请点击上面“思影科技”四个字,选择关注作者,思影科技专注于脑影像数据处理,涵盖(fMRI,结构像,DTI,ASL,EEG/ERP,FNIRS,眼动)等,希望专业的内容可以给关注者带来帮助,欢迎留言讨论,也欢迎参加思影科技的课程,可添加微信号siyingyxf或19962074063进行咨询。(文末点击浏览)
虽然在当前,人们对精神分裂症的神经机制有了一定的了解,但是对其神经生物学的异质性仍旧了解甚少,这严重影响了当前对精神分类症神经生物学的不同表征的分析研究。本文的研究者使用新颖的半监督机器学习方法研究了多机构多种族队列中的神经解剖亚型,旨在发现与疾病相关的不同模式。在已建立的精神分裂症(n = 307)和健康对照(n = 364)数据中,对PHENOM(通过多维度神经影像学评估精神病异质性研究队列)在三个不同站点的结构MRI和临床数据进行了分析。灰质(GM)、白质(WM)和脑脊液(CSF)的区域体积测量用于确定精神分裂症的独特且可重现的神经解剖亚型。本研究发现了两种不同的神经解剖亚型。亚型1表现出较低的灰质体积,在丘脑,伏隔核,颞内侧,前额叶/额叶内侧和岛状皮层中最为突出;亚型2显示基底神经节和内囊的体积增加以及正常的脑容量。灰质体积与亚型1(r = –0.201,P = 0.016)的疾病持续时间呈负相关,而与亚型2(r = –0.045,P = 0.652)无关,可能表明这两种亚型存在不同的潜在神经病理学过程。这两种亚型在年龄(t = –1.603,df = 305,P = 0.109),性别(卡方= 0.013,df = 1,P = 0.910),病程(t = –0.167,df = 277,P=0.868),抗精神病药物剂量(t = –0.439,df = 210,P = 0.521),发病年龄(t = –1.355,df = 277,P = 0.177),阳性症状(t = 0.249,df = 289,P = 0.803),阴性症状(t = 0.151,df = 289,P = 0.879)或抗精神病药类型(卡方= 6.670,df = 3,P = 0.083)等方面没有显著差异。亚型1的教育程度低于亚型2(卡方= 6.389,d.f. = 2,P = 0.041)。总之,本文发现了两种截然不同且具有高度可重复性的神经解剖亚型。亚型1表现出与病程相关的广泛的脑容量减少和较差的发病前功能。亚型2解剖结构正常、稳定,但基底节及内囊较大,不能用抗精神病药剂量来解释。这些亚型挑战了脑容量减少是精神分裂症的一个普遍特征的观点,并提出了不同的病因解释方案。注释:全文12100左右字数,推荐阅读时间35分钟,如仅对方法感兴趣,可直接翻阅到“数据和方法”进行阅读精神分裂症在临床表现,病程,治疗反应和生物标志等方面具有不同的表现现象。长期以来,人们已经认识到,这种异质性影响了临床治疗诊断的准确性,并掩盖了研究结果。尽管如此,尝试通过症状亚型来剖析这种异质性的研究对研究和实践影响不大。实际上,诊断系统已从分类方案(例如DSM-V)中删除了大多数基于症状的精神分裂症亚型。先前的神经影像学研究主要使用二元病例对照设计来研究精神分裂症的神经解剖异常。这些分析主要显示出广泛且细微的脑容量的降低。除分布缺陷外,据报道,包括在ENIGMA和COCORO以及作者团队自己的大样本中发现基底节的体积也增加了。目前尚不清楚这两种改变是否都存在于同一个体中,或者这些变化是否代表不同的潜在亚型。基于症状定义精神分裂症亚型的研究表明,与其他亚型相比,具有更多负面症状的个体表现出更广泛的皮层容量减少,但大脑信号相互重叠,无法弄清楚是否如同在大型数据集中发现的脑容量增加或减少。基于神经解剖学数据客观地定义生物学亚型对于进一步的研究很重要。先前的“生物型”研究已经检查了其他表型,包括结合基因,功能性MRI或电生理学和认知学等数据的研究。 只有两项先前的研究试图直接解析精神分裂症的神经解剖学异质性。但是,这些研究受到样本多样性不足和样本量小的限制,这阻碍了亚型的严格可重复性分析,例如拆分后的样本的可重复性,留一交叉验证,与性别相关的评估以及保留45岁以内的样本以最小化衰老造成的影响。尽管其中一项研究受益于外部验证集,但该研究中使用的方法并非专门设计用于根据患者亚型与健康对照的差异来识别患者亚型以更好地捕获疾病效果。综上所述,这些因素可能会导致所发现的亚型存在较低的可重复性以及亚型的重叠分布等问题,这些结果会影响对这些疾病亚型进行合理解释。
