今天是大年初一,小编给大家拜年啦!

本文是小小挖掘机2020年货的第一篇,主要回顾一下2019年推荐系统遇上深度学习系列的一些原创文章。后续还会有更多的年货送给大家,希望大家持续关注呦~。
推荐系统大多分为召回、排序(有时候又细分为粗排和精排)、重排序等几个阶段,而本文也将按照此思路展开。
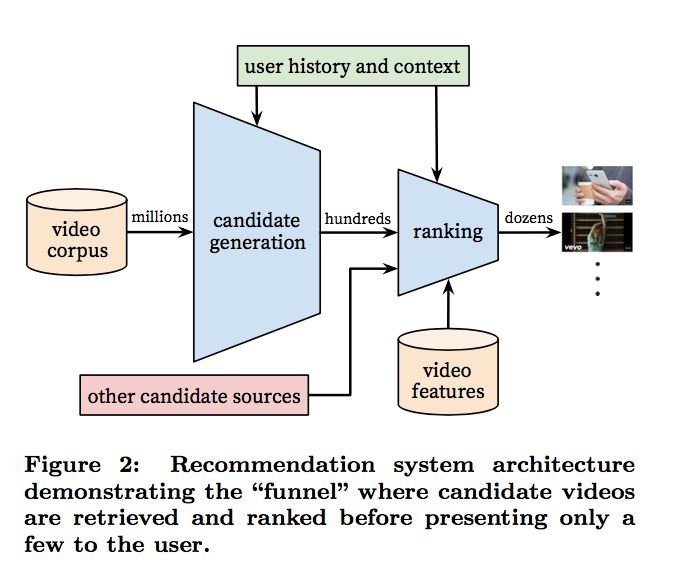
1、召回阶段
目前召回阶段大多数使用多路召回策略,如向量化召回、协同过滤、基于热度召回、基于兴趣标签召回等等。其中双塔模型是最为常见的一种召回模型。
双塔模型如下图所示:
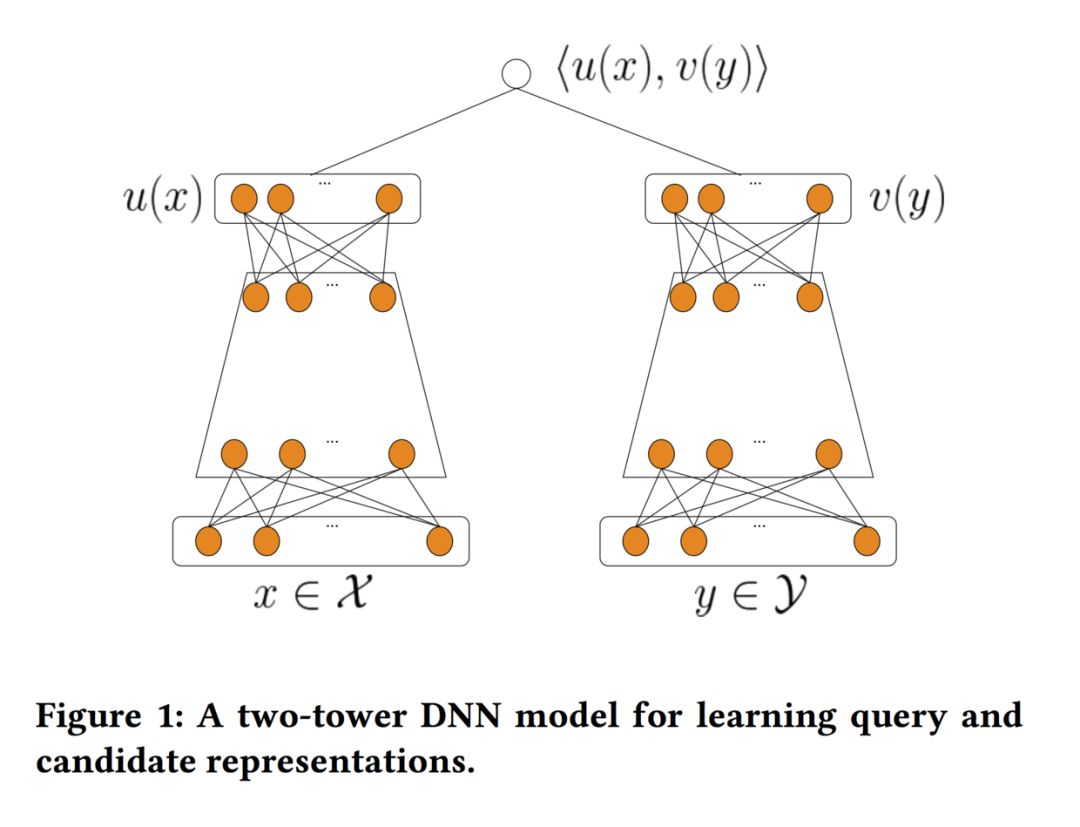
在推荐系统遇上深度学习(三十四)--YouTube深度学习推荐系统和RS Meet DL(72)-[谷歌]采样修正的双塔模型两篇文章中,对双塔模型进行了较为详细的介绍,特别是后一篇详细介绍了在大规模推荐系统中使用双塔模型来做召回的一些经验,如通过batch softmax optimization来提升训练效率和通过streaming frequency estimation来修正sampling bias。
