点击上方 “AirPython”,选择“置顶公众号”
第一时间获取 Python 技术干货!
很多人都是在朋友圈装死,微博上蹦迪。
微信朋友圈已经不是一个可以随意发表心情的地方了,微博才是!
本文教你如何用 Python 自动通知女神微博情绪变化,从今天开始做一个贴心小棉袄。为了及时获取这些消息,三步可以实现:
你需要注册一个微博账户,找到你微博账户的 Cookie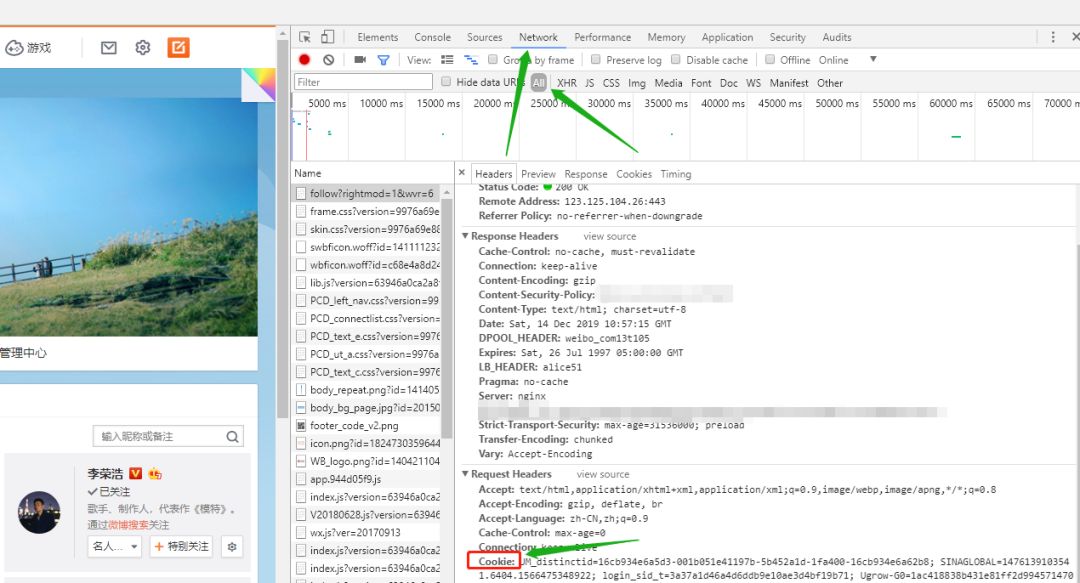
然后找到你需要关注的微博用户的 id,下面以李荣浩为例: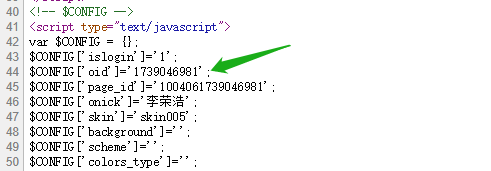
或者直接去用户主页查看,进入指定用户主页,如李荣浩的主页 :https://m.weibo.cn/u/1739046981?uid=1739046981&luicode=10000011&lfid=231093_-_selffollowed先根据这些信息设置好自己的账号,由于最新的微博内容肯定在第一页,设置好首页微博内容的 url
user_id = YOUR_ID
cookie = {"Cookie": "YOUR_COOKIE"}
url = 'http://weibo.cn/%d/profile?page=1'%user_id
html = requests.get(url, cookies = cookie).content
print ('user_id和cookie读入成功')
有了这些信息以后,我们就可以爬取微博内容啦,这里需要注意的是我们需要加一个第一条微博的判断。
page_num = 1
nickname = None
weibo = None
try:
json = r.get(
('https://m.weibo.cn/api/container/getIndex?'
