机器学习已经成为建模环节中必备的实践方法。本章主要介绍用R语言实现机器学习的一些典型算法。其中,本章将以相亲市场数据为例,讲解相关模型的建立与解读。
机器学习的整个过程就像是烹饪。首先是准备食材,也就是准备并读入数据;其次是对食材进行加工,比如洗菜、切菜,也就是数据预处理;再次是对这些食材进行烹调,也就是模型训练;最后是将不同厨师做出来的菜给评委品尝,评委满意度越高越好,也即模型预测及评价(见图1)。
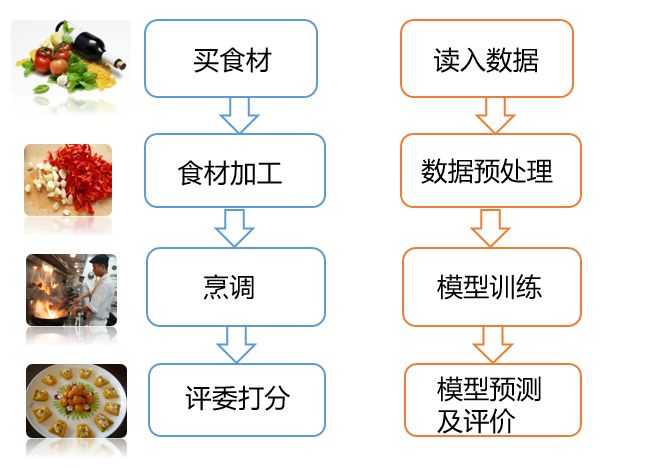
图1 数据分析流程
分析之前,要先把数据和分析所需要的R包准备好。这里分析用到的数据为相亲数据.csv,直接使用read.csv操作即可。分析的整个过程借用了caret包(见图2)来完成。这里的caret包是为了解决预测问题的综合机器学习工具包。这个包的特点就是能够快速把所有的材料准备好,包括数据预处理、模型训练、模型预测的整个过程。
图2 caret包页面示例


1. 缺失值处理
现实生活中,在数据分析时,经常会碰到缺失值,比如相亲数据中,有些女性不愿意暴露自己的年龄,年龄就会有缺失值。那么对于缺失值,怎么处理呢?处理方式很多,甚至有时候数据缺失本身也暗含一些信息(比如年龄缺失的女性可能是因为年龄比较大),由此引申了许多插补方法。不过这里缺失值处理并不是重点,因此对于缺失值直接删除即可。
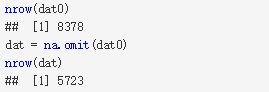
2. 转换数据类型
对于完整的观测,首先需要定义变量的类型:属于定性变量还是连续变量。对于定性变量而言,需要给定性变量的各个水平取名,比如性别有两个水平1和0,分别命名为男、女。
3. 数据分割
这一步,需要将数据分割为训练集和测试集。常用的方式是5折划分,也就是将数据的80%划分为训练集,20%划分为测试集。训练集用于训练模型,测试集用于测试模型的效果。需要注意的是,测试集的信息就是黑盒子,是“雷区”,是绝对不能用到的信息。
当因变量Y的各个水平比例分布不均时,需要保证训练集和测试集中有相同比例,这时就会用到caret包。

caret包中createDataPartition()函数可以用于创建训练集,该函数的抽样方法类似分层抽样,从因变量Y的各个水平中随机抽取80%的数据作为训练集,剩下的数据作为测试集。
4.标准化处理
标准化处理是指将数据处理为均值为0、标准差为1的数据。那么为什么要进行标准化处理呢?因为在进行实证分析时,有些变量取值很大,有些变量取值很小,这里需要营造一个公平公正的环境,权重的大小不能被自身变量取值的大小所束缚。比如在判断一个女生是否是美女时,会考虑腿长、脸长、脸宽、腰围等因素,这些因素的学名为特征。显然腿长的取值比脸长的取值大得多,这时为了防止腿长的权重过高,就需要将这些特征进行标准化才能学习各个变量真实的权重。
标准化处理时,只能利用训练集的均值与标准差对训练集和测试集进行标准化。
特征选择是指选择出那些对研究问题至关重要的特征,剔除掉那些不重要的变量。依然拿判断一个女生是否是美女为例,我们会考虑腿长、脸长、脸宽、腰围、年龄、肤色、脸型、上下身比例、牙齿是否洁白……影响一个人是否是美女的因素很多,但并不是所有因素都是特别重要的。所以需要选择出那些对判断是否为美女至关重要的变量。
特征选择在R中如何实现呢?caret包中rfe()函数可以用于特征选择,该函数属于特征选择中的封装法(见图3)。该函数还内嵌一个特殊的函数——rfecontrol(),用于输入目标函数和抽样方法。在判断一个女生是否为美女的例子中,我们以随机森林为目标函数,即functions为rfFuncs,抽样方法为交叉验证,即将参数method设置为cv。该方法的核心思想为用随机森林法进行预测,挑出来的特征使交叉验证的平均预测精度越高越好。
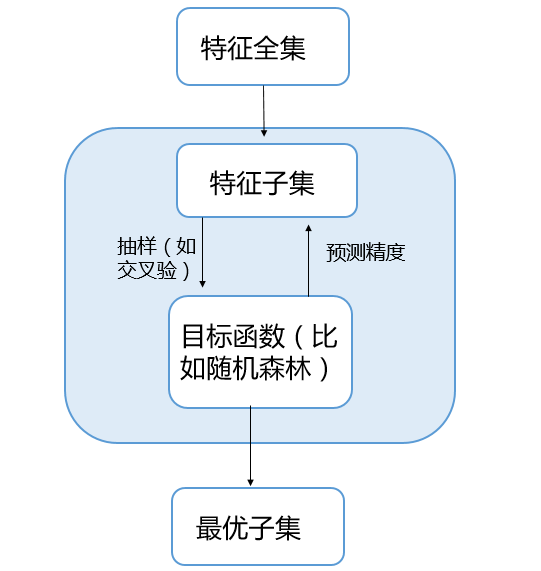
图3 封装法变量选择流程