双塔模型实质上是在学习用户和物品的Embedding,并通过Embedding的内积来计算二者的相似性。用户的Embedding可以表征用户的兴趣,但是目前的大多数算法仅仅将用户的兴趣表示成单个的Embedding,这是不足以表征用户多种多样的兴趣的,同时容易造成头部效应。因此在RS Meet DL(74)-[天猫]MIND:多兴趣向量召回中,提出了MIND,同时生成多个表征用户兴趣的Embedding,来提升召回阶段的效果。
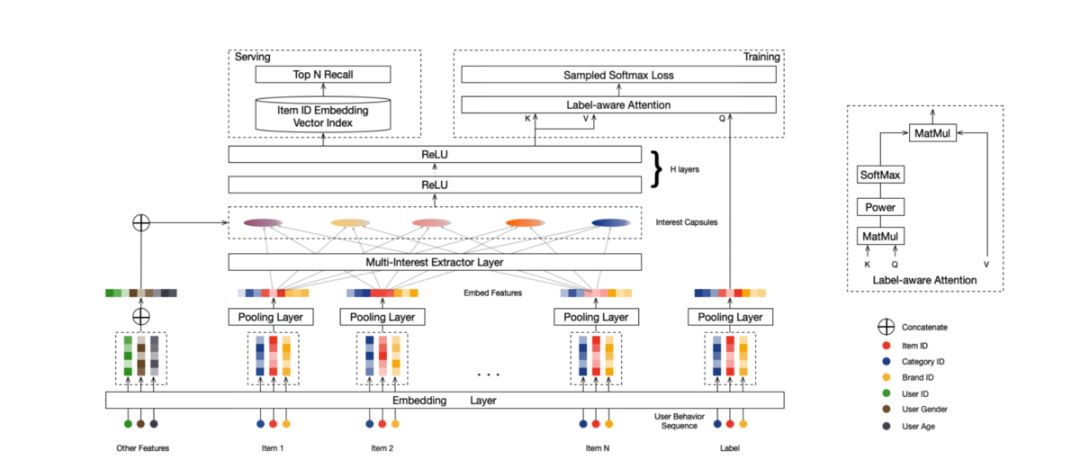
除了通过端到端的方式训练得到Embedding之外,还有一些训练得到Embedding的策略,如阿里的两篇推荐系统遇上深度学习(三十六)-Learn and Transferr IDs Repre in E-commerce和推荐系统遇上深度学习(四十六)-阿里电商推荐中亿级商品的embedding策略,借助图网络和side-information并通过Skip-Gram模型来训练得到物品的Embedding,并使用side-information来一定程度上解决物品冷启动的问题。
