2019 年 1 月到 2019 年 7 月滴滴 ElasticSearch 团队(Arius)将维护国内的 30 多个 ES 集群,2000 多个 ES 节点,4PB 的数据,从 2.3.3 跨大版本无缝升级到 6.6.1。
在对用户查询写入基本零影响和改动的前提下,解决了 ES 跨大版本协议不兼容、Mapping 不兼容等业内难题,整个过程对绝大部分用户完全透明。
团队同学经过 7 个月的奋斗,完成 ES 版本升级的过程中,也完成了滴滴 ElasticSearch 平台的架构升级。
取得了单机查询性能提升 40%,整体集群 CPU 下降 10%,写入 TPS 提升 30%,归还物理机近 400 台,成本节约 80W /月、0 故障的成绩,并在引擎上向社区贡献了 4 个 PR,一位同学升级为 ES Contributor。
如此大规模的跨大版本升级,在 ES 业内也很少见,从开始准备到实际执行,遇到了很多困难,踩了一些坑,期间也有很多我们的思考。
为此我们准备本期的总结和分享,主要从以下几个方面展开:
背景:推石头的西西弗斯
困难:拔剑四顾心茫然
思考:天生我材必有用
实战:百战沙场碎铁衣
收益:长风破浪会有时
展望:直挂云帆济沧海
滴滴 ElasticSearch 团队从 2016 年开始建设 ElasticSearch 平台,在 2016 年 6 月份的时候开始对外提供服务,当时选择了 ElasticSearch 最新的 2.3 版本。
如今三年过去了,ElasticSearch 生态经历了飞速的增长,Elastic 公司完成了上市,ElasticSearch 在 db-engines 的分数从 88 上涨到 148,排名从 11 名上升到第 7 名。
这期间 ES 发布了 3 个大版本,几十个中版本,而最近 ElasticSearch 已经发布了 7.x 版本。
在这三年中滴滴 Elasticsearch 平台基于 ElasticSearch 推出了日志检索、MySQL 实时数据库快照、分布式文档数据库、搜索引擎等四大服务,四大业务均快速发展。
目前滴滴 ElasticSearch 平台服务了集团里面 1200 个应用,其中:订单、客服、金融、把脉、新政等业务核心实时场景也运行在 Elasticsearch 之上,运维 ES 集群 30+,写入 TPS 峰值到达 1500W,查询 QPS 达到 2W。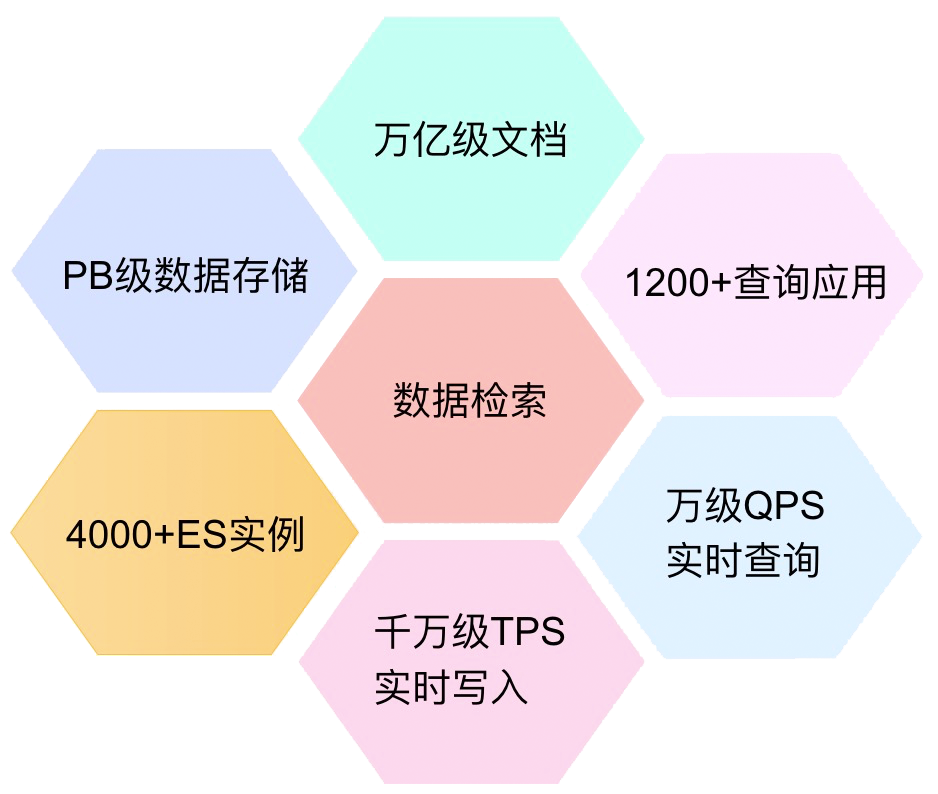
业务的快速发展既是滴滴 ElasticSearch 团队工作的肯定,但随之而来也有巨大的挑战和压力,其中版本过低是未来 ElasticSearch 平台发展最大制约因素,其中主要有以下几点。