'is_search[]=0&'
'visible[]=0&'
'is_all[]=1&'
'is_tag[]=0&'
'profile_ftype[]=1&'
'page={0}&'
'jumpfrom=weibocom&'
'sudaref=weibo.com&'
'type=uid&'
'value={1}&'
'containerid=107603{1}'
).format(page_num, uid),
verify=False,
).json()
except:
return None, None
if json['ok'] == 0:
print('sth wrong')
return None, None
else:
for card in json['cards']:
if card['card_type'] == 9:
weibo = [
card['mblog']['created_at'],
BeautifulSoup(
card['mblog']['text'], 'lxml'
).text.replace(' \u200b\u200b\u200b', ''),
*get_comments_from_one_weibo(
card['mblog']['id']),
]
这样的话我们就可以获取到女神的最新微博啦~下面要做的就是根据获取到的微博数据来分析情感内容。
这部分仅对文本内容有效,如果是图片内容就直接通知你内容不做情感分析。这里主要介绍一下情绪分的计算逻辑,情感词典和完整的实现逻辑后台回复「微博通知」获取,下次再专门写一篇针对文本情绪评分的内容。简化的情感分数计算逻辑:所有情感词语组的分数之和
两情感词之间的所有否定词和程度副词与这两情感词中的后一情感词构成一个情感词组,即 notWords + degreeWords + sentiWords,
例如不是很开心,其中不是为否定词,很为程度副词,开心为情感词,那么这个情感词语组的分数为:finalSentiScore = (-1) ^ 1 * 1.25 * 3.546其中1指的是一个否定词,1.25 是程度副词的数值,3.546 是开心的情感分数。finalSentiScore = (-1) ^ (num of notWords) * degreeNum * sentiScorefinalScore = sum(finalSentiScore)def scoreSent(senWord, notWord, degreeWord, segResult):
W = 1
score = 0
senLoc = senWord.keys()
notLoc = notWord.keys()
degreeLoc = degreeWord.keys()
senloc = -1
for i in range(0, len(segResult)):
if i in senLoc:
senloc += 1
score += W * float(senWord[i])
if senloc 1:
for j in range(senLoc[senloc], senLoc[senloc + 1]):
if j in notLoc:
W *= -1
elif j in degreeLoc:
W *= float(degreeWord[j])
if senloc 1:
i = senLoc[senloc + 1]
return score