而在airbnb的文章推荐系统遇上深度学习(四十四)-Airbnb实时搜索排序中的Embedding技巧中,借助skip-gram模型,基于用户Session中的点击序列训练房源的embedding,同时基于用户的预定序列来学习用户类型和房源类型的Embedding。
召回阶段的目的是能够快速得到用户可能感兴趣的物品候选集,但是双塔模型这种向量化模型对模型结构做了很大的限制,必须要求模型围绕着用户和向量的embedding展开,同时在顶层进行内积运算得到相似性。这样一个特定的结构实际上对模型能力造成了很大的限制。在推荐系统遇上深度学习(三十九)-推荐系统中召回策略演进!一文中,介绍了阿里的深度树匹配召回模型,使得先进模型应用于召回阶段变为可能。而在RS Meet DL(62)-[阿里]电商推荐中的特殊特征蒸馏中,提出了一种蒸馏的思路来提升召回模型的精度。
2、排序阶段
排序阶段的模型可谓百花齐放,但大都是对用户的行为序列进行建模,我在这里将其分为两类:静态兴趣和动态兴趣。
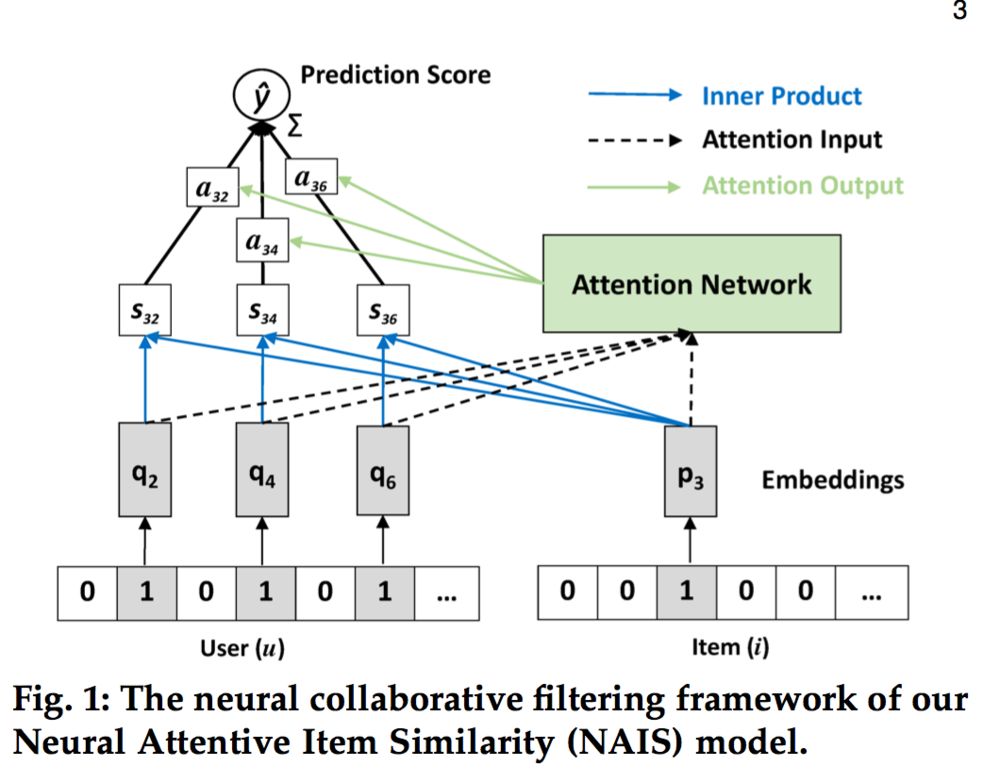
我这里所指的静态兴趣是指在模型中不考虑行为发生时间,如推荐系统遇上深度学习(三十三)--Neural Attentive Item Similarity Model。
