(给数据分析与开发加星标,提升数据技能)
来源:简书-七把刀
https://www.jianshu.com/p/d4cc0ea9d097
MySQL InnoDB 引擎现在广为使用,它提供了事务,行锁,日志等一系列特性,本文分析下 InnoDB 的内部实现机制,MySQL 版本为 5.7.24,操作系统为 Debian 9。MySQL InnoDB 的实现非常复杂,本文只是总结了一些皮毛,希望以后能够研究的更加深入些。
1、InnoDB 架构
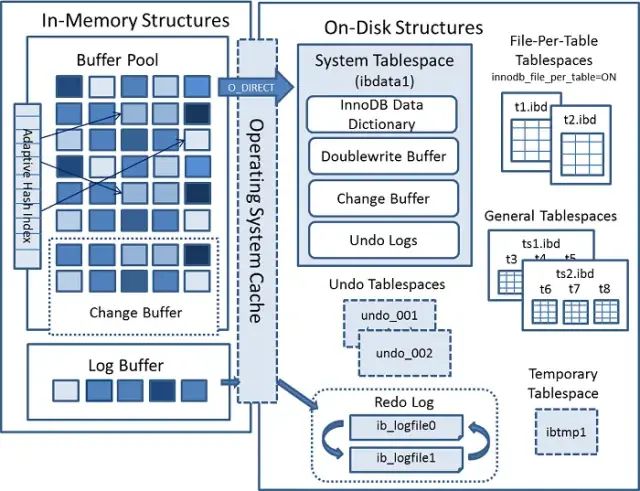
Innodb 架构图
InnoDB 的架构分为两块:内存中的结构和磁盘上的结构。InnoDB 使用日志先行策略,将数据修改先在内存中完成,并且将事务记录成重做日志(Redo Log),转换为顺序IO高效的提交事务。这里日志先行,说的是日志记录到数据库以后,对应的事务就可以返回给用户,表示事务完成。但是实际上,这个数据可能还只在内存中修改完,并没有刷到磁盘上去。内存是易失的,如果在数据落地前,机器挂了,那么这部分数据就丢失了。InnoDB 通过 redo 日志来保证数据的一致性。如果保存所有的重做日志,显然可以在系统崩溃时根据日志重建数据。当然记录所有的重做日志不太现实,所以 InnoDB 引入了检查点机制。即定期检查,保证检查点之前的日志都已经写到磁盘,则下次恢复只需要从检查点开始。2、InnoDB 内存中的结构
内存中的结构主要包括 Buffer Pool,Change Buffer、Adaptive Hash Index以及 Log Buffer 四部分。如果从内存上来看,Change Buffer 和 Adaptive Hash Index 占用的内存都属于 Buffer Pool,Log Buffer占用的内存与 Buffer Pool独立。Buffer Pool
缓冲池缓存的数据包括Page Cache、Change Buffer、Data Dictionary Cache等,通常 MySQL 服务器的 80% 的物理内存会分配给 Buffer Pool。
基于效率考虑,InnoDB中数据管理的最小单位为页,默认每页大小为16KB,每页包含若干行数据。
为了提高缓存管理效率,InnoDB的缓存池通过一个页链表实现,很少访问的页会通过缓存池的 LRU 算法淘汰出去。InnoDB 的缓冲池页链表分为两部分:New sublist(默认占5/8缓存池) 和 Old sublist(默认占3/8缓存池,可以通过 innodb_old_blocks_pct修改,默认值为 37),其中新读取的页会加入到 Old sublist的头部,而 Old sublist中的页如果被访问,则会移到 New sublist的头部。缓冲池的使用情况可以通过 show engine innodb status 命令查看。其中一些主要信息如下:----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 137428992 # 分配给InnoDB缓存池的内存(字节)
Dictionary memory allocated 102398 # 分配给InnoDB数据字典的内存(字节)
Buffer pool size 8191 # 缓存池的页数目
Free buffers 7893 # 缓存池空闲链表的页数目
Database pages 298 # 缓存池LRU链表的页数目
Modified db pages 0 # 修改过的页数目
......
