一、单表优化
建表:
create table article(
id int unsigned not null primary key auto_increment,
author_id int unsigned not null,
category_id int unsigned not null,
views int unsigned not null,
comments int unsigned not null,
title varchar(255) not null,
content text not null
);
打印
Query OK, 0 rows affected (0.05 sec)
插入数据:
insert into article(`author_id`,`category_id`,`views`,`comments`,`title`,`content`) values
(1,1,1,1,'1','1'),
(2,2,2,2,'2','2'),
(1,1,3,3,'3','3');
打印
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
查询category_id为1且comments大于1的情况下,views最多的article_id:
select * from article where category_id = 1 and comments > 1 order by views desc limit 1;
打印
+----+-----------+-------------+-------+----------+-------+---------+
| id | author_id | category_id | views | comments | title | content |
+----+-----------+-------------+-------+----------+-------+---------+
| 3 | 1 | 1 | 3 | 3 | 3 | 3 |
+----+-----------+-------------+-------+----------+-------+---------+
1 row in set (0.00 sec)
explain语句分析
explain select * from article where category_id = 1 and comments > 1 order by views desc limit 1;
打印
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
| 1 | SIMPLE | article | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 33.33 | Using where; Using filesort |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
1 row in set, 1 warning (0.01 sec)
type为all,全表扫描,且Using filesort,需要进行优化。
--建立复合索引
create index idx_article_ccv on article(category_id,comments,views);
explain select * from article where category_id = 1 and comments > 1 order by views desc limit 1;
打印
显然,type变成了range并且出现了Using index condition,但是Using filesort仍然存在,未解决问题,改变条件语句进行尝试可知,views字段索引是多余的,所以在索引中去掉views,再次尝试。
drop index idx_article_ccv on article;
--重新建索引
create index idx_article_cv on article(category_id,views);
explain select * from article where category_id = 1 and comments > 1 order by views desc limit 1;
打印
+----+-------------+---------+------------+------+----------------+----------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+----------------+----------------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | article | NULL | ref | idx_article_cv | idx_article_cv | 4 | const | 2 | 33.33 | Using where |
+----+-------------+---------+------------+------+----------------+----------------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
此时type为ref,且Using filesort未出现,达到优化效果。
二、双表优化
建表:
--商品类别
create table class(
id int unsigned not null primary key auto_increment,
card int unsigned not null
);
--图书表
create table book(
bookid int unsigned not null auto_increment primary key,
card int unsigned not null
);
打印
Query OK, 0 rows affected (0.02 sec)
Query OK, 0 rows affected (0.01 sec)
插入随机数据:
--向class表插入数据
insert into class(card) values(floor(rand()*100));
--向book表插入数据
insert into book(card) values(floor(rand()*100));
反复执行多次可以插入多条数据。
select * from class left join book on class.card = book.card;
打印
+----+------+--------+------+
| id | card | bookid | card |
+----+------+--------+------+
| 10 | 6 | 9 | 6 |
| 12 | 13 | 10 | 13 |
| 1 | 12 | NULL | NULL |
| 2 | 43 | NULL | NULL |
| 3 | 78 | NULL | NULL |
| 4 | 63 | NULL | NULL |
| 5 | 81 | NULL | NULL |
| 6 | 15 | NULL | NULL |
| 7 | 32 | NULL | NULL |
| 8 | 18 | NULL | NULL |
| 9 | 92 | NULL | NULL |
| 11 | 51 | NULL | NULL |
| 13 | 16 | NULL | NULL |
| 14 | 39 | NULL | NULL |
| 15 | 47 | NULL | NULL |
| 16 | 21 | NULL | NULL |
| 17 | 63 | NULL | NULL |
| 18 | 53 | NULL | NULL |
| 19 | 78 | NULL | NULL |
| 20 | 31 | NULL | NULL |
+----+------+--------+------+
20 rows in set (0.00 sec)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
性能测试
explain select * from class left join book on class.card = book.card;
打印
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | class | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | NULL |
| 1 | SIMPLE | book | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
type为all,全表扫描,且出现Using join buffer连接缓存,需要优化。
--向右表加索引
create index idx_book_card on book(card);
explain select * from class left join book on class.card = book.card;
打印
此时,book表的type变为ref,且Using join buffer消失。
drop index idx_book_card on book;
--向左表加索引
create index idx_class_card on class(card);
explain select * from class left join book on class.card = book.card;
打印