而大部分的则是动态兴趣建模,继DIN和DIEN之后,阿里今年又提出了多篇基于用户行为序列建模的文章,如推荐系统遇上深度学习(四十五)-探秘阿里之深度会话兴趣网络DSIN、
推荐系统遇上深度学习(四十八)-BST:将Transformer用于淘宝电商推荐和RS Meet DL(六十一)-[阿里]使用Bert来进行序列推荐
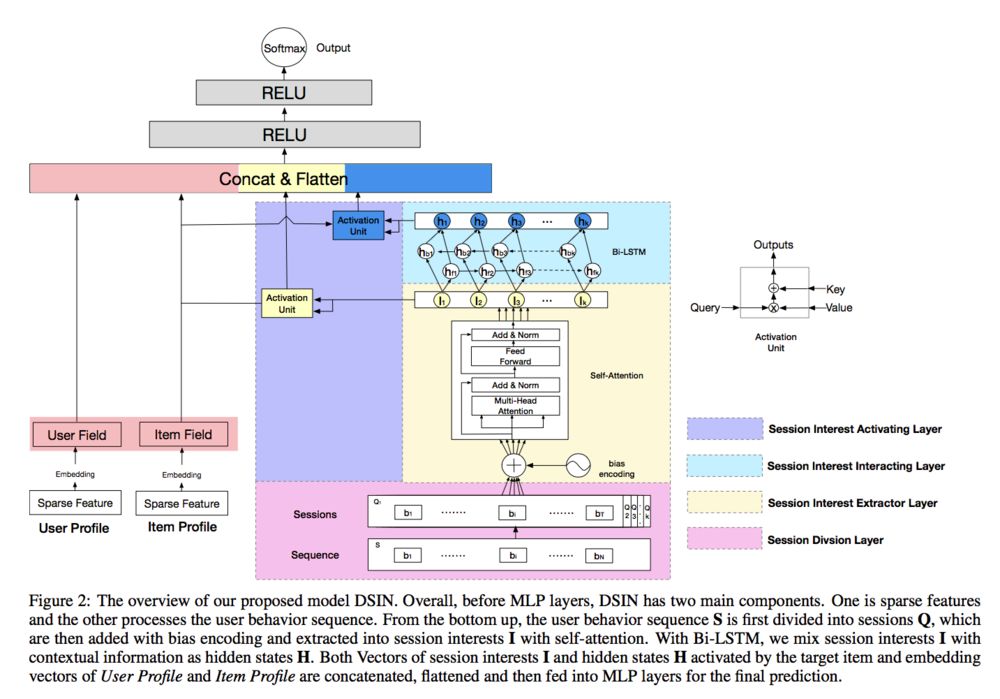 DSIN
DSIN
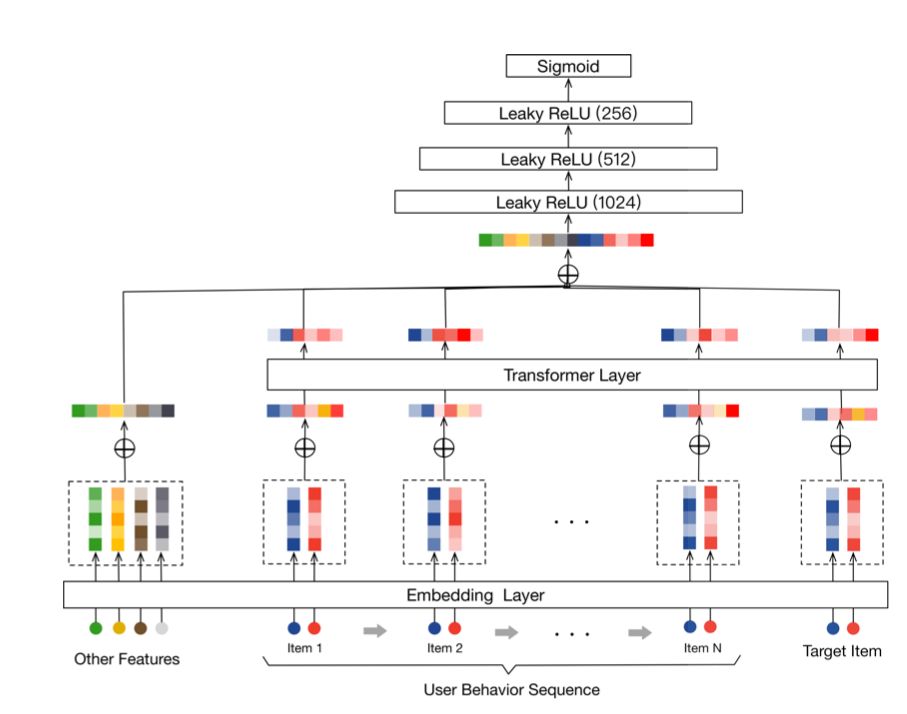 BST
BST
动态兴趣建模中还有一类是基于会话(Session)的推荐,基于会话的推荐,我们可以理解为从进入一个app直到退出这一过程中,根据你的行为变化所发生的推荐;也可以理解为根据你较短时间内的行为序列发生的推荐,这时session不一定是从进入app到离开,比如airbnb的论文中,只要前后两次的点击不超过30min,都算做同一个session。