目录
- 从十年前的Tesla T10说起
- AI/深度学习系统的搭建步骤
- NVIDIA Data Science Stack:真的能一个命令解决部署?
- 验证:在JupyterLab中使用Python、CUDA、TensorFlow等
- 硬件选择建议
从十年前的Tesla T10说起

早期主动散热的Tesla,怎么看怎么像Quadro,除了没有显示输出。如今NVIDIA也并不反对Quadro用于数据中心,RTX 6000和8000甚至还推出了被动散热的版本。被限制的只有“利润较低”的GeForce…
上面这两块GPU卡有多少朋友能认出来?它们是十年前的NVIDIA Tesla C1060,代号“T10”,不过和《NVIDIA Tesla T10变身GeForce?云游戏能接盘矿卡市场吗》一文中的新T10实在没什么关系。
C1060是Tesla家族的第二款产品,之前还有一款是C870,它们都还是涡轮风扇主动散热的。所以大家可以看到上图中的2块卡是装在一台塔式工作站中,为了显示输出还添加了一块Quadro FX 380。同期NV也开始推动被动散热用于服务器上的M1060——并逐渐发展壮大为今天人们所熟悉的Tesla产品线。
那几年,CUDA也是刚开始崭露头角。还记得有一次客户给我打电话咨询这个“万亿次浮点预算”的方案(C1060的理论单精度性能为1T FLOPS),大有马上就要掏钱的势头。当时我显然没有老黄那种自信,还是建议用户先测试一下CUDA,毕竟和传统CPU的软件编程不同。可能是网络没今天发达吧,这客户居然跑过来找我拷贝Tesla的驱动光盘,当时我正在外面另一个客户那里干活呢。
我还记得,当年已经开始有国内排名靠前的HPC超算四处咨询Tesla的价格,几年之后某行业被禁售了… 另一方面,当时我并没想到CUDA、以及后来开始流行的AI、深度学习会把GPU计算推到如今的高度。
AI/深度学习系统的搭建步骤
有位同事反映过几次,说我写的文章插入与主题关系不密切的内容有点多(比较散),所以这就赶紧切回正题:)
前面是什么让我想起十年前呢?记得当初测试CUDA环境在Windows里装一下就好了,然后Matlab等支持GPU的应用就可以运行了。如今基于GPU的人工智能、深度学习系统更青睐开源的Linux平台,软件环境的部署要相对麻烦一些,特别是像我这样平时主要摆弄硬件的人,总是希望有更简单的办法。当然,我也看过网上一些高人朋友总结的操作经验,也自己动手尝试过。下面大致列出几个主要步骤:
1、安装Linux,Ubuntu或者RedHat/CentOS;
2、Linux下安装NV显卡/GPU驱动(含准备工作),在Ubuntu下就有3种方法,下文中我会推荐其中最方便的;
3、CUDA安装——除了独立安装,还有一种方式是显卡驱动随CUDA一同安装;
4、安装深度学习环境:这部分首先是NVIDIA的cuDNN基础神经网络SDK,然后才是依赖它的TensorFlow、Caffe、MXNet、PyTorch等深度学习框架,其间还要安装的Python和pip等。
可能有朋友说用Docker容器会简单一些。没错,NVIDIA网站提供了一些常用的容器可供下载,这样在GPU驱动之后的部署就可以省去了?但别忘了Docker对有些人(比如我)来说也需要学习,特别是想用的好一点、乃至于定制部署自己的容器。
NVIDIA Data Science Stack:真的能一个命令解决部署?