①社区不再维护老版本:ElasticSearch 2.3.3 版本过于陈旧,ES 社区早已不再进行维护,在 2.x 上遇到的问题社区不解决,提交的 issue 也不处理,提交代码也不被接收。
基于 2.3.3 我们也解决了很多 ES 自身的问题,如:Master 更新元数据超时导致内存泄露、TCP 协议字段溢出等。
由于无法和社区互动,团队同学的价值也得不到社区的认可,长此以往只会和 ES 生态越来越远,我们在 ES 技术圈中的声音也会越来越弱。
②新版本特性很难被使用:最近 3 年是 ES 生态大发展的 3 年,ES 自身在功能、性能上都有非常大提升。
如:默认使用 BM25 评分算法,效果更佳;lucene docvalues 稀疏区域改进,更节约磁盘空间;新增 Frozen indices 能力,可以显著降低 ES 内存开销。
很多特性也非常适合 ElasticSearch 平台的场景,但是版本差距过大一直制约着我们,无法享受技术进步的红利。
一边是业务快速发展要求更丰富的功能、更强大的性能、更低的成本、更稳定的服务;一边离最新的业内技术越来越远,团队价值越来越弱,逐渐沦为一支只能做业务的伪引擎团队,整个团队的现状就如同推石头的西西弗斯。要么我们迎难而上,克服困难,一口气把整个集群升级到最新的版本,把石头推过山顶,再轻装前行;要么就是继续独自勉力支撑,在业务和引擎的双重压力下蹒跚而行。
滴滴 ElasticSearch 团队最终选择对滴滴 ElasticSearch 平台进行重构并将维护的所有 ES 集群升级到最新版本。
理想很丰满,现实很骨感,下决心很容易,然而实际执行很困难:2.3.3 和 6.6.1 协议不兼容啊,6.6.1 都不支持 TCP 协议了,那些通过 TCP 查的用户怎么办,让他们一个一个改代码,那要改到什么时候?
2.3.3 和 6.6.1 有些返回的字段都不一样了,有些查询语法也不兼容,怎么做到对用户的透明,还是直接强迫用户接受改变?
2.3.3 和 6.6.1 lucene 文件格式都不一样,没办法原地直接升级,要再搞个集群全部双写一遍。
2.3.3 和 6.6.1 的 Mapping 格式不统一,6.6.1 不支持多 type,现有的那些数据搬迁都没办法搬。
滴滴 ElasticSearch 平台现在不支持索引多版本同时查询,用户查询习惯也千奇百怪,很多带*查询你根本控制不了。
用户那么多,使用差异很大,怎么和用户进行沟通和宣导,怎么屏蔽用户影响和管理用于预期?