主要的方法是基于RNN如推荐系统遇上深度学习(四十)-使用RNN做基于会话的推荐和推荐系统遇上深度学习(四十一)-使用RNN做基于会话推荐的一些小trick,基于图神经网络如推荐系统遇上深度学习(四十二)-使用图神经网络做基于会话的推荐,和基于“翻译”的方法如RS Meet DL(58)-基于“翻译”的序列推荐方法和RS Meet DL(60)-FM家族的新朋友之TransFM。
在上面介绍的排序论文中,基于Transformer来做推荐的论文非常之多,除上述之外,还有推荐系统遇上深度学习(三十一)--使用自注意力机制进行物品推荐
、RS Meet DL(52)-基于注意力机制的用户行为建模框架ATRank、RS Meet DL(64)-通过自注意力机制来自动学习特征组合等。
多任务学习也是在推荐系统中常用的方法,多任务学习主要有以下五种方式:
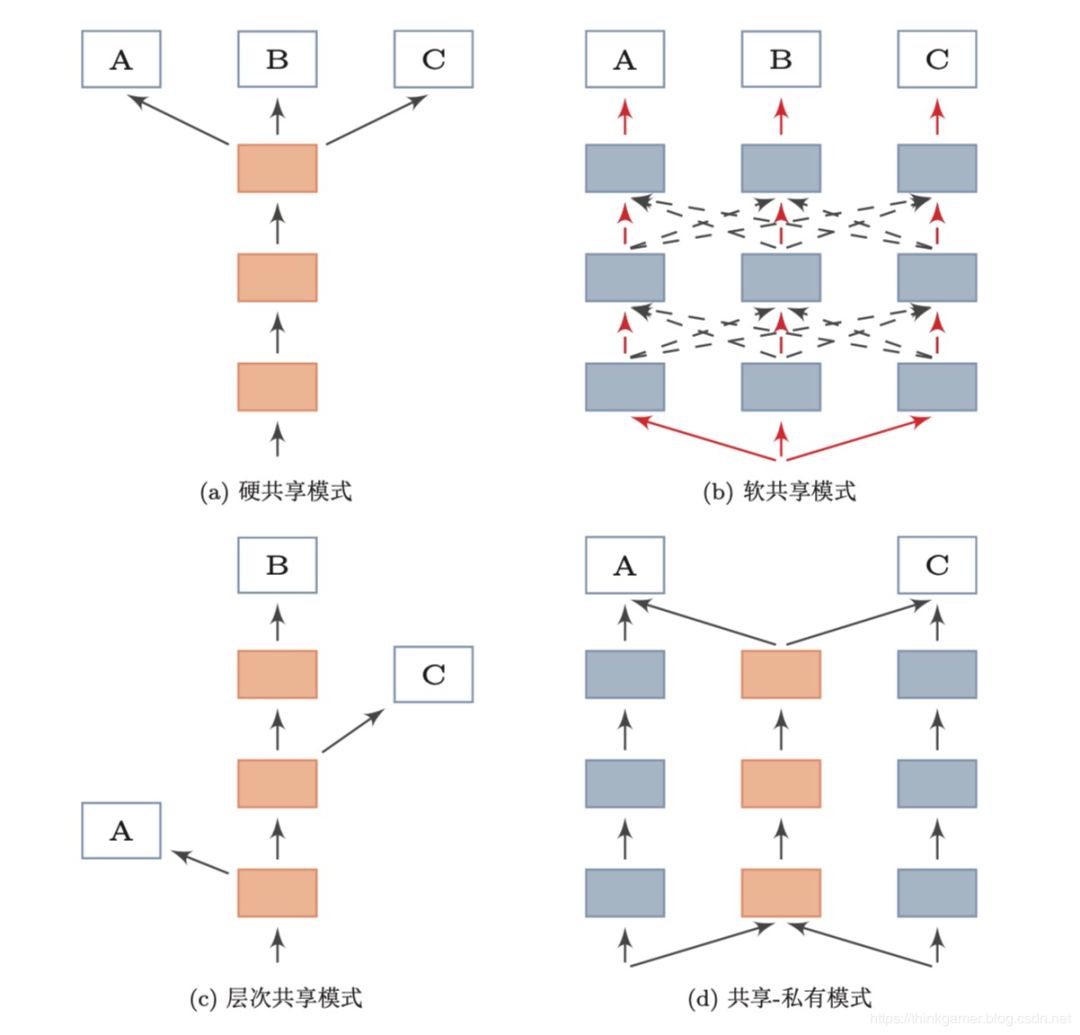
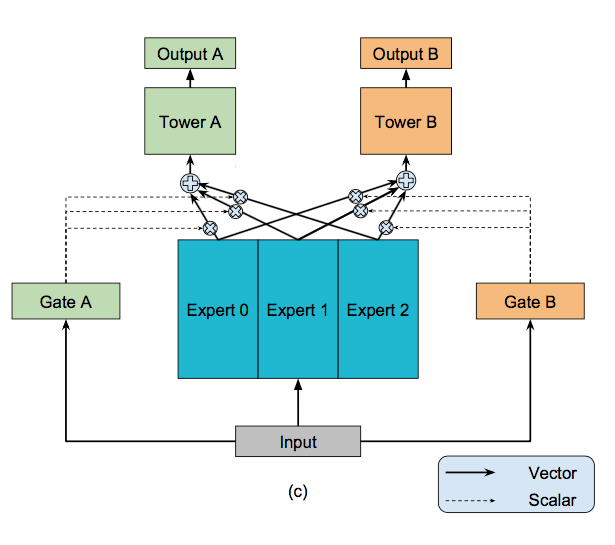
其中最主要的是第一种和第五种(第五种也称为MMoE),阿里的两篇多任务学习文章中,都采用的是第一种方式:RS Meet DL(53)-DUPN:通过多任务学习用户的通用表示、RS Meet DL(66)-[阿里]基于多任务学习的CVR预估模型ESM2。