最近我了解到NV的Data Science Stack(数据科学套件,https://github.com/NVIDIA/data-science-stack),并按照《Dell Precision Data Science Workstation Guided Install Edition》手册的操作指导进行了测试,下面把步骤和收获分享给大家:
1、选择机型配置(略,关于硬件的讨论我想放在最后)
本次测试使用了Dell Precision 7740移动工作站(Quadro RTX 5000 GPU),以及Precision7920 Tower塔式工作站(Quadro P4000 GPU)。
2、安装系统前准备。这一步主要是关闭BIOS中的“Secure Boot”,这是因为影响到Linux Kernel
的更新,基本上Linux安装NV显卡驱动都是要改这个的。
3、提升你的性能——设置和优化(可选),这部分做的是2方面事情:
3.1 关闭闲置使用电源管理设置
/usr/bin/gsettings setorg.gnome.settings-daemon.plugins.power sleepinactive-ac-timeout 0
3.2 关闭休眠设置
sudo systemctl maskhibernate.target
3.3 删除交换文件
sudo swapon –show
sudo swapoff -v /swapfile
sudo sed -i ‘/^\/swapfile/d’/etc/fstab
sudo rm /swapfile
关闭虚拟内存(页面文件)的理由,我就不在这里展开了。
4、安装NVIDIA Data Science Stack v2.2.x