为了更好的描述精神分裂症疾病亚型,需要更多的样本数据以及更多样化的数据,并且还需要适用于不同数据中心和族群的高级的数据分析方法。为了应对这一挑战,研究者们建立了一个横跨三大洲的联盟,称为PHENOM(“通过多维度神经成像评估精神疾病的异质性”)。然后,他们应用了最近开发的称为HYDRA(通过判别分析进行异质性分离)的半监督机器学习算法(注:半监督学习是一种同时结合监督学习和无监督学习的模型学习方法。半监督学习同时使用大量无标签的数据和一部分有监督的数据。在本文中,HYDRA算法通过对健康被试和患者被试做分类进行监督学习,然后在患者被试中寻找疾病亚型进行无监督学习。)来识别神经解剖亚型。HYDRA与以前的聚类方法有根本上的不同,因为HYDRA专门通过建模与健康对照之间的差异来对疾病影响进行聚类,而不是直接对患者聚类。通过约束年龄、性别、扫描仪、种族和其他可能会引起疾病异质性的因素,此方法有助于识别真正的疾病亚型。之所以如此,是因为对照组中已经存在所有这些混杂的变异,而仅归因于病理过程的患者和对照之间的差异才得以聚集。他们假设这种方法将客观地揭示以前在典型的病例对照设计中被掩盖的独特的神经解剖亚型,并且不能用病程或抗精神病剂量来解释。这项研究收集了来自三个地点的PHENOM子样本。研究人员有意从各种成像协议中选择了样本,包括来自德国的1.5 T数据。为确保疾病亚型不受位点/方案的偏倚,他们通过利用“留一(数据中心)交叉验证”(这个方法是指每一次留出一个数据站点的所有数据用于测试,剩下的站点数据用于训练,重复多次,直到所有数据都参与了测试),进一步验证了亚型分类的可重复性。图像由各自的研究人员共享,并在宾夕法尼亚大学的生物医学图像计算和分析中心进行了分析。从941名精神分裂症患者和对照组的国际队列中选取被试,只分析45岁以下的被试,以减少衰老造成的影响。表1列出了最终选出来的样本(307位精神分裂症患者和364位健康对照者)的人口统计学数据,反映了联合队列研究和MRI扫描协议的多样性。来自三个站点的数据详情如下:这项研究得到了宾夕法尼亚大学机构审查委员会的批准。获得了每个被试的书面知情同意。由训练有素的临床研究人员进行招募和评估。诊断评估采用了DSM-IV (Structured Clinical Interview for DSM-IV,SCID)的结构化临床访谈。如果被试在过去6个月内有药物滥用或依赖(尼古丁除外)史,或在研究当天尿检呈阳性,则不纳入研究。如果健康对照被试符合任何DSM-IV精神障碍的标准,则将其排除。采用阳性症状评定量表(Scale for the Assessment of Positive Symptoms,SAPS) (Andreasen, 1984)和阴性症状评定量表(Scale for the Assessment of Negative Symptoms,SANS) (Andreasen, 1983)对患者样本进行评估。被试来自德国慕尼黑路德维希-马克西米利安大学精神病学和心理治疗系。该研究方案得到了路德维希-马克西米利安大学伦理委员会的批准。被试在MRI和临床检查前提供书面知情同意书。由训练有素的临床研究人员对被试进行招募和评估。如果被试有其他精神疾病和/或神经系统疾病、过去或现在经常酗酒、和/或服用非法药物、过去头部外伤失去意识或电休克治疗、不懂德语、智商< 70、年龄< 18或> 65岁的情况,则被排除到数据队列之外。通过使用正面和负面症状量表(Positive and Negative Syndrome Scale,PANSS)对患者进行评估。本研究经天津医科大学总医院伦理委员会批准。在研究登记之前,每个被试都要得到书面的知情同意。由两位临床精神病专家通过使用DSM-IV (SCID)来确定被试是否患有精神分裂症。入选标准为年龄处于16-60岁之间且是右利手。受试者排除标准为:MRI禁闭症、妊娠、全身疾病史、中枢神经系统疾病和头部外伤史、近3个月或终身药物滥用或依赖史。对于健康对照,额外的排除标准是有一级亲属有过精神病史或有精神障碍。通过使用PANSS对精神分裂症患者进行评分。站点1(美国)中,通过使用3T TIM TRIO扫描仪(德国西门子)采集T1加权的梯度回波序列获取影像,TR=1810ms,TE=3.51ms,TI=1100ms,flip angle=9 degree, FOV=240mm x 180mm,matrix=256 x 192, slice=160,slice/skip thickness=1mm/0mm。站点2(德国)中,通过1.5 T Magnetom Vision扫描仪采集T1加权 MPRAGE 像,TR=11.6ms,TE=4.9ms,FOV=230mm,matrix=512 x 512,126个连续的轴向切片,每个切片厚度为1.5mm,体素大小=0.45 x 0.45 x 1.5mm。站点3(中国)中,通过3T MR系统(Discovery MR750, General Electric, Milwaukee, WI, USA)采集图像数据。TR=8.2ms,TE=3.2ms,TI=450ms,flip angle=12 degree,FOV=256mm x 256mm,Matrix=256 x 256,层间厚度为1mm,188个矢状面切片。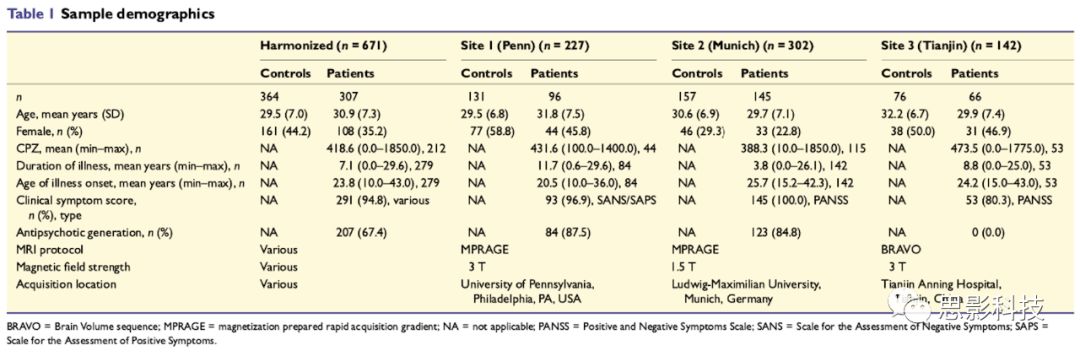