就算是要搬迁升级,哪里去找那么多机器,现在还要机房裁撤,还要往外拿机器。
几十个集群,几千个节点都要部署、搭建、重启,还要腾挪上千台机器。慢点搞,这得搞到什么时候,快点搞,万一出问题怎么办?
就算是双写升级了,怎么知道中间有没有问题,数据有没有丢失,用户的查询是不是一致的,功能和性能有没有达到预期,这个怎么验证?
这么多数据,这么多人在用,这么点资源,业务稳定压力又大,估计今年一年都搞不完。
…………
在刚开始决定进行跨版本升级之后,我们面临的问题就扑面而来,其中任何一条不解决,都会极大的阻碍升级的进程。
在起步阶段有很多问题杂糅在一起,需要理清楚每个问题的重要性、紧急程度、影响层面、相互依赖关系,通过分析归纳我们将其总结为四大问题域:
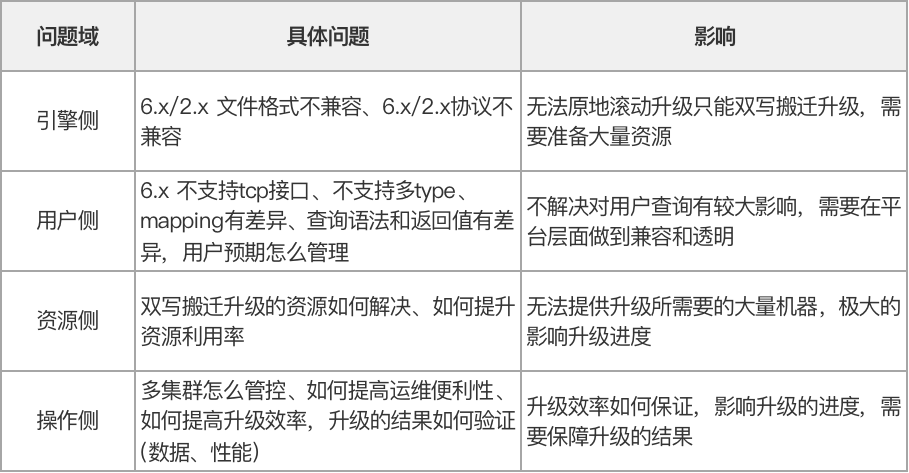
在对问题域进行归总之后,我们讨论了具体的实施方案和步骤,将其归纳以下四个可以实际推进的环节:
首先进行架构升级:解决引擎侧 2.x/6.x 的不兼容问题,所有的协议、查询语法、Mapping 等不兼容处理在平台侧进行处理。
同时我们开发了一个 ES java SDK 用来解决 6.x 不支持 TCP 接口的问题,使用方式和原有的 es java client 完全一致,用户只要修改 pom 即可。
具体包括:Arius 平台多版本支持、Gateway 的多版本兼容、用户 SDK 开发、AMS 数据采集等,具体见后续详细说明。
其次解决运维问题:解决运维操作过程中多集群搭建、部署、重启的管控问题,提升操作的便利性,提升升级的操作效率,具体见后续详细说明。
再次解决资源问题:解决搬迁升级所需要的大量机器资源问题,为大量集群升级做充足准备,同时还要满足机房裁撤归还机器的要求。
具体包括:索引存储周期优化、冷热数据分离、Mapping 优化、fastIndex 等,具体见后续详细说明。
最后开始实际推进:在做好前期的所有准备工作之后,开始实际推进升级过程。具体包括:性能压测、资源评估、批量双写、查询回放,其中还有一些意想不到的采坑和填坑的过程,具体见后续详细说明。
在理清了整个升级过程中的各个环节的依赖关系、资源消耗、瓶颈点之后,针对架构、资源、实操等三个方面的问题,我们都设计了对应的解决方案,主要如下:

①滴滴 ElasticSearch 平台 ES 多版本支持的架构改造
