数据框(DataFrame)用于存储多行和多列的数据集合,就像Excel表格一样,在Pandas中进行数据处理与分析就是主要对数据框进行操作。
我们来看之前使用过的案例数据,输入以下代码:
1import pandas
2data = pandas.read_csv(
3'D:/D/data.csv',
4 engine='python',
5 encoding='utf8'
6)
执行后,在变量浏览窗口中就可以看到刚导入的data变量了,双击打开data变量,就可以得到下面这张表。注意看左上角提示,类型为DataFrame,所以导入的数据就是个数据框。
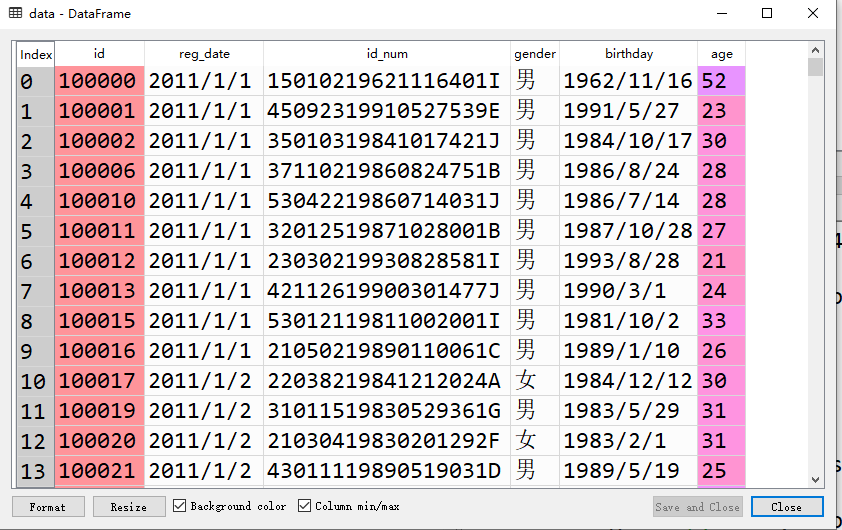
数据框中的不同列可以是不同的数据类型,同一列数据之间也可以是不同的数据类型。但是根据数据规范,进行数据分析时,一般都要求同一列数据是同一数据类型,这样才方便后续的数据处理、分析。
我们现在通过data.dtypes命令查看下data数据框中各个列的数据类型分别是什么。
data.dtypes
id int64
reg_date object
id_num object
gender object
birthday object
age int64
dtype: object
可以看到只有id跟age是int型,就是整数型,其他都是object型,这个object型在数据框中就是字符型,只是显示为object。
另外也可以通过data.info()查看data数据框中各个列的数据类型。
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 59101 entries, 0 to 59100
Data columns (total 6 columns):
id 59101 non-null int64
reg_date 59101 non-null object
id_num 59101 non-null object
gender 59101 non-null object
birthday 59101
non-null object
age 59101 non-null int64
dtypes: int64(2), object(4)
memory usage: 2.7+ MB
这个就显示的更加详细了,不仅显示各个列的数据类型,还有多少行多少列,使用多少内存空间都显示了。
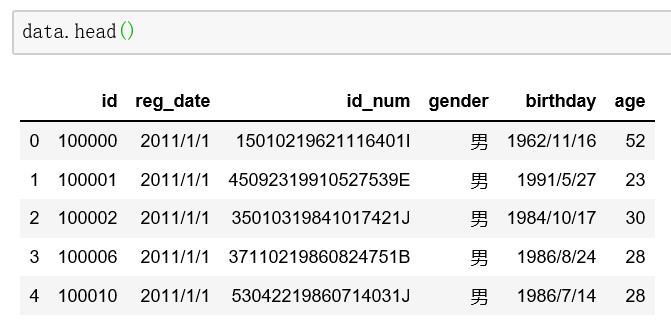
在变量浏览窗口中双击打开data变量查看数据框是Spyder特有的功能,如果使用的是Jupyder等工具,可以通过head()方法查看,括号里不输入参数就是默认查看前5行数据,如果要查看前10行,直接在括号里输入10即可,其他同理。
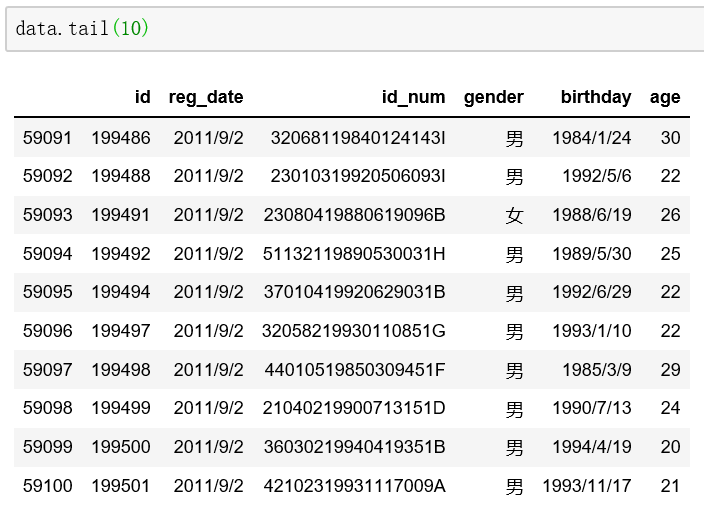
还可以通过tail()方法查看后5行数据,同样括号里不输入参数就是默认查看后5行数据,如果要查看后10行,直接在括号里输入10即可,其他同理。
如果只要'id'列数据,只需要输入以下代码运行即可。
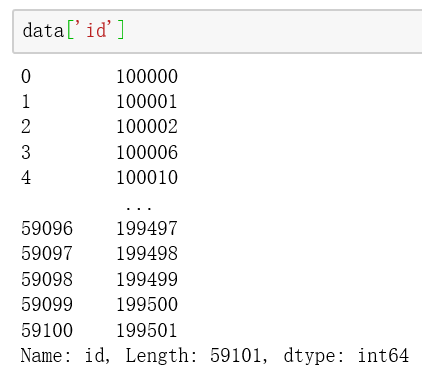
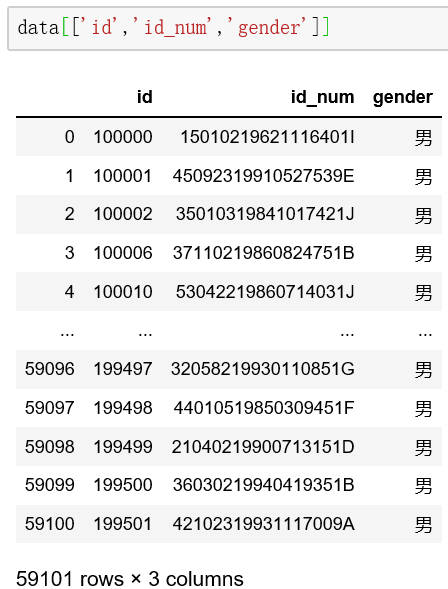
如果要'id','id_num','gender'三列数据,只需要输入以下代码运行即可。

希望系统、快速学习Python数据分析知识,可以学习
数据分析专家@文彤老师的
《跟文彤老师学Python数据分析》系列视频课程

包含以下三门课程
Python数据分析--玩转Pandas
玩转Python统计分析
Python数据分析--玩转数据可视化

如有问题也可添加课程助理微信号咨询,添加时请注明咨询课程

现参加课程学习,可享受6折优惠
购买课程直接点击文末“阅读原文”进入即可












