近日旁边IOS同学请假在家嘿嘿嘿,徒留朕一个人孤零零的在墙角瑟瑟发抖,虽然公司空调开到28℃,还是融化不了朕冰冷的心
到这儿你可能会问,你们公司就两个人吗?
BUG
,啊呸,写代码才能维持生活这样子。
今天来聊聊Python下载视频那些事儿
python下载视频文件三步骤
:
拿到视频url,请求链接获取视频流,写入本地文件保存
import requests
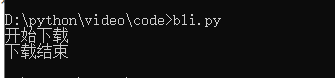
print ( "开始下载" )
url = 'https://vdept.bdstatic.com/65796c493957364e51574e65504b757a/474c6d4464633277/37715aae880a70427da12d5d682d3a534b3947470869ecc29530cc310a944c1ac684c3ab83e07d18f65784748120987a.mp4?auth_key=1578908333-0-0-a70ed19862afa01935265e5a32906867'
r = requests. get( url, stream= True )
with open ( 'test.mp4' , "wb" ) as mp4:
for chunk in r. iter_content( chunk_size= 1024 * 1024 ) :
if chunk:
mp4. write( chunk)
print ( "下载结束" )
点击运行,等待一会儿
(当然,这段代码也适用于大多数有色网站,嘿嘿嘿,你懂的)
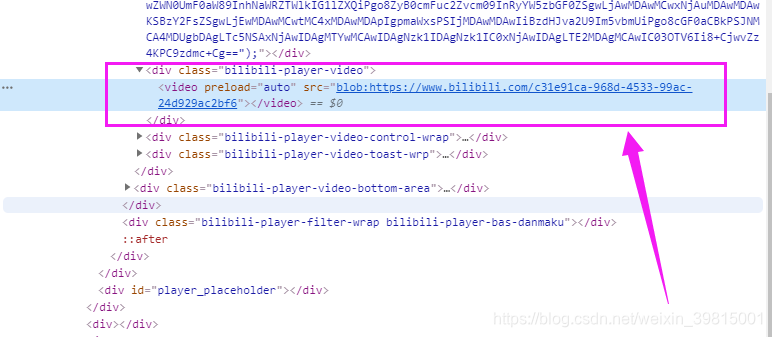
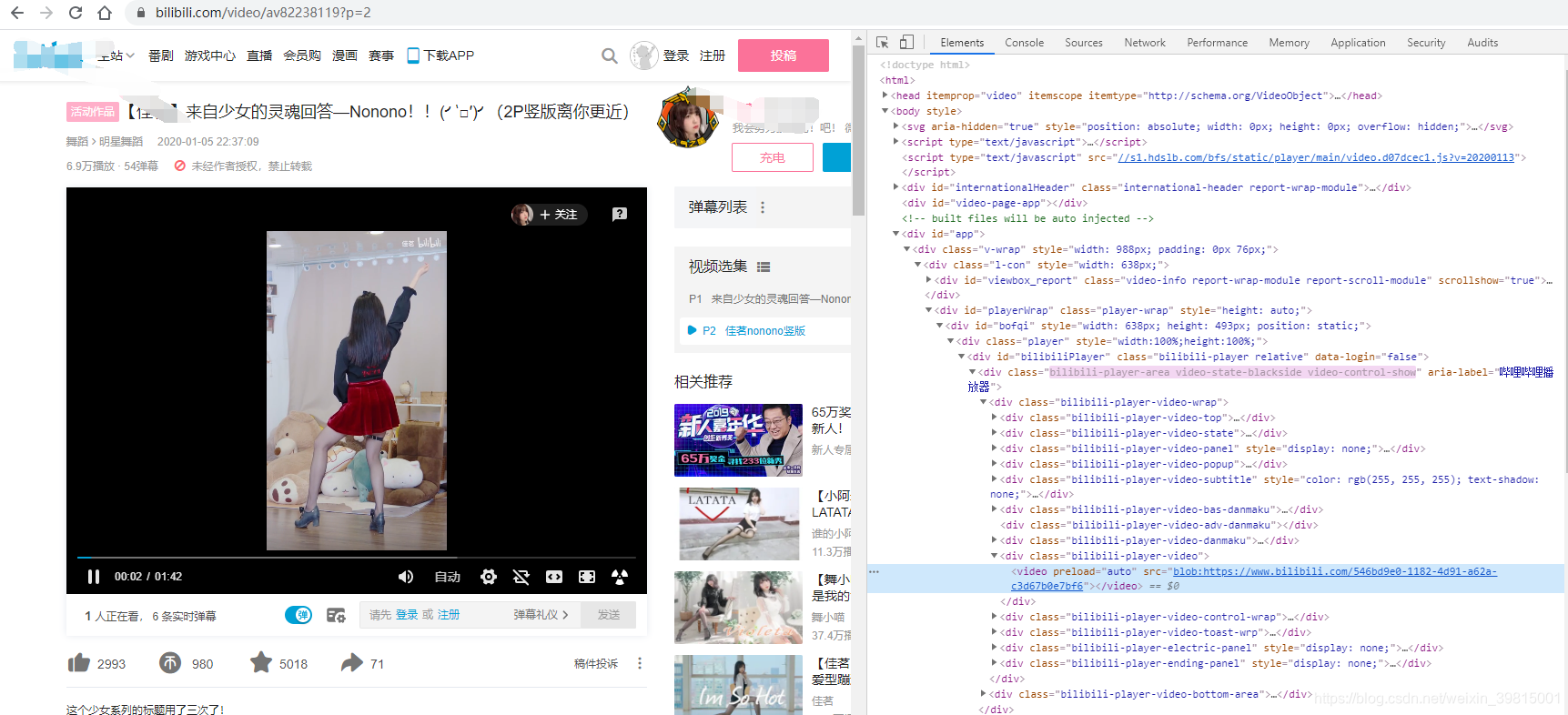
Blob URL / Object URL是一种伪协议,允许Blob和File对象用作图像,下载二进制数据链接等的URL源。生产场景往往是对切片格式的视频 m3u8 地址进行 blob 格式处理,其实并不是为了加密,因为浏览器还是会解析 blob 并去 get 请求对应的 m3u8 地址,使用 blob uri 的好处在于可以在一定层度上干扰爬虫。
简单的说,就是不能F12直接拿到视频的真实地址了
you-get
的东西出现在了朕的视野中。
pip3 install you-get
,正常情况下,这样就已经安装好了,如果出现特殊情况,请查阅官方文档:
https://github.com/soimort/you-get/wiki/%E4%B8%AD%E6%96%87%E8%AF%B4%E6%98%8E