采用了一套广泛使用的质量控制程序,其中包括人工验证和自动标记。首先人工检查原始T1图像是否存在运动伪影、图像伪影或者受限的FOV。矫正因受不均匀影响而发生扭曲的图像,并采用multi-atlas、multi-warp分割方法(MUSE)将每个被试的图像分割成感兴趣的解剖区域(ROIs),其中包括灰质(GM)、白质(WM)和脑脊液(CSF)。通过使用非线性配准的配准方法将剥去颅骨的t1图像配准到位于MNI标准空间的模板中,生成了基于GM、WM和CSF组织的体素水平区域脑图谱(regional volumetric map)。同时研究人员还会人工评估经过上述处理后的图像,如果大脑组织提取的不好、脑组织分割的不太好或者存在配准错误(在图像预处理的过程中,经常会发生配准、分割错误。配准错误可能是指某些关键脑区过度配准,发生较为严重的、不自然的扭曲。),就去除掉这些图像。通过使用线性模型在健康被试的子样本中估计ROI区域中特定于站点的站点效应,这些样本中每个站点都具有相同的男女比[平均年龄(标准差):宾夕法尼亚大学 29.97(7.13),慕尼黑 29.39(6.17),天津 29.04(7.54),P>0.46],然后从所有数据(包括疾病数据)中移除站点效应。在对站点效应进行校准之后,对ROI进行年龄和性别的归一化;因此,此处报告的所有聚类结果均与数据采集地点,年龄以及性别无关。研究者将HYDRA用于ROI上测量来识别亚型。HYDRA通过比较患者和对照组来确定患者的亚型。与完全监督学习方法如支持向量机和随机森林不能区分患者的亚型不同,HYDRA能够同时进行分类和聚类。HYDRA使用支持向量机对健康对照和患者进行分类,分类器构建的超平面两侧则分别是健康对照和患者。HYDRA通过聚类算法将由分类器构建的多面体的不同平面(超平面)与患者联系起来,并对患者进行亚型分类。与无监督聚类算法(如k-means)相比,HYDRA可以有效地根据患者与对照组的差异对患者进行聚类;而k-means则根据患者间的相似性对患者进行聚类,这种方法容易混淆个体间的差异(如年龄或性别)。HYDRA通过改变超平面的数目来评估更多的子类型,具有一定的灵活性。在HYDRA算法中,通过线性边界最大化分类器(其实就是SVM)构建一个凸多边形对健康对照以及患者进行区分。亚型分类是通过将患者与称为超平面的多面体的不同面联系起来进行聚类来实现的。HYDRA由以下几个主要步骤组成:多次初始化并迭代求解凸多边形的解,最后求解多个聚类结果中的一致性解。具体来说,HYDRA通过对K个单位长度的超平面进行采样进行初始化,以完成对患者的分组,这样得到的超平面考虑了患者与健康对照之间所有成对差异的空间。采用确定点过程(determinantal point processes, DPP)的方法选择K个唯一的超平面,DPP是一种采样技术,对疾病的不同方向进行采样。然后用采样得到的超平面估计初始的聚类分配(S-)。然而由此估计的出来的结果可能会因初始化的不同而有所不同,因此DPP提出了一个多次初始化的策略。最终的聚类结果是基于多次聚类出来的结果的一致性解得到的。HYDRA算法具体如下:输入:X∈R^{n x d}, Y∈{-1,+1}^n, (有n个被试的训练数据,每个被试的数据有d维图像特征),K(亚型或者超平面的数量)输出:W∈R^{d x K}, b∈R^{1 x K} (W和b是分类器参数);S-(聚类结果)循环:直到算法收敛或者到达一定的迭代次数(循环终止条件)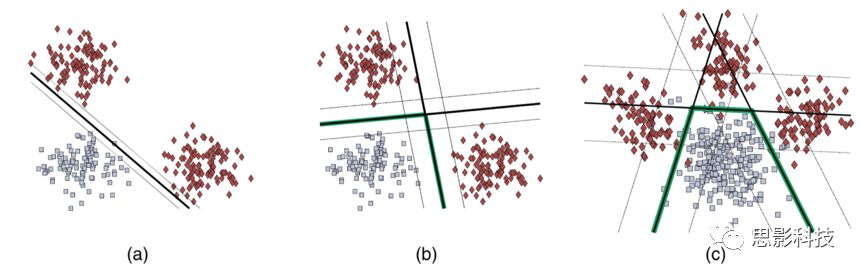
HYDRA算法的基本思路假设图中灰色方块为健康对照,红色菱形为患病被试。图(a)中,线性SVM将健康被试和患者在高维空间中使用一线性超平面(实线)分开,然而这个分类器的划分边界(点状线)很窄。众所周知,SVM分类器中会构建两条线穿过支持向量点,而SVM的优化目标则是使这两条线的距离最大。如果这两条线之间的距离比较窄的话,那么分类器的泛化性能则会比较弱。当然也可以使用核方法在高维空间中构建非线性超平面划分结果,但是这样构造的非线性函数可解释性比较弱。更重要的一点是,仅仅使用由监督学习构建出来的超平面无法发现患者数据中所隐含的数据堆(比如图a中,患者被试有两个
