
作者:zhaikun 风控建模屌丝一枚,现居于北京
个人微信公众号:Python数据分析与评分卡建模
本文数据获取:关注Python爱好者社区微信公众号,回复B卡。
评分卡主要有三种,申请评分卡、行为评分卡、催收评分卡,也就是俗称的A卡、B卡、C卡。
申请评分卡要求最为严格,也最为重要,可解释性也要求最强,一般用逻辑回归创建,感兴趣的同学可以参考一本书,叫:信用风险评分卡研究-基于SAS的开发与实施。虽然是用SAS写的,但是原理是共通的;
在机器学习大当其道的今天,行为评分卡与催收评分卡可以尝试用机器学习模型,比如随机森林、GBDT、Xgboost等。
A卡与B卡最主要的区别就是其作用时间点不一样,所选特征不一样。
申请评分卡用于贷前,行为评分卡用于放款后,根据贷款人的消费习惯,还款情况等一些信用特征,来预估用户M3+(欠款失联、委外催收)的概率。
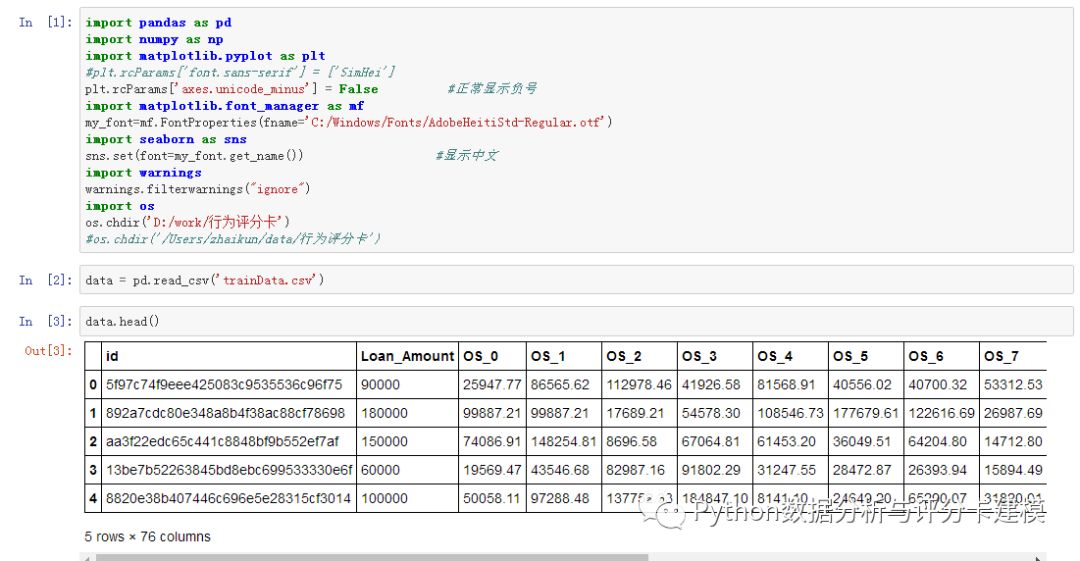

20000多行,76个特征,特征名是英文,相信大家不好理解,体贴的我转成中文了。
继续缺失值可视化一下

没缺失值
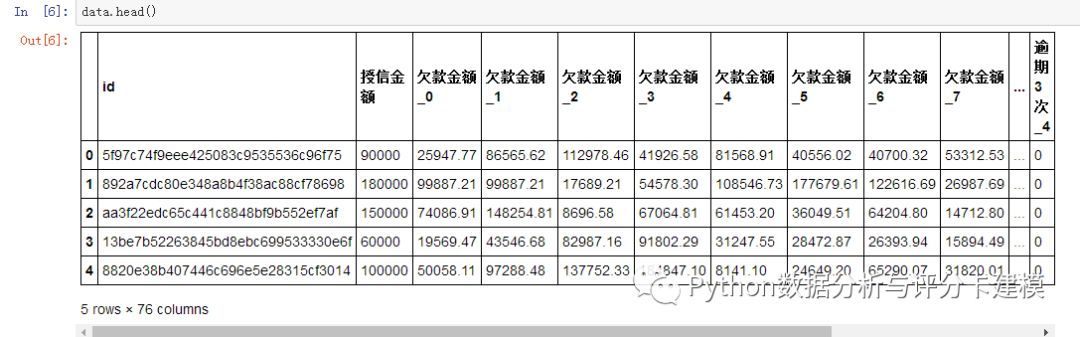
特征衍生:


变成115个特征了。
区分连续变量和分类变量:

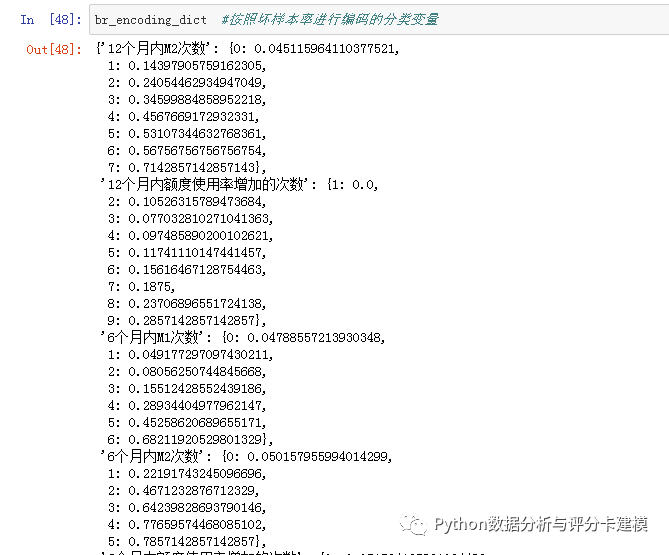
正常机器学习的话,应该会进行one-hot编码和归一化了,但是评分卡的话,我还是用传统的卡方分箱和woe编码进行转换
关于卡方分箱,一个大神提供了解决思路,感兴趣的同学可以看:
https://www.aaai.org/Papers/AAAI/1992/AAAI92-019.pdf
https://github.com/lisette-espin/pychimerge
之后数据变成这样:
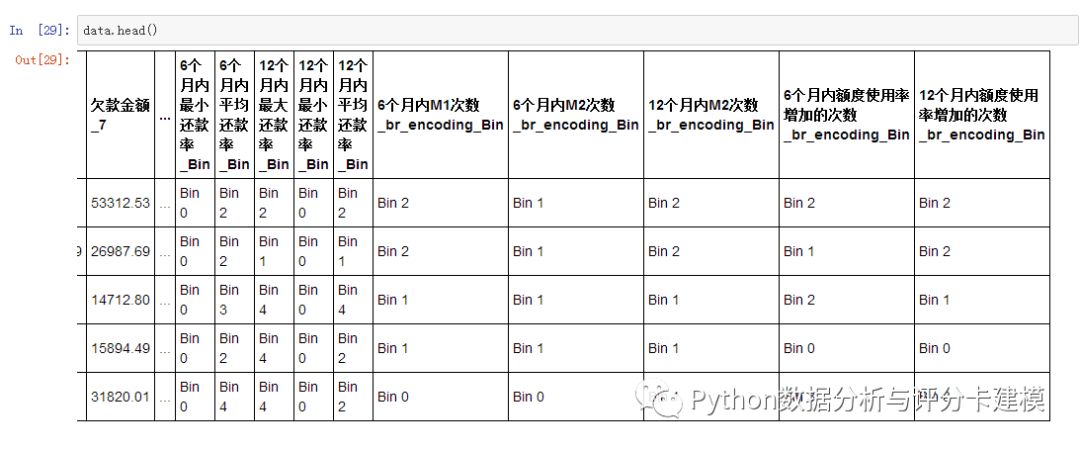