通过这个计算逻辑最终输出整条微博的情绪评分,在做这个最重要的是要有好用的语料库,定义好正向情感词和负向情感词。
基础情感词典已经有整理好了的情感词典。使用的是大连理工大学的情感词汇本体库,停用词表使用哈工大的停用词表。https://blog.csdn.net/qq_22765745/article/details/70947728当我们获取到新的微博内容时,就需要将消息推送到我们的邮箱,这时候,我们需要添加判定条件,判断是否执行邮件提醒。这个判断条件与爬取最新微博的判断设置成一致。python 发邮件需要掌握两个模块的用法,smtplib 和 email,这俩模块是 python 自带的,只需 import 即可使用。smtplib 模块主要负责发送邮件,email 模块主要负责构造邮件。smtplib 模块主要负责发送邮件:是一个发送邮件的动作,连接邮箱服务器,登录邮箱,发送邮件(有发件人,收信人,邮件内容)。email 模块主要负责构造邮件:指的是邮箱页面显示的一些构造,如发件人,收件人,主题,正文,附件等。from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.mime.image import MIMEImage
import smtplib
msg = MIMEMultipart()
在邮件中插入微博正文,同时将情绪分值添加到邮件正文里:
df_text="Hi!\n你的女神新发了一条微博,情绪分值只有 %s \n快去看看吧!"% score
msgtext = MIMEText(df_text, 'plain'
, 'utf-8')
msg.attach(msgtext)
email_host= ''
sender = ''
password =''
receiver = ''
try:
smtp = smtplib.SMTP(host=email_host)
smtp.connect(email_host,port)
smtp.starttls()
smtp.login(sender, password)
smtp.sendmail(sender, receiver.split(',') , msg.as_string())
smtp.quit()
print('发送成功')
except Exception:
print('发送失败')
smtplib.SMTP():实例化SMTP()
connect(host,port):
email_host:指定连接的邮箱服务器。常用邮箱的smtp服务器地址如下:
新浪邮箱:smtp.sina.com
163网易邮箱:smtp.163.com。
port:指定连接服务器的端口号,默认为25
login(user,password):
sender:登录邮箱的用户名。
password:登录邮箱的密码(网易邮箱一般是网页版,需要用到客户端密码,需要在网页版的网易邮箱中设置授权码,该授权码即为客户端密码)
sendmail(from_addr,to_addrs,msg,…):
sender:邮件发送者地址
receiver:邮件接收者地址
msg:邮件内容
quit():用于结束SMTP会话
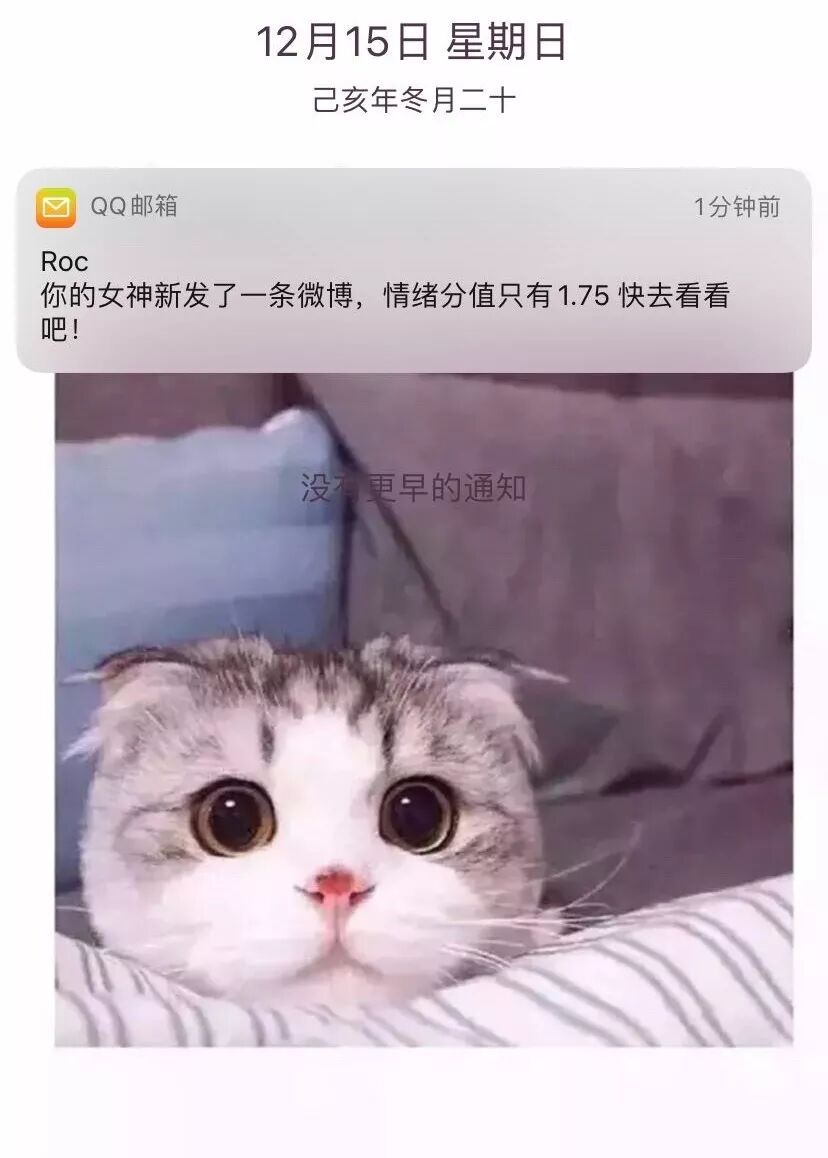
如果你觉得文章还不错,请大家点赞分享下。你的肯定是我最大的鼓励和支持。