cluster,但是监督学习方法无法发现这样的数据堆);为了解决上面的问题,图(b)中,HYDRA使用多个线性分类器对数据进行划分,多个分类器构建的多个超平面则能够组成一个凸多边形(绿色加粗线段)。凸多边形的不同面捕获了不同的亚型;图(c),使用3个分类器构建的凸多边形捕获了3种亚型。(Varol E, Sotiras A, Davatzikos C. Alzheimer’s Disease Neuroimaging I. HYDRA: revealing heterogeneity of imaging and genetic patterns through a multiple max-margin discriminative analysis framework. NeuroImage 2017; 145: 346–64.)循环迭代估计超平面参数和聚类结果50次,20次估计聚类结果的一致性解,正则化参数为0.25,10折交叉验证。根据得到的解的稳定性来评估HYDRA的聚类性能。使用adjusted Rand指数(ARI,Hubert and Arabie, 1985)评估在十折交叉验证中,多次聚类结果的相似性。因此,ARI计算了被试被划分在同一个聚类堆中的一致性,尽管在不同的交叉验证中同一个被试可能会被划分在不同的聚类堆中。ARI的计算修正了被试的随机分组,对多个聚类结果的重合性估计提供了更加保守的估计。在这里,ARI等于1表示在多次交叉验证中,被试一直被划分在相同的聚类堆中。利用(i)Permutation test(排列测试):对亚型的可重复性进行了广泛的分析,以检验统计学意义;(ii)Split-sample reproducibility: 多次拿出不同样本,以评估每一半的子类型是否表现出相似的情况;(iii)“留一(数据采集站点)交叉验证(Leave-one-site-out validation)”,以检查使用此方法发现的子类型是否与将所有站点放在一起得到的解决方案一致。Permutation tests for the subtypes为了验证疾病亚型分布的稳定性,在健康(HC)样本中做了亚型分析,在这些样本中,与疾病相关的变异并不存在。为此,将HC样本(n = 364)随机分为HC组(~20%)和伪患者组(~80%),并进行HYDRA分析。这些样本随机重排了50次,并且每一次都运行一次HYDRA算法。为了将这些结果与实际患者组的聚类结果进行比较,研究人员使用了大小一样的HC和患者组(分别为~20%和~80%,364个人)。这样做是为了使零分布和实际实验使用完全相同的样本量。最后,将实际实验中得到的ARI与随机重排实验中得到的ARI的零分布进行比较,以确定其统计学意义。Split-sample reproducibility为了研究精神分裂症亚型的可重复性,研究人员进行了split-sample分析。数据样本被分成两半,然后分别在Split 1和Split 2中使用HYDRA算法。然后在两个Split中进一步比较体素水平的volumetric profiles(连接模式)。Leave-one-site-out validation(LOSO)通过使用LOSO进一步交叉验证得到的聚类结果。该方法首先在两个站点的数据中对HYDRA模型进行训练,然后使用训练后的模型在剩下的一个站点中的数据进行测试,识别出亚型(subtype)标签(subtype 1或subtype 2)。对所有三种可能的站点组合重复此过程,如图1所示。由LOSO策略预测出来的两个亚型与使用所有站点上的数据预测出来的亚型进行了比较。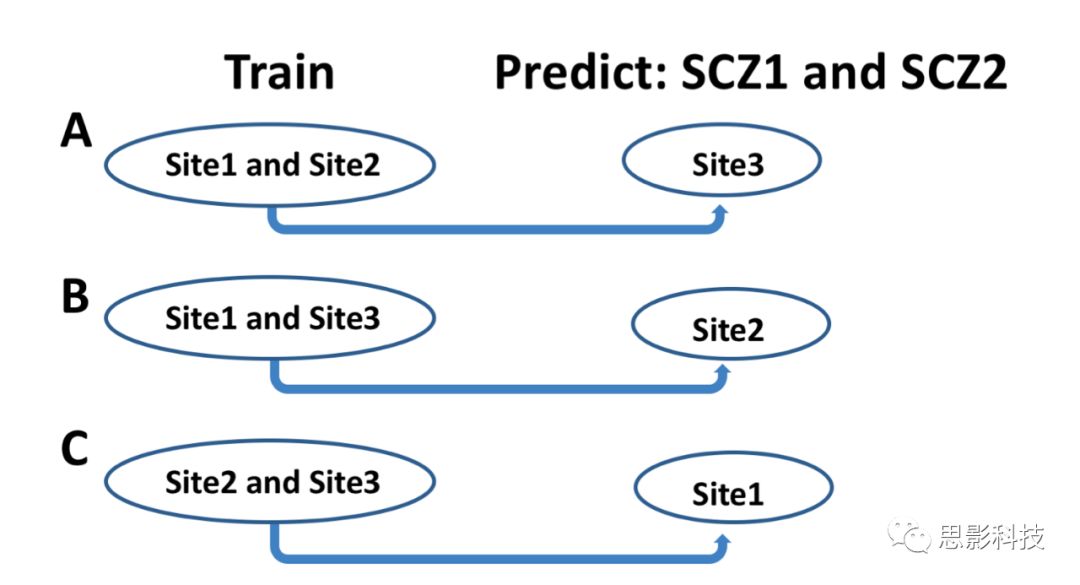
图1 LOSO预测示意图:每个站点的两个亚型(SCZ1和SCZ2)是使用在其他两个站点上训练的HYDRA模型确定的。同一亚型的患者重叠率为86.72% (站点1为83.33%,站点2为86.21%,站点3为90.63%),与使用所有站点的数据训练得到的结果相比较。
研究人员使用区域线性多元判别统计映射(regionally linear multivariate discriminative statistical mapping, MIDAS)进行体素水平的分析,以研究不同亚型之间的神经解剖学差异。MIDAS利用区域判别分析的能力,与其他信息映射方法(如Searchlight)相比,在检测组间差异方面具有较高的敏感性和特异性。
MIDAS是最近发表并验证的一种基于体素的组水平的比较方法。它克服了由于在应用广义线性模型之前通过任意和固定的高斯滤波器对图像进行临时过滤而导致的基于体素的常规分析的局限性。MIDAS有效地确定了能够最佳捕获组差异的任何图像数据的区域变化的、各向异性的滤波。使用MIDAS比较组间的regional volumetric map可以获得更好的统计效力。MIDAS使用一组足够大的重叠邻域(P)解析任意一组图像map(本文中为volumetric map),并基于最小二乘支持向量机(LS-SVM)进行区域判别分析。LS-SVM通过权重向量w将图像特征X∈R^{n x v}(n个被试以及v维的图像特征)与组变量Y∈R^n关联起来。对组间进行最优判别的区域模式等价于对一个最优核进行局部滤波,该核的系数为判别器的权值。然后,通过调整每个体素对估计的局部激活模式(a)的总体贡献,并使用各自机器学习器的总体预测能力,计算特定体素的统计量: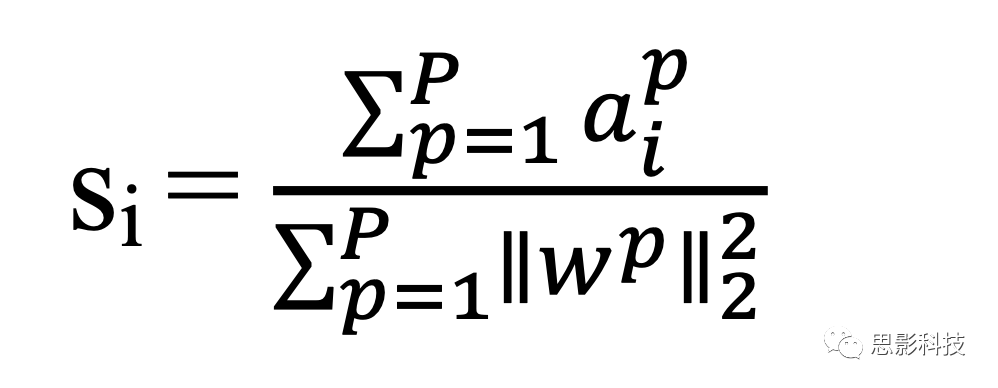
