翻译 |来自: AI科技大本营(rgznai100)
参与 | 刘畅
编辑 | 周翔
最近,A股尤其是上证指数走势凌厉,让营长有种身在牛市中的错觉。然而大盘天天涨,营长账户中还是那几百万,甚至还有所缩水。夜深人静的时候,营长常常会点着一支烟,思索到底有没有一个完美的算法,可以预测股价的涨跌,这样就可以早日实现财务自由,走向人生巅峰。这时,一篇外国友人的文章成功引起了营长的注意,看完后备受启发,所以我们将其编译后,分享给大家。
友情提醒:股市有风险,投资需谨慎。
对数据科学家来说,预测证券市场走势是一项非常有诱惑力的工作,当然,他们这样做的目的很大程度上并不是为了获取物质回报,而是为了挑战自己。证券市场起起伏伏、变幻莫测,试想一下,如果在这个市场里存在一些我们或者我们的模型可以学习到的既定模式,让我们可以打败那些商科毕业的操盘手,将是多么美妙。当然,当我一开始使用加性模型(additive model)来做时间序列预测时,我不得不先用模拟盘来验证我的模型在股票市场上的表现。
一众挑战者们都希望在每日收益率上能够跑赢市场,但是大多数都失败了,我也未能幸免。不过,在这个过程中也学到了大量Python相关知识,包括面向对象编程、数据处理、建模、以及可视化等等。同时,我也认清了一个道理,不要在每日收益率上锱铢必较,学会容忍适当的短期亏损,放长线才能钓大鱼。
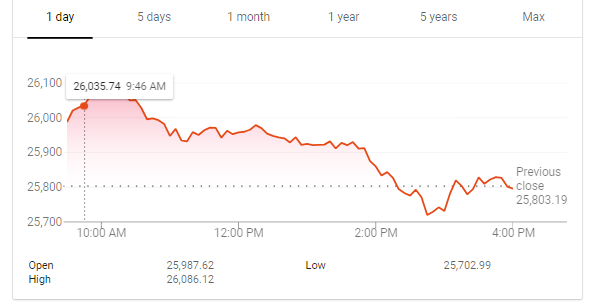
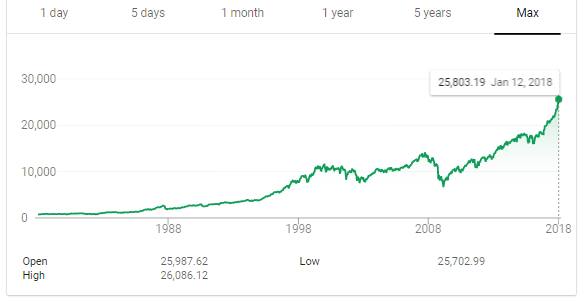
一天与三十年对比结果:你宁愿把钱投在哪里?
在任何任务中(不只是数据科学),当我们没有取得立竿见影的成效时,我们都有三个选择:
1. 调整结果,让我们看起来像是成功了
2. 隐藏结果,所以没有人会注意到
3. 公开我们所有的结果和方法,以便其他人(以及我们自己)可以从中吸取经验和教训
显然,不管站在个人还是社会层面,方案三都是最佳选择,但它同时也是最需要勇气去实践的。我可以选择性地公布结果,比如当我的模型能够带来丰厚的利润回报时,我也可以掩盖失败的事实,假装自己从来没有在这项工作上花过时间。这似乎是很天真的想法!我们之所以能够进步是因为不断重复失败——学习这个过程,而不仅仅是之前的成功。而且,为有难度的任务编写Python代码而付出的努力也并不应该白费!
