乾明 发自 凹非寺
量子位 报道 | 公众号 QbitAI
AI框架,又来重磅中国玩家。
刚刚,清华自研的深度学习框架,正式对外开源。“贵系”计算机系的图形实验室出品,取名Jittor,中文名计图。
值得一提的是,这也是首个来自中国高校科研机构的开源深度学习框架,之前,业内来自“高校”的还有加拿大蒙特利尔大学的Theano,UC伯克利的Caffe。
与主流的深度学习框架TensorFlow、Pytorch不同,Jittor是一个完全基于动态编译(Just-in-time)、使用元算子和统一计算图的深度学习框架。
研发团队介绍称,开发Jittor是为了将新技术、硬件和模型的能力,更好地释放出来。
“深度学习发展迅猛,TensorFlow、PyTorch这些老牌主流框架,也会在新模型,新算法,新硬件上表现不佳,所以需要新的框架,在易于扩展同时保持高效。”
而现在框架呈现出来的能力,的确有超越“前辈”的倾向:
基于Jittor开发的深度学习模型,可以实时自动优化并运行在指定的硬件上,如CPU,GPU,在多种机器视觉任务上能够比同类产品PyTorch性能提高10%~50%。
团队还介绍,如此成果,得益于Jittor的两大创新点:元算子和统一计算图。这也是Jittor的立身之本。
Jittor的核心:元算子与统一计算图
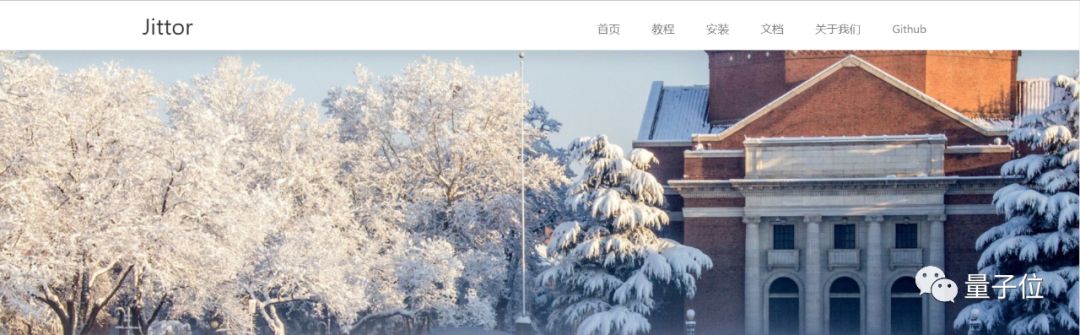
根据Jittor官方文档定义,元算子是指神经网络所需的基本算子。
在TensorFlow,PyTorch框架底层,有上千个算子,如此多的算子使得开发和优化难度大幅提升。
在设计Jittor的时候,他们就定下了一个目标,即用户只需要数行代码,就可定义新的算子和模型。同时在保证易用的同时,不丧失任何可定制性。
所以在Jittor中,多个元算子之间,可以相互融合成更加复杂的算子,这些复杂算子构成了神经网络计算的多个模块,如卷积层,归一化层等等。
他们将这种融合称为元算子融合,可以提升性能,节省资源。在文档中,他们分享了一个案例:只用4个元算子,就实现了卷积操作。
他们介绍称,元算子的可拓展性很强,通过对元算子的简单修改,就可以实现更多复杂的卷积操作,如扩张卷积、深度卷积、点卷积、分离式卷积、反卷积等。
而且,通过元算子反向传播闭包,能自动生成反向卷积层。具体如下图所示,反向卷积层将来自输出的梯度,通过4个元算子,将梯度反向传播给卷积层的权重:

