
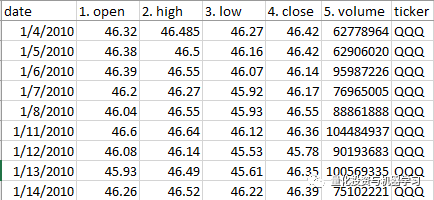
选股部分股票的Open、High、Low、Close和Volume。
常用的量价技术指标:Chaikin A/D、BBAND、CCI、EMA、MACD、OBV、RSI、SMA和STOCH。
▍简单移动平均线
▍指数移动平均线

▍随机指标
▍累积/派发线
▍布林带

▍OBV

起初,我们想建立一个单一的模型,使用所有ETF(QQQ、TQQQ、SPY、VTI、IWM)的数据来预测股票的长期价格趋势。如果未来20个交易日的收益为>3%,则我们将标签设为1,否则设为0。
然而,我们发现每个ETF之间的数据差异很大,因此我们决定为每个ETF构建单独的模型。最后只使用QQQ ETF数据集来构建我们的模型。
实验1(20天收益率3%作为标签)
LSTM: Test AUC 0.476

MLP Neural Network: Test AUC 0.577

Random Forest: Test AUC 0.917



我们使用QQQ数据集的最佳模型的AUC为0.917。我们以为我们找到了预测股市的方法。然而,情况并非如此,因为我们发现了我们的模型的一个主要缺陷。
按照惯例,在机器学习中,为了创建训练和测试集,需要对打乱数据集中数据顺序(shuffle)。这样做是必要的,因为我们希望在测试集中的数据与训练数据有相同的分布。然而,由于股票历史数据是时间序列,我们没办法知道随后几天的数据,因此对数据进行打乱意味着训练数据集有未来的数据(未来函数)。假设我们在2017年使用2018年的数据集训练我们的模型,我们实际上不能使用这个训练数据集来训练我们的模型,因为在2017年,2018年的数据还不存在。因此,在创建训练和测试数据集时,我们不能打乱数据。
对于我们的下一个模型,使用2010年到2016年的数据作为我们的训练集,使用2017年到2019年的数据作为我们的测试集。
遗憾的是,在这个模型中,使用相同的随机森林分类器,AUC分数显著下降到0.44。


正如在示例数据集中所看到的,所有这些行都有非常相似的20-MAs,开盘价和收盘价。
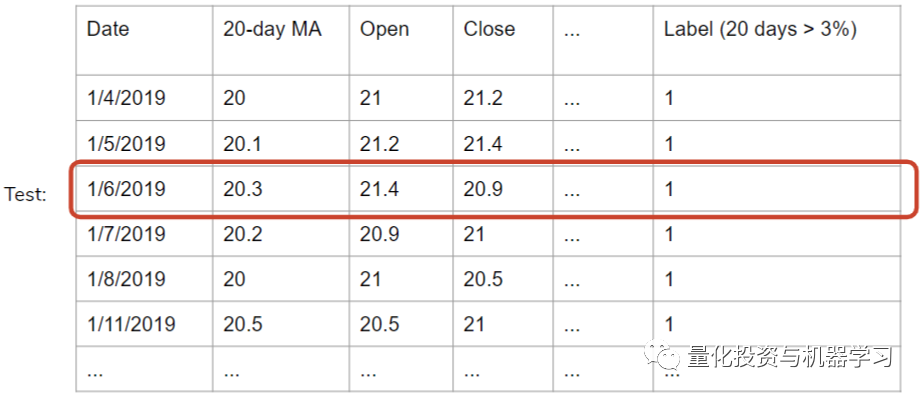
如果在2019年4月1日之后的20天里上涨了3%,那么在2019年4月1日左右的日子里也会上涨3%,对于任何股票来说都是如此,标签在20天内上涨的决定因素一般不会在第20天决定。这取决于这些记录在其20个未来交易期重叠的日子。在这种情况下,如果我们提取出2019年6月1日的数据,作为测试集并对其余的测试集进行训练,该模型肯定会为测试数据分配一个标签,因为它的所有特征都与围绕它的日期相似,这些日期形成了一个集群。这种方法的另一个问题是,如前所述,模型允许训练集使用未来数据进行预测。例如,训练集包括1/7/2019 -1/11/2019,预测1/6/2019,但这在现实世界是不可能做到的。