+----+-------------+-------+------------+-------+---------------+----------------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+----------------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | class | NULL | index | NULL | idx_class_card | 4 | NULL | 20 | 100.00 | Using index |
| 1 | SIMPLE | book | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+-------+---------------+----------------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
此时只是class的type变为index,其他未变化。
--指定class表先载入
explain select * from class straight_join book on class.card = book.card;
打印
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | class | NULL | ALL | NULL | NULL | NULL | NULL | 100 | 100.00 | NULL |
| 1 | SIMPLE | book | NULL | ALL | NULL | NULL | NULL | NULL | 1000 | 10.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
--指定book表先载入
explain select * from book straight_join class on class.card = book.card;
打印
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | book | NULL | ALL | NULL | NULL | NULL | NULL | 1000 | 100.00 | NULL |
| 1 | SIMPLE | class | NULL | ALL | NULL | NULL | NULL | NULL | 100 | 10.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
straight_join
实现强制多表的载入顺序,选择其左边的表先载入;而join语法是根据“哪个表的结果集小,就以哪个表为驱动表”来决定谁先载入的
三、三表优化
建立新表并插入多条数据
--手机
create table phone(
phoneid int unsigned not null primary key auto_increment,
card int unsigned not null
);
insert into phone(card) values(floor(rand()*20));
进行测试
打印
+----+-------------+-------+------------+------+----------------+----------------+---------+-----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+----------------+----------------+---------+-----------------+------+----------+-------------+
| 1 | SIMPLE | class | NULL | ALL | NULL | NULL | NULL | NULL | 100 | 100.00 | NULL |
| 1 | SIMPLE | book | NULL | ref | idx_book_card | idx_book_card | 4 | demo.class.card | 1 | 100.00 | Using index |
| 1 | SIMPLE | phone | NULL | ref | idx_phone_card | idx_phone_card | 4 | demo.book.card | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+----------------+----------------+---------+-----------------+------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)
四、索引优化
1.建表:
create table staffs(
id int primary key auto_increment,
name varchar(24) not null default "",
age int not null default 0,
pos varchar(20) not null default "",
add_time timestamp not null default CURRENT_TIMESTAMP
)charset utf8;
create table user(
id int not null auto_increment primary key,
name varchar(20) default null,
age int default null,
email varchar(20) default null
) engine=innodb default charset=utf8;
打印
Query OK, 0 rows affected (0.02 sec)
Query OK, 0 rows affected (0.01 sec)
2.插入数据:
insert into staffs(`name`,`age`,`pos`,`add_time`) values('z3',22,'manager',now());
insert into staffs(`name`,`age`,`pos`,`add_time`) values('July',23,'dev',now());
insert into staffs(`name`,`age`,`pos`,`add_time`) values('2000',23,'dev',now());
insert into user(name,age,email) values('1aa1',21,'b@163.com');
insert into user(name,age,email) values('2aa2',22,'a@163.com');
insert into user(name,age,email) values('3aa3',23,'c@163.com');
insert into user(name,age,email) values('4aa4',25,'d@163.com');
打印
Query OK, 1 row affected (0.01 sec)
Query OK, 1 row affected (0.00 sec)
Query OK, 1 row affected (0.01 sec)
Query OK, 1 row affected (0.00 sec)
Query OK, 1 row affected (0.00 sec)
Query OK, 1 row affected (0.00 sec)
3.建立复合索引:
create index idx_staffs_nameAgePos on staffs(name,age,pos);
打印
Query OK, 0 rows affected (0.04 sec)
Records: 0 Duplicates: 0 Warnings: 0
4.口诀:
全值匹配我最爱,最左前缀要遵守;
解释:
全值匹配我最爱:
查询使用的字段和建立的索引对应的字段完全匹配。
explain select * from staffs where name = 'July';
打印
+----+-------------+--------+------------+------+-----------------------+-----------------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+-----------------------+-----------------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | staffs | NULL | ref | idx_staffs_nameAgePos | idx_staffs_nameAgePos | 74 | const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+------+-----------------------+-----------------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.01 sec)
此时key_len为74,只用到了name。
explain select * from staffs where name = 'July' and age = 23;
打印
此时key_len变为78,索引多了一个age。
explain select * from staffs where name = 'July' and age = 23 and pos = 'dev';
打印
