目前视频和图像类深度学习加速芯片已经呈现红海状态,而语音类人工智能芯片还处于上升期,文本处理等领域目前还处于探索时期。本文的目的就是从应用和算法的角度分析一下,我们需要一款怎样的语音/文本处理的深度学习芯片?它需要具有怎样的功能覆盖和参数灵活度?这样的芯片能应用到哪些地方?
目前,语音文本类深度学习应用主要分为几个大的方面:
1. 语音识别(语音转文字),包括语音命令,语音听写和语音转录。语音命令往往比较短,例如“发短信给xxx”,“打开电视机”等等。语音听写则是对近场清晰语音的人对机听写,需要有一定的实时性。可以识别完整的一句话或一段内容。语音转录做的是人人对话(例如会议)时的速录员的工作,可以是非实时的录音,可以采用更复杂的处理技术。目前语音识别大类,尤其是后两者主要还是依靠调用云端API实现。在终端化上还处于尝试期。另外,对学习者的口语进行评分,也属于语音识别的范畴。
2. 语音生成(文字转语音(TTS))
文字转语音比较明确,主要用于读出给定的文本,也可以进行风格化,即模仿某个人的声音。目前采用终端和云端都可以实现这个功能,甚至手机本身就可以处理。其难点是需要妥善处理分词、多音字和语气。
3. 人机对话(Chatbot)
这是文本处理的最典型的应用,主要用于聊天/客服机器人。有时候也会结合前两者用于人机语音对话,例如智能音箱。目前人机对话整体还处于一问一答阶段,基于上下文的对话机制仍处研究阶段,但对于特定场景,例如客服机器人,可以进行一定程度的多轮对话。人机对话往往和搜索引擎结合起来使用,当无法作出准确回答时,往往会提供搜索结果。
4. 自然语言处理(NLP)
当前的自然语言处理技术可以对一段文字进行词法分析(中文分词、词性标注、命名实体识别等),从而提供出用词统计信息,提取关键词,分析词与词的相似度等。句法分析可以得到句子的结构和词的依赖关系。找到句子的成分,分析语干,将非结构化的语言转换成一个结构化的语义框架,从而可以通过分析、数据库查找等技术进一步实现语义理解和知识挖掘。采用上述技术可以构建出知识图谱,将大量背景知识与当前的输入连接起来,可用于搜索的联想和商品推荐等应用。另外,也可以实现评论观点抽取、情感分析、阅读理解等。
另一个大类是翻译,往往指任意语言对的篇章级别翻译。
5. 视频和语言结合的应用
主要的应用是视频理解,即将一段视频转换为描述文字或结构化信息。
上述应用都属于自然信息的处理,另外一类是创作,例如音乐生成,写诗、创作文章等最近几年也取得了突破性进展。
•••
这些领域在深度学习到来之前都有各自的发展,但都在深度学习中获得了发展提高。例如语音识别从原先GMM-HMM的基础框架向DNN-HMM框架转型,再到DNN-CTC转型。又例如在NLP中,规则和统计模型构建的词性-句法-语义多步方法被引入了CNN,LSTM的直接的跨步骤特征提取方法所革新。下面介绍一下使得这些领域取得革命性突破的深度学习框架。