在这种情况下,训练集的收盘价格徘徊在每股20美元,但因为我们使用的是2019年作为测试集,价格是截然不同的,因此,该模型将它们正确的标签在分配表现不佳,特别是考虑到我们的记录有一系列的特征值,在训练集不存在。
当我们没有对原始数据集进行打乱时,当我们使用后来的日期作为测试集时,这就成了一个问题。在这种情况下,训练集的收盘价徘徊在每股20美元左右,但因为我们使用的是2019年作为测试集,价格是截然不同的,因此,模型在给他们分配正确的标签时将表现不佳,特别是考虑到我们的记录的特征,其值的范围在训练集中不存在。
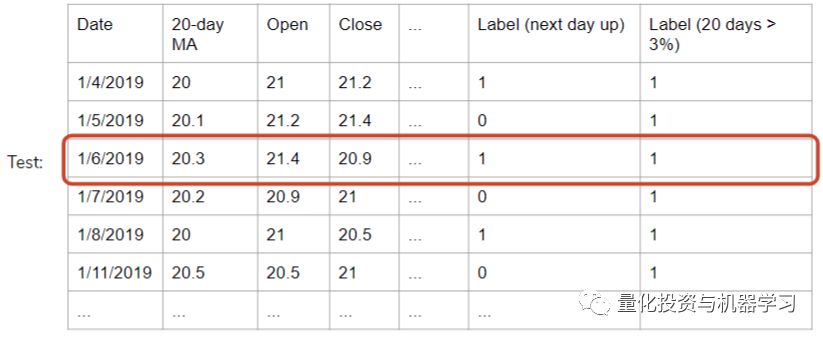
我们想到的解决方案是将我们的标签改为每日的股价变动。如果第二天的收盘价大于当天的收盘价,那么标签就是1。在这里,当天的股价是否会在第二天上涨是相互独立的,这解决了我们形成集群和使用未来数据的问题。
实验2(第二天价格上升 / 下降作为标签)
1、TPOT
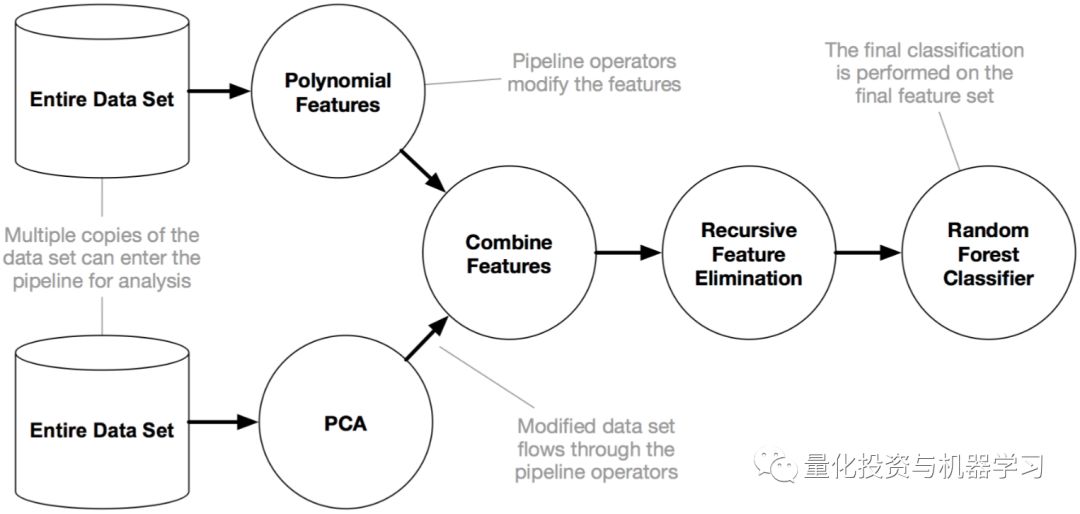
TPOT是一个开源的AutoML Python包,可以运行许多不同的特性工程和模型选择组合。TPOT自动创建许多pipeline,其中包括不同的特征工程方法(PCA、MaxAbsScaler、MinMaxScaler等),以及各种混合超参数的不同模型。