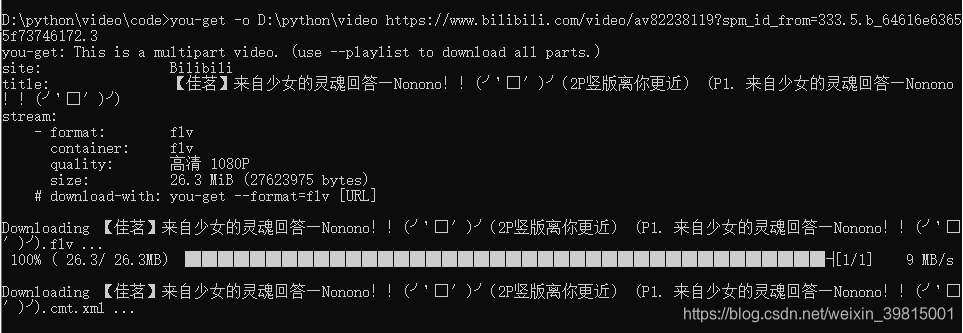
使用起来也非常简单,以B站小姐姐跳舞视频为例:
you- get - o D: \python\video https: // www. bilibili. com/ video/ av82238119?spm_id_from= 333.5 . b_64616e63655f73746172. 3
示例:
from you_get import common
common. any_download( url= 'https://www.bilibili.com/video/av82238119?spm_id_from=333.5.b_64616e63655f73746172.3' , info_only= False , output_dir= r'D:\python\video' , merge= True )
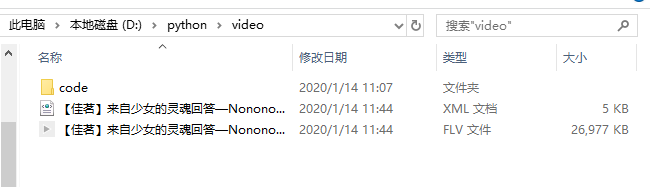
试运行一下,嘿嘿嘿,居然跑起来了,接下来的事情就好办了,比如我要B站小姐姐跳舞视频,示例步骤如下:
import requests
import random
import json
from you_get import common
header_list = [
{ "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" } ,
{ "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3676.400 QQBrowser/10.4.3469.400" } ,
{ "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36" } ,
{ "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362" }
]
if __name__ == "__main__" :
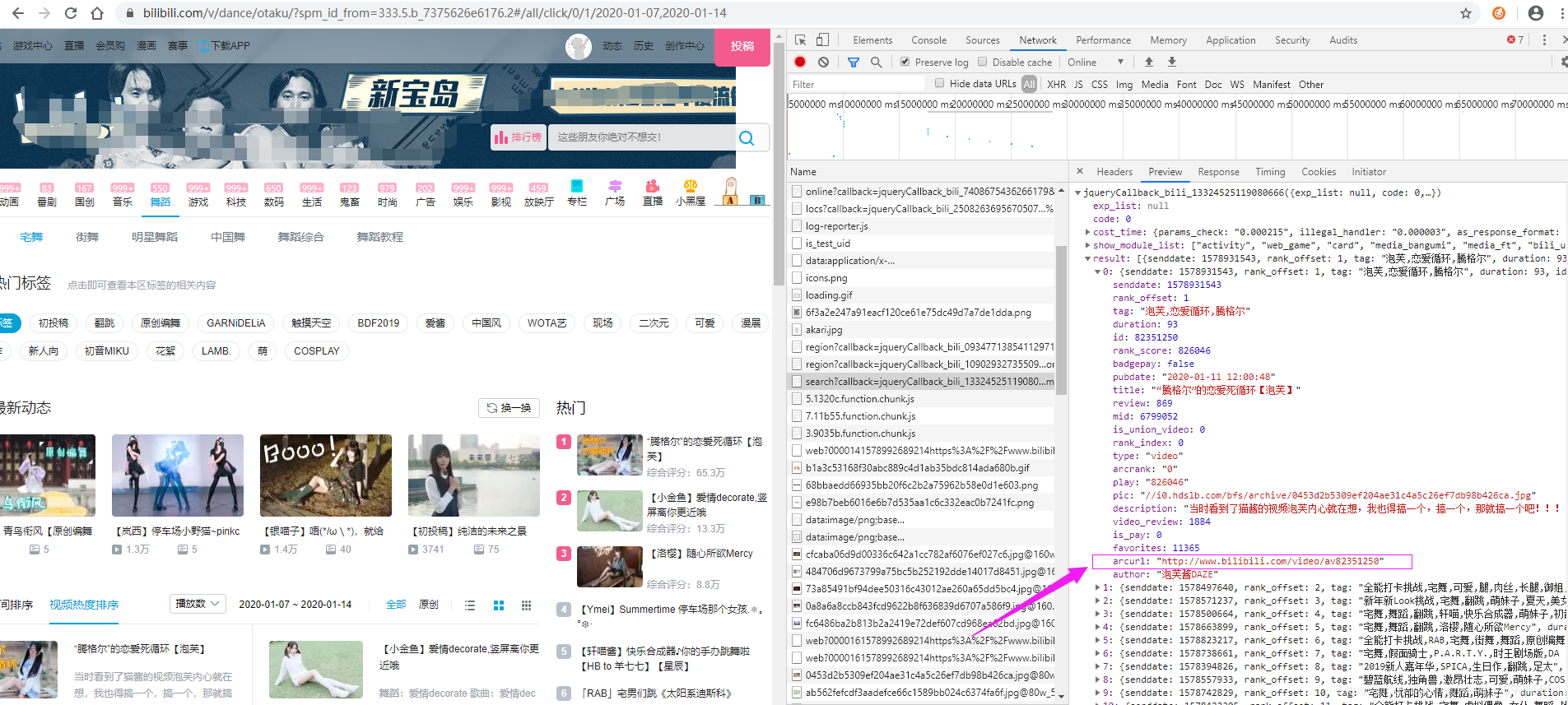
base_url = 'https://s.search.bilibili.com/cate/search?main_ver=v3&search_type=video&view_type=hot_rank&order=click©_right=-1&cate_id=20&page=1&pagesize=20&jsonp=jsonp&time_from=20200107&time_to=20200114&_=1578992689153'