首先是Linux发行版的选择,NV数据科学套件支持Ubuntu 18.04.x和RedHat Enterprise Linux 7.5+ or 8.0+ (需要license)。RHEL是购买商业版OS不错的选择,不过由于我手头恰好没有Lincense,无法使用红帽订阅来更新,所以本次测试使用Ubuntu。
注:由于Dell 7740移动工作站带的IntelAX200 WiFi6无线网卡需要Linux5.1+内核才有驱动,因此我安装了最新的5.3内核的Ubuntu 18.04.4。
尽管这个版本的NV Data Science Stack宣称在Ubuntu下能够包含GPU驱动的安装,但经过我的测试还是建议手动先装好。(也可能是我水平不够,坐等高人拍砖)
sudo apt update
sudo apt upgrade
sudo apt install nvidia-driver-430
包扩系统更新在内,准备工作总共就这3条在线命令,不算复杂吧?我也试过用NV官网下载的.sh驱动文件安装,但为了解决相关依赖还是步骤繁琐了点。所以上面推荐最简单的办法。
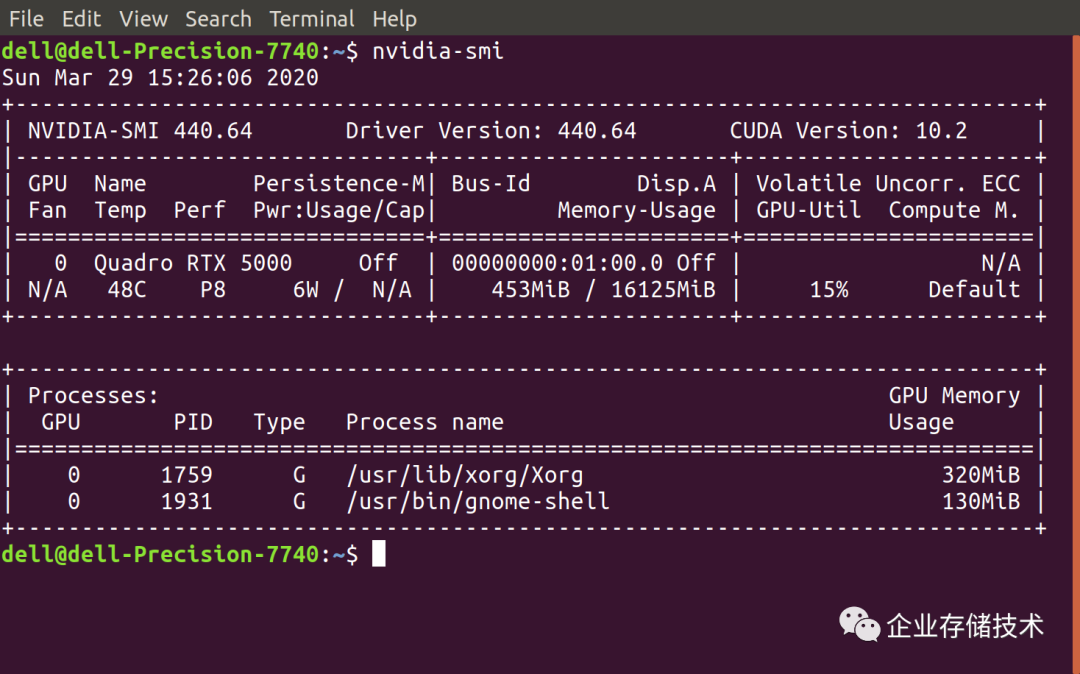
运行nvidia-smi出现上面这样的输出,就代表显卡驱动装好了。大家都知道GeForce比Quadro的性价比好,但如果用户需要像RTX 5000这样16GB显存的笔记本,还真没有更多的选择。
然后就是从github上下载data-science-stack-2.2.2.tar.gz(很小),并解压缩:
tar zxvfdata-science-stack-2.2.2.tar.gz
cd data-science-stack-2.2.2
再往后的命令行操作,就真的是只使用一个脚本了。
安装系统环境、设置用户:
./data-science-stack setup-system
./data-science-stacksetup-user