https://epistasislab.github.io/tpot/using/
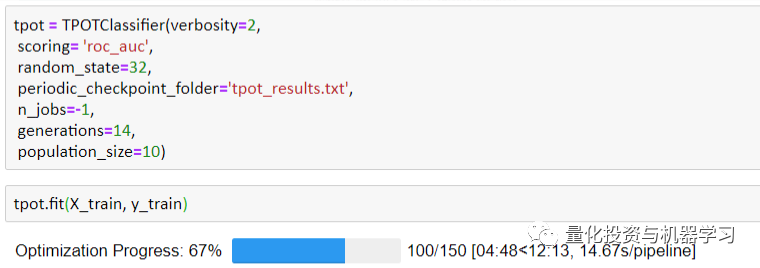
TPOT的性能在很大程度上取决于pipeline的数量和允许它运行的时间。pipeline总数等于POPULATION_SIZE + generation x OFFSPRING_SIZE,可以在TPOT的参数中确定。
由于我们只让TPOT运行150个pipeline,这只需要不到15分钟的时间,所以性能并不理想:测试AUC=0.509。然而,如果有足够的时间(几十个小时甚至几天),TPOT可以是一个非常强大和容易的工具来产生我们想要的结果。
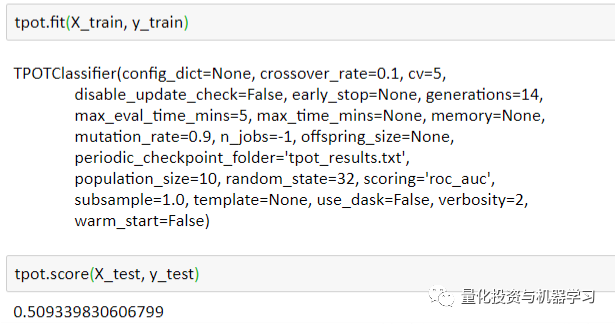
此外,TPOT会自动存储它搜索到的最佳pipeline,并允许用户将这些结果导出为.py文件。在本文中,TPOT对我数据进行PCA,并选择GaussianNB作为最佳分类模型。

2. XGBoost
使用XGBClassifier,除了学习率、最大深度、n_estimators和子样本之外,我们不需要配置太多。利用交叉验证和AUC评分指标对超参数进行优化。最后,利用优化后的超参数对X_train和y_train进行建模。测试集的准确率(不是AUC)为50.5%