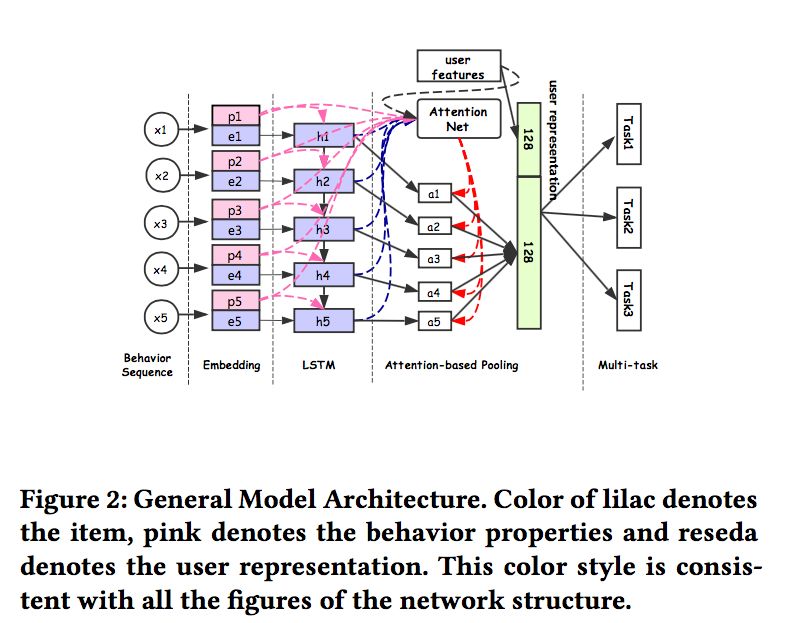
DUPN
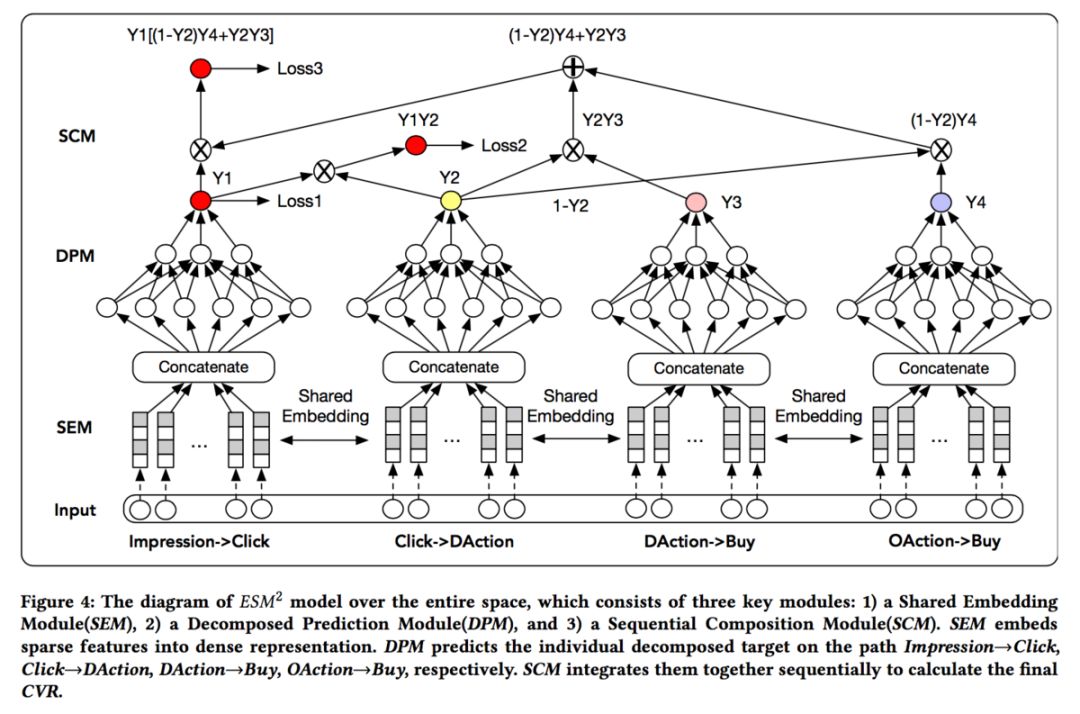
ESM2
而当多任务学习中不同的目标之间关联性并不是很大时,这种共享底层的方式容易造成模型效果的下降,在RS Meet DL(68)-建模多任务学习中任务相关性的模型MMoE和RS Meet DL(69)-youtube视频推荐中的多任务排序模型两篇文章中,介绍了另一种多任务学习的框架,称作MMoE,可以使不同的任务多样化的使用共享层,提升任务的效果。
强化学习应用于推荐系统也是目前各公司研究的一大重点,京东发表了一系列强化学习相关的文章,如推荐系统遇上深度学习(三十五)--强化学习在京东推荐中的探索(二)、推荐系统遇上深度学习(五十)-使用强化学习优化用户的长期体验和RS Meet DL(54)-使用GAN搭建强化学习仿真环境。但就目前来说,强化学习应用于推荐系统还未取得很好的效果,期待后面的研究进展。
除此之外,在点击率预估问题中,面临两个问题,一是位置偏置,二是正负样本比例失衡的问题。
