和学术研究不同,将深度学习技术运用到实际项目实践中需要考虑诸多不同的因素。如何确定哪些任务可以用人工智能完成?如何划分数据集?模型性能不佳时如何判断问题所在?如何判断某个改进思路的可行性?深度学习项目通常需要消耗大量的资源,与其投入一两个月的精力实现某思路结果发现性能并不尽如人意,“谋定而后动”是十分必要的。目前,直接关注深度学习在实际项目实践中经验心得的中文资料还十分匮乏,本文力图对深度学习项目实践从项目选型、数据准备、训练、模型分析、模型部署全阶段的注意事项和技巧进行梳理。
学术研究的目标。学术研究的目的是为人类认识世界提供新的知识,因此很看重独创性(novelty)和 方法可复现性。创新是学术研究的核心,同样的研究问题,无论以何种形式,已经有人发表,那么该工作的创新性将大打折扣。
项目实践的目标。而项目实践的目标通常是得到一个高性能的模型,对这个模型是否独创或可复现并不看重。这并不是说项目实践比学术研究更简单,不客气地讲,有的学术研究就是在想方设法过拟合几个基准(benchmark)数据集的测试集以在论文中展示出漂亮的数字。而项目实践对模型的泛化性能十分看重,如果过拟合测试集,只会让你的老板短暂的高兴一下之后将发现线上指标十分糟糕。此外,要想做好项目实践,除了需要读论文、复现结果、产生自己idea的能力外,还需要下载处理数据、调试代码等脏活累活,这两部分同等重要。
找工作时应具备的技能。通常,雇主希望应聘者具有两方面的能力和经验:(1). 机器学习(尤其是深度学习)的知识和工程编程能力。(2). 做过有价值的工作,例如完成的科研、做过的项目或实习、开源代码贡献。因此,建议是对各个子领域了解呈T形,也就是说,广泛了解各个子方向,而对一块特别深入。
选工作时考虑因素。求职是一个双向的过程,不仅是找工作,更是选工作的过程。选工作时可以考虑如下因素:
(1). 和重要的人/项目合作(包括主管、合作的团队)。
(2). 了解主管是谁、团队大小、做的项目。
(3). 团队比整体的牌子重要很多。
(4). 能学到更多。
(5). 工作中从事重要的角色。
有网页的零售店不等于互联网公司。互联网公司的特点是:
(1). A/B测试:同时线上测试两个版本,迭代速度快,而零售店不可能同时运营两个版本。
(2). 由产品经理或工程师进行决策:更熟悉用户和算法。
用深度学习的传统公司不等于AI公司。AI公司的特点是:
(1). 有策略地获取数据。
(2). 统一的数据管理。
(3). 发现自动化AI可以完成的机会。
(4). 新的职位描述:以前全是软件工程师,现在细分为前端/后端/移动端/...
1.1 确定合适的AI项目
AI可以做什么。
(1). 普通人1秒之内可以做的事情。
(2). 预测一个重复性事件的下一个结果(例如用户点击广告、快递花费时间)。
尽量选择普通人可以容易完成的任务。当普通人难以完成的任务时,整个流程将变得很难。选择普通人可以完成的任务有如下几点好处:
(1). 容易标注数据。
(2). 可以进行人工误差分析,获得改进启示。
(3). 可以利用普通人预测准确率作为贝叶斯准确率。
头脑风暴可行的项目。考虑如下几点:
(1). 想自动化任务(task),而不是自动化工作(job)。例如让AI读X光,而不是去替代放射科医生。
(2). 商业价值的主要驱动和主要痛点是什么。
(3). 即使只有小数据,也可以取得进展。
(4). 对于初始项目,选择最容易做成的,而不是最有价值的。
如何构建有壁垒的AI产品。后期经常要考虑如果构建壁垒,主要依靠这两部分构建壁垒:
(1). 数据:获得足够的数据是很困难的。
(2). 才智:直接下载开源实现并用于实际任务中通常是不奏效的。
1.2 与产品经理沟通
产品经理与工程师/研究员的不同关注点。产品经理的关注点是哪些是用户喜欢的,AI研究员/工程师的关注点是哪些是技术可行的。最后得到的产品是这两部分的交集。
产品经理与工程师/研究员的最有效沟通方式。和传统沟通模式不同,对AI产品的最有效方式是构建数据集,通过数据集产品经理可以指明想要的是什么。因此,对于一个AI团队,通常需要如下分工:
(1). 产品经理的责任是提供验证集和测试集(两者最好是源于同一个分布)。
(2). AI研究员/工程师的责任是获取训练集,并开发出在验证集和测试集上满足标准的系统。
1.3 调研相关工作