185列了。


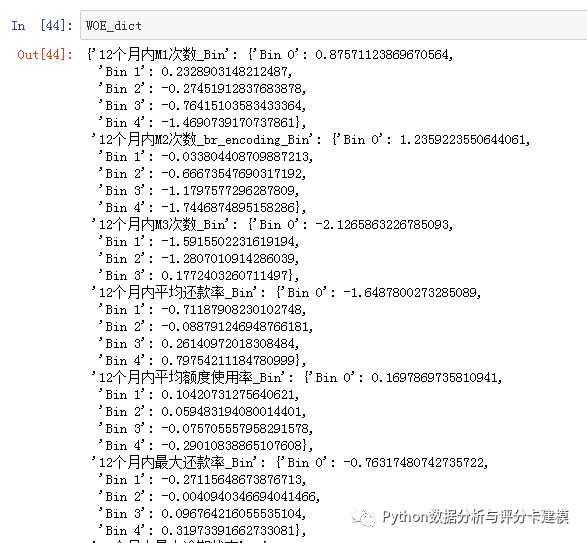

IV排序后,选择IV>0.02的变量,共58个变量IV>0.02,不知道什么是IV的同学可以参考下我第一篇文章:利用lending_club数据创建申请评分卡

多变量分析,保留相关性低于阈值0.6的变量,剩余27个变量

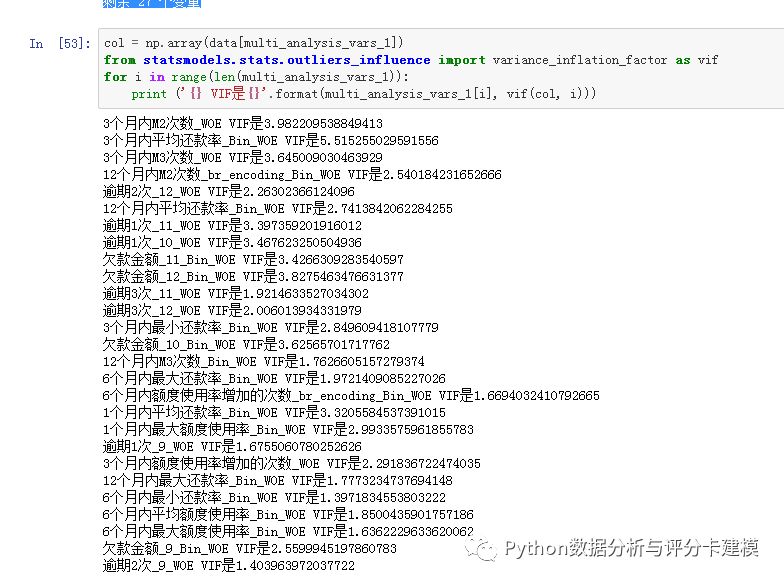
逻辑回归对共线性敏感,我们判断下VIF:
接下来看特征分布,考虑采样:

现在再次预览
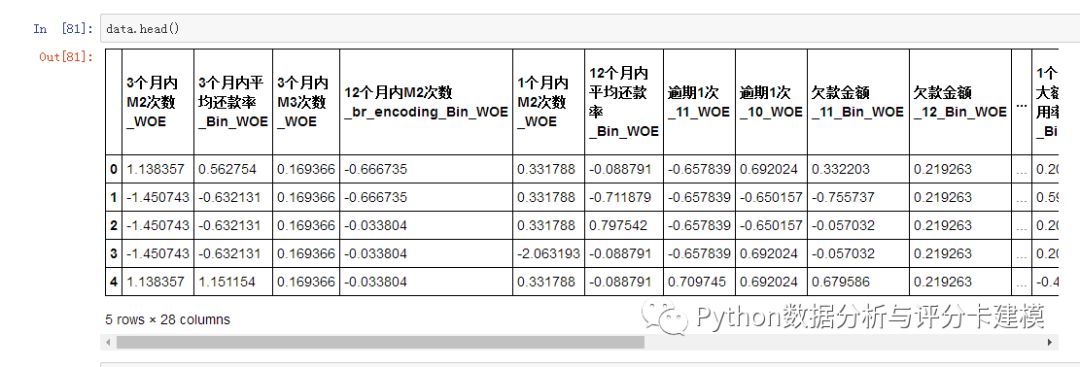

剩余28个变量了。
接下来我们进行显著性分析,删除P值不显著的变量,剩余12个变量了。

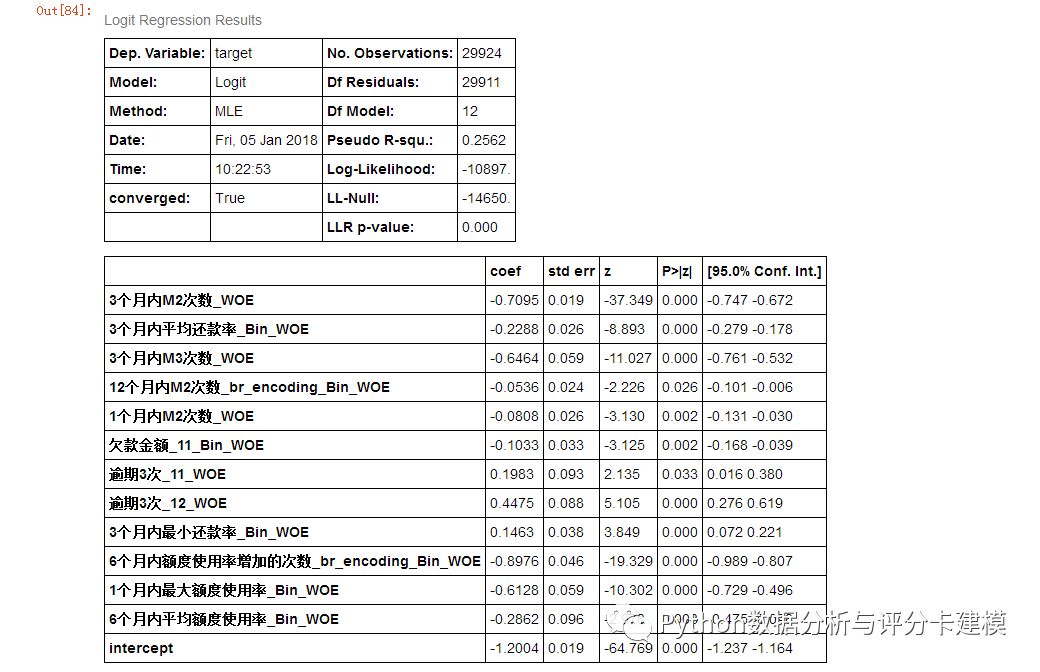
正常来说,系数应该为负,如果是正的的话,说明有共线性。我们单独检验下

这三个变量系数确实为负,那还要继续筛选变量。
这时候我们用Xgboost计算变量重要性,进行筛选
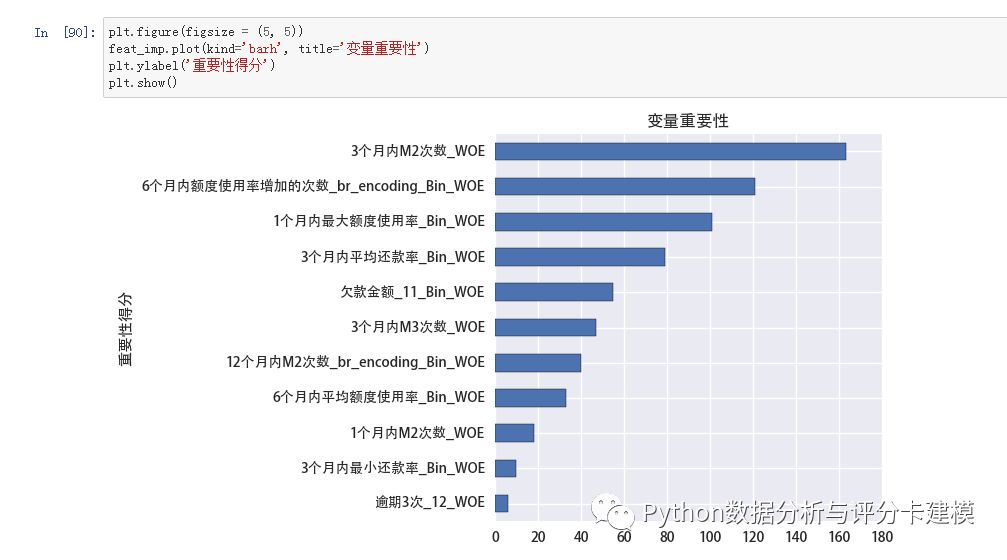
先选择前5个最重要的变量放入逻辑回归模型,计算系数和显著性。