Jittor开发团队介绍称,在这样的设计下,元算子和Numpy一样易于使用,并且超越Numpy能够实现更复杂更高效的操作。
而且,通过元算子的反向传播闭包,Jittor可以对所有前向反向算子进行统一管理,这就是他们所说的第二个创新点:统一计算图。
简单来说,统一计算图是完成了多种统一的动态计算图。根据官方文档介绍,在Jittor中,核心有四个方面的统一:
统一管理前向反向计算图,使得高阶导数可以被支持。
统一管理CPU,GPU内存,使得训练模型时,可以突破原有的GPU显存限制,让CPU,GPU可以共享内存。
统一同步、异步运行接口,使得数据读取,内存拷贝,模型计算可以同时进行,提升性能
统一管理多次迭代的计算图,使得平台可以实现跨迭代的融合优化。
基于这个方面,他们给出了Jittor与其他各个框架的特性对比:
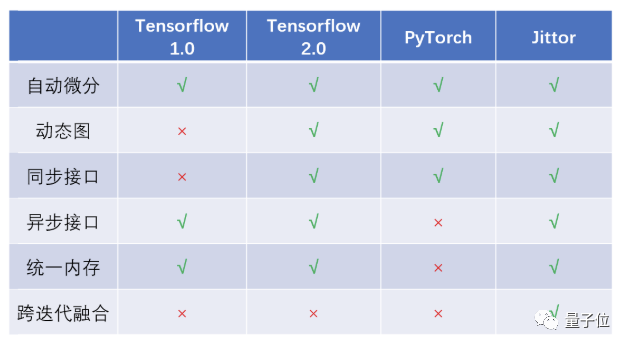
自动微分、动态图方面,Tensorflow、Pytorch和Jittor都支持。但在同步接口和异步接口方面,Jittor的优异性得到了体现。
同步接口易于编程,异步接口有助于提高性能,Jittor同时支持这两种接口。
相比之下,Tensorflow部分算子支持统一内存管理,而PyTorch不支持异步接口,而Jittor的所有算子都支持统一内存管理,当深度学习模型将GPU内存资源耗尽时,将使用CPU内存来弥补。

除此之外,Jittor还支持跨迭代融合。
在这些特性的支持下,Jittor具备了动态编译的能力。
官方文档介绍称,通过内置元算子编译器,可以将用户用元算子编写的Python代码,动态编译成高性能的C++代码。
比如,下图中的Python代码编写了神经网络中常用的批归一化层(batch norm), 通过元算子编译器,动态生成了批归一化层C++代码。

开发团队介绍称,Jittor还会使用内置的编译优化,以及LLVM兼容的优化编译遍(complier pass)来优化动态生成的代码。
这些编译会根据硬件设备,自动优化动态编译的代码,常见的优化编译有:循环重排,循环分裂,循环融合,数据打包,向量化,GPU并行。
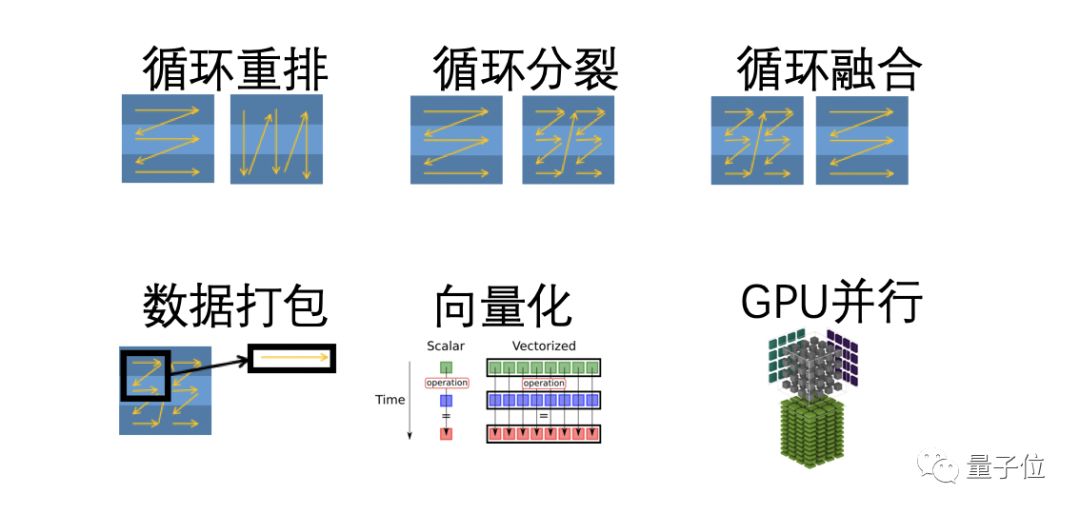
他们说,这些编译遍,能够对C++代码进一步优化,生成对计算设备友好的底层算子,从而提高性能。
这体现了他们设计Jittor的另一个理念:
所有代码都是即时编译并且运行的,包括Jittor本身。用户可以随时对Jittor的所有代码进行修改,并且动态运行。
此外,在整体设计中,他们还遵循了实现与优化分离的理念。
如此打造出来的整体架构,“用户可以通过前端接口专注于实现,而实现自动被后端优化。从而提升前端代码的可读性,以及后端优化的鲁棒性和可重用性。”他们介绍称。
Jittor的整体架构与上手样例
具体来说,Jittor的整体架构一共分为四层,如下图所示:
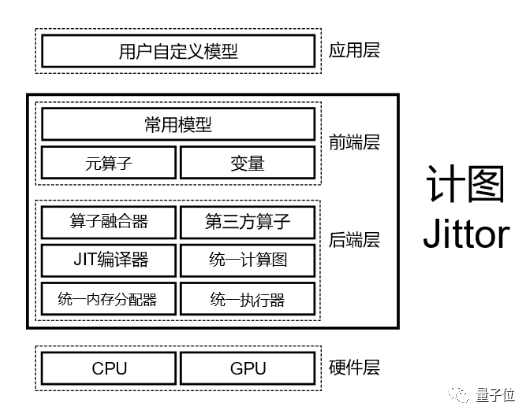
它是基于Jit编译技术、完全重新设计的深度学习框架,从上到下分别是应用层,前端层,后端层,硬件层,官方文档的介绍如下:
应用层的代码,用户使用Python编写,并可以访问从前端层公开的所有接口。
前端层 是Jittor的组件之一,代码用Python编写,提供了元算子的调用接口,来操作Jittor变量和Jittor实现的通用模型。
后端层是Jittor的内核,由C++编写,管理底层硬件资源。该层包含很多模块,比如算子融合器、第三方算子、JIT编译器、统一计算图、统一内存调度、统一执行器等。
硬件层支持的硬件有CPU和Nvidia GPU。但如果需要让Jittor支持新的硬件,只需要重载编译接口即可,让Jittor移植到新的硬件的难度将大大降低。Jittor开发团队说,他们将在未来支持更多的计算设备。
如此架构,用起来怎样?官方文档介绍称,从头只需要若干行代码,就能训练一个两层神经网络。