Linux系统中需要的包、Docker环境会在上面的操作中完成,如有英文提示重启或者Log out / Log in,请按要求执行。
接下来是选择构建容器,或者原生的数据科学开发环境:
./data-science-stackbuild-container
./data-science-stackbuild-conda-env
Conda 是一个开源的软件包管理系统和环境管理系统。上述2种部署我都测试过,无论使用容器与否,下载安装的组件其实大多是相同的,比如下面我随便挑几个比较常见的:
pytorch-1.4.0
cudnn 7.6.0
mkl-2020.0
tensorflow-base-1.14
cudatoolkit-10.1.243
ffmpeg-4.1.3
……
最后的验证,就是运行容器化环境或者Conda环境,分别使用2个不同的参数:
./data-science-stackrun-container
./data-science-stack run-jupyter
验证:在JupyterLab中使用Python、CUDA、TensorFlow等
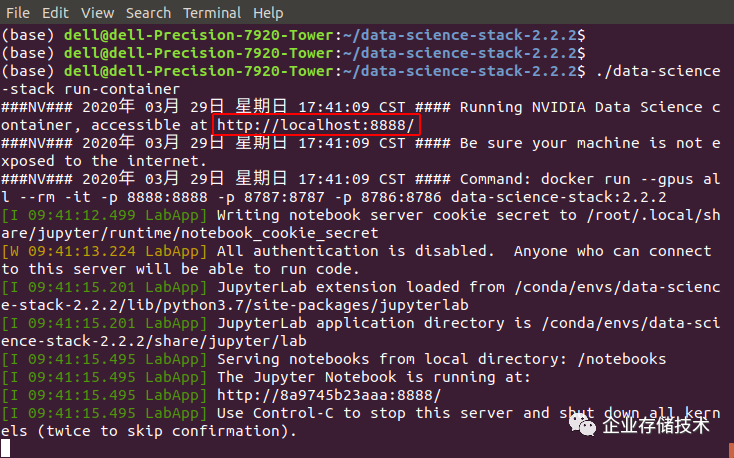
这里我以使用容器为例,跑起来之后看提示,用浏览器访问localhost:8888。其实无论是否选择容器化部署,最终用户的使用界面都是JupyterLab这个基于网页的用于交互计算的应用程序。
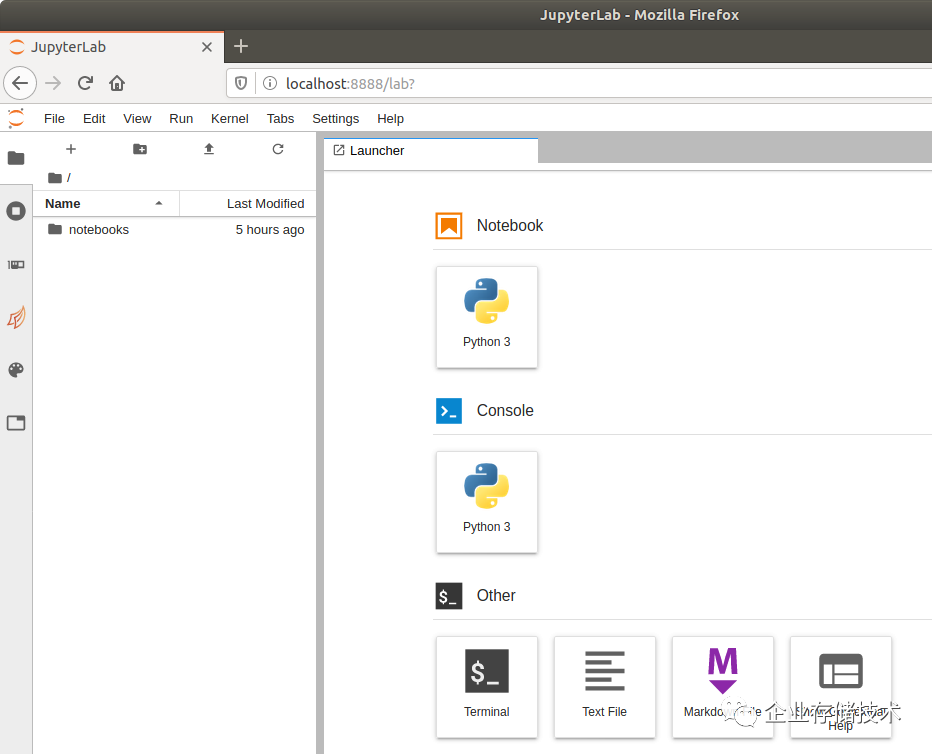
如上图,JupyterLab显然是为编程人员服务的。我先开一个Python 3的Console看看。
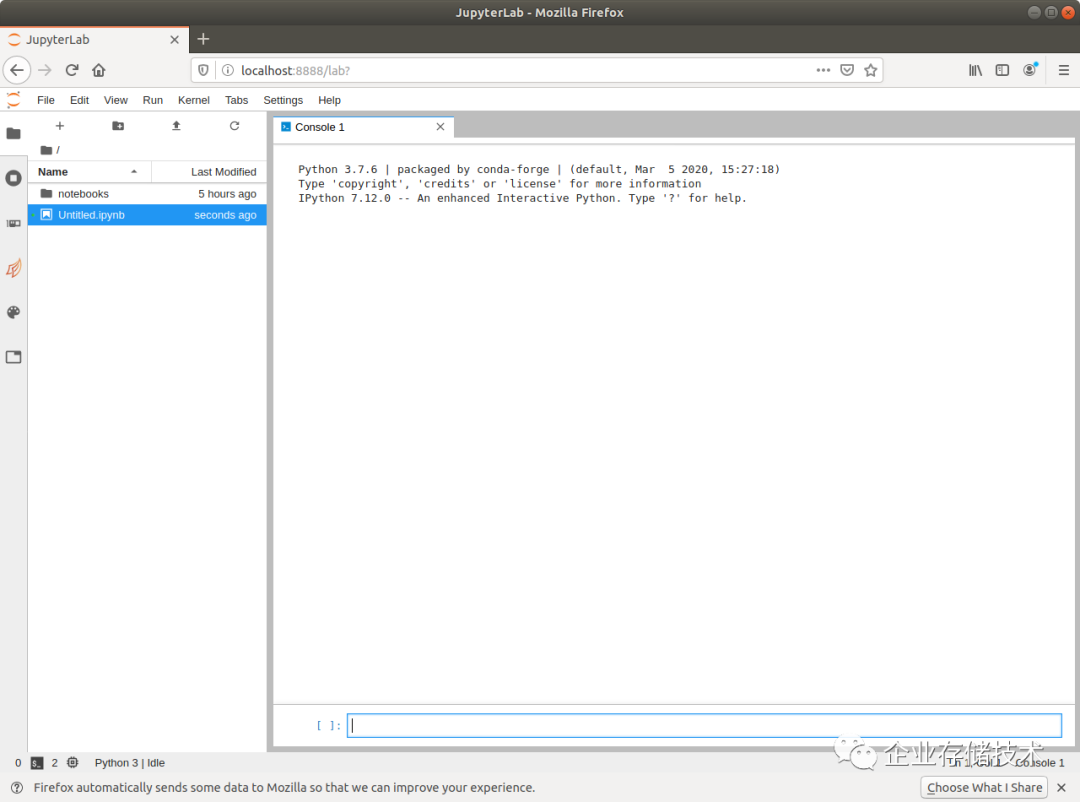
在下面的输入框里就可以敲代码了,上面显示的Python版本是3.7.6
,常用的2.7有没有呢?