首先我们在滴滴 ElasticSearch 平台上完成了 ES 多版本支持的架构升级,其中重点有:
Arius Gateway 对跨版本查询差异的兼容,以及多集群下索引跨高低版本集群访问,使得在升级过程中对用户查询结果透明。
Elasticsearch-didi-interanl-client SDK 开发,对用户屏蔽 ES TCP/HTTP 查询差异,解决 ES 6.x 版本不支持 TCP 接口的问题,原有 2.x 的用户只要修改一行 pom 就可以切换到高版本访问。
滴滴 ElasticSearch 平台架构梳理以及 Arius admin 多版本支持。
②基于弹性云的 ES 多集群管控方案
目前滴滴 ElasticSearch 团队运维 30 多个 ES 集群,5000+ 的 ES 节点,集群规模大,场景复杂,运维管控成本比较高。
为此我们设计开发了 ECM(ElasticSearch Cluster Manager)系统用于 ES 集群的部署、重启、扩容、配置管控等一系列操作。
并且我们 80% 的 ES 节点运行在弹性云上,结合弹性云灵活高效的特点,使得我们在进行搬迁升级的过程更加高效。
③ES 服务元数据体系建设
我们构建了一套 AMS(Arius MetaData Service)服务,用于采集和分析 ES 所有集群、节点、索引的各种数据。
包括:容量信息(集群、节点、模板、索引、租户)、TPS/QPS 信息(集群、节点、模板、索引、租户)、运行信息、查询语句、查询模板信息、查询结果和命中率的分析信息等等。
在这些基础的指标数据基础上,我们构建了全面的 ES 运行指标系统,可以全面的了解和监控集群、节点、索引、租户级别的运行信息。
详尽的数据为后续的 ES 的成本优化提供了基础,具体见 —— 基于数据驱动的 ES 分级存储体系,分级存储体系的构建使得我们构建了一套体系化的ES成本节约的系统。
详尽的数据为后续升级时做查询的流量回放对比提供了基础,具体见——基于 ES 服务元数据的查询流量回放对比系统,使得我们在升级过程中可以快速验证升级结果,提升升级效率和稳定性。
同时 AMS 还对数据的可靠性负责,保证产生的数据是及时并且准确的,这样依赖 AMS 的数据分析服务。
如:分级存储、容量规划、回放系统、成本账单、集群健康检查、索引健康分等,只用专注自身的逻辑的实现即可。
在解决架构和兼容性问题之后,我们已经有信心将一个集群在线升级到新版本。