上面的代码,定义了激活函数和全连接层。Jittor开发团队介绍称,其实这些层已经集成在了框架中,并使用了类似的实现方式,在这里重新定义,用于更好展示内部机制和实现。
从代码中可以看出,Jittor的接口和现在主流深度学习框架接口类似,都是使用模块化的方式定义模型。其中,random、matmul、exp都是Jittor的内置算子。
基于JIT编译,Jittor的后端会将这几个算子自动融合成一个算子。

上面的代码,定义了双层神经网络。隐层的神经元个数是10, 使用的激活函数是上面定义好的sigmoid。

最后,可以从头开始训练模型。在这段代码,使用了梯度下降和L2 loss来训练网络。训练过程是异步的。
Jittor开发团队介绍称,Jittor会自动计算梯度并且将计算图保存起来,后端的JIT编译器会根据计算图,同时使用算子级别优化和图级别的优化。
他们进一步解释称,在这一示例中,Jittor使用了以下几种优化:
算子融合:激活函数和loss函数会被融合在一起。
并行化:算子会自动并行化以提升性能和计算密集度,在现代多核CPU和GPU上十分有效。
并发:没有依赖关系的操作会被并发执行,比如内存拷贝和计算可以并发并相互重叠。
元算子与统一计算图加持,整体框架优化下,Jittor在一些任务上展现出了性能提升,在多种机器视觉任务上尤为明显。
多个视觉任务上,性能超过现有主流框架
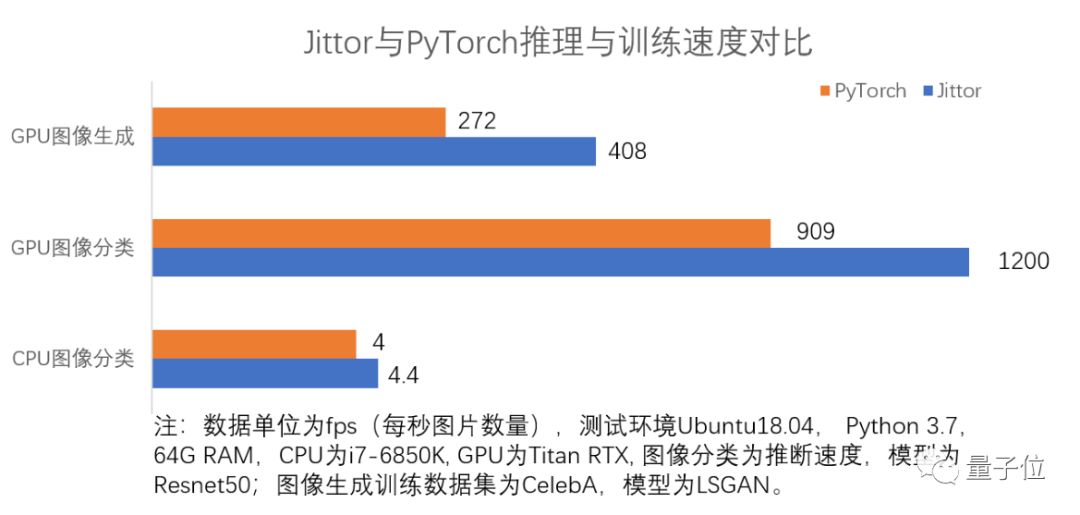
Jittor开发团队提供了实验数据。在ImageNet数据集上,使用Resnet50模型,GPU图像分类任务性能比PyTorch相比,提升32%;CPU图像分类任务提升11%。
在CelebA数据集上,使用LSGAN模型,使用GPU处理图像生成任务,Jittor比PyTorch性能提升达51%。
此外,为了方便更多人上手Jittor,开发团队采用了和PyTorch较为相似的模块化接口,并提供辅助转换脚本,可以将PyTorch的模型自动转换成Jittor的模型。
他们介绍称,在参数保存和数据传输上,Jittor使用和PyTorch一样的 Numpy+pickle 协议,所以Jittor和PyTorch的模型可以相互加载和调用。