headers = random. choice( header_list)
response = requests. get( url= base_url, headers= headers)
code = response. status_code
if code == 200 :
urls_json = json. loads( response. content)
for i in urls_json[ 'result' ] :
print ( i[ 'arcurl' ] )
common. any_download( url= i[ 'arcurl' ] , info_only= False , output_dir= r'D:\python\video' , merge= True )
print ( 'the end!' )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
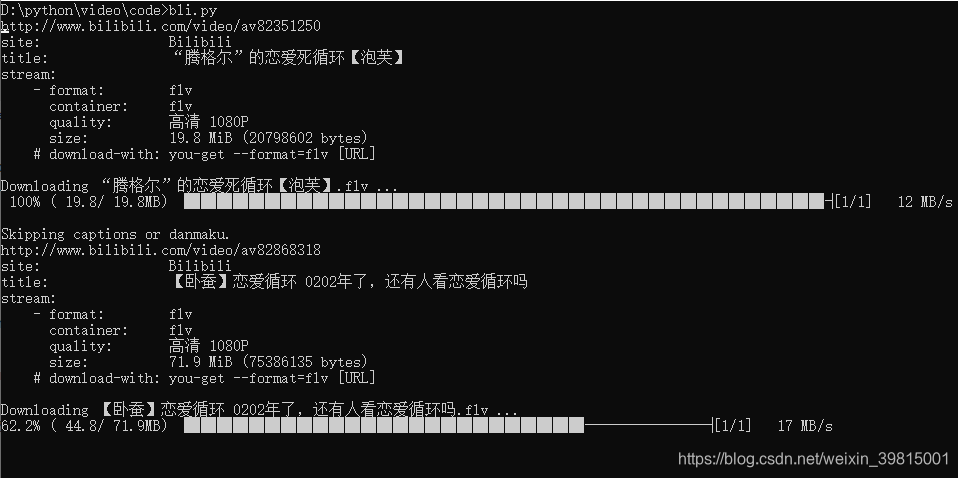
运行文件,得如下结果:
import queue
import requests
import re
import random
import time
import os
import json
from you_get import common
header_list = [
{ "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" } ,
{ "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3676.400 QQBrowser/10.4.3469.400" } ,
{ "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36" } ,
{ "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362" }
]
def get_urls ( base_url, start_page_num, queue) :
while True :
headers = random. choice( header_list)
page_url = base_url + str ( start_page_num)