如何选论文。面对不熟悉的项目,第一步是阅读该领域的研究论文,跟进该领域的SOA(state-of-the-art)。选择论文的方式可以有如下几种。
(1). 媒体。如微博、知乎、reddit等。
(2). 顶级会议。
(3). 身边人推荐。对一个领域需要持续阅读,每周读坚持几篇,但没有短期收益,长期来看,读5-20篇可以做到基本了解,而读50-100篇就可以做到十分了解了。
如何读论文。基本方法是快速泛读几篇,之后详读一篇,并反复迭代这个过程。对于读某一篇论文,绝对不要从第一个字一直读到最后一个字,而是从粗到细、有选择的多读几遍。打印出来阅读比读电子版更有效,需要前后反复跳读
第一遍:title -> abstract -> 所有图表
第二遍:introduction -> conclusions -> 所有图表
第三遍:读全文,但是跳过related works和数学推导
第四遍:读全文,跳过看不懂的地方
其中,详读所有图表的原因是,深度学习的很多论文提出的方法用一张网络结构图就可以概括,而表格通常是汇报各种实验结果。跳过related works的原因是,如果你对该领域不了解,related works部分基本看不懂。跳过看不懂的地方的原因是,不要迷失在论文中,而且并不是论文所有部分对未来都有用。最后,读完之后需要多思考:(1). 该论文想要完成什么?(2). 这个方法的关键是什么?(3). 我能用到什么?(4). 哪些引用我希望关注。
不要沉溺在论文的海洋。现在人工智能正值热潮,每年新发表的论文非常多。而机器学习是实践科学,尤其是当你不是该领域专家时,事先很难知道哪种方案在实际中效果最好,通常需要尝试很多的思路。机器学习实战的过程是思路、代码实现、实验结果的迭代循环。迭代循环的越快,取得的进展越大。不要在开始前想的过多,尤其不要一开始就想着设计和构建一个完美的系统,最初的方案要越早构建和训练越好,之后根据偏差/方差分析和误差分析确定下一步的工作方向,并进行迭代。
2.1 不使用额外训练数据
数据的重要性。项目实践是个反复迭代的过程。边收集数据、边给AI团队进行处理、边得到AI部门的反馈。不要认为只要有足够的数据,就可以发现有价值的结果。对于混乱的数据,智能garbage in, garbage out。在学术界通常只划分训练集和测试集,但是在实际应用中由于训练集和验证集/测试集常常不服从于同一个数据分布,所以划分起来要复杂一些。
不使用额外数据进行训练时的数据划分。我们需要将数据划分为4个不相交的子集:
- 训练集(training set):学习算法在训练集上进行学习。
- 黑盒验证集(blackbox validation set):根据黑盒验证集的性能调节超参数、模型选择。我们要避免人工观察黑盒验证集。
- 观察验证集(eyeball validation set):人工观察其中样本进行误差分析(见第4.2节)。
- 测试集(test set):只用于观察模型的性能,而不能用于调节超参和模型选择。验证集(包括黑盒验证集和观察验证集)和测试集要服从同一分布,要和现实任务中关心的数据分布一致。
·
黑盒验证集和测试集应该多大。取决于你对任务性能的数字的敏感程度。如果能容忍0.1%的估计误差,大小为1,000的黑盒验证集和测试集就差不多了,如果容忍程度要精确到0.01%,大致则需要大小为10,000的黑盒验证集和测试集。经典机器学习使用的70%-30%的划分准确对大数据时代来说有些浪费数据,不需要那么大的黑盒验证集和测试集。
观察验证集应该多大。观察验证集的大小应该使得你会有大约100个模型分错的样本可以进行人工观察。例如,当模型错误率为5%时,观察验证集大小应该为2,000(由于2,000 * 5% = 100)。随着开发过程的进行,模型的错误率越来越低,观察验证集的大小则应当相应得越来越大。
什么时候应该更换黑盒验证集和测试集。当出现模型A在验证集和测试集的指标更高,但是在现实任务中模型B更好的情形时,说明:
(1). 验证集/测试集和现实任务的数据分布不一致。(2). 使用验证集调参过多,已经过拟合验证集,或者使用测试集进行决策而开始过拟合测试集。
(3). 指定的单一数字的性能优化目标不能很好的反应你在实际任务中的目标,此时应当更换该单一数字的性能优化目标。