其中,a正比于(X-X_mean)^T(X-X_mean)w/n,其中i表示voxel的编号。这种体素水平的统计量表明了该体素在包含该体素的所有部分重叠区域过滤器中的参与程度。最后,通过近似排列试验(approximating permutation tests)得到体素统计量对应的p值。在MIDAS中,使用尺寸为182 x 218 x 182的GM、WM或CSF的体素区域容积图(voxel-wise regional volumetric maps)来评估组间的体素神经解剖学差异。MIDAS分析使用了以下参数:体素的15个邻域半径、500个邻域,正则化参数为0.1。在每个亚型中,总的灰质体积与疾病持续时间之间的关系通过使用Pearson相关分析进行评估。使用双样本t检验来评估不同亚型之间的差异,包括年龄、患病时间、每日氯丙嗪当量剂量(mg) (CPZ mg eq/day)、发病年龄、阳性症状和阴性症状(详见补充资料)。性别、受教育程度(顺序量表)和抗精神病药物类型(第一代与第二代)用卡方检验进行比较。在标准病例对照比较中,患者人群大脑容量既呈现减少的趋势又呈现增加的趋势(图2),但尚不清楚这些影响是由整个患病人群还是由部分患者亚群造成的。HYDRA有效地解决了这个问题,如下所述。研究人员将HYDRA应用于感兴趣区域的结构像数据上(见补充材料表1),以识别亚型。他们使用adjusted Rand指数(ARI)来评估在不同数量的聚类堆(2到8个聚类堆)下聚类堆聚类的一致性(也就是聚类结果的稳定性,如果多次运行HYDRA算法得出的亚型聚类堆具有较高的相似性,则说明所发现的亚型具有高度的可重复性,反映了聚类出来的亚型的有效性),该指数对聚类堆的数量(K)相对不敏感。当聚类数量K=1的时候,ARI指标并没有意义,因为所有的患者被聚类到一个聚类堆中。然而,如果把样本理解为呈现均匀分布的话(即最优K=1),那么可以在别的K值中找到较低的ARI值。当K=2时,可以找到最大的ARI数值指标,ARI=0.616(见图3)。K位于2到8之间时,ARI指标在0.4左右,低于K=2的时候。当K值变化时,精神分裂症患者在不同K值以及不同数据站点的分布情况如补充材料表2所示。在K = 2时,每个数据站点有更多的患者被分配到亚型1。为了确定疾病亚型聚类的统计显著性,研究人员将每个聚类堆的ARI指标与使用排列测试生成的零分布进行了比较。K= 2时的ARI值高于零分布(P_fdr < 0.001)(图4),但K=3时的ARI值不高于零分布。K=4 ~ 8时的ARIs也高于零分布;然而,当聚类数量为3或者更大时,聚类出来的疾病亚型之间将呈现更多的性别、年龄或数据站点差异(见补充材料表2-9)。在split-sample实验中,K=2时依然具有最高的可重复性(图5)。当K=2时,在
Split 1与Split 2中也存在具有可重复性的体素模式(voxel-wise volumetric patterns,本文中,这里指的是体素水平上的体积差异模式),但是当K>2时则没有(图6和图7)。此外,还是用“留一(数据站点)交叉验证”方法对疾病亚型进行可重复性的分析(图1)。使用“留一(数据站点)交叉验证”方法从所有三个站点获得的亚型1和亚型2与同时使用所有站点数据计算得到的两个亚型进行了比较(见补充材料表2: K=2)。在HYDRA的多次迭代聚类的过程中,被聚类到相同类别的患者比例为86.72%,站点1的患者中,这个比例为83.33%,站点2为86.21%,站点3为90.63%。这两种亚型在不同站点的数据中具有较高的可重复性(图8)。鉴于这些结果,随后的分析将集中在这两个具有较高可重复性的疾病亚型。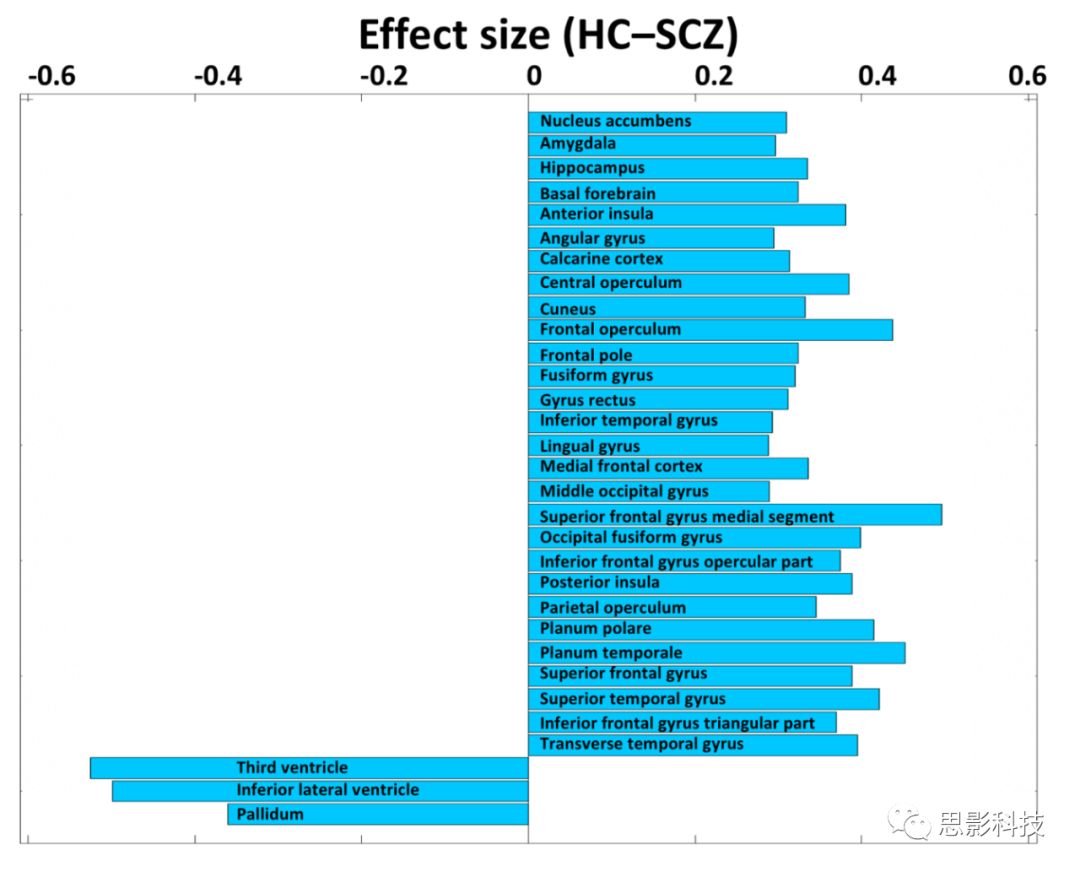
图2 健康对照组(HC) (n = 364)和精神分裂症(SCZ) (n = 307)的关键区域的体积差异。注意,在这个标准病例对照比较中,区域体积既呈现减少的趋势又呈现增加的趋势。
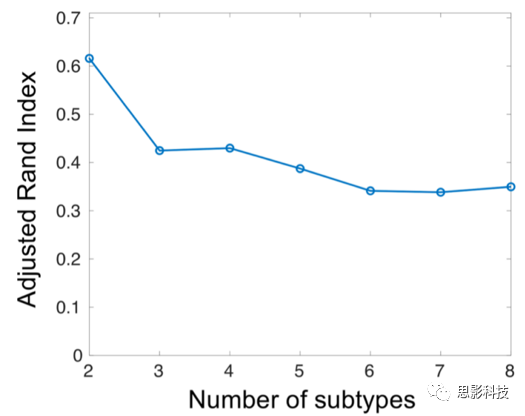
图3 精神分裂症亚型的交叉验证稳定性:K=2时,具有最高的亚型聚类稳定性。
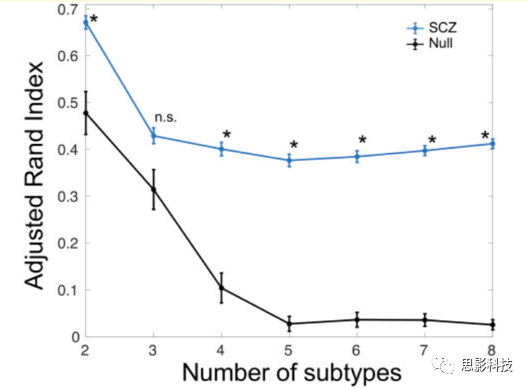