这篇文章记录了我使用Python开发的“stock explorer”工具——Stocker的预测功能。此前,我曾展示了如何使用Stocker进行分析,并且将完整的代码贴在GitHub上,以方便大家。
Github代码地址:
https://github.com/WillKoehrsen/Data-Analysis/tree/master/stocker
▌实现预测的Stocker工具
Stocker是一款用于探索股票情况的Python工具。一旦我们安装了所需的库(查看文档),我们可以在脚本的同一文件夹中启动一个Jupyter Notebook,并导入Stocker类:

现在可以访问这个类了。我们通过传递任一有效的股票代码(粗体是输出)来创建一个Stocker类的对象:

根据上面的输出结果,我们有20年的亚马逊每日股票数据可以用来探索! Stocker对象是建立在Quandl金融库上,而且拥有3000多只股票可以使用。我们可以使用plot_stock函数来绘制一个简单的历史股价图:

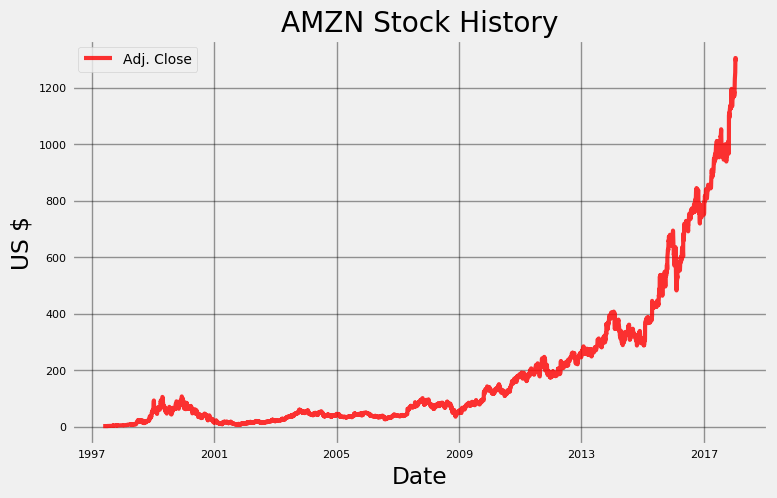
Stocker的分析功能可以用来发现数据中的整体趋势和模式,但我们将重点关注预测股票未来的价格上。Stocker中的预测功能是使用一个加性模型来实现的,该模型将时间序列视为季节性(如每日、每周和每月)的整体趋势组合。Stocker使用Facebook开发的智能软件包进行加性建模,用一行代码就可以创建模型并进行预测:

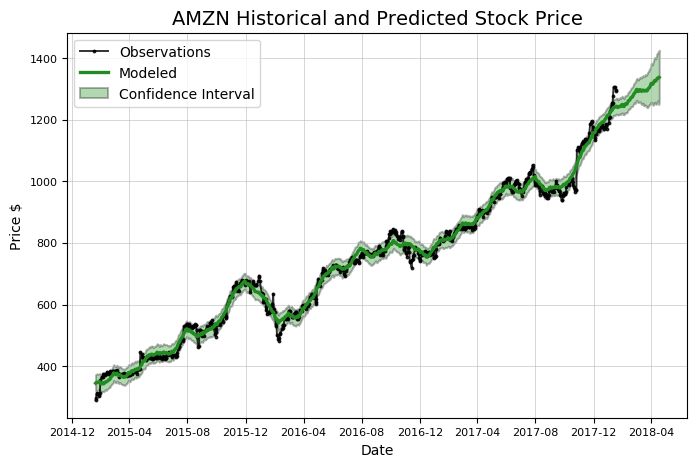
注意,表示预测结果的绿线包含了相对应的置信区间,这代表在模型预测的不确定性。在这种情况下,如果将置信区间宽度设置为80%,这意味着我们预计这个范围将包含实际值的可能性为80%。置信区间将随着时间进一步扩大,这是因为随着预测时间距离现有数据的时间越来越远,预测值将面临更多的不确定性。任何时候我们做这样的预测,都必须包含一个置信区间。尽管大多数人倾向于一个确定的值,但我们的预测结果必须反映出我们生活在一个充满不确定性的世界!