然而由于版本跨度太大无法在原集群上直接进行滚动升级,必须要进行数据双写的搬迁升级,这样升级所需要的 buff 资源就成为制约整个升级进度最重要的因素,因此接下来我们把精力放在节省资源提高资源利用率上。
通过内外挖潜和技术改造,不仅支持了版本升级所需要的机器资源(高峰时 3 个集群同时升级),最终还归还了近 400 台机器,节约成本 80W+ /月。
①基于数据驱动的 ES 分级存储体系
基于 AMS 对应索引的大小、数据量、查询量、查询条件、查询时间、返回结果的统计和分析,我们能精确的分析出来每个索引被使用的场景以及被查询的方式。
如:索引的高频查询时间区间、索引被检索的字段等,在数据分析基础上我们针对每个索引进行了 Mapping 优化、存储周期优化、冷热数据存储优化。
在不影响用户使用需求的前提下,累计节省数据 1PB,搬迁冷数据 700TB,不仅保障了升级过程中有充足的 buff 机器,还归还了近 400 台物理机,节省成本 70W+ /月。
②ES FastIndex 离线数据导入体系
ES FastIndex 的初衷是为了解决集团标签系统的离线导入的效率和资源问题,集团标签系统每天有 30 多 TB 的数据需要在短时间内同步到 ES 中,否则将会影响当天的业务结果,之前方案为了满足效率采用了大量的机器资源。
采用基于 Hadoop 的 ES fastIndex 离线数据导入系统之后,同样的数据导入时间由原来的 8 个小时下降到 2 个小时。
机器成本由原来的 40 台物理机 (ES 27 台、Kafka 3 台、Dsink 10 台) 下降到 30 台弹性云节点(10 台物理机),单单在标签场景就节约成本 7W+ 每月。
③基于资源 Quota 管控的 ES 集群容量规划方案
提升 ES 集群资源使用率也是滴滴 ElasticSearch 团队一直面临和致力于解决的问题。
滴滴 ElasticSearch 团队维护的 ES 机器总容量将近 5PB,提升 10% 的资源使用率即可节约 500TB 的空间,或者用于归还机器,或者用于服务新的需求。
当前 ES 集群整体磁盘使用率在 50% 左右,高峰期曾经达到 60%,日志集群磁盘使用率达到 69.5% (2019.05.01),但是这个时候集群资源非常不均,磁盘告警也很严重,运维压力非常大,偶尔还会出现丢数据的问题。