什么时候应该更换观察验证集。由于我们需要不断的对观察验证集的样例进行人工观察,久而久之,我们将渐渐过拟合到观察验证集。当发现观察验证集的性能提升显著高于黑盒验证集时,说明我们应该更换观察验证集。
2.2 使用额外训练数据
有时,你所关心的任务的数据量太少,为了取得进展,你不得不使用一些额外的数据进行训练(例如使用ImageNet数据),这些额外的数据和你所关心任务的数据服从不同的分布。
使用额外数据进行训练时的数据划分。当我们使用额外数据进行训练时,我们需要将训练集进一步划分为一个训练集和一个验证集,这样一共需要讲数据划分为5个不相交的子集:
- 增广训练集(augmented training set):由关心任务的数据和额外收集的数据构成。
- 增广验证集(augmented validation set):由关心任务的数据和额外收集的数据构成,用于作为增广训练集的验证集。
而验证集和测试集需要完全用你关心任务的数据构成,不要使用额外数据。
使用的额外的数据的必要条件。给定输入x之后,输出y完全可以确定,不依赖于x的来源。例如给定一张猫狗图像之后我就可以识别出其动物种类,和图片源于网络还是用户手机拍摄无关。而一个房间的出租价格不仅依赖于房间内家具陈设,还依赖于房间的来源地段。
额外数据进行加权。使用额外数据通常不会带来坏处。当不同类别数据分布很不一样,或者额外数据比原数据数据量多很多的情况下,可以考虑对原数据的损失进行加权。在训练时对不同类别的数据的损失项使用不同的权重项,权重项可以设置为使不同类别数据重要性相同,还可以把它当做一个超参数在黑盒验证集进行调节。
谨慎构造合成数据。合成的数据可能对人看上去十分真实。例如,需要完成的任务是自动驾驶中的车辆识别,你可能会用很多汽车驾驶游戏中的车的图像作为合成数据。即使这些图像看上去十分真实,但为了节约成本,游戏厂商在整个游戏中可能一共只有十几种汽车3D模型,最后你的模型将过拟合到这特定的十几种汽车种类上。合成数据集要尽可能有代表性,要尽可能减小合成数据和非合成数据的区别。
3.1 训练设置
要不要使用端到端(end-to-end)的解决方案。端到端的解决方案不应该是我们追求的目标。主要考虑两点:
(1). 数据量。划分为多个模块之后各个模块能否获得更多的训练数据?
(2). 子任务简单程度。划分为多个模块之后各个模块是否容易解决?
制定单一数字的性能目标。在确定单一数字的性能目标之后,可以对模型的性能进行排序,用于模型选择。例如,如果你关心分类准确率,想方设法提高验证集分类准确率将是你的目标。如果你关心查准率(precision)和查全率(recall),可以讲目标设为验证集F1。
满足性目标和性能目标。除了性能指标外,还会有一些资源指标,例如运行时间。此时,我们可以讲运行时间转化为“满足性目标”:定义一个运行时间阈值,然后在模型运行时间小于该阈值条件下,最大化精度。一般的,如果有n个目标,我们将其中n-1个设置为满足性目标,1个设置为优化目标。
详细记录每次训练过程和结果。保存训练好的模型,起合适的名字,详细记录实验细节,保存代码,未来可以直接查阅和调用。
3.2 训练技巧
介绍了许多有用的技巧。
模型结构调整。相比经典ResNet结构(图1),图2(b)使用3个3×3 卷积取代7×7卷积,图2(c)避免了使用1×1步长2卷积的3/4信息损失。
使用更大的批量大小和更低的数值精度加速训练。
单纯增大批量大小会使梯度随机性下降,从而使模型收敛时的性能变差。因此,增大批量大小需要配合如下技巧:
(a). 初始学习率按批量大小变化成比例增大,以增大梯度随机性。
(b). 使用太大初始学习率会使训练不稳定,需要进行学习率预热(从0开始线性增加到初始学习率)。
(c). 将BN的β、γ参数置零,降低网络有效大小使训练变容易。
使用更低的数值精度(32位浮点数->16位浮点数)会使性能变差。因此,需要配合如下技巧:(a). 前向使用16位,反向更新使用32位。(b). 将损失乘以常数,使梯度有合适的数值范围。
使用余弦学习率衰减。
其中, t 和 T 分别是训练当前和总批量数(不计预热阶段)。相比阶梯衰减,余弦衰减保持比较长时间的大学习率。此外,使用较大的学习率有缓解过拟合的效果。
其中 K 是分类类别数。相比独热编码,标记平滑之后使网络不倾向输出极端值,泛化能力更好。
知识蒸馏。使用同系列网络结构的更大的网络的各类别预测分数r指导当前网络训练,最终损失函数是