任何人都可以做股票预测:简单地选择一个数字,而这就是你的估测(我可能是错的,但我敢肯定,这是华尔街所有人都会做的)。为了让我们的模型具有可信度,我们需要评估它的准确性。Stocker工具中有许多用于评估模型准确度的方法。
▌评估预测结果
为了计算准确率,我们需要一个测试集和一个训练集。我们需要知道测试集的答案,也就是实际的股价,所以我们将使用过去一年的历史数据(本例中为2017年)。训练时,我们不选用2014-2016的数据来作为训练集。监督学习的基本思想是模型从训练集中学习到数据中的模式和关系,然后能够在测试数据上正确地重现结果。
我们需要量化我们的准确率,所以我们使用了测试集的预测结果和实际值,我们计算的指标包括测试集和训练集的美元平均误差、正确预测价格变化趋势的时间百分比、以及实际价格落在预测结果80%置信区间内的时间百分比。所有这些计算都由Stocker自动完成,而且可视化效果很好:


可以看到,预测结果真是糟糕透了,还不如直接抛硬币。如果我们根据这个预测结果来投资,那么我们最好是买买彩票,这样比较明智。但是,不要放弃这个模型,第一个模型通常比较糟糕,因为我们使用的是默认参数(称为超参数)。如果我们最初的尝试不成功,那么我们可以调整这些参数来获得一个更好的模型。在Prophet模型中有许多不同的参数设置需要调整,最重要的是变点先验尺度(changepoint prior scale),它控制着模型在数据趋势上的偏移量。
▌变点先验(Changepoint Prior)的选择
变点代表时间序列从增加到减少,或者从缓慢增加到越来越快(反之亦然)。它们出现在时间序列变化率最大的地方。变点先验尺度表示在模型中给予变点的偏移量。这是用来控制过度拟合与欠拟合的(也被称为偏差与方差间的权衡)。