图4 通过与随机排列得到的零分布比较,得到在不同数量亚型(K)下的ARI的统计显著性。n.s代表没有显著性。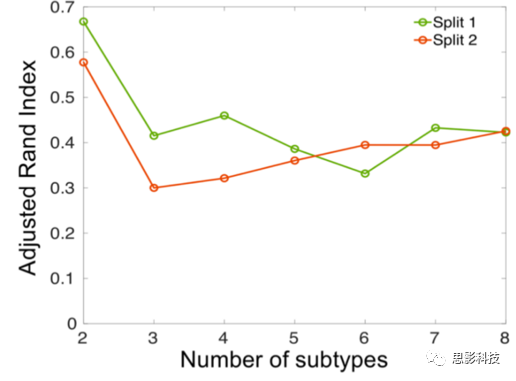
图5 split-sample测试中的交叉验证稳定性:ARI指标与聚类数量K的关系,当K=2时,在Split 1和Split 2中均呈现最高的可重复性。
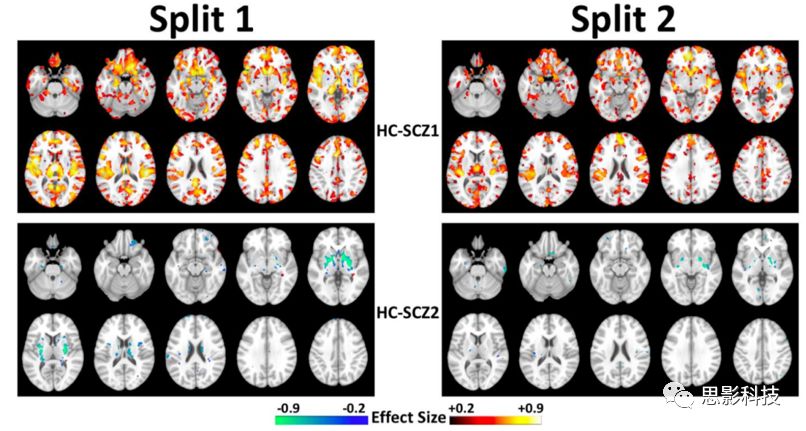
图6 K = 2时,在两个Split中,每个亚型(HC-SCZ1与HC-SCZ2)与HC之间的GM体积差异。GM的体积差异模式与使用所有数据得到的体积差异模式均相似,FDR-p<0.05。在MIDAS分析中,Effect Size图是由一组区域所掩盖的区域体积图(regional volumetric maps)生成的,这些区域在统计上有显著差异,之后的所有Effect Size图都是这样生成的。
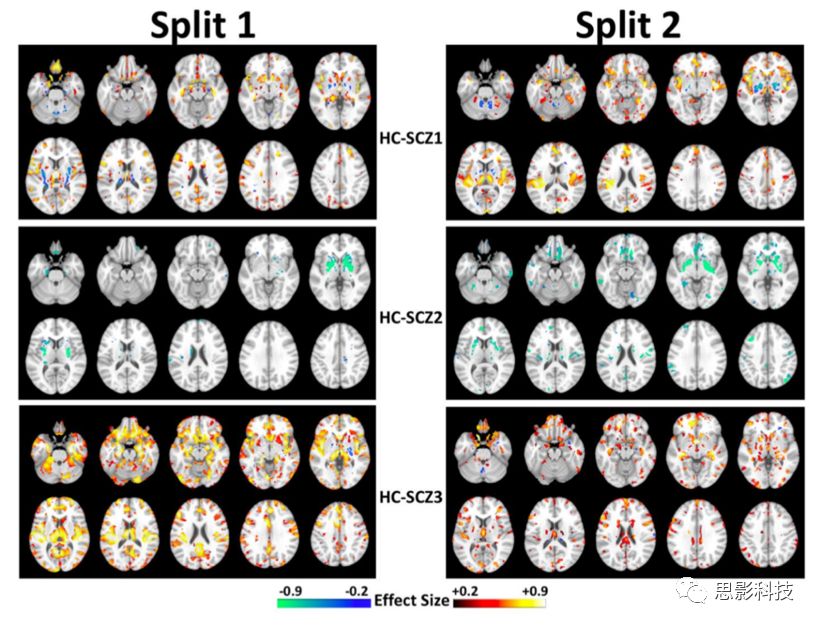
图7 K=3时,在两个Split中,每个亚型与HC之间的GM体积差异模式。Split 1与Split 2中不存在具有可重复性的模式,FDR-p<0.05。
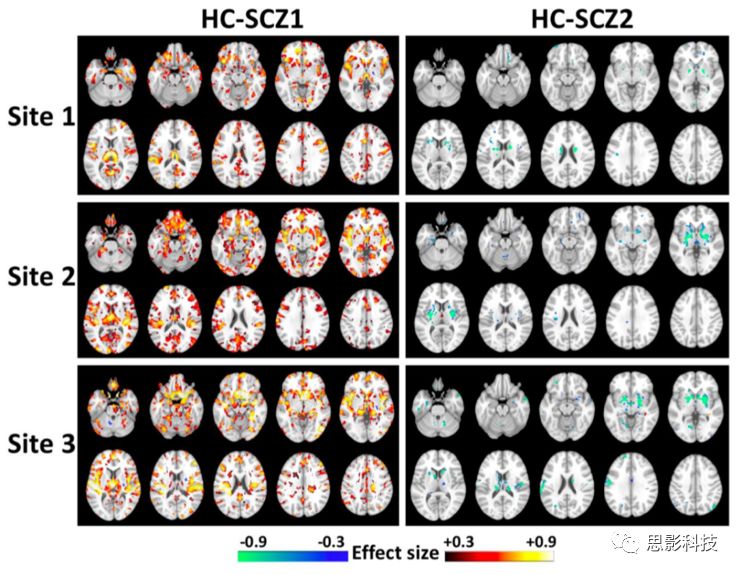
图8 每个站点中,疾病亚型与健康对照(HC)之间的GM体积差异:与HC相比,SCZ1在丘脑、伏隔核、内侧颞叶、内侧前额叶/额叶和岛叶皮质中体积明显增大,而SCZ2在基底神经节中体积增大,FDR-p<0.05
亚型之间在体素水平上存在显著的神经解剖学缺陷差异(图9)。与健康对照组(图9A)和亚型2(图10)相比,亚型1表现出广泛分布的灰质缺陷。与健康对照组相比,亚型1在丘脑、伏隔核、内侧颞叶、内侧前额叶和岛叶皮质具有最为突出的异常。此外,亚型1表现出广泛减少的白质体积(图9C)。相比之下,亚型2的脑解剖结构正常,但基底神经节(苍白球、壳核和尾状核部分)的灰质体积较大(图9B)。与健康对照组相比,亚型2的深部结构,特别是内囊的白质体积也相对较大(图9D)。与健康对照组相比,这两种亚型脑脊液体积均轻度升高,主要发生在第三脑室和额叶半球间裂中(图11)。
图9 灰质和白质的体积模式确定了这两种亚型。相比于健康对照组(HC), (A)精神分裂症亚型1 (SCZ1)表现出较少的灰质体积的普遍模式,特别是在丘脑、伏隔核、内侧颞叶、内侧前额叶/额叶和岛叶皮质 (B)精神分裂症亚型2 (SCZ2)在基底神经节(苍白球、壳和尾状部分)中表现出较大的灰质体积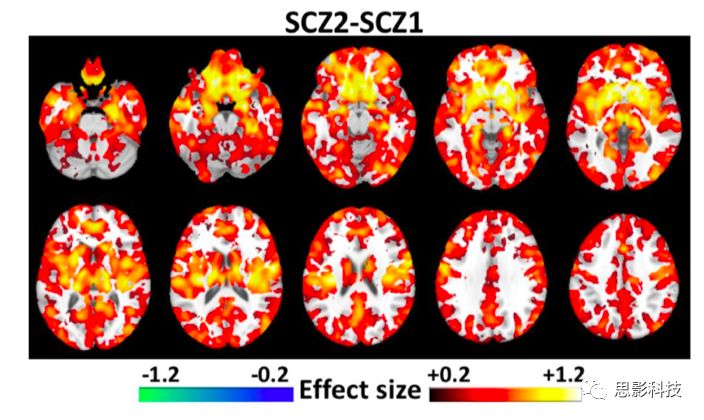
图10 两个疾病亚型之间的GM体积模式比较,FDR-p<0.05
。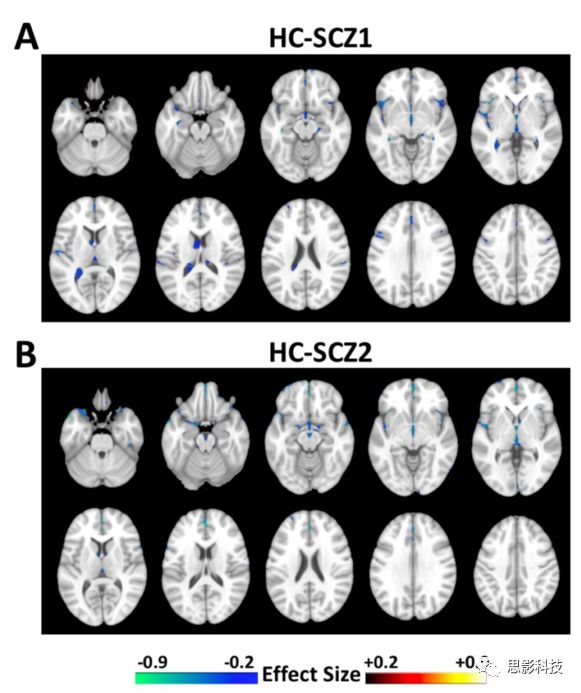
图11 每个亚型与健康对照之间的CSF体积差异模式比较,FDR-p<0.05
相比使用所有站点的数据(图9)一起计算得到的结果,使用“留一(数据站点)交叉验证”的方法得到的亚型表现出最佳的可重复性(图12)。与上述结果一致,亚型1存在广泛分布的异常,最明显的是在丘脑、伏隔核、内侧颞叶、内侧前额叶和岛叶皮质(图12A)的灰质减少,而亚型2在基底神经节体积较大(图12B)。与亚型2相比,亚型1也表现出灰质缺陷的分布模式(图13),这与上述结果(图10)一致。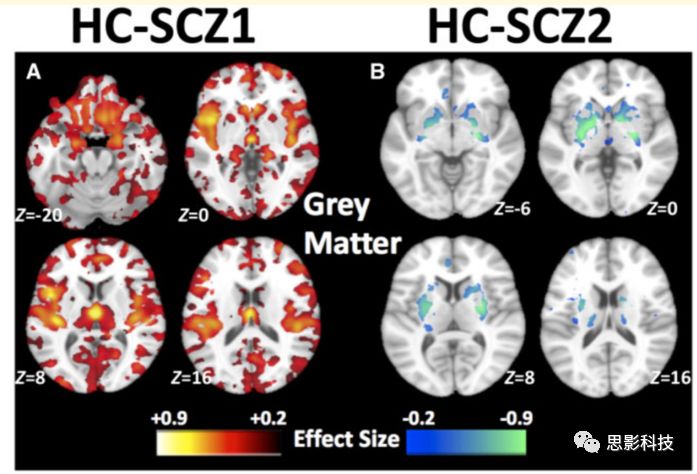
图12 可重复性分析。使用“留一(数据站点)交叉验证”方法分析两种亚型的灰质体积模式:与健康对照(HC)相比,(A)精神分裂症亚型1(SCZ1)在丘脑、伏隔核、颞内侧、额前/额内侧和岛状皮层表现出较小的体积(B)亚型2(SCZ2)在基底神经节中显示较大的体积。
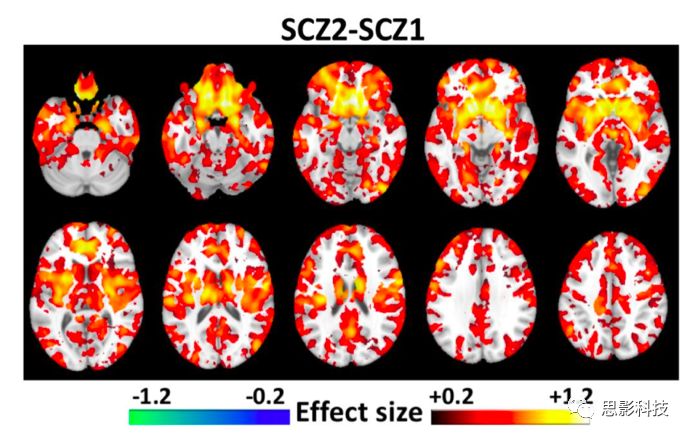
图13 使用“留一(数据站点)交叉验证”法估计的两种亚型间的GM体积模式,FDR-p<0.05。这些结果与使用所有数据计算得到的结果是一致的(图10)。
接下来,研究人员进行了敏感性分析,以确保上述结果不受样本量、性别差异、药物、疾病长期性或组织对比度的影响。首先,确保这些发现不受样本数量大小差异的影响(亚型1:n = 192;亚型2:n = 115),他们在亚型1的一个子集(n = 115)中做了重复分析,发现了一致的模式(图14);第二,亚型1具有广泛分布的异常灰质体积的减少,亚型2在男性和女性中都具有较大的基底神经节(图15);第三,评估药物治疗的潜在贡献,研究者调整了抗精神病药剂量(氯丙嗪当量,CPZ)。与图9的结果一致,在控制了氯丙嗪(图16和17)后,亚型仍然存在,尽管在这个有药物信息的子样本中样本量和相应的统计能力显著降低。第四,他们进一步将分析限于病程小于2年的精神分裂症样本(占总精神分裂症样本的