随机森林算法选择了15个让其预测精度最高的特征,接下来就要把这15个特征作为自变量来训练模型,此时用到的数据为训练集,建模依然用随机森林法。

模型训练出来后,就可以顺便把变量的重要性给提取出来了。从图4可以看出,好感、吸引力与共同爱好这三个特征最为重要。
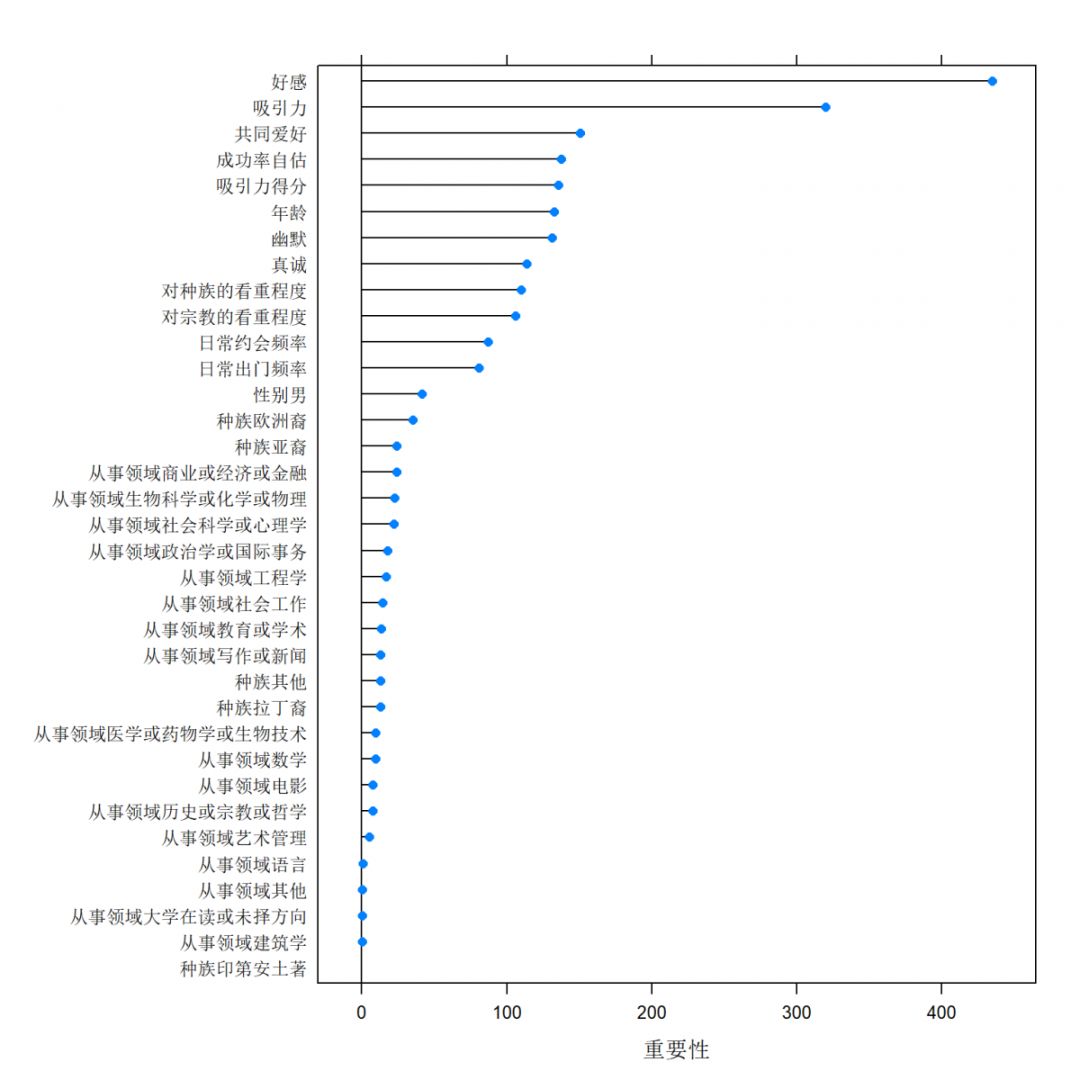
图4 变量重要性
最后来测试一下模型的预测精度。数据分析的结局不能是开放式任凭想象的,需要给出一个具体的数值。使用caret包的predict()函数,预测精度就呈现出来了,本例中为0.8147。

请扫描以下二维码/点击链接购买
《R语言:从数据思维到数据实战》


https://detail.tmall.com/item.htm?spm=a220z.1000880.0.0.0A6pvS&id=581845865737