位置偏置问题是说,用户对于item的点击行为,不仅受用户兴趣的影响,还受到item展示位置的影响,展示位置靠前的item,其本身的点击率就高。消除位置偏置信息,目前主要的方法有两种,一是将位置信息作为特征,一是将位置信息单独建模为一个模型:
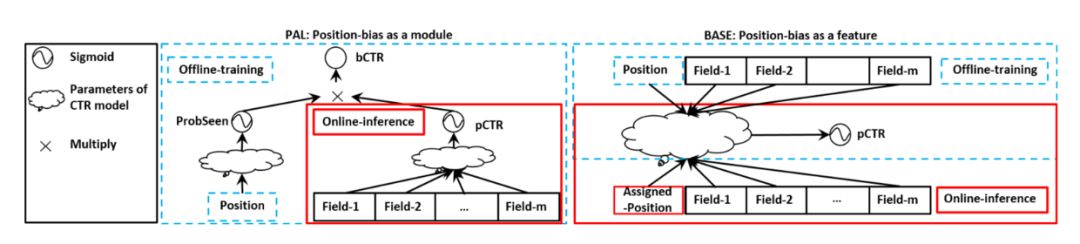
华为提出的 RS Meet DL(71)-[华为]一种消除CTR预估中位置偏置的框架,就是采用上图中的左边的方法, 将位置信息单独建模为一个模型。除此之外,微软提出的RS Meet DL(73)-[微软]通过对抗训练消除位置偏置信息 ,使用对抗学习的思路来进一步消除样本中存在的偏置信息。
而解决样本不均衡的方法通常是对负样本进行采样,但在广告场景下,排序依据CTR*BID,因此需要对点击率进行修正,RS Meet DL(65)-负采样点击率修正的那些事介绍了具体的修正方法。
3、重排序
目前的重排序大都是基于策略的方法,如对相似物品进行打散,复购商品提前或剔除等,而阿里提出使用Transformer做个性化的重排序,具体参考:RS Meet DL(70)-[阿里]推荐中的个性化重排序。

4、其他文章
还有一些文章上述没有提及,感兴趣的同学可以参考一下。
推荐系统遇上深度学习(二十九)--协同记忆网络理论及实践