当然, Jittor作为一个新兴深度学习框架,在一些功能上,仍旧需要持续迭代完善。比如生态的建设,以及更大范围的推广,仍旧需要很多的努力。
Jittor开发团队介绍称,就目前来看,Jittor框架的模型支持还待完善,分布式功能待完善。这也是他们下一阶段研发的重点。
首个中国高校深度学习开源框架,清华教授领衔打造
最后,是时候介绍Jittor的开发团队出场,他们来自清华大学计算机系图形学实验室,牵头者是清华大学计算机系胡事民教授。
该实验室的主要研究方向是计算机图形学、计算机视觉、智能信息处理、智能机器人、系统软件等,在ACM TOG, IEEE TVCG, IEEE PAMI, ACM SIGGRAPH, IEEE CVPR, IEEE ICRA, USENIX ATC等重要国际刊物上发表论文100余篇。
开发Jittor的主力,是该实验室梁盾、杨国烨、杨国炜、周文洋等一批博士生。
据梁盾透露,他们接下来的计划,是先围绕学界,重点发力。希望能成为国内以及世界上学术界最受欢迎,使用最多的框架,并对AI产业界产生积极的影响。
但想要走通这条路,并没有那么容易。TensorFlow和PyTorch已经成为了当前主流的深度学习框架,正在被全世界的研究者们采用。尤其是PyTorch,正在大面积抢占学术界。
其实从模型特性,以及设计理念来看,PyTorch可能是Jittor更直接的对标对象。
Jittor将如何发力?
在他们的规划中,接下来将组建开源社区,除了完善框架外,还会联合多所高校使用Jittor教授课程,以现有人员作为核心,壮大开发团队和用户,首要目标是服务更多研究人员。
据说,已经有多位高校教授,决定要在自己课堂上使用。
同时,另一个公开信息也值得关注:胡事民教授从2010年开始,就担任清华大学—腾讯联合实验室主任。在Jittor研发过程中,还得到了这一实验室支持。
所以这一框架是否会与腾讯展开合作?
目前研究团队没有给出直接明确的答复,但表示:非常希望能和更多的产业界的伙伴们联手推动Jittor的发展。
总之,打造AI框架本身已不易,开源之后更要接受各方直接检验。
现在,清华迈出了关键一步,虚的不多说,各位收好下方传送门,走过路过不要错过,都参与检验一下吧~
开源传送门
https://cg.cs.tsinghua.edu.cn/jittor/
作者系网易新闻·网易号“各有态度”签约作者
— 完 —
北京时间3月21日早10:30,两位轻舟智航顶级技术专家、前Waymo核心工程师将交流讨论现有无人车技术思路,提出无人车创新型技术思路及大规模智能仿真系统的具体应用及实践。戳二维码,备注“无人车”即可报名、加交流群与同好讨论交流无人车进展~
高能直播 | 无人车创新型技术思路及仿真系统应用讲解