一个更高的先验能创造一个更多变点权重和更具弹性的模型,但这可能会导致过拟合,因为该模型将严格遵守训练数据的规律,而不能将它泛化到新的测试数据中。降低先验会减少模型的灵活性,而这又可能会导致相反的问题:欠拟合,当我们的模型没有完全遵循训练数据,而没有学习到底层模式时,这种情况就会发生。如何找出适当的参数以达到正确的平衡,这更多的是一个工程问题而不是理论问题,在这里,我们只能依靠经验结果。Stocker类有两种不同的方式来选择适当的先验:可视化和量化。 我们可以从可视化方法开始:

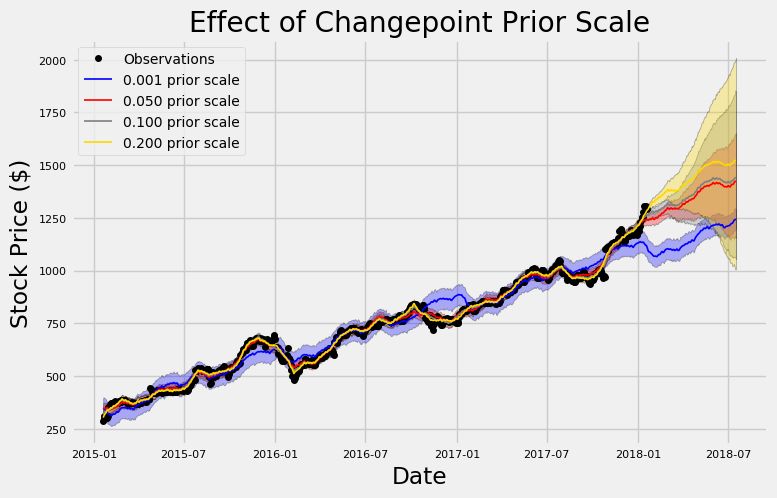
在这里,我们使用三年的数据进行训练,然后显示了六个月的预测结果。我们没有量化这里的预测结果,因为我们只是试图去理解变点先验值的作用。这个图表很好地说明了过拟合与欠拟合!代表最小先验的蓝线与代表训练数据的黑线值并不是非常接近,就好像它有自己的一套模式,并在数据的附近随便选了一条路线。相比之下,代表最大先验的黄线,则与训练观察结果非常贴近。变点先验的默认值是0.5,它落在两个极值之间的某处。
我们还要注意先验值不同带来的不确定性(阴影区间)方面的差异。最小的先验值在训练数据上表现有最大的不确定性,但在测试数据上的不确定性却是最小。相比之下,最大的先验值在训练数据上具有最小的不确定性,但在测试数据上却有最大的不确定性。先验值越高,对训练数据的拟合就越好,因为它紧跟每次的观察值。但是,当使用测试数据时,过拟合模型就会因为没有任何数据点来定位而迷失掉。由于股票具有相当多的变化性,我们可能需要比默认模型更灵活的模型,这样才能够捕捉尽可能多的模式信息。
现在我们对先验值带来的影响有了一个概念,我们可以使用训练集和验证集对数值进行评估:
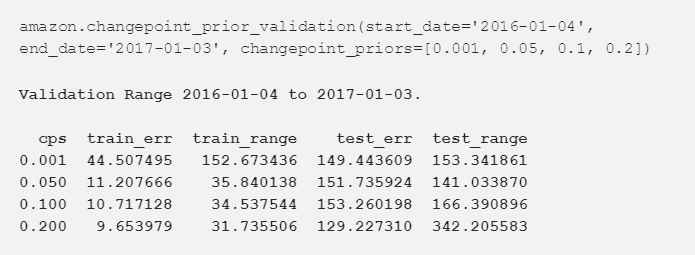