1. 时序分析系列神经网络
由于语音和文本具有很强的时序特性。而由于卷积网的平移不变性使得对时序序列分析能力有一定程度的欠缺,因此需要带有时间能力的神经网络补充它的不足。循环神经网络(RNN)及其衍化形式长短时记忆网络(LSTM)和门控循环单元(GRU)是典型代表,广泛应用于大量语音文本分析领域。由于这些网络只阐明了当前状态和历史的关系,而有时,当前状态会同时依赖于历史和未来,因此双向时序网络,例如BRNN,BLSTM得到了较多的应用,这种类型的网络可以认为是正向时间的时序网络和一个反向时间的时序网络合在了一起。值得注意的是,这些网络结构可以铺多层,即一层的输出是另一层的输入,组成更强大的时序网络。值得注意的是,由于RNN具有梯度弥散问题,因此实际应用时,几乎还是使用的其衍化形式,例如LSTM和GRU。GRU和LSTM相比性能上难分伯仲,可根据具体应用选择,而在资源开销上,GRU较LSTM更具优势,RNN占用资源最少,但实用性较低。
2. 深度学习技术
本用于视频领域的卷积神经网络(CNN)在语音/文本处理上获得了广泛应用。例如对音频识别起到了一定程度的改善作用。此时输入变为二维的语谱图(时间-频率图)。对于句子理解,有时会直接把一句话按照每单词作为一行(单词的高维向量表示),组成“图像”,通过CNN进行降维和特征提取。分析结果可以用于分类和对话。多层感知机网络(MLP)在这些网络中发挥着强大的胶水连接作用,以及Word embedding的作用等。对于阅读理解和多轮对话等应用,关注(Attention)机制可以从上下文或者历史知识中提取出对当前任务有用的因素,简单的关注可以认为是一种动态权重下的加权求和操作。
3. 非神经网络的分析技术
值得注意的是,文本/语音处理区别于视频处理的一大特色是,这些神经网络技术目前大部分情况还没法构成端到端的应用,因此这些先进的神经网络往往需要和传统的非神经网络技术混搭使用。例如,对于语音识别技术,往往可以分为语音模型、文本模型、搜索三部分。语音模型中的前期处理已经逐渐被CNN、LSTM等神经网络技术所替代,而后部为了解决语音的速率问题,还需要采用基于状态切换的HMM模型,或者基于搜索的音素合并算法CTC(BeamSearch)。这些算法可以有效弥补当前神经网络没有变长的时序(t)表达能力的问题。另外,对于文本模型而言,N-gram仍然具有很高的应用性,虽然也有基于RNN替代方法,但未必会产生完全替代。
•••
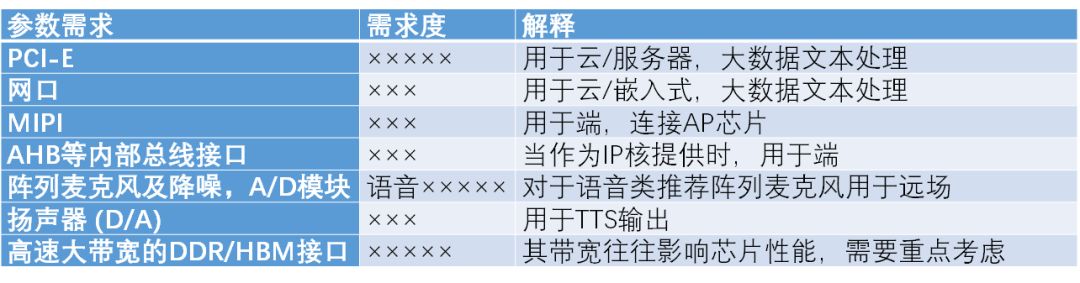
综合以上情况,对于语音文本类应用而言,需求度分析可以整理如下表。
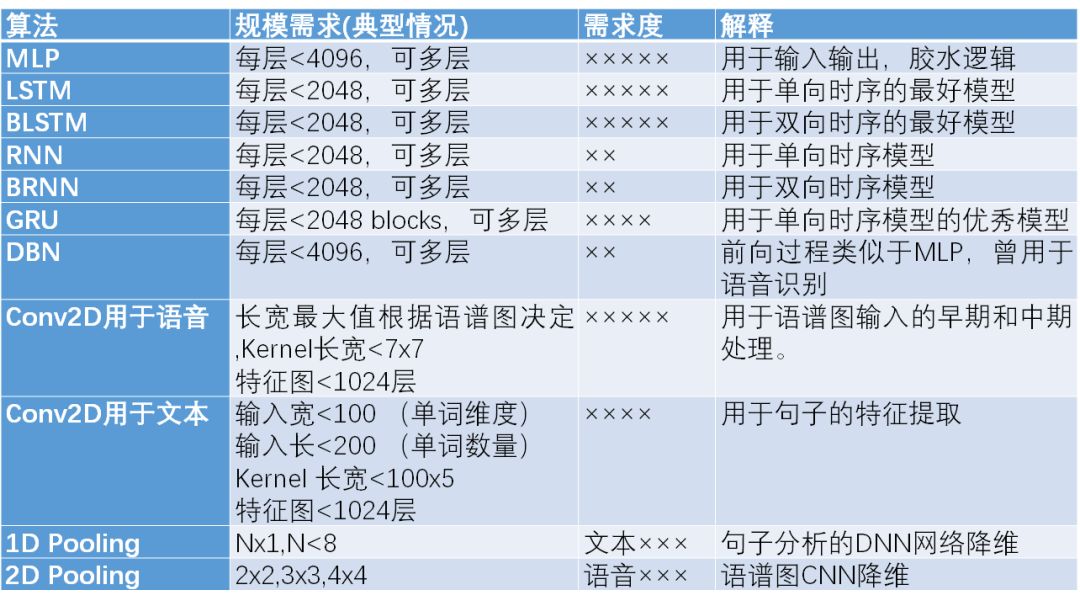