都是符合我们要求的。
继续往逻辑回归模型里面加变量,直至不显著或系数为正为止

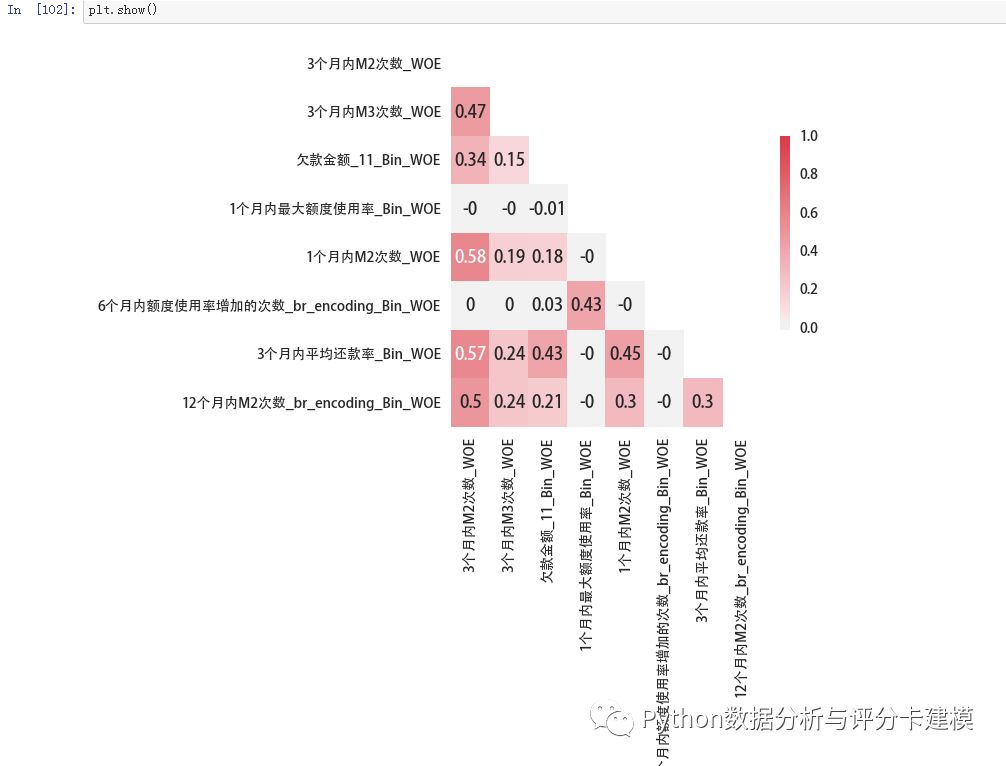
这8个变量,计算相关系数矩阵,可视化一下:
建模:
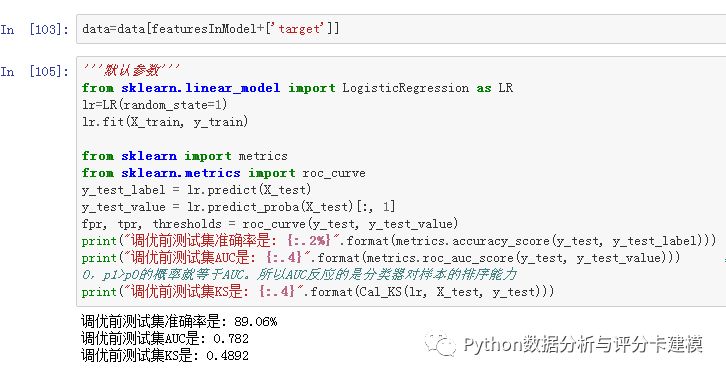
评价指标还可以,模型可用。
学习曲线判断是否过拟合:

最终集中于一点,效果还是不错的。
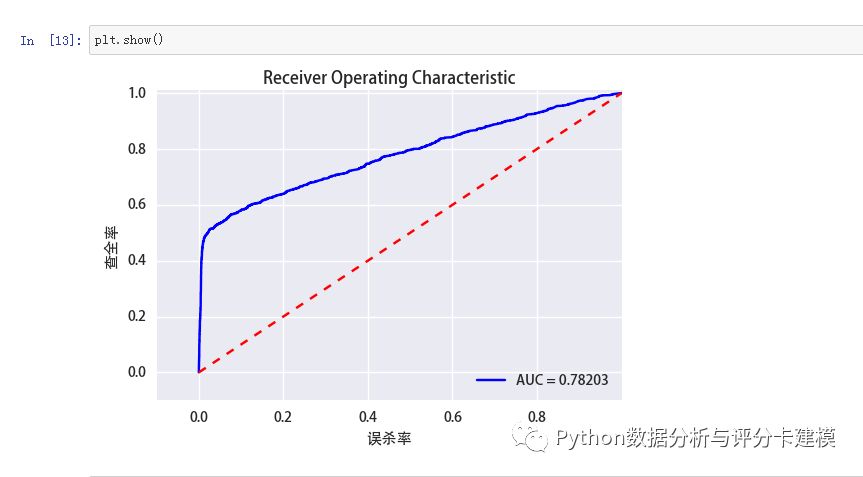
ROC曲线:
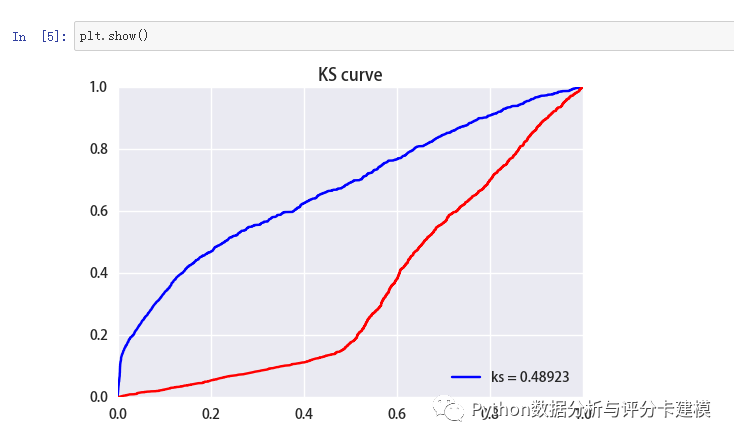
KS曲线:
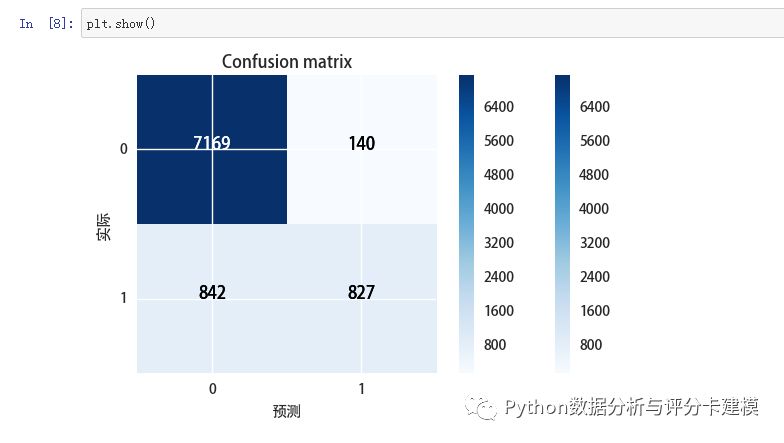
混淆矩阵:
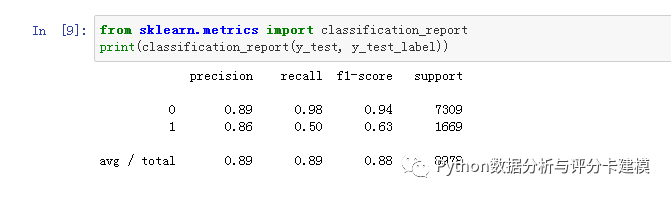
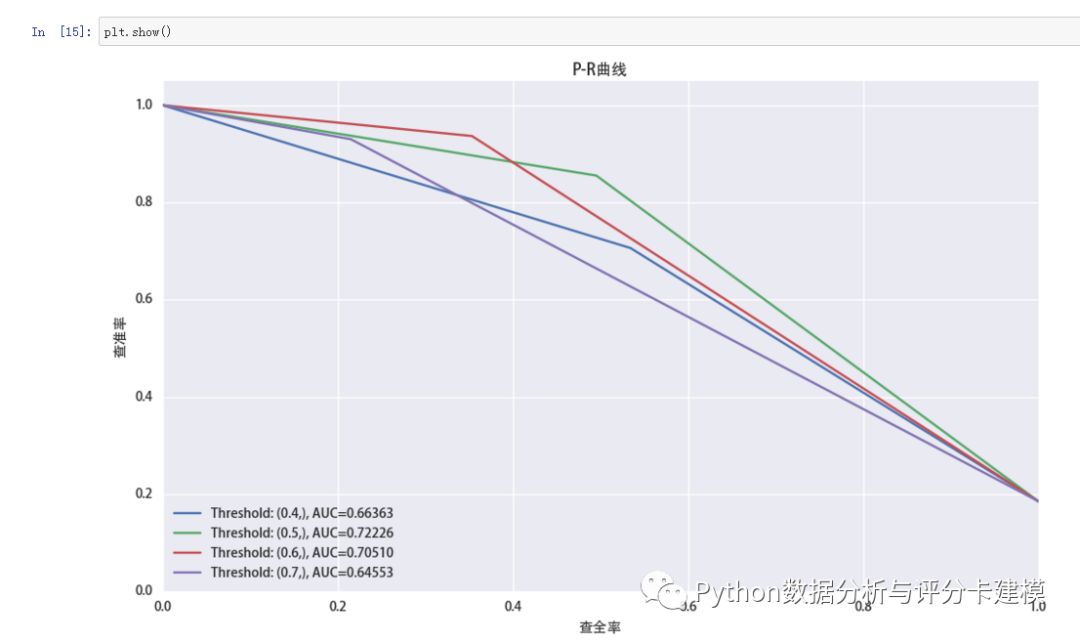
