
作者简介:Mort,数据分析爱好者,擅长数据可视化,比较关注机器学习领域,希望能和业内朋友多学习交流。
目前整个世界同新冠肺炎的斗争仍在继续,从新冠肺炎爆发以来,很多人都提出了各种各样的模型来预测肺炎疫情的发展,其中比较常见的就是SIR模型。这是因为SIR是目前疾病防控领域最经典也是最常用的一个模型,而今天笔者就用图论来讲述一下SIR模型。
首先对SIR模型做一个简单的介绍,SIR全称就是Susceptible—Infected—Recovered,翻译过来就是易感—感染—康复,即易感人群Susceptible有α概率被某种疾病感染,成为感染人群Infected,而感染人群Infected又有β概率康复,成为康复人群Recovered。这个过程可以是一次或者是多次的,而且还衍生出不少类似的模型,比如SIS、SIRS和SI等。整个SIR过程可以用下图来描述。

图1. SIR模型示意图
而笔者这次用的是图论,也就是我们平常所说的网络分析来说明SIR模型,大概过程如下图所示。
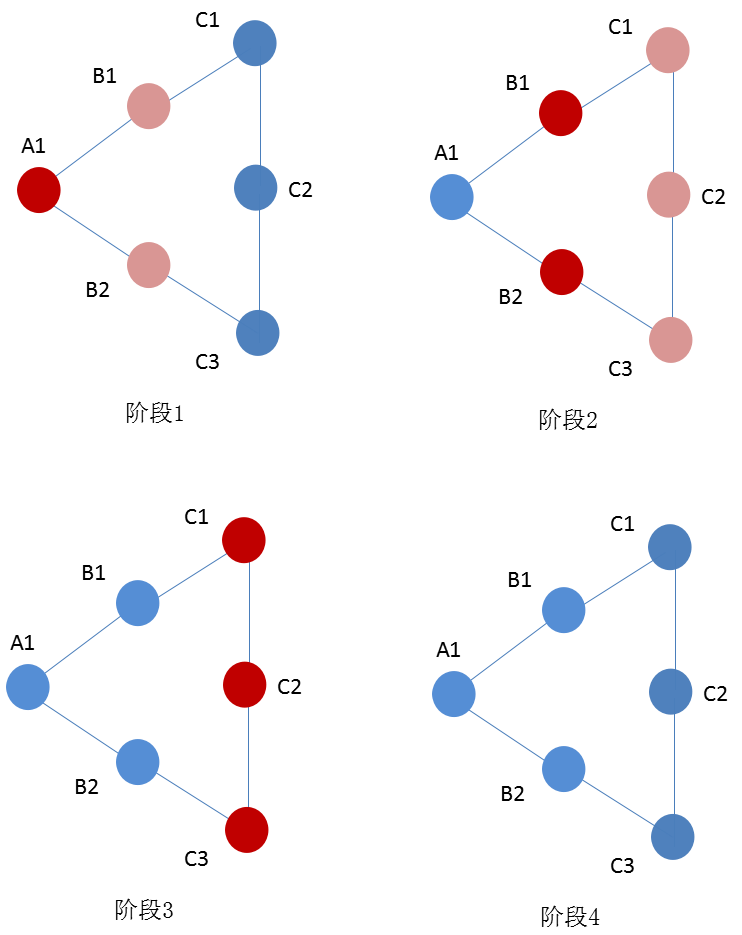
图2. SIR网络模型示意图
这个过程其实很简单,就是由少数人感染多数人,然后最终所有感染人群都康复的一个过程,这个模型简化了我们很多实际情况所遇到的部分问题,比如不考虑感染人群的死亡问题,不考虑感染人群的再感染等等。这次用到的图论方面的库是networkx,这是Python中最常用的图论分析的库。下面还是直接用代码来具体说明一下。
首先导入各种包。
import matplotlib.pyplot as plt
import numpy.random as rdm
import networkx as nx
接下来定义两个变量n和g。n是总人数,而nx.erdos_renyi_graph则是一种随机网络图,Erdos和Renyi是两位匈牙利数学家,他们的主要贡献就是建立了著名的E-R随机图理论(Random graph theory),这被公认为在数学上开创了复杂网络拓扑结构的系统性分析。而这个E-R图也是本文应用的基础。而nx.erdos_renyi_graph(n, 0.01)的意思就是以概率0.01来连接100个节点。这里100和0.01这两个数字笔者用的比较随意,大家可以根据自己的研究来任意设定相关数值,这里主要还是用于简单说明。然后是三个string类型的变量susceptible、
infected和recovered,分别代表“易感”、“感染”和“康复”人群。
n = 100
g = nx.erdos_renyi_graph(n, 0.01)
susceptible = 'S'
infected = 'I'
recovered = 'R'
接下来我们要定义几个函数。
def onset(g): #初始设置
for i in g.node.keys():
g.node[i]['state'] = susceptible
def infect_prop(g, proportion): #设置感染比例
for i in g.node.keys():
if(rdm.random() <= proportion):
g.node[i]['state'] = infected
def build_model(pInfect, pRecover): #模型构建
def model(g, i):
if g.node[i]['state'] == infected:
for m in g.neighbors(i):
if g.node[m]['state'] == susceptible:
if rdm.random() <= pInfect:
g.node[m]['state'] = infected
if
rdm.random() <= pRecover:
g.node[i]['state'] = recovered
return model
def model_run(g, model): #单次模型运行
for i in g.node.keys():
model(g, i)
def model_iter(g, model, iter): #多次模型循环
for i in range(iter):
model_run(g, model)
第一个函数onset,也就是刚开始的状态,在这里我们把每个节点的状态都设置为“S”,也就是易感的意思,这里我们假设所有人都属于易感人群中的。然后就开始有部分人群出现感染,而这个感染函数就是infect_prop,prop意思就是proportion,这个函数的意思就是感染比例,这里我们用到了numpy.random.random方法,也就是返回一个均匀分布,数值大小在0-1之间,不包含1,当rdm.random()<= proportion时,我们就让这样的人群变为感染人群,这样让感染人群更加均匀一些。第三个函数是build_model,是一个嵌套函数,有两个参数,pInfect和pRecover,分别代表感染概率和康复概率,而这里的g.neighbors(i)的意思是节点i的每个相邻的节点,而g是我们生成的一个图(graph),是一个class,后面会有说明。在这些感染人群中,当他们的相邻节点的状态是“susceptible”时,我们让这些节点(人群)以概率pInfect来进行感染;而在这些感染人群中,以pRecover的概率进行康复。这就是一个简单的感染—康复过程。而后面的两个函数model_run和model_iter则是将这个模型运行一次和多次,分别用来模拟一个循环和多个循环。
接下来就是画图。
fig, ax= plt.subplots(figsize=(12, 10))
ax.set_xticks([])
ax.set_yticks([])
pos = nx.spring_layout(g, k=0.2)
nx.draw_networkx_edges(g, pos
, alpha=0.5, width = 1)
nx.draw_networkx_nodes(g, pos, node_size=80)
plt.show()
首先设置图片的大小,并去掉坐标轴,然后设置网络图的位置,nx.spring_layout就是设置网络图的位置的方法,k是节点间的最佳距离,这个可以随意设置,值越大节点越分散,接下来绘制节点和连线,nx.draw_networkx_nodes(g, pos, node_size=80)用来绘制节点,pos就是刚才设置的位置参数,再设置一下节点的大小,而nx.draw_networkx_edges(g, pos, alpha=0.5, width = 1)用来绘制连线,同样要传入位置参数,再设置透明度和线宽。最后生成的图如下。