其中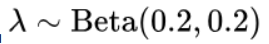
只使用混合后的样例进行训练,混合样例后需要更长的训练轮数。
4.1 偏差/方差分析
贝叶斯准确率(Bayes accuracy)。算法能达到的准确率上限。为了对贝叶斯准确率进行估计,我们可以在训练集中随机取一些样本,人工进行预测,并计算准确率,用该准确率近似贝叶斯准确率
偏差与方差。
在估计出贝叶斯准确率之后,我们可以计算得到偏差和方差:
偏差(bias):贝叶斯准确率 - 训练集准确率
方差(variance):训练集准确率 - 黑盒验证集准确率
·
在经典机器学习领域,存在偏差-方差权衡(bias-variance tradeoff),降低方差则偏差增大,反之亦然。而在深度学习领域,由于使用非常大的模型和非常多的数据,可能做到只降低其中一方面而不影响另一方面。
解决顺序。如果训练集中没有使用额外的数据,我们的解决顺序是:
1. 提高训练集准确率,降低偏差。例如通过训练更大的模型。
2. 提高黑盒验证集和观察验证集准确率,降低方差。例如通过使用更多的数据。
3. 提高测试集准确率,降低对验证集的过拟合。例如通过使用更大的验证集。
如果训练集中使用了额外的数据,构建了增广训练集,我们的解决顺序是:
1. 提高增广训练集准确率,降低偏差。例如通过训练更大的模型。
2. 提高增广验证集准确率,降低方差。例如通过使用更多的数据。
3. 提高黑盒验证集和观察验证集准确率,降低分布不一致问题。例如通过使用更多的数据。
4. 提高测试集准确率,降低对验证集的过拟合。例如通过使用更大的验证集。
.
高偏差解决方案。最直接简单有效的方法是训练更大的网络,例如加深网络层数、增加每层通道数、网络输入用更大的分辨率,或者同时加大这三者 ,训练更大的网络有时需要相应地增大正则化。除此之外,还可以:
(1). 使用额外的输入特征,给模型提供更多的信息。
(2). 降低L2正则化和dropout,但这会增加方差。(3). 尝试新的网络结构,但是结果往往是不可预测的。
(4). 对训练集进行分错样本误差分析,提出新解决思路。
高方差解决方案。最直接简单有效的方法是收集更多的数据。除此之外,还可以:
(1). 降低输入特征数目,但是在深度学习领域更倾向于使用全部特征。
(2). 增大L2正则化和dropout,但这会增加偏差。(3).根据黑盒验证集性能早停训练(early stopping),但这会增加偏差。
(4). 尝试新的网络结构,但是结果往往是不可预测的。
分布不一致解决方案。通过误差分析理解哪个特性带来两个分布的不一致。随后找到分布更加匹配的额外数据,或使现有额外数据分布更加贴近关心数据分布。
4.2 误差分析
基本思路。很多时候有许多的改进思路,你需要知道每个思路能带来的收益(即对性能的改进)有多少,根据此来判断是否需要投入时间和精力进行这项改进。具体来说,误差分析是从观察验证集中随机选择一些(例如100个)模型分错的样例,人工观察这些样例,判断其对应于哪一项分错的原因,见下图。最后依据最后一行百分比,可以得到每项改进能获得的收益的上限的估计。由于一个样例可能同时有多个分错的原因,所以最后一行的总和可能超过100%。如果一开始你想不到一些可能的分错原因也没关系,观察一些样例之后你将很可能发现一些其中的分错原因。
很多AI研究员/工程师不愿意花费人工的精力进行误差分析,设计并实现新算法对他们更加exciting,但是不进行误差分析,可能花费几个月的时间最终只发现带来一点点性能提升。
如何应对样本的标记错误。由于数据通常是人工标记得到的,因此很有可能你的验证集和测试集中会存在人工标记错误。注意验证集和测试集的作用使用来判断不同模型的优劣,利用误差分析的方法对标记错误的比例进行估计,刚开始容忍验证集/测试集中存在的标记错误是很常见的,只有当样本的标记错误影响到该判断之后才需要花时间修正验证集和测试集中的标记错误。例如,当验证集中5%的错误是由标记错误造成的时候,可以不用考虑标记错误的影响,而当验证集中30%的错误是由标记错误造成的时候,则需要进行标记校正。
在修改标记错误时,需要同时修改验证集和测试集中的标记错误,以使得验证集和测试集仍然服从同一分布。另一方面,你的模型分对和分错的样本中可能都存在标记错误问题,由于模型分对的样本通常要远多于模型分错的样本,因此为了减轻工作量,我们通常只校正模型分错的样本中的标记错误问题。但是要留意这么做会得到对于模型性能过于乐观的估计。