response = requests. get( url= page_url, headers= headers)
code = response. status_code
if code == 200 :
urls_json = json. loads( response. content)
if urls_json[ 'result' ] :
for i in urls_json[ 'result' ] :
queue. put( i[ 'arcurl' ] )
print ( i[ 'arcurl' ] )
else :
break
start_page_num += 1
print ( 'Get url done!' )
def get_vedio ( save_dir, queue) :
while not queue. empty( ) :
vedio_page_url = queue. get( )
queue. task_done( )
common. any_download( url= vedio_page_url, info_only= False , output_dir= save_dir, merge= True )
if __name__ == "__main__" :
base_url = 'https://s.search.bilibili.com/cate/search?main_ver=v3&search_type=video&view_type=hot_rank&order=click©_right=-1&cate_id=20&pagesize=20&jsonp=jsonp&time_from=20200107&time_to=20200114&_=1578992689153&page='
start_page_num = 1
save_dir = r'D:\python\video'
video_urls_queue = queue. Queue( )
get_urls( base_url, start_page_num, video_urls_queue)
get_vedio( save_dir, video_urls_queue)
print ( 'the end!' )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67
看着自己的 ‘ 学习文件盘 ’ 慢慢被充满,露出了
猥琐
帅气的笑容 。。。。
The end!
人最大的对手,往往不是别人,而是自己的懒惰。