图3. 模型生成的网络图
networkx使用的绘图算法是随机的,同时我们使用的参数也是随机的,所以这个图每次生成的结果都不同,但大体相似,我们可以看到这里面已经有部分节点相连,疾病也就是通过他们开始传播。
最后就是计算感染率。
onset(g)
infect_prop(g, 0.05)
model = build_model(0.2, 0.8)
model_iter(g, model, 10)
infected = [ v for (v, attr) in g.nodes(data = True) if attr['state'] == recovered ]
infection_rate = len(infected)/n
print(infection_rate)
这当中onset(g)中的g就是前面我们用g = nx.erdos_renyi_graph(n, 0.01)生成的图,这是一个类的实例,infect_prop(g, 0.05)中的0.05就是设置人群初始感染率为0.05,model = build_model(0.2, 0.8)中的感染几率和康复几率分别设置为0.2和0.8,至于为何这么设置,主要是根据常用的“二八理论”,这个数字可以根据使用者的模拟情况随意设置,而model_iter(g, model, 10)中我们让这个模拟过程重复10次,最后计算出感染人数,并得出最终稳定的感染率infection_rate,因为这些参数不少都是随机的,所以得出的结果理论上每次都是不同的,笔者得出的结果从0.03到0.12不等,这个结果意义不大,主要还是理解模拟的方法。
赞 赏 作 者

Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。
扫码关注下方公众号后回复“预测”即可获取源码数据
 ▼ 点击成为社区注册会员 喜欢文章,点个在看
▼ 点击成为社区注册会员 喜欢文章,点个在看