为此我们在原有的 ES 机器容量规划算法上,加入了资源 Qutoa 管控,并深入引擎,在引擎层面完善 ES 节点的容量规划和资源均匀,期望将 ES 集群的磁盘整体使用率再提升 10%,日均达到 60%,高峰达到 70%,并且没有磁盘告警和稳定性问题。
在前期准备工作都完成之后,集群升级就成为一个按部就班的过程,虽然期间也遇到了一些意想不到的情况,踩了一些坑,但整体的过程还是进行的比较顺利。
①基于 ES 服务元数据的查询流量回放对比系统
在前期构建的 AMS(Arius Meta Service)系统上,我们对用户查询条件、查询结果进行记录和分析。
在双写搬迁升级过程中,我们将用户的查询条件分别在高低版本的集群上进行回放,将查询返回的结果、性能参数进行对比分析。
只有对比一致,并且性能无太大差异的情况下,我们才认为升级有效,这样做到心中有底。
②基于 ECM 的 ES 多集群升级过程
由于需要进行双写搬迁升级,在实际的升级过程中,需要密集的进行集群搭建、搬迁、重启等操作,得益于 ECM 的集群管控能力,弹性云灵活的特性,我们和运维同学密切配合才能在短时间内完成多个集群的升级工作。
③ES 新版本特性以及升级性能分析
ES 6.6.1 提供了很多新的特性,在查询写入性能上也有很大的提升,我们升级完成的一些案列也得到了验证,我们会这些特性和性能提升进行一个详细的分析并分享给大家。
④ES 版本升级采坑分析
在升级的过程中我们也踩了一些坑,如:高版本 SDK 堆外内存无限制使用导致 OOM 的问题,我们把遇到的问题都详细记录下来进行并分享给大家。
经过近半年的开发和重构,在将国内集群升级到高版本的过程中,我们也在架构、产品、成本、性能、特性、自身能力上都有了很大的提升。
重构之后整个滴滴 ElasticSearch 平台的服务体系变得更清晰,主要收敛为四大块应用:
Gateway 负责查询写入请求的接入,用户的限流、权限校验、版本兼容在此完成。
ECM 负责所有集群的管控,集群搭建、升级、重启、集群级别监控和运维分析在此完成。
AMS 负责所有集群、节点、索引的运行时信息采集与分析,保障数据质量,并支持其他数据分析应用,分级存储、索引健康分、集群健康检查、查询回放等在此完成。
Arius Admin 负责索引、权限、资源管控等核心能力。依赖 Admin 的核心能力以及 AMS 的数据采集能力,还提供了容量规划和智能告警两个设计良好并且可插拔的扩展服务。