在这里,我们必须注意到,我们的验证集和测试集是不一样的数据。如果它们是一样的,那么我们会得到在测试数据上效果最好的模型,但是它只是在测试数据上过拟合了,而我们的模型也不能用于现实世界的数据。总的来说,就像在数据科学中通常所做的那样,我们正在使用三组不同的数据:训练集(2013-2015)、验证集(2016)和测试集(2017)。
我们用四个指标来评估四个先验值:训练误差、训练范围(置信区间)、测试误差和测试范围(置信区间),所有的值都以美元为单位。正如我们在图中看到的那样,先验值越高,训练误差越低,训练数据的不确定性越低。我们也可以看到,更高的先验能降低我们的测试错误。为了在测试集上获得更高的准确率,作为交换,随着先验的增长,我们在测试数据上得到了更大范围的不确定性。
Stocker先验验证还可以通过两条线来阐述这些点:
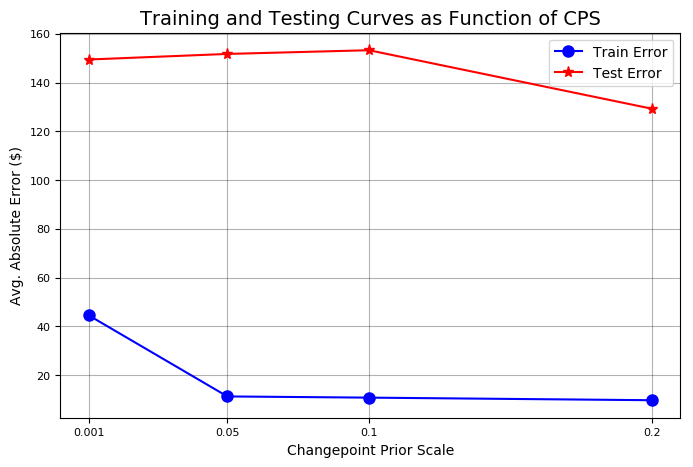
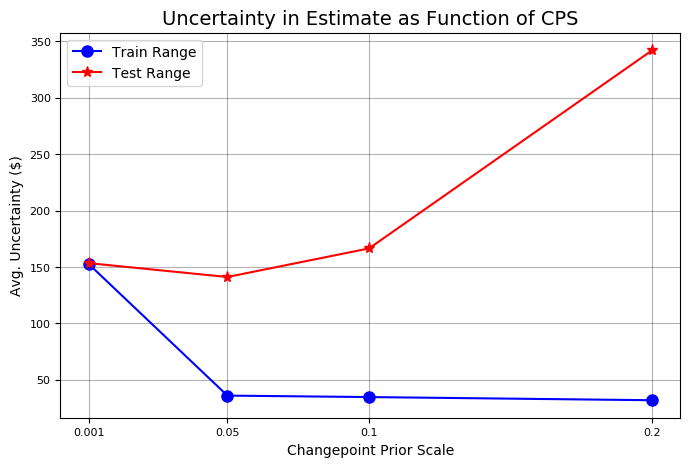
基于不同变点先验尺度下,训练和测试准确性曲线和不确定性曲线
既然最高的先验值产生了最低的测试误差率,我们应该尝试再增加先验值来看看是否能得到更好的结果。我们可以通过在验证中加入其它值的方法来优化我们的搜索:

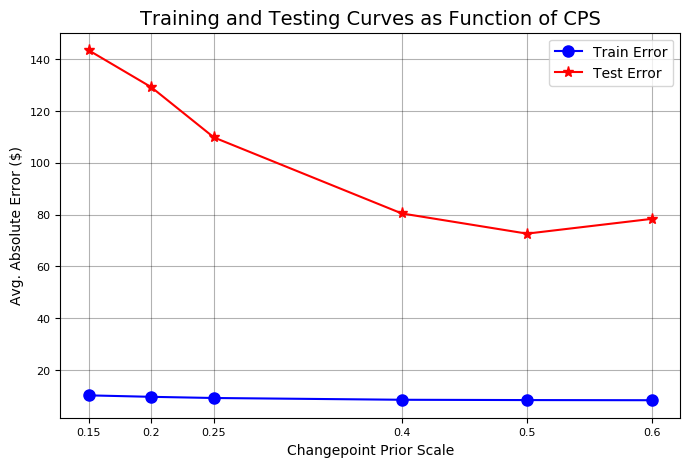
改进后的训练和测试曲线
当先验值为0.5时,测试集的错误率将最小化。因此我们将重新设置Stocker对象的变点先验值。
我们可以调整模型的其他参数,比如我们期望看到的模式,或者模型使用的训练数据。找到最佳组合只需要重复上述过程,并使用一些不同的值。请随意尝试任意的参数!
▌评估改进的模型
现在我们的模型已经优化好了,我们可以再次评估它:

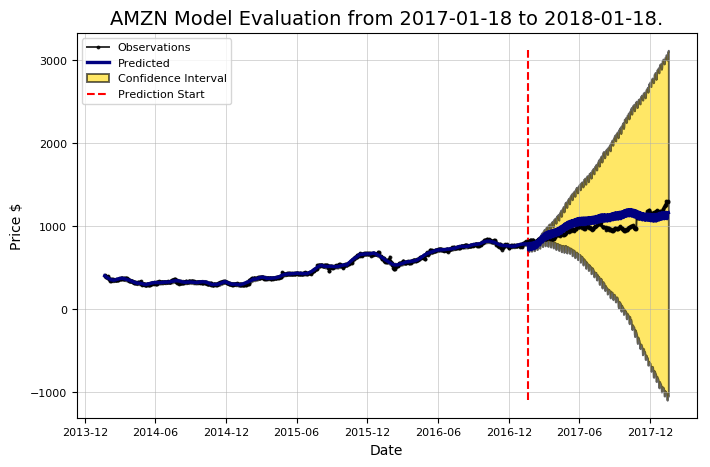
现在看起来好多了! 这显示了模型优化的重要性。使用默认值可以提供第一次合理猜测,但是我们需要确定,我们正在使用正确的模型“设置”,就像我们试图通过调整平衡和淡入淡出来优化立体声的声音那样(很抱歉引用了一个过时的例子)。
▌玩转股票市场
股票预测是一个有趣的实践,但真正的乐趣在于观察这些预测结果在实际市场中会发挥多好的作用。使用evaluate_prediction函数,我们可以在评估期间使用我们的模型“玩一玩”股票市场。我们将使用模型预测给出的策略,与我们在整个期间简单地购买和持有股票的策略进行一个对比。
我们的策略规则很简单,如下:
1、当模型预测股价会上涨的那一天,我们开始买入,并在一天结束时卖出。当模型预测股价下跌时,我们就不买入任何股票;
2、如果我们购买股票的价格在当天上涨,那么我们就把股票上涨的幅度乘以我们购买的股票的数量;
3、如果我们购买的股票价格下跌,我们就把下跌的幅度乘以股票的数量,计作我们的损失。
在整个评估期间,也就是2017年,我们每天以这样的方式进行股票操作。将股票的数量添加进模型回馈里面,Stocker就会以数字和图表显示的方式告诉我们这个策略是如何进行的:
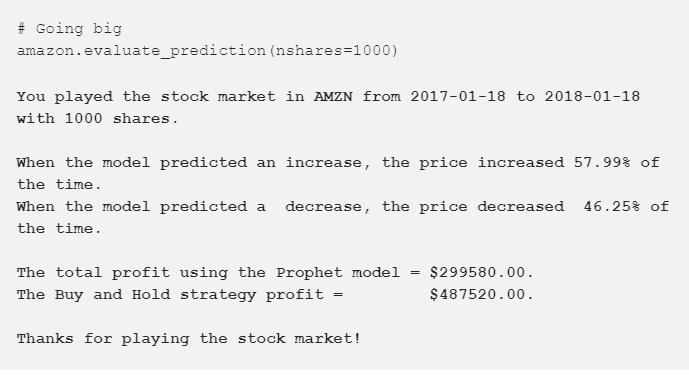
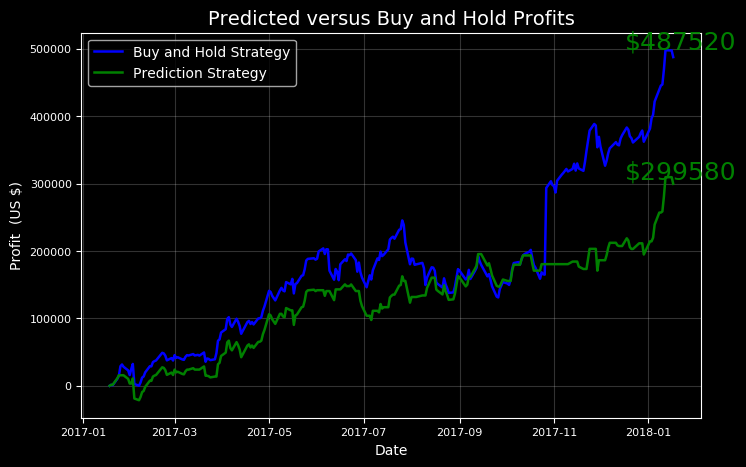
上图告诉了我们一个非常宝贵的策略:买入并持有!虽然我们可以在策略上再作出相当大的调整,但更好的选择是长期投资。
我们可以尝试其他的测试时间段,看看有没有什么时候我们的模型给出的策略能胜过买入和持有的方法。我们的策略是比较保守的,因为当我们预测市场下跌的时候我们不进行操作,所以当股票下跌的时候,我们期待有比持有策略更好的方法。