当模型超过普通人准确率时。此时模型性能的进展将会变慢,你仍然可以尝试找到一个子集,在该子集上模型的性能不如普通人的准确率,误差分析的方法在这里仍可以使用。
4.3 多模块误差分析
基本思路。当模型整体的性能低于预期时,你想知道是哪个模块的问题。例如,整个模型是判断图像中是否含有猫,模型分为两个子模块
图像 -> 猫检测器 -> 猫分类器 -> 含有猫/不含有猫
随机采样观察验证集中100个模型分错的样例,观察其检测器的输出:如果检测器能正确检测到猫,则认为是分类器的问题;如果不能,则认为是检测器的问题。
如何应对模棱两可的中间结果。有时,检测器会输出一些模棱两可的结果。如果这部分比例不大,不影响我们的误差分析决策;而如果比例比较大,做法是手工将该模棱两可的结果改为“完美”检测结果,观察分类器的输出,如果分类器仍分错,说明是分类器的问题,否则,是检测器的问题。一般来说,如果模型有多个子模块
输入 -> 模块A -> 模块B -> 模块C -> ... -> 输出
将模块A的输出手工校正为完美输出,运行其他部分,如果输出正确,说明是模块A的问题。将模块B的输出手工校正为完美输出,运行其他部分,如果输出正确,说明是模块B的问题。以此类推。
各个子模块和贝叶斯准确率的比较。此外,我们还可以分别把各个子模块和其贝叶斯准确率进行比较,如果某个子模块和贝叶斯准确率相差很大,那么我们认为其有很大的改进空间。如果每个子模块都和贝叶斯准确率接近,而整体性能很差,说明模型的模块化流程有问题。
与HPC部门合作。大数据和大模型需要HPC(高性能计算),但是HPC需要专门的知识,同时精通这两个领域的人很少。
如何在边缘设备(edge device)和云端分配计算?使用云端计算的好处是在不违反隐私协议的条件下获得用户的最新数据,可以发现新问题,并且有新的数据训练,最后方便更新。这样便于构成AI产品的循环:产品发布给用户、用户使用产品得到数据、数据用于更新产品、新产品发布给用户。
如果选择使用边缘设备部署,由于边缘设备计算资源有限,通常在边缘设备部署一个简单的、通常非机器学习的判断模块,只有通过该模块判断再前馈网络。例如在唤醒设备中,通常使用
语音输入 -> VAD (voice activity detection) -> DNN -> 唤醒词/非唤醒词
VAD用于判断是否有人说话,只有说话时才前向DNN。VAD计算很简单,例如通过声音音量阈值。只有在发现存在狗叫或者交通噪音问题时,再修正VAD用更复杂的技术。非ML的VAD更加稳健(robust):参数量更少,VC维低,泛化能力强。
最后,本文准备了一个具体的深度学习实践项目开发过程模板,如下所示。
https://docs.qq.com/sheet/DYnFxbnNYclJZanVR?preview_token=&coord=C14%24C14%240%240%240%240&tab=qnzoza
参考资料
- A. Ng. Structuring machine learning projects. deeplearning.ai, 2017.
- A. Ng. Machine learning yearning. Draft. 2018.
- A. Ng and K. Katanforoosh. CS230: Deep learning. Stanford, 2018.
- A. Ng. AI for everyone. deeplearning.ai, 2019.
- A. Ng. AI for everyone. deeplearning.ai, 2019.
- T. He, Z. Zhang, H. Zhang, Z. Zhang, J. Xie, and M. Li. Bag of tricks for image classification with convolutional neural networks. In CVPR, 2019.
- M. Tan and Q. V. Le. EfficientNet: Rethinking model scaling for convolutional neural networks. In ICML, 2019.