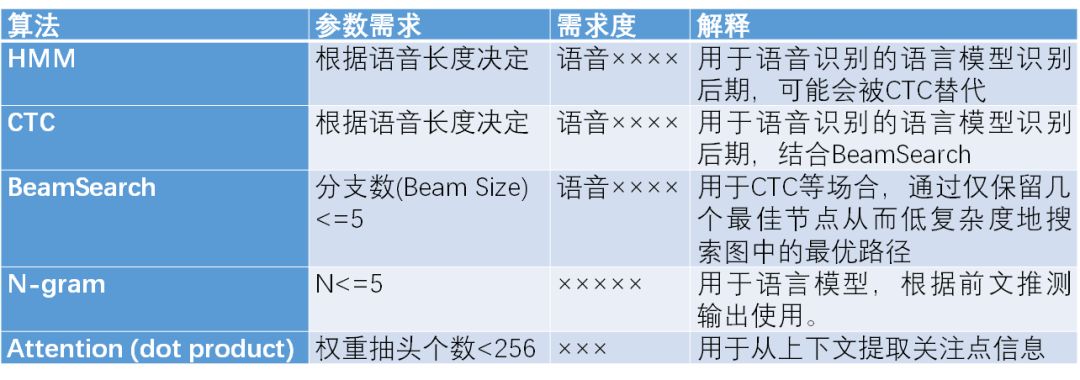
在神经网络实现细节变化方面,我们需要进一步考察。在文本和语音领域,激活函数往往不是ReLU,而是一些非线性函数。因此对数据精度的要求比较高,目前成熟的仍然是浮点。近几年有关于8b的LSTM结构研究,甚至部分量化为更低精度的研究,但并不能保证通用性。因此建议采用浮点数据类型。另外,残差连接对于语音识别仍具有意义。
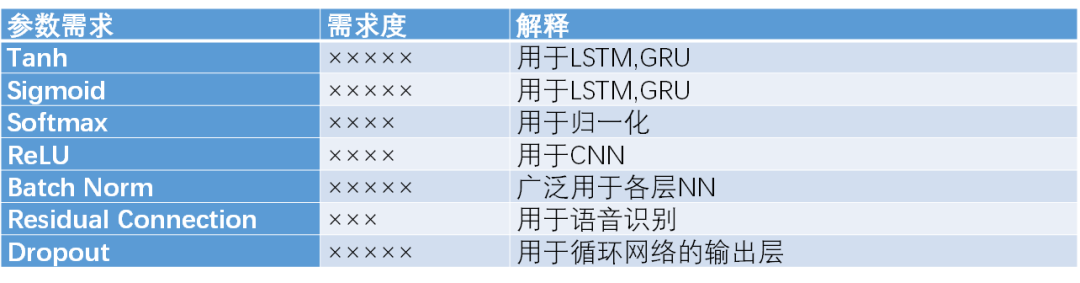
在预处理方面,语音和文字都有各自较为成熟的预处理方案。对于语音,主要需要构建语谱图。有些时候也可以直接用音频作为输入。而对于文本,主要需要先将词分开并表示为向量。主要算法如表所示。
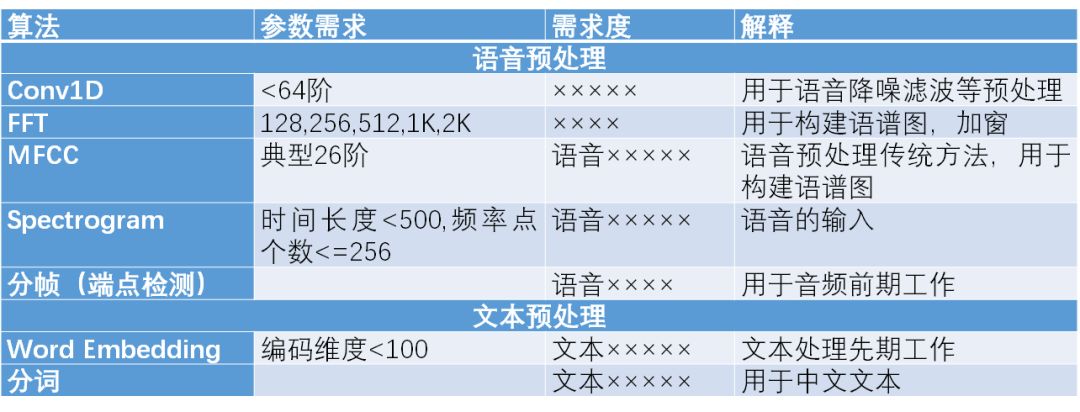
语音在经过神经网络进行处理后,后期处理的主要技术包括HMM或CTC,以及N-gram。
根据四元拆分方法,一个数字IP核分为控制,计算,存储,互联四个大的部分,下表对每一部分的需求进行简述。

在接口方面,主要考虑是嵌入式平台还是云平台,其中嵌入式平台往往直接通过麦克风获取语音,而对于远场而言,阵列麦克风模块是最好的选择。对于云而言,数据主要通过PCI-E或者网口传输。由于这些神经网络结构需要更大的内存开销,因此DDR/HBM需求较高。
对系统的整体理解有助于我们设计它的支撑平台,因此我们以上文的砖块为基础,重点介绍目前处于领先地位的若干神经网络体系结构。例中以知名公司推出的语音/文本处理神经网络算法为主要关注点。大多具有公开论文作为参考。可以得出的结论是,商业级别的LSTM(GRU)的单层尺寸一般为1000-2000左右,会放置3~7层。卷积网及其各类变种都有应用。CTC是目前较为流行的语音识别后端处理模式。Attention机制会有长远发展,值得关注。详细情况如表所示。
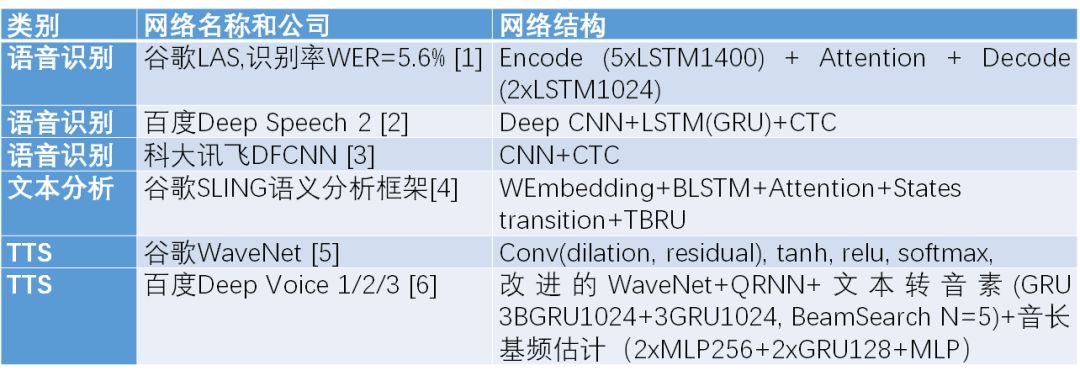
注:BLSTM, BGRU在有些文献中也写作biLSTM,biGRU。
•
••
今音频/文本处理正在深度学习的轨道上快速发展。例如谷歌的LAS算法在本文写作几天前公布,大大简化了语音识别框架,百度Deep Voice 3在大半个月前公布,训练速度提升了10倍。各大公司相继推出了基于深度学习算法的语音识别网络[8]。在NLP方面[7],深度学习也正在进行着前所未有的变革。值得注意的是这些变革是刚性的,因为它确实刷新了各项性能指标,把相关领域研究推向了新的高度。另外,很多任务会加入很多个性化算法元素,而不是单纯的神经网络结构。飞速的算法进展以及个性化传统算法的引入给芯片设计的灵活度带来了考验。