+----+-------------+--------+------------+------+-----------------------+-----------------------+---------+-------------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+-----------------------+-----------------------+---------+-------------------+------+----------+-------+
| 1 | SIMPLE | staffs | NULL | ref | idx_staffs_nameAgePos | idx_staffs_nameAgePos | 140 | const,const,const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+------+-----------------------+-----------------------+---------+-------------------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
此时key_len变为140,索引多了一个pos。
最左前缀要遵守:
查询从索引的最左前列开始,并且不跳过索引中的列:
带头大哥不能死:
建立索引的第一个字段不能缺失,即查询从索引的最左前列开始。
explain select * from staffs where age = 23 and pos = 'dev';
打印
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | staffs | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 33.33 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
显然没有Using index condition,即没有使用到索引。
中间兄弟不能断:
建立索引的中间字段不能缺失,即不能跳过索引中的列。
explain select * from staffs where name = 'July' and pos = 'dev';
打印
+----+-------------+--------+------------+------+-----------------------+-----------------------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+-----------------------+-----------------------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | staffs | NULL | ref | idx_staffs_nameAgePos | idx_staffs_nameAgePos | 74 | const | 1 | 33.33 | Using index condition |
+----+-------------+--------+------------+------+-----------------------+-----------------------+---------+-------+------+----------+-----------------------+
1 row in set, 1 warning (0.01 sec)
key_len为74,说明用到了1个索引,即只用到了name,索引中的字段在where条件句中中间的字段不能缺失,否则缺失后面的字段索引将失效,如例中的pos字段即失效。
索引列上少计算:
不能
在where条件语句的索引列
上直接进行数值计算、调用函数。
explain select * from staffs where lower(name) = 'july';
打印
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | staffs | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100.00 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
type为all,全表扫描,索引失效。
explain select * from staffs where name = 'July' and age - 1 = 22;
打印
id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+-----------------------+-----------------------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | staffs | NULL | ref | idx_staffs_nameAgePos | idx_staffs_nameAgePos | 74 | const | 1 | 100.00 | Using index condition |
+----+-------------+--------+------------+------+-----------------------+-----------------------+---------+-------+------+----------+-----------------------+
1 row in set, 1 warning (0.01 sec)
key_len为74,只用到了1个索引,说明age索引失效,要想使用索引,可以在等号右边进行计算。
create index idx_add_yime on staffs(add_time);
explain select * from staffs where date(add_time) = '2019-12-16';
打印
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | staffs | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100.00 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
即使用函数会使索引失效。
范围之后全失效:
explain select * from staffs where name = 'july' and age > 25 and pos = 'dev';
打印
+----+-------------+--------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | staffs | NULL | range | idx_staffs_nameAgePos | idx_staffs_nameAgePos | 78 | NULL | 1 | 33.33 | Using index condition |
+----+-------------+--------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.01 sec)
有2个索引字段有效,即name、age有效,age为范围,所以之后的pos失效。
like百分写最右:
%、_写到字符串最右边,type为range。
explain select * from staffs where name like '%july%';
打印
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | staffs | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 33.33 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
模糊查询(字段值首位都有%),为全表查询,未使用索引。
explain select * from staffs where name like 'july%';
打印
+----+-------------+--------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | staffs | NULL | range | idx_staffs_nameAgePos | idx_staffs_nameAgePos | 74 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+--------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.01 sec)
字段值尾有%,能用到索引。
explain select * from staffs where name like '%july';
打印
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | staffs | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 33.33 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
显然,%位于字段值首时,又变为全表扫描,索引失效。
create index idx_user_nameage on user(name,age);
explain select name from user where name like '%aa%';
打印