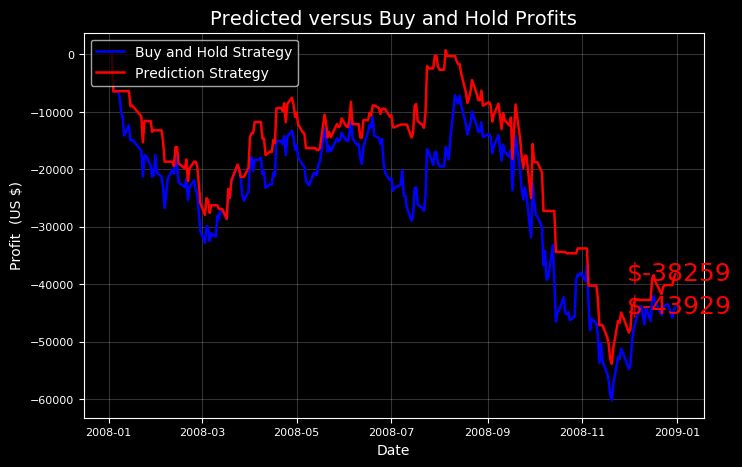
一直用虚拟货币实验
我就知道我们的模型可以做到这一点!不过,我们的模型只有在已经有了当天的数据时才能战胜市场,也就是说还只是事后诸葛亮。
▌对股票未来价格的预测
现在我们有了一个像样的模型,然后就可以使用predict_future()函数来对股票未来价格的进行预测。

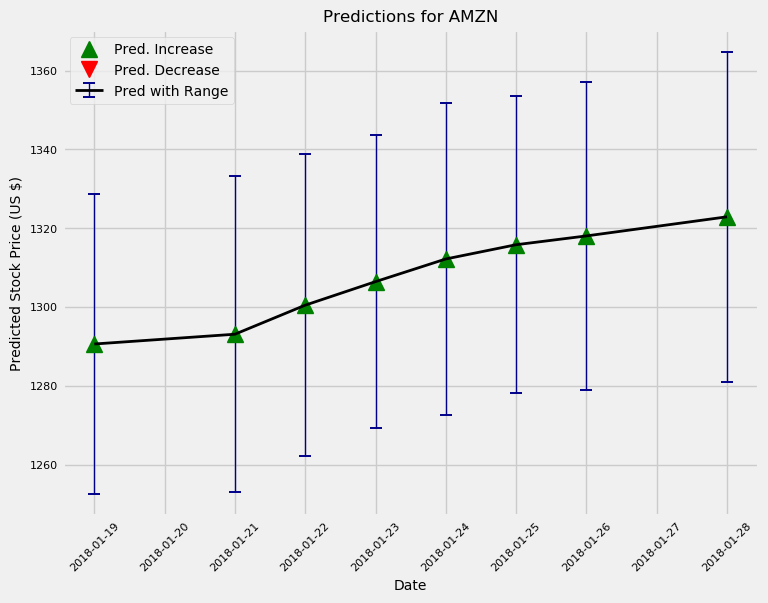
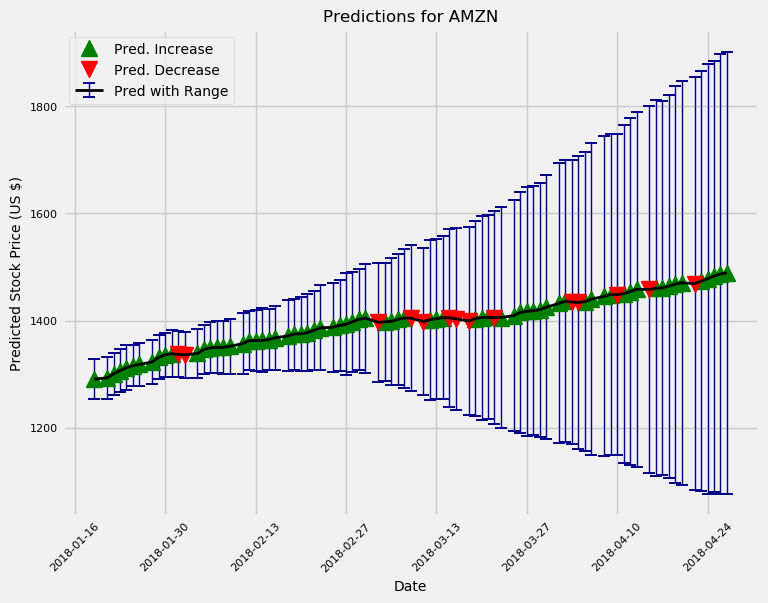
预测接下来10天和100天的股票价格趋势
这个模型和大多数“专业人士”一样,总体上看好Amazon这支股票。另外,我们按照预期做出的估计,不确定性会进一步增加。实际上,如果我们使用这个模型策略进行交易,那我们每天都可以训练一个新的模型,并且提前预测最多一天的价格。
虽然我们可能没有从Stocker工具中获得丰厚的收益,但是重点在于开发过程而不是最终结果! 在我们尝试之前,我们实际上不知道自己是否能解决这样一个问题,就算最终失败,也好过从不尝试!任何有兴趣检查代码或使用Stocker工具的人,都可以在GitHub上找到代码。(https://github.com/WillKoehrsen/Data-Analysis/tree/master/stocker)
作者 | William Koehrsen
原文 | https://towardsdatascience.com/stock-prediction-in-python-b66555171a2
加入数据君良心打造的高效学习圈子点击:
你叫最大?人都是逼出来的…
近期培训
【北京】Python爬虫数据抓取实战开课啦