推荐系统遇上深度学习(三十)--深度矩阵分解模型理论及实践
推荐系统遇上深度学习(三十二)--《推荐系统实践》思维导图
推荐系统遇上深度学习(三十八)--CFGAN:一种基于GAN的协同过滤推荐框架
推荐系统遇上深度学习(四十三)-考虑用户微观行为的电商推荐
推荐系统遇上深度学习(四十七)-TEM:基于树模型构建可解释性推荐系统
推荐系统遇上深度学习(四十九)-九篇阿里推荐相关论文汇总!
RS Meet DL(51)-谈谈推荐系统中的冷启动
RS Meet DL(55)-[阿里]考虑时空域影响的点击率预估模型DSTN
RS Meet DL(56)-[阿里]融合表示学习的点击率预估模型DeepMCP
RS Meet DL(57)-[阿里]如何精确推荐一屏物品?
RS Meet DL(59)-FM家族的新朋友FAT-DeepFFM
RS Meet DL(63)-[阿里]大型推荐系统中的深度序列匹配模型SDM
RS Meet DL(67)-计算广告中的COEC简介
有关上述文章的PDF,小编也是已经准备好了:
1、关注下方公众号“小小挖掘机”
2、公众号后台回复“庆元旦”和“过年好”即可获取两个PDF的下载地址