四个应用完成功能抽象、依赖解耦和服务化改造,相比之前下线了 arius-watch、arius-dsl、arius-tools、arius-monitor、arius-mark 等五个小应用,重构之后整体开发效率和可运维性得到了很大的提高。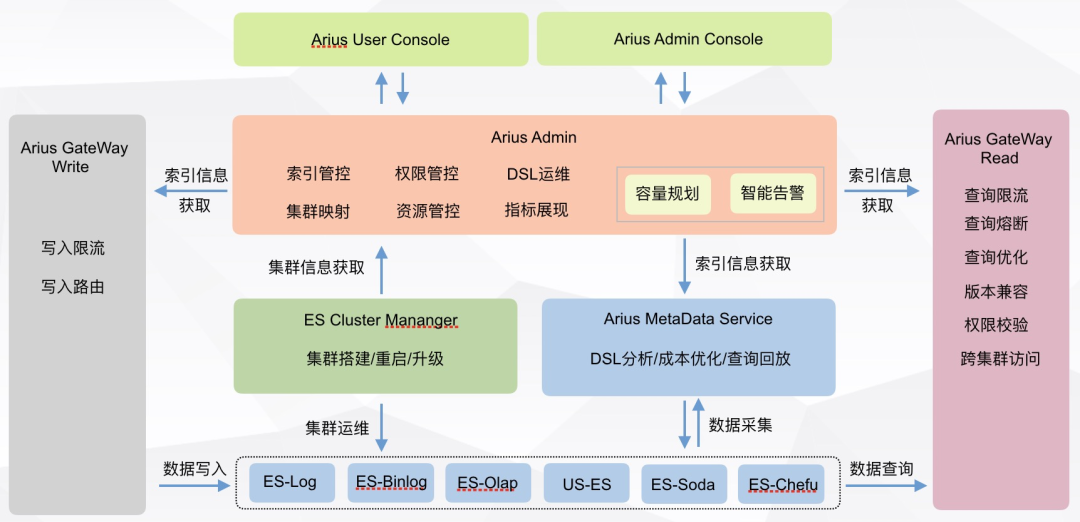
我们基于 ES 6.5.1 版本,完全重构了滴滴 ElasticSearch 用户控制台,其中将用户的一些高频操作,如:Mapping 设置/变更、数据清理、索引扩容缩容、索引转让、成本账单等开放给用户,提升用户的自助操作性。
未来我们还会对滴滴 ElasticSearch 用户控制台中的 Kibana 升级到最新版本并进行定制化开发,提供更丰富和更强大的功能给用户使用。
之前滴滴 ElasticSearch 平台有一套基于索引创建规则的容量规划算法,相比完全没有规划,老版容量规划算法可以将整体的集群资源使用率由 30% 提升到 50% 左右。
但是也存在着一些问题,如:资源分布不均、热点无法快速发现、动态自适应能力低、规划算法抽象不够无法在索引集群生效、运维便利性差。
下图展现了一个日志集群新老容量规划的磁盘使用率对比,上线新的容量规划之后,集群资源会向着两个方向发展:
经过一系列的存储优化和资源使用率改造的完成,在满足集群升级和业务需要增长的基础上,国内 ES 的资源成本从 2019 年 2 月的 339w 下降到 2019 年 6 月的 259w,机器数也从 1658 台下降到 1321 台。
随着国内集群升级逐渐全部完成,Ceph 冷存的完善,还会逐步归还更多的机器,滴滴 ElasticSearch 平台的使用成本也会一步一步下降,在定价上我们也会考虑进一步的进行降价。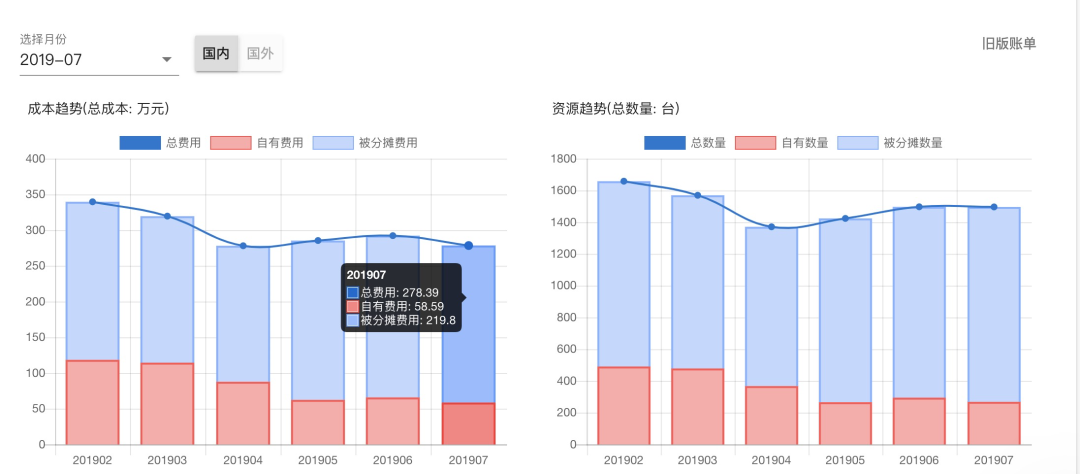
新版本升级之后带来的性能主要体现在以下两点:
①查询性能提升
下图是客服订单列表查询语句升级前后的对比,50 分位耗时从 300ms 下降到 50ms。99 分位从 600ms 下降到 300ms。
性能提升的详细分析见:ES 新版本特性以及升级性能分析。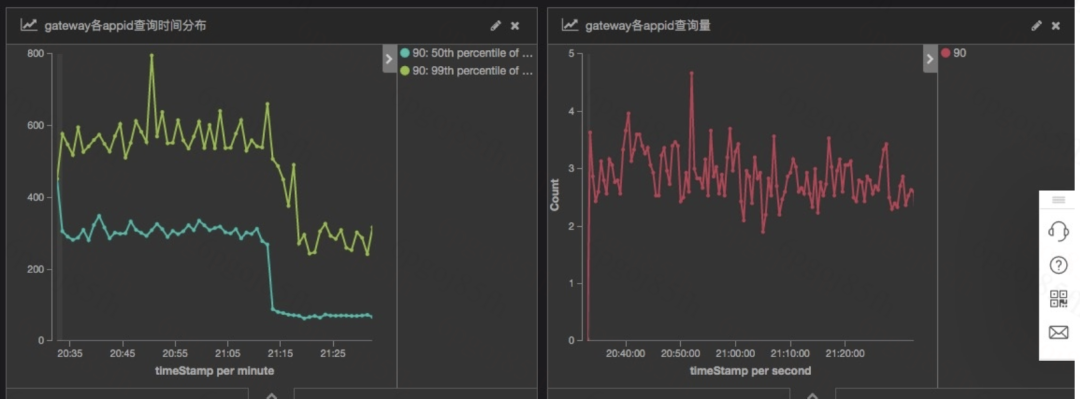
②集群写入性能提升
升级到高版本只会,ES 6.6.1 集群相对于 ES 2.3.3 集群同等资源消耗下,整个集群的写入能力提升了 30%。
