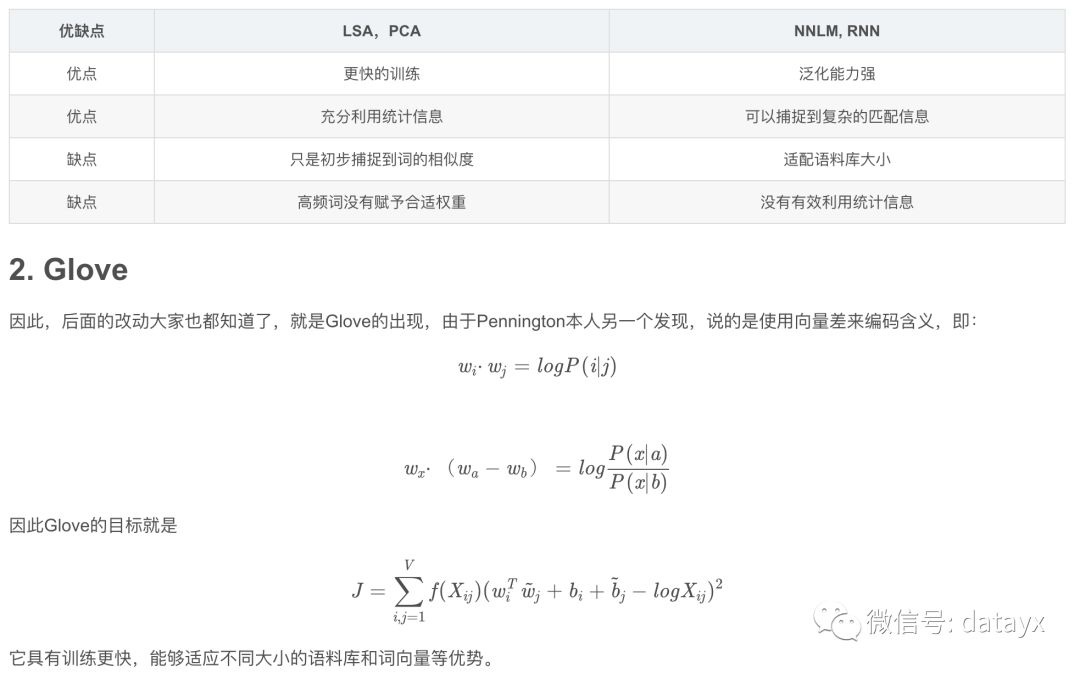
1.3 基于统计和直接预测方法比较
那么基于统计和直接预测两种方法比较如下:
3. 词向量评估
接下来的问题就是如何进行词向量的评估,一般的NLP的评估分为内在的(Intrinsic)和外在的(extrinsic)两种方法,区别如下。
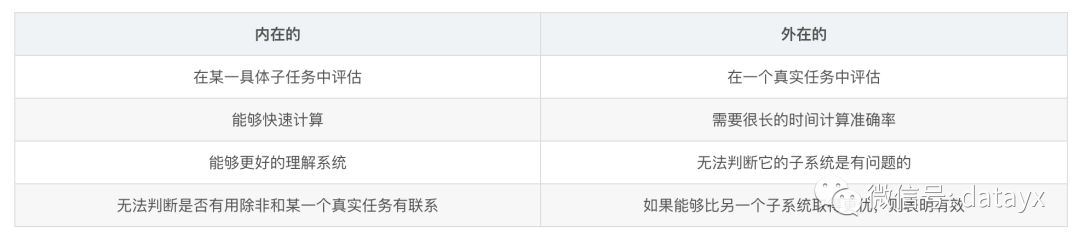
具体的,内在性评估方法有常见的词距离是否表示相同的含义(anology)和信息检索等。
后面的实验(On the Dimensionality of Word Embedding)也证明以下问题:
4. 一词多义
剩下要解决的问题就是接下来的方向,可能存在一词多义现象。
其中一个解决方法是增加标号,同一个词使用不同的标号表示不同的含义。
另一个方法是,根据不同含义进行加权求和,例如;
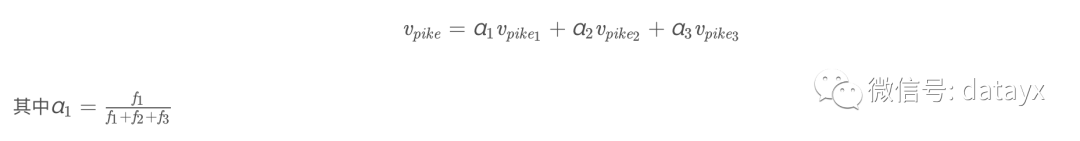
然而随着技术的发展,现有的解决方法是使用不同层次的编码层,从而获得不同的含义,这就使得一个词不仅基于该词本身的含义(最后一层输出),还基于其上下文(前n层的输出)。
原文地址https://blog.csdn.net/qq_35082030/article/details/88847720
阿里云双11大促 服务器ECS 数据库 全场1折
活动地址

1核2G1M,86一年,¥229三年
2核4G3M,¥799三年
2核8G5M,¥1399三年
......
阅读过本文的人还看了以下文章:
分享《深度学习入门:基于Python的理论与实现》高清中文版PDF+源代码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
《深度学习之pytorch》pdf+附书源码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
《Python数据分析与挖掘实战》PDF+完整源码
汽车行业完整知识图谱项目实战视频(全23课)
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
笔记、代码清晰易懂!李航《统计学习方法》最新资源全套!
《神经网络与深度学习》最新2018版中英PDF+源码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

长按图片,识别二维码,点关注
AI项目体验
https://loveai.tech