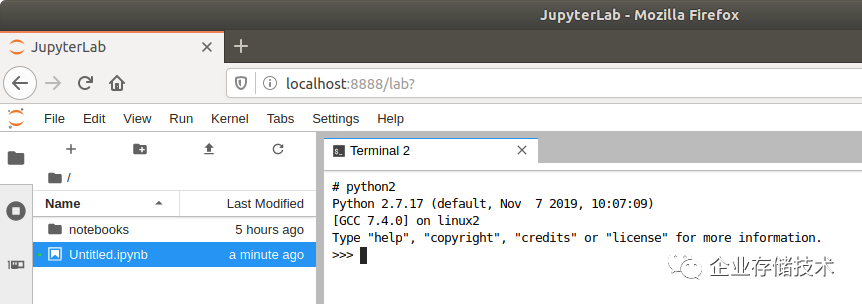
我开了一个终端,验证下Python2.7是必须存在的。
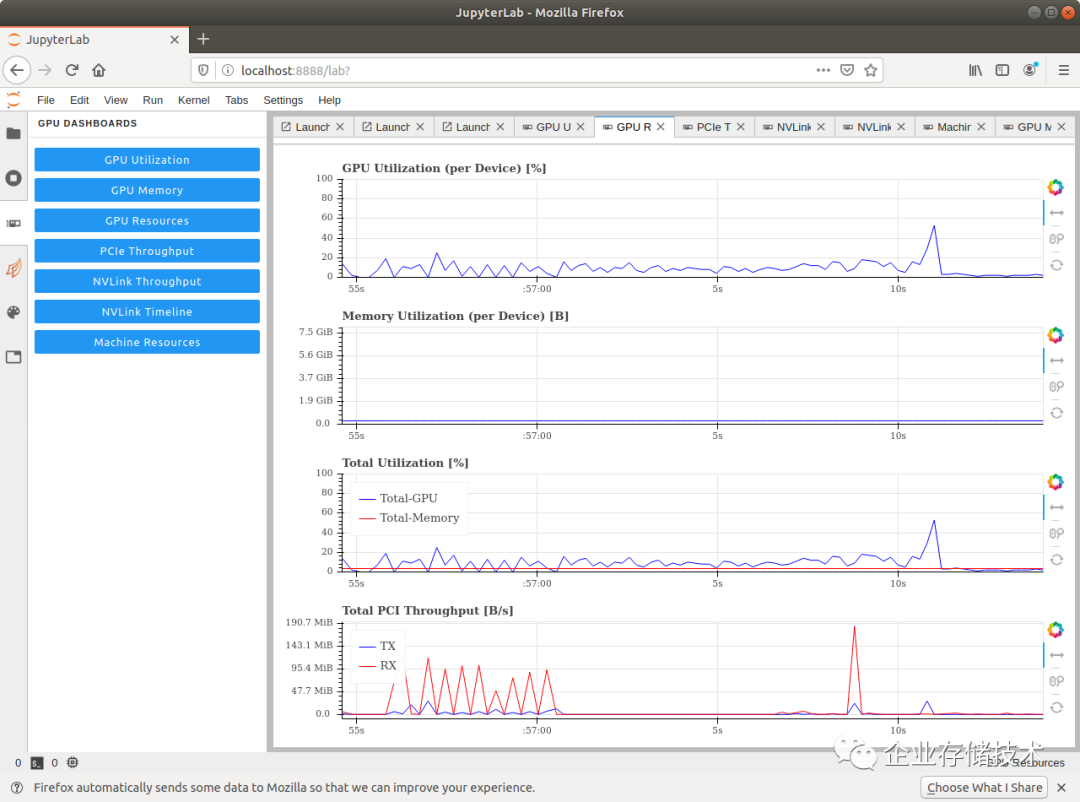
JupyterLab里的图形化GPUDASHBOARDS,可以选择从不同方面监控GPU的资源使用情况。
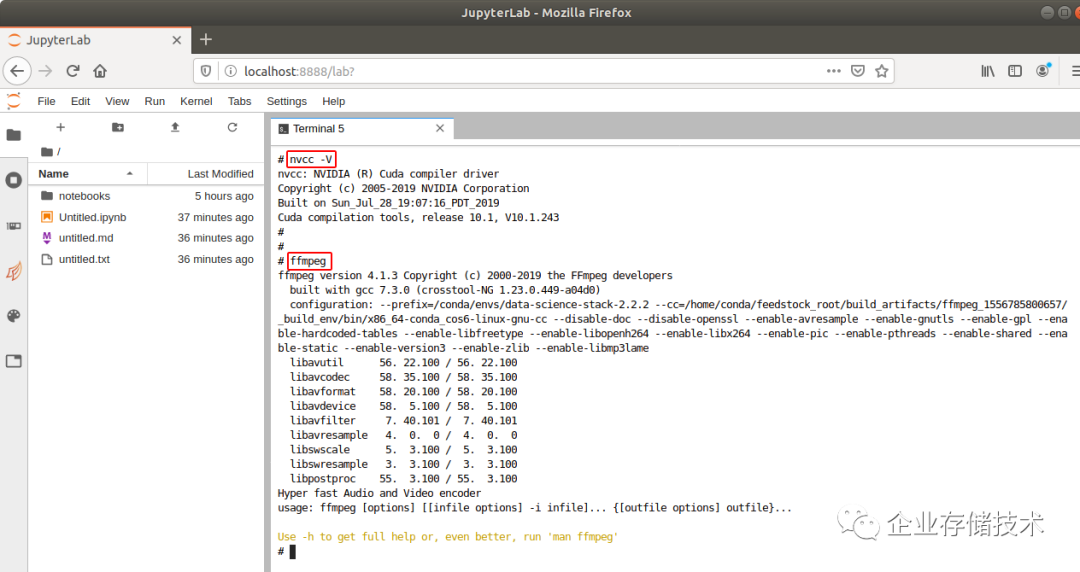
我又验证了一下CUDA环境,是V10.1.243版本。ffmpeg也是正常的。
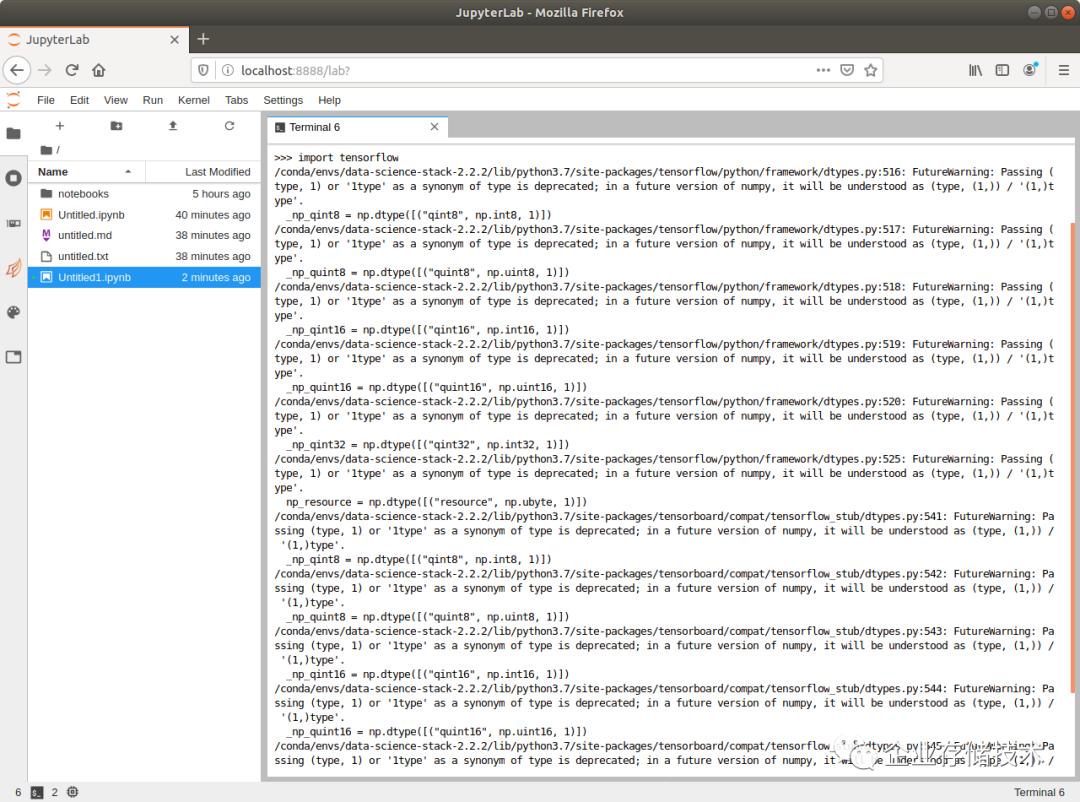
最后试了下在Python里导入TensorFlow深度学习框架,上图为输出。PyTorch等其它的框架也可以按照同样的方式导入。
结果表明,从CUDA到一系列深度学习框架等的安装部署,以及JupyterLab的运行都只用data-science-stack这一个脚本就可以实现。哪怕使用容器,也可以在不会敲一条Docker命令的情况下就run起来。