+----+-------------+-------+------------+-------+---------------+------------------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------------------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | user | NULL | index | NULL | idx_user_nameage | 68 | NULL | 4 | 25.00 | Using where; Using index |
+----+-------------+-------+------------+-------+---------------+------------------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
select后的字段都必须为含有索引的字段的组合,才能使用索引,用全局索引或搜索引擎解决问题。
explain select email from user where name like '%aa%';
打印
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | user | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 25.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
email字段不含有索引,所以为全表扫描,不能使用索引。
覆盖索引不写星:
select不能用*,一般根据需要用什么字段select就接什么字段。
explain select name from staffs where name = 'july' and age = 23 and pos = 'dev';
打印
+----+-------------+--------+------------+------+-----------------------+-----------------------+---------+-------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+-----------------------+-----------------------+---------+-------------------+------+----------+-------------+
| 1 | SIMPLE | staffs | NULL | ref | idx_staffs_nameAgePos | idx_staffs_nameAgePos | 140 | const,const,const | 1 | 100.00 | Using index |
+----+-------------+--------+------------+------+-----------------------+-----------------------+---------+-------------------+------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
不等空值还有or,索引失效要少用:
explain select * from staffs where name != 'july';
打印
+----+-------------+--------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | staffs | NULL | ALL | idx_staffs_nameAgePos | NULL | NULL | NULL | 3 | 66.67 | Using where |
+----+-------------+--------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
即为全表扫描,且未使用索引。
explain select * from staffs where name is null;
打印
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Impossible WHERE |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------+
1 row in set, 1 warning (0.01 sec)
因为建表时标记name为非空,所以这里为Impossible WHERE。
explain select * from staffs where name is not null;
打印
+----+-------------+--------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | staffs | NULL | ALL | idx_staffs_nameAgePos | NULL | NULL | NULL | 3 | 66.67 | Using where |
+----+-------------+--------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
也为全表扫描。
explain select * from staffs where name = 'july' or name = 'tom';
打印
+----+-------------+--------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | staffs | NULL | ALL | idx_staffs_nameAgePos | NULL | NULL | NULL | 2 | 100.00 | Using where |
+----+-------------+--------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
varchar引号不可丢,SQL高级也不难:
explain select * from staffs where name = '2000';
打印
+----+-------------+--------+------------+------+-----------------------+-----------------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+-----------------------+-----------------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | staffs | NULL | ref | idx_staffs_nameAgePos | idx_staffs_nameAgePos | 74 | const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+------+-----------------------+-----------------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.01 sec)
没有引号时
explain select * from staffs where name = 2000;
打印
+----+-------------+--------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | staffs | NULL | ALL | idx_staffs_nameAgePos | NULL | NULL | NULL | 2 | 50.00 | Using where |
+----+-------------+--------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
1 row in set, 3 warnings (0.00 sec)
即没有引号时MySQL也能隐式转换为char型,可以正常运行实现功能、查询到数据,但是索引会失效,成为全表扫描,降低查询效率。
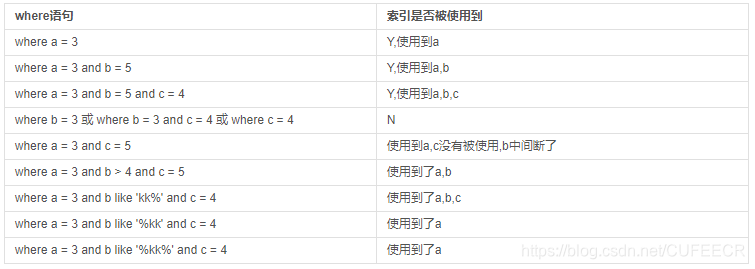
5.练习:
假设index(a,b,c),如下图
五、排序优化
1.分析
观察,至少跑一天,看看生产的慢SQL情况,问题复现;
开启慢查询日志,设置阙值,比如超过5秒钟的就是慢SQL,并抓取出来;
explain + 慢SQL分析;
show profile查询SQL在MySQL服务器里面的执行细节;
进行SQL数据库服务器的参数调优(运维 or DBA来做)。
2.永远小表驱动大表
小表驱动大表,即小的数据集驱动大的数据集。
for i in range ( 5 ) :
for j in range ( 1000 ) :
pass
for i in range ( 1000 ) :
for j in range ( 5 ) :
pass
如果小的循环在外层,对于数据库连接来说就只连接5次,进行5000次操作,如果1000在外,则需要进行1000次数据库连接,从而浪费资源,增加消耗。这就是为什么要小表驱动大表。
https://blog.csdn.net/akunshouyoudou/article/details/90518955
。
https://jq.qq.com/?_wv=1027&k=5m5AduZ
Python极客社区
,在我的公众号里,经常会分享很多Python的文章,而且也分享了很多工具、学习资源等,另外回复“电子书”还可以获取十本我精心收集的Python电子书。