评分卡要有分数。我们看下分数的分布:
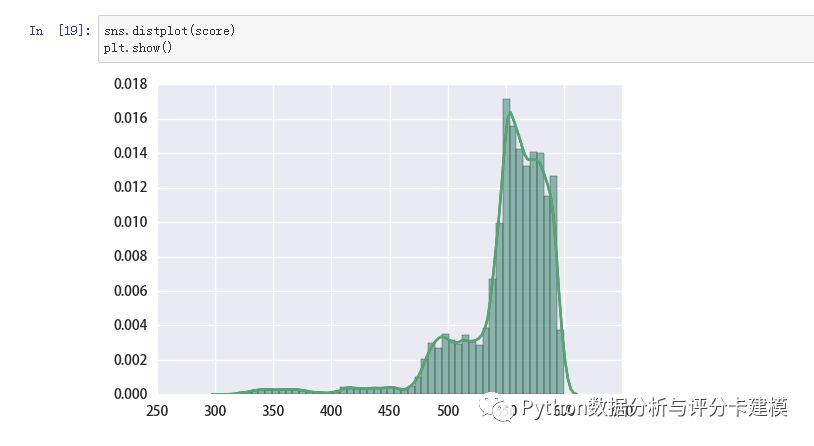
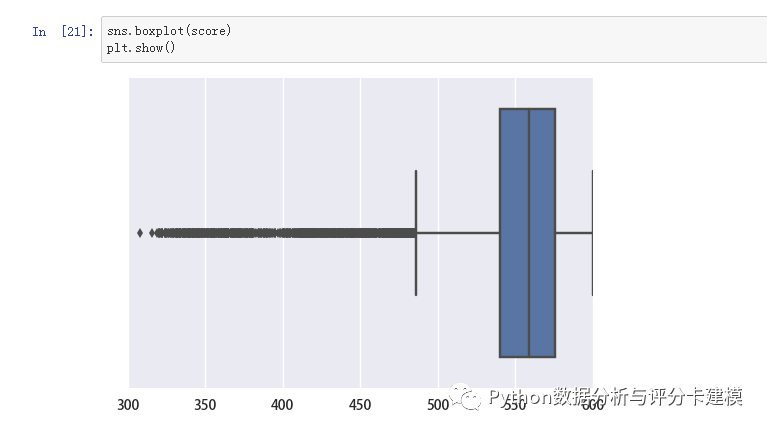
看下评分表现:
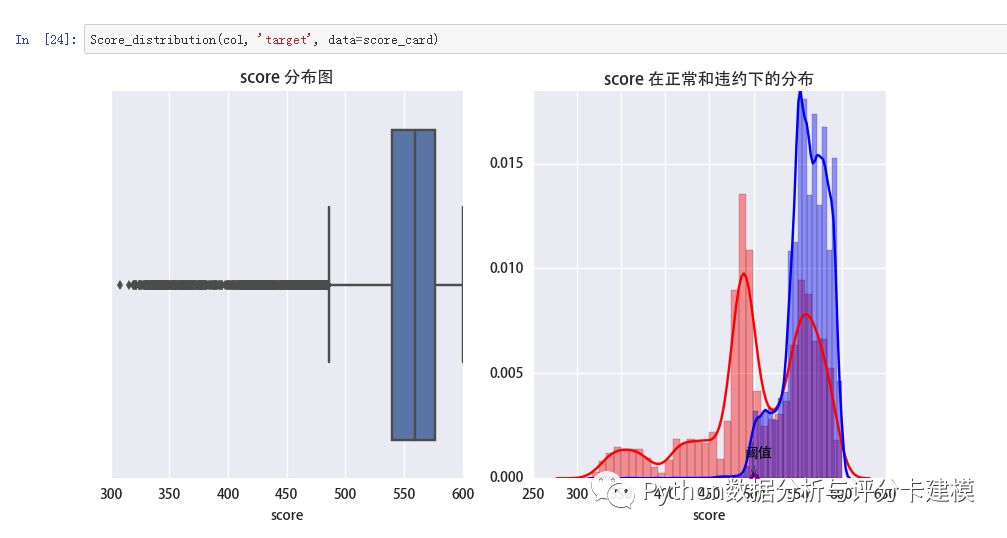
本文数据获取:关注Python爱好者社区微信公众号,回复B卡。
区分的还算比较明显

Python爱好者社区历史文章大合集:
Python爱好者社区历史文章列表(每周append更新一次)
 福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
关注后在公众号内回复“课程”即可获取:
小编的Python入门视频课程!!!
崔老师爬虫实战案例免费学习视频。
丘老师数据科学入门指导免费学习视频。
陈老师数据分析报告制作免费学习视频。
玩转大数据分析!Spark2.X+Python 精华实战课程免费学习视频。
丘老师Python网络爬虫实战
免费学习视频。