硬件选择建议
结尾处简单聊几句,感兴趣的朋友可以看看。
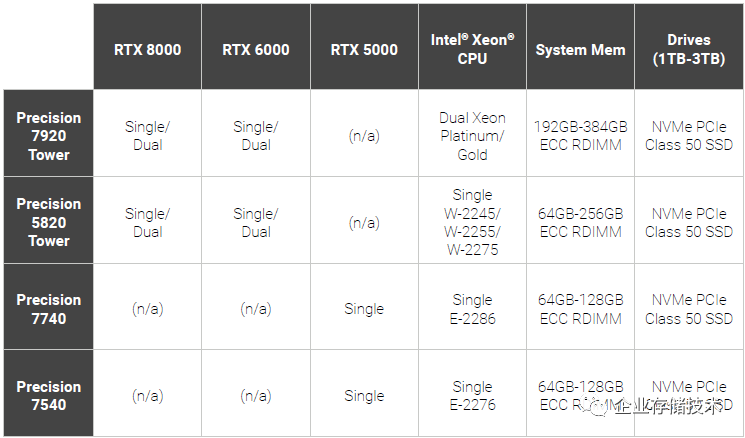
上表是出现在Dell这份安装文档中的,推荐的配置比较高,比如塔式工作站上只列出了Quadro RTX6000和8000选项?除了性能较高、显存更大之外,选择认证这些配置有没有NV想赚更多钱的原因呢?
下面我们再看一下NVIDIA Data Science Stack的硬件要求:
NVIDIA GPU - Pascal, Volta, orTuring family GPU(s) including:
不过还好,Quadro P系列以及GeForce 10xx和20xx也在支持的范围内,对性价比要求高的用户,在塔式工作站上配1-3片GeForce RTX如何?商用产品的支持服务和设计可靠性会更好,无论Quadro、Tesla(适用于服务器)还是一款优秀的(图形)工作站。

参考资料:
https://www.delltechnologies.com/en-us/ai-technologies/index.htm
https://github.com/NVIDIA/data-science-stack
注:本文只代表作者个人观点,与任何组织机构无关,如有错误和不足之处欢迎在留言中批评指正。进一步交流技术,可以加我的微信/QQ:490834312。如果您想在这个公众号上分享自己的技术干货,也欢迎联系我:)
尊重知识,转载时请保留全文,并包括本行及如下二维码。感谢您的阅读和支持!《企业存储技术》微信公众号:HL_Storage

长按二维码可直接识别关注
历史文章汇总:http://chuansong.me/account/huangliang_storage