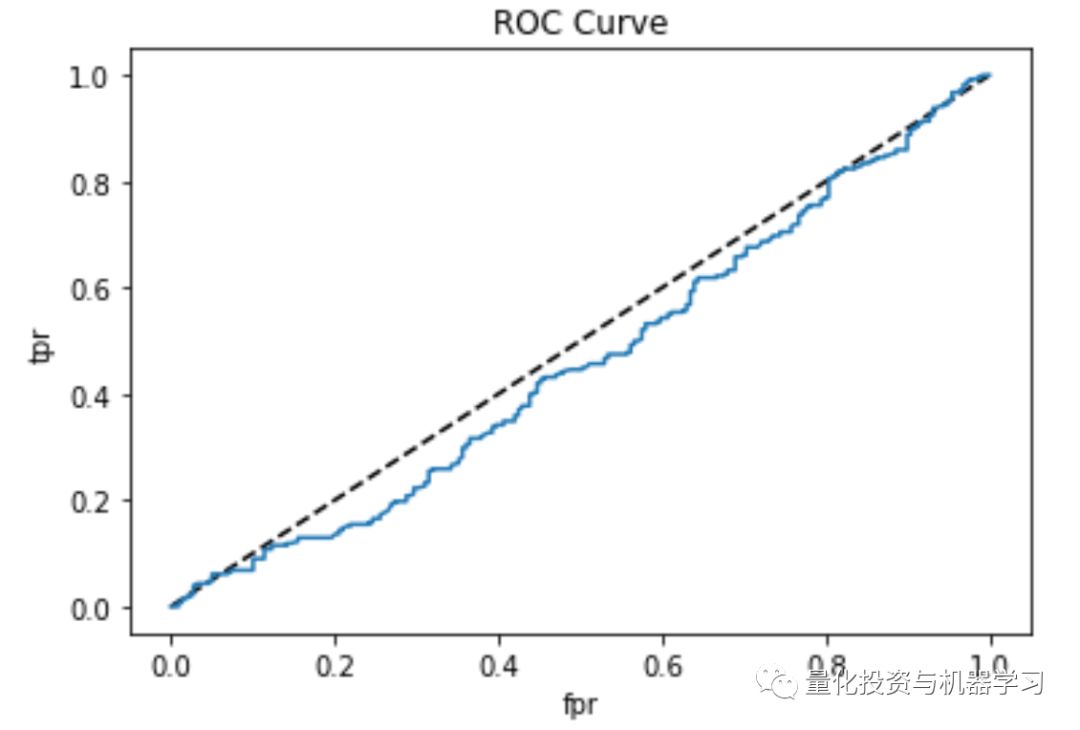
使用XGBClassifier:0.478 Test Set AUC得分。
3、随机森林
使用随机森林分类器,我们使用暴力网格搜索交叉验证来调整超参数。最佳参数为max_depth =3,min_samples_leaf = 3。




使用随机森林分类器:0.519 Test Set AUC得分。
4、谷歌AutoML
随着AutoML的日益流行,我们决定将数据集输入到谷歌Cloud AutoML,看看它是否能比我们更好地预测AUC分数。谷歌AutoML有一个非常友好的界面,它会在你上传数据集后自动吐出一些统计数据。

在我们这样的分类项目中,谷歌AutoML允许用户选择不同的性能指标来优化最终的模型。

仅仅经过一个小时的训练,它的AUC就达到了0.529,这是我们测试中最高的。值得注意的是,随机森林的AUC达到0.519,仅比谷歌AutoML低0.01。

技术分析的弱点:在金融领域,技术分析(使用历史股价预测未来股价)已被证明是徒劳的。进一步分析时可考虑其他特征:
1、Twitter/微博等:情绪分析。
2、电话会议记录:分析高管在电话会议中的语调;评估主管/分析师正在讨论的主题。
3、卫星数据:油井的卫星图像可以用来预测油价等。
4、······
上面这些可以总结为另类数据或者文本情绪数据。
有关另类数据的热点文章,请点击:
打败股市的唯一真正方法是获得额外的信息,比如获得未来的数据或提前知道季度收益结果,但这样做,要么导致不可能,要么违法。使用技术指标可以告诉我们部分情况,但预测第二天的股市走向太过随机,而且受到外部因素的影响,无法建立一个强有力的模型。
只有当用于训练模型的数据和模型与未来数据有相同的分布时,机器学习才是有用和有效的,而使用独立且波动的股市日收益率作为标签时,情况就不同了。
2020年第6篇文章
量化投资与机器学习微信公众号,是业内垂直于Quant、MFE、Fintech、AI、ML等领域的量化类主流自媒体。公众号拥有来自公募、私募、券商、期货、银行、保险资管、海外等众多圈内18W+关注者。每日发布行业前沿研究成果和最新量化资讯。