1/3,平均病程0.54年),以减轻疾病慢性病的影响(图18-20)。虽然观察到完整的精神分裂症样本(图9)与病程小于2年的精神分裂症样本(图18)有相似之处,但在脑灰质缺损的空间分布上,如在岛叶皮层上,存在一些明显的差异。最后,研究人员检验了灰质和白质体积的总和(即大脑的总体积),以确保结果不受因为图像对比度变化所导致的灰白质分割效果(一般来说,现有的分割算法是基于脑脊液、灰白质之间的对比度和解剖先验进行分割的,如果图像的灰白质对比度发生变化,图像的灰白质分割效果可能会受到对比度的影响)的影响。这个分析产生了与主分析一致的疾病亚型模式(图21)。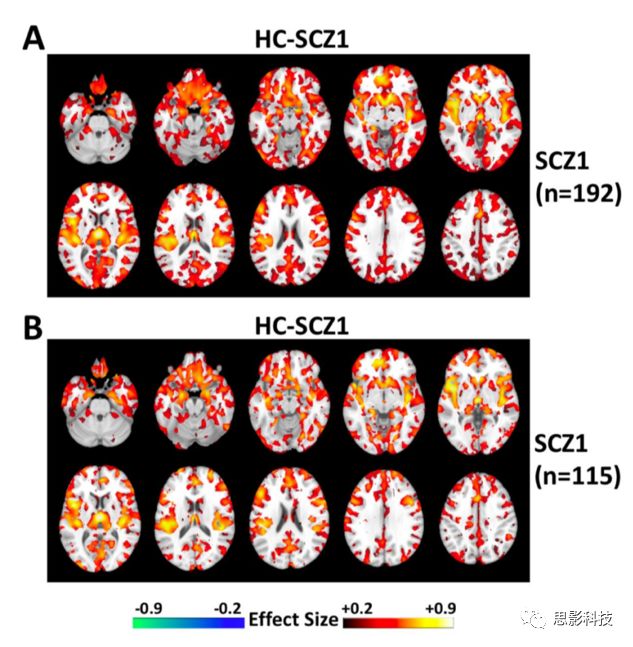
图14 分别将(A)使用所有数据样本计算得到的亚型1和(B)使用与亚型2一样数量的自样本计算的到的亚型1与健康被试比较得到GM体积差异图,FDR-p<0.05。本实验表明,在SCZ1中观察到的较小的GM体积的发现并不受SCZ1较大的样本量影响。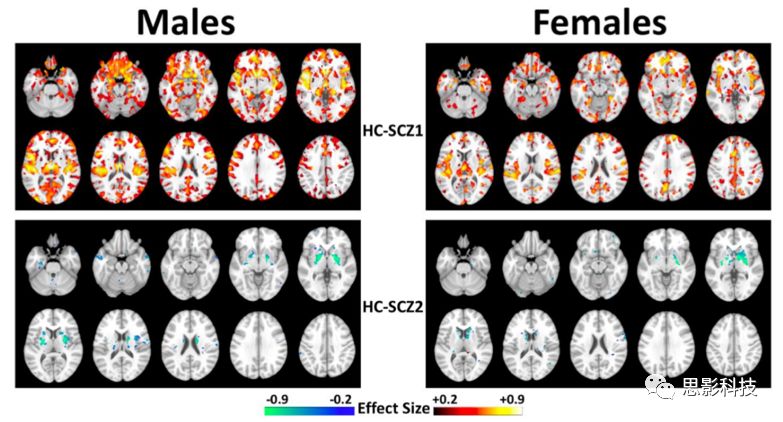
图15 男性(左栏)和女性(右栏)分别是各亚型相对于HC的GM体积模式,FDR-p < 0.05。这些模式与同时使用两个性别的数据得到的模式是一致的,这表明,亚型的估计并不是由两个亚型的性别差异驱动的。
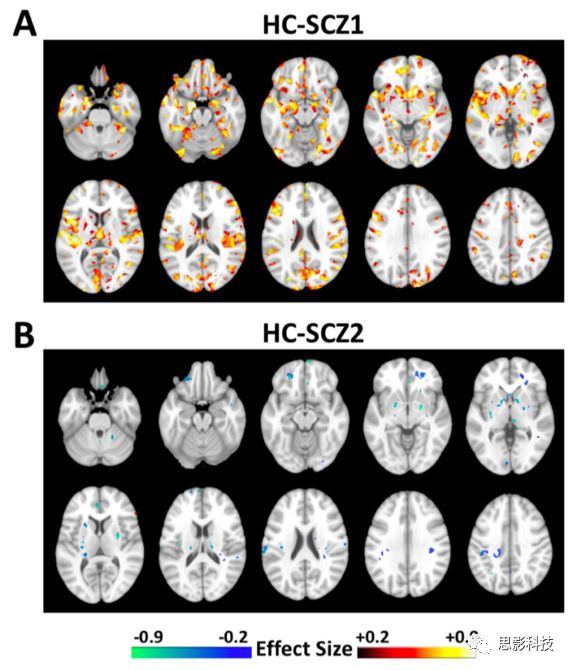
图16 当cpz当量剂量数据调整之后,与HC相比,K=2的亚型的GM体积模式发生了改变 [n = 125 SCZ1,n = 87 SCZ2]。这些模式与从整个样本中得到的模式是一致的,尽管较弱,主要是由于样本量较小,FDR-p < 0.05。
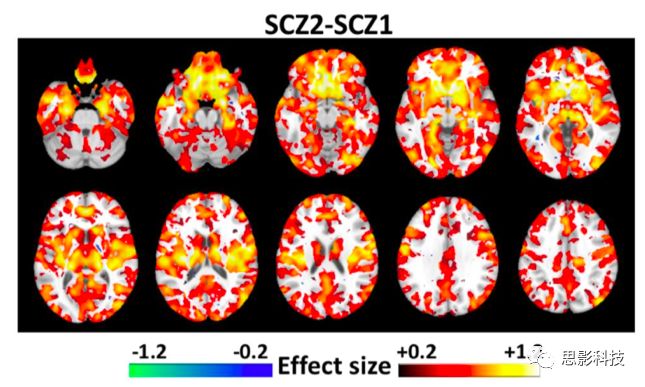
图17 经cpz当量剂量调整后,两种亚型间GM体积差异的比较(FDR-p < 0.05)。这些结果与未进行CPZ调整的结果一致(图10和图13)。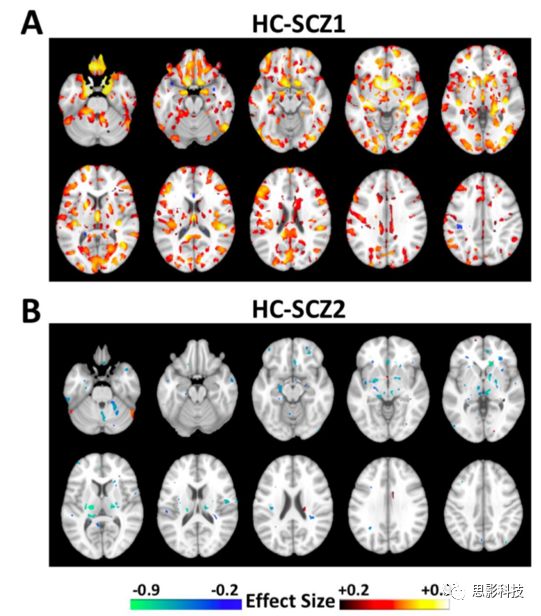
图18 在病程小于2年的患者中(平均病程为0.54年),由此计算得到的两个亚型与健康被试之间的GM体积差异,FDR-p<0.05
。这些模式与来自较大群体的研究结果一致,只是由于样本量较小,结果略弱一些。

图19 在病程小于2年的患者中,由此计算得到的两个亚型与健康被试之间的CSF体积差异,FDR-p<0.05。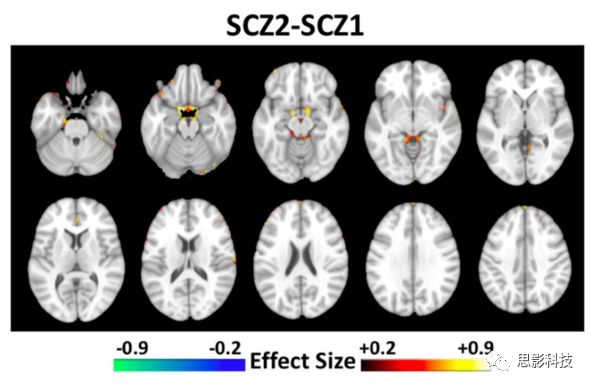
图20 在病程小于2年的患者中,由此计算得到的两个亚型之间的CSF体积模式,FDR-p<0.05。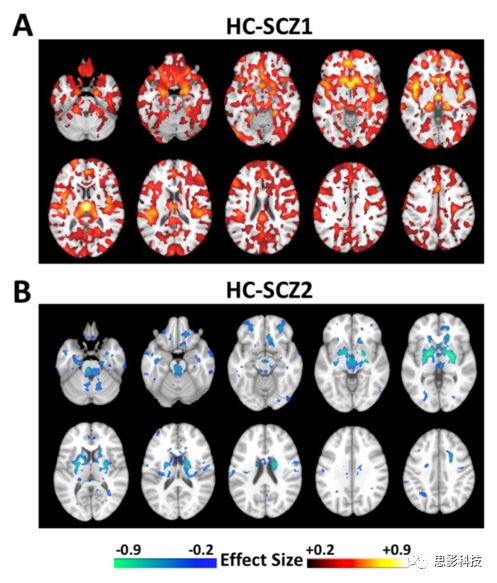
图21 每个疾病亚型与健康对照之间的脑组织(灰质和白质)的体积差异模式图。图中结果分别与灰质和白质的结果一致。所以MRI图像中灰质与白质之间的对比度并不会影响组织分割结果以及疾病亚型的聚类结果。
表2 精神分裂症亚型1和亚型2患者的人口学和临床指标的比较 FGAs=第一代抗精神病药;SCZ1 =精神分裂症亚型1;精神分裂症亚型2; SGAs=第二代抗精神病药。
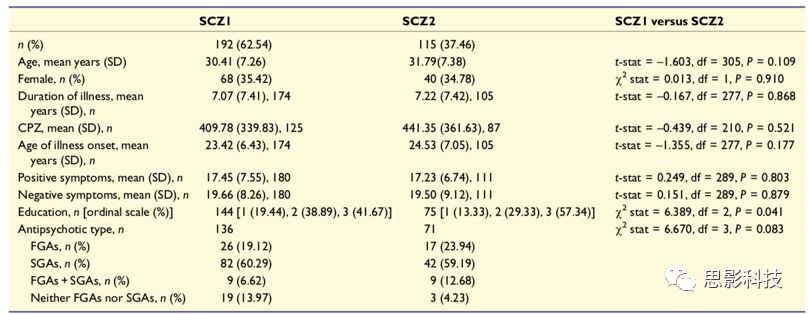
亚型1中患者的受教育程度较低(卡方= 6.389,d.f. = 2, P = 0.041),但在年龄、性别、患病时间、抗精神病药物剂量、发病年龄、症状严重程度或抗精神病药物类型等方面,两个亚型无差异(表2)。亚型1患者灰质体积与病程呈负相关(r = -0.201;P = 0.016),但亚型2并没有这样的现象 (r = -0.045;P = 0.652),如图22。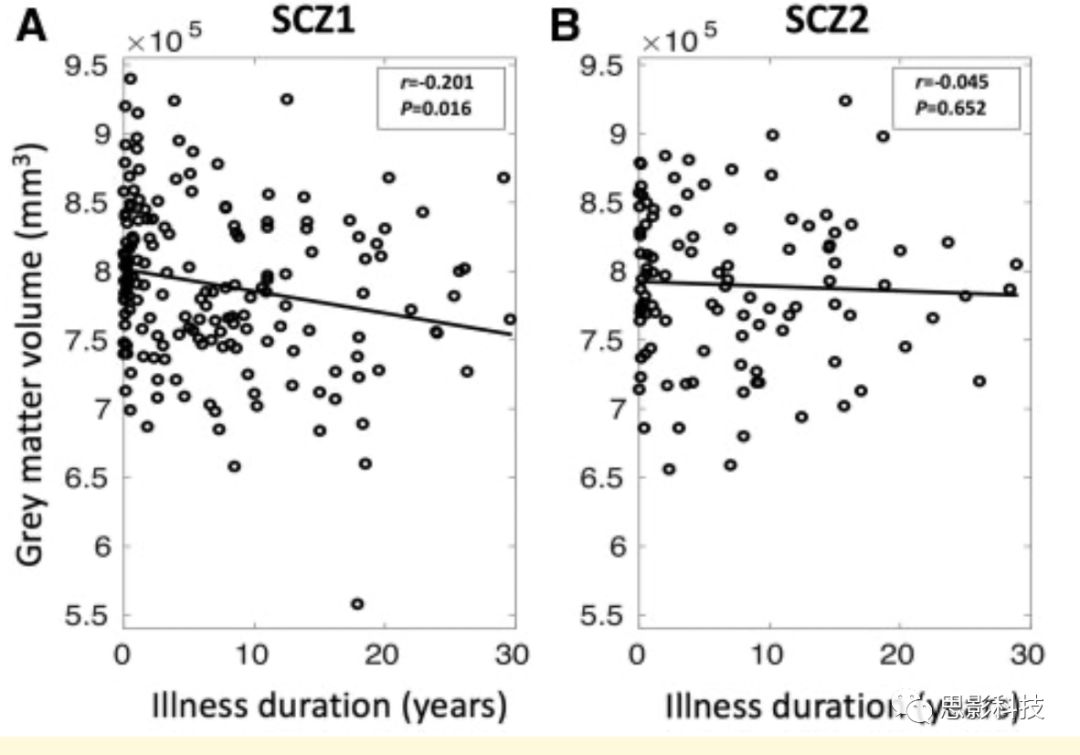
图22
两种亚型的总灰质体积与病程的关系。A)精神分裂症亚型1患者灰质体积与病程呈负相关(SCZ1;r = -0.201, PFDR = 0.016),但(B)精神分裂症亚型2的灰质体积与病程无显著相关性(SCZ2;r = -0.045, P = 0.652)。
讨论