如下图日志集群的写入 TPS 前后对比,集群写入能力从 240w/s 提升到320w/s。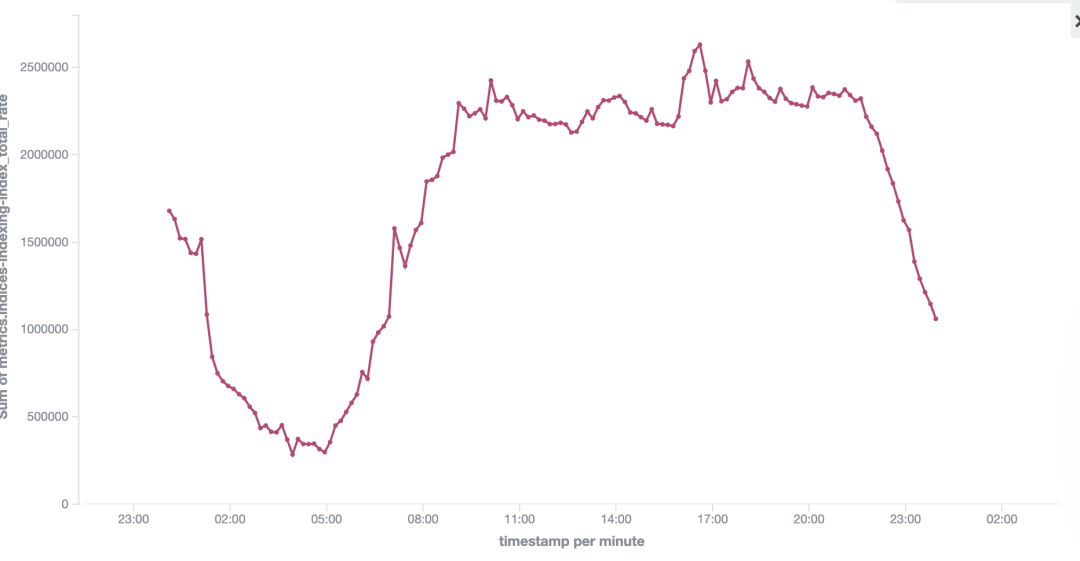
至此,滴滴 ElasticSearch 团队已经完成了国内全部日志集群、90% 的 vip 集群的升级,整个滴滴 ElasticSearch 平台的架构也得以重构和升级,从而在 ES 引擎层面也有了更大的发展空间。
未来我们将更加专注于引擎建设,更多的从根本上解决目前遇到的问题。未来我们将在以下几个方向持续努力:
①更大的集群
在日志场景下尝试突破 ES 单集群支持的最大节点数限制,提升单个集群能支持的节点数量,从目前的单集群支持的 200 个节点提升到 1000 个节点。
期待在大集群下能降低我们的集群数量提升运维效率,同时更大的集群能更方便和更灵活的提升资源使用率,解决流量突增和资源热点问题。
②更低的成本
降低 ES 的使用成本,提升资源使用率一直是我们追求的目标,上半年我们在完成集群升级以及服务好业务的同时也完成节约成本 80w 每月,ES 整体成本下降约 25%,下半年争取再下降成本 10%。
ES 6.6.1 提供的一些新特性如:Frozen 机制、Indexing sort 都将会进一步降低资源消耗。
③更快的迭代
ES 集群内多租户查询之间的相互影响一直也是滴滴 ElasticSearch 团队面临的一个比较难解决的问题,之前更多的是在平台层面通过物理资源隔离,查询审核和限流来解决,资源利用率不高和人为运维成本太大。
后续我们将构建一套 ES 自身的查询优化器,类似 MySQL 的 Explain,可以在查询语句级别进行性能分析和查询优化,并在引擎层面通过索引模板级别的查询资源隔离、一般 query 和 heavy query 的分离来保障查询的稳定。
④更紧密的联系
在 ES 新版的基础上,我们将和社区保持更紧密的联系,积极的跟进社区提供的新特性和发展方向,并引入滴滴供大家使用。
也会更积极的参与社区建设,将我们在滴滴内部遇到和解决的问题反馈给社区,贡献更多的 PR 和产生更多的 ES Contributor。
作者:赵情融
简介:滴滴专家工程师 2018 加入滴滴,滴滴搜索团队负责人,全面负责滴滴搜索平台的建设工作。曾在阿里巴巴工作多年,有丰富的平台建设经验。
编辑:陶家龙
出处:转载自微信公众号滴滴技术(ID:didi_tech)