综上,本文分析了当前语音文本深度学习算法的主要应用场景,阐述了支持这些应用场景的芯片应支持何种深度学习算法,最后分析了若干知名技术方案中这些网络的使用情况。结论为(1)大量深度学习算法和神经网络结构是这些领域的最优性能的必需算法,因此这些应用具有很强的神经网络加速需求。(2)仿存量远大于CNN,可以理解为存储访问带宽主导的设计。其特点可能会导致片上内存的增大和近内存计算架构得到长足发展。(3)语音/文本类网络结构复杂,传统处理算法和神经网络变种需要高效支持。我们期待未来会有更多的芯片公司关注语音/文本类深度学习应用的加速,开发出令人激动的新品,让这些应用能够走进每个人的日常生活。
由于此文涉及面较广,有可能不够准确,在此仅供抛砖引玉之用,各位如见到有错误和不足之处请务必留言指出。
Reference
[1]. Google LAS (https://arxiv.org/pdf/1712.01769.pdf)
[2]. Deep Speech 2 (https://arxiv.org/abs/1512.02595, http://blog.csdn.net/xmdxcsj/article/details/54848838)
[3]. DFCNN (http://blog.csdn.net/real_myth/article/details/52274005)
[4]. SLING (https://arxiv.org/abs/1710.07032)
[5]. WaveNet (https://deepmind.com/blog/wavenet-generative-model-raw-audio/, https://arxiv.org/pdf/1609.03499.pdf)
[6]. Deep Voice 3 (https://arxiv.org/abs/1710.07654, Deep Voice 2 https://arxiv.org/abs/1705.08947, http://news.zol.com.cn/631/6315926.html) Deep Voice 1 https://arxiv.org/abs/1702.07825
[7]. NLP进展 (http://www.sohu.com/a/210427622_465975)
[8]. 语音识别网络对比 (http://www.360doc.com/content/17/0729/00/41022878_675010230.shtml)
- END -
作者简介:
吴臻志博士,清华大学类脑计算研究中心助理研究员。专长神经网络芯片设计,众核芯片设计,神经网络高效实现等。邮件 wuzhenzhi@gmail.com。同行及朋友可加微信zhenzhi-wu联系。
本文为机器之心转载,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com