研究人员确定了精神分裂症的两个明显不同的神经解剖亚型。相对于健康对照组,亚型1显示出广泛分布的灰质减少的模式,而亚型2表现出正常的灰质和白质背景下,基底节和内囊的体积增加。这项研究的总体结果总结在图23中。这两种亚型对排列试验(permutation test)、分离样本试验(split sample test)、留一(数据站点)交叉验证试验、性别分析、抗精神药物剂量调整和对病程不超过2年的患者的限制具有鲁棒性。关键的是,标准的病例对照比较掩盖了这样一个事实,即精神分裂症的平均差异来自于不同的神经解剖学亚型,灰质的减少仅占患者总数的约三分之二,皮层下的增加仅占患者总数的约三分之一。最近使用normative models的研究也表明,精神分裂症的这种平均群体差异掩盖了生物异质性,客观地定义生物亚型是一个合乎逻辑的下一步。随着对神经影像学异质性的不断认识,上述分析揭示了无法通过(相对粗糙的)临床表型检测到的亚型,但这些亚型可能具有尚未被发现的临床意义。因此,文章中的发现挑战了精神分裂症患者脑容量普遍减少的主流观点,澄清了以前的病例对照研究结果,并首次提出精神分裂症患者的亚型之间存在根本的脑差异,而这些亚型并没有被慢性或标准的临床措施明确界定。
神经解剖学模式和潜在的机制
自从早期的大脑造影研究以来,已经形成了一种共识,即被诊断为精神分裂症的个体表现出灰质减少和脑室增大,这已被最近的meta分析和mega分析所证实。亚型1中,所观察到的灰质减少与一项大型分析报告的结果一致,即脑岛最大容量缺陷。一项多数据中心的研究发现内侧额叶、颞边缘和大脑外侧外侧皮质萎缩;ENIGMA和COCORO项目发现海马体、丘脑和伏隔核的体积减少。
本文的研究发现了皮质下灰质的增加,并且揭示了一些脑结构的个体差异。在这里,研究人员发现基底神经节体积的增加仅发生在一部分皮质灰质没有减少的个体中(所占比例约为37%)。这些结果挑战了传统观念,即脑容量减少是精神分裂症的普遍特征。精神分裂症多基因风险和单一风险等位基因也与非临床样本中较大的壳核有关。此外,最近的一项研究发现,经初次诊断的未接受过药物治疗的样本中的壳核蛋白量增加,而家庭成员未受影响。
综上所述,本文的发现可能暗示先前未发现过的原发性多巴胺痛精神分裂症亚型。与亚型2的体积增加受限相比,亚型1的广泛分布的体积减小与早期神经发育破坏,炎症和皮质功能障碍相关的机制更为一致,在这种机制中,补体-小胶质细胞系统的过度活动可产生突触过度修剪并损害中间神经元迁移。中间神经元功能障碍和更广泛的皮质异常发育,也与谷氨酸过高和皮质中的兴奋性/抑制性平衡失调有关。虽然这些机制可能导致继发性多巴胺能破坏,但原发性非多巴胺能异常的存在可能使1型患者对目前的多巴胺阻断性抗精神病药反应较弱。

图23 精神分裂症亚型1(SCZ1)与亚型2(SCZ2)的总结。
总之,本文发现了精神分裂症的两个明显不同的神经解剖亚型,从而提示了这种疾病在神经解剖学上的两种疾病维度。相对于健康对照组,亚型1具有较小的灰质体积的广泛分布模式,而亚型2具有相对较大的基底神经节和内囊,但皮层解剖结构正常。这两种亚型在病例对照研究或临床亚型研究中并未发现,这些研究没有直接说明潜在的神经解剖学异质性。未来的研究将结合脑结构和功能的其他方面以及临床特征(包括认知表现,急性治疗反应,纵向进展和病因)等信息进行更加细致的研究。这些“亚型特征”将在高风险,亚综合征和流行病学样本中追踪。随着进一步的研究,这些亚型可能有助于利用广泛使用的临床脑成像方法在诊断、预后和治疗方面的生物异质性的细致的临床护理。本文给机器学习如何更进一步的介入神经影像学和临床诊断之间的关系给出了一个很好的范例,在一些疾病的神经基础难以从理论上阐释清楚时,仅仅依靠临床症状及行为表现来进行疾病亚型的诊断不仅容易出现分类不清的问题,而且对进行诊断的医生也提出了很高的要求,使用机器学习的方法,结合监督和半监督可以更好的对疾病潜在的亚型进行探索和进一步确认。在当前,不同疾病的脑影像数据的积累已经向着多中心、大数据的方向不断前进了,这给机器学习甚至于深度学习的介入提供了良好的基础,在以后的相应实践中一定能够大放异彩。计算机视觉领域的大跨步发展已经给我们一个很好的启示了,现在已经是“取经”的开端时间了,再犹豫就要错过这个“风起云涌,英雄辈出”的新机遇了,不要等待,这里的机器学习班等你来战!(目前思影科技采取预报名制度,以下所有课程均可报名,受疫情影响课程时间有调整,报名后我们会第一时间联系,并保留名额):
如需原文及补充材料请加微信:siyingyxf 或者19962074063获取,如对思影课程感兴趣也可加此微信号咨询。
另思影科技招聘兼职文章解读人员,需具备一定的脑电、近红外、脑影像数据分析功底。可添加上文微信号联系。
微信扫码或者长按选择识别关注思影
非常感谢转发支持与推荐
欢迎浏览思影的数据处理课程以及数据处理业务介绍。(请直接点击下文文字即可浏览思影科技所有的课程,欢迎添加微信号siyingyxf或19962074063进行咨询,目前思影采取预报名制度,所有课程均开放报名,受疫情影响部分课程时间或有调整,报名后我们会第一时间联系,会为您保留名额):
第十五届磁共振脑网络数据处理班(南京4.13-18)
弥散磁共振成像数据处理提高班
脑电数据处理入门班
脑电数据处理中级班
数据处理服务,招聘及其他产品(直接点击即可浏览内容):
目镜式功能磁共振刺激系统介绍