Change Buffer
通常来说,InnoDB辅助索引不同于聚集索引的顺序插入,如果每次修改二级索引都直接写入磁盘,则会有大量频繁的随机IO。Change buffer 的主要目的是将对 非唯一 辅助索引页的操作缓存下来,以此减少辅助索引的随机IO,并达到操作合并的效果。它会占用部分Buffer Pool 的内存空间。在 MySQL5.5 之前 Change Buffer其实叫 Insert Buffer,最初只支持 insert 操作的缓存,随着支持操作类型的增加,改名为 Change Buffer。如果辅助索引页已经在缓冲区了,则直接修改即可;如果不在,则先将修改保存到 Change Buffer。Change Buffer的数据在对应辅助索引页读取到缓冲区时合并到真正的辅助索引页中。Change Buffer 内部实现也是使用的 B+ 树。
可以通过 innodb_change_buffering 配置是否缓存辅助索引页的修改,默认为 all,即缓存 insert/delete-mark/purge 操作(注:MySQL 删除数据通常分为两步,第一步是delete-mark,即只标记,而purge才是真正的删除数据)。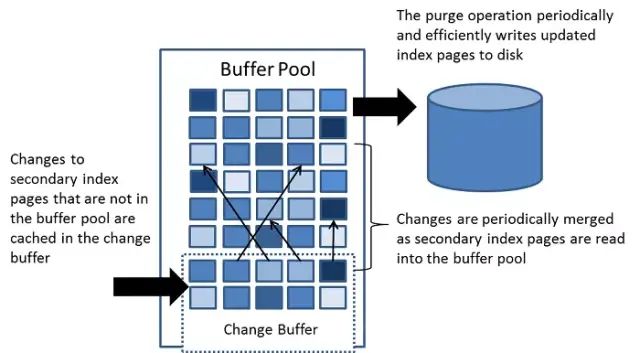
查看Change Buffer 信息也可以通过 show engine innodb status 命令。更多信息见-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1
, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 34673, node heap has 0 buffer(s)
Hash table size 34673, node heap has 0 buffer(s)
Hash table size 34673, node heap has 0 buffer(s)
Hash table size 34673, node heap
has 0 buffer(s)
Hash table size 34673, node heap has 0 buffer(s)
Hash table size 34673, node heap has 0 buffer(s)
Hash table size 34673, node heap has 0 buffer(s)
Hash table size 34673, node heap has 0 buffer(s)
Adaptive Hash Index
自适应哈希索引(AHI)查询非常快,一般时间复杂度为 O(1),相比 B+ 树通常要查询 3~4次,效率会有很大提升。innodb 通过观察索引页上的查询次数,如果发现建立哈希索引可以提升查询效率,则会自动建立哈希索引,称之为自适应哈希索引,不需要人工干预,可以通过 innodb_adaptive_hash_index 开启,MySQL5.7 默认开启。考虑到不同系统的差异,有些系统开启自适应哈希索引可能会导致性能提升不明显,而且为监控索引页查询次数增加了多余的性能损耗, MySQL5.7 更改了 AHI 实现机制,每个 AHI 都分配了专门分区,通过 innodb_adaptive_hash_index_parts配置分区数目,默认是8个,如前一节命令列出所示。Log Buffer
Log Buffer是 重做日志在内存中的缓冲区,大小由 innodb_log_buffer_size 定义,默认是 16M。一个大的 Log Buffer可以让大事务在提交前不必将日志中途刷到磁盘,可以提高效率。如果你的系统有很多修改很多行记录的大事务,可以增大该值。
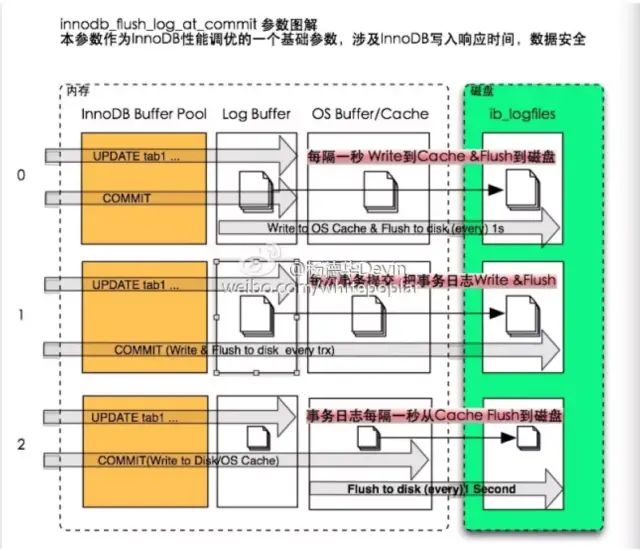
配置项 innodb_flush_log_at_trx_commit 用于控制 Log Buffer 如何写入和刷到磁盘。注意,除了 MySQL 的缓冲区,操作系统本身也有内核缓冲区。
默认为1,表示每次事务提交都会将 Log Buffer 写入操作系统缓存,并调用配置的 “flush” 方法将数据写到磁盘。
设置为 1 因为频繁刷磁盘效率会偏低,但是安全性高,最多丢失 1个 事务数据。
而设置为 0 和 2 则可能丢失 1秒以上 的事务数据。
为 0 则表示每秒才将 Log Buffer 写入内核缓冲区并调用 “flush” 方法将数据写到磁盘。
为 2 则是每次事务提交都将 Log Buffer写入内核缓冲区,但是每秒才调用 “flush” 将内核缓冲区的数据刷到磁盘。
配置不同的值效果如下图所示:
innodb_flush_log_at_timeout 可以配置刷新日志缓存到磁盘的频率,默认是1秒。注意刷磁盘的频率并不保证就正好是这个时间,可能因为MySQL的一些操作导致推迟或提前。而这个 “flush” 方法并不是C标准库的 fflush 方法(fflush是将C标准库的缓冲写到内核缓冲区,并不保证刷到磁盘),它通过 innodb_flush_method 配置的,默认是 fsync,即日志和数据都通过 fsync 系统调用刷到磁盘。可以发现,InnoDB 基本每秒都会将 Log buffer落盘。而InnoDB中使用的 redo log 和 undo log,它们是分开存储的。redo log在内存中有log buffer,在磁盘对应ib_logfile文件。而undo log是记录在表空间ibd文件中的,InnoDB为undo log会生成undo页,对undo log本身的操作(比如向undo log插入一条记录),也会记录redo log,因此undo log并不需要马上落盘。而 redo log 则通常会分配一块连续的磁盘空间,然后先写到log buffer,并每秒刷一次磁盘。redo log 必须在数据落盘前先落盘(Write Ahead Log),从而保证数据持久性和一致性。而数据本身的修改可以先驻留在内存缓冲池中,再根据特定的策略定期刷到磁盘。3、InnoDB 磁盘上的结构
为了后面测试方便,我们先建立一个测试数据库 test,然后建立一个测试表 t。
mysql>
create database test;
mysql> use test;
mysql> create table t (id int auto_increment primary key, ch varchar(5000));
mysql> insert into t (ch) values('abc');
mysql> insert into t (ch) values('defgh');
建立完成后,可以在 MySQL 目录中看到 test 数据库目录,然后里面有 db.opt, t.frm 和 t.ibd 3个文件。其中 db.opt 保存了数据库test的默认字符集 utf8mb4 和校验方法 utf8mb4_general_ci,t.frm 是表的数据字典信息(InnoDB数据字典信息主要是存储在系统表空间ibdata1文件中,由于历史原因才在 t.frm 多保留了一份),t.ibd是表的数据和索引。3.1 InnoDB 表结构
InnoDB 与 MyISAM 不同,它在系统表空间存储数据字典信息,因此它的表不能像 MyISAM 那样直接拷贝数据表文件移动。MySQL5.7 采用的文件格式是 Barracuda,它支持 COMPACT 和 DYNAMIC 这两种新的行记录格式。创建表时可以通过 ROW_FORMAT 指定行记录格式,默认是 DYNAMIC。可以通过命令 SHOW TABLE STATUS 查看表信息,此外,也可使用 SELECT * FROM INFORMATION_SCHEMA.INNODB_SYS_TABLES WHERE NAME='test/t' 查看。mysql> SHOW TABLE STATUS FROM test LIKE 't' \G
*************************** 1. row ***************************
Name: t
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 2
Avg_row_length: 8192
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: 3
Create_time: 2019-01-13 02:24:52
Update_time: 2019-01-13 02:28:16
Check_time: NULL
Collation: utf8mb4_general_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
InnoDB表使用上有一些限制,如一个表最多只能有64个辅助索引,一行大小不能超过65535等,组合索引不能超过16个字段等,一般应该不会突破限制,详细见 innodb-restrictions。3.2 InnoDB 表空间概述
表空间根据类型可以分为系统表空间,File-Per-Table 表空间,常规表空间,Undo表空间,临时表空间等。本节分析 File-Per-Table 表空间。
注意:必须删除常规表空间中的表后才能删除常规表空间。
CREATE TABLESPACE `ts1` ADD DATAFILE 'ts1.ibd' Engine=InnoDB;
CREATE TABLE t1 (c1 INT PRIMARY KEY
) TABLESPACE ts1;
CREATE TABLE t2 (c2 INT PRIMARY KEY) TABLESPACE ts1;
ALTER TABLE t2 TABLESPACE=innodb_file_per_table;
DROP TABLE t1;
DROP TABLESPACE ts1;
表空间文件结构上分为段、区、页。
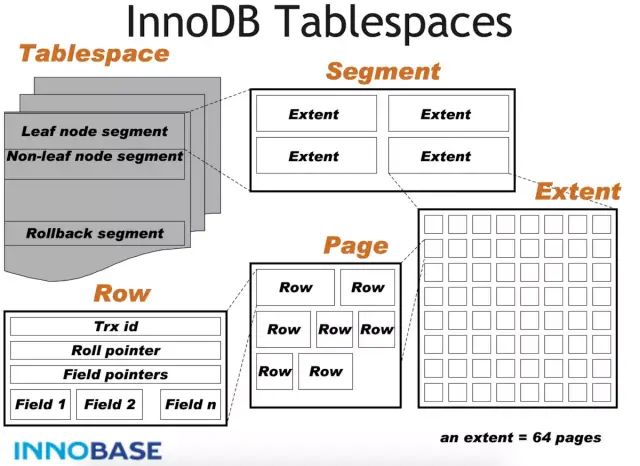
段(Segment)分为索引段,数据段,回滚段等。其中索引段就是非叶子结点部分,而数据段就是叶子结点部分,回滚段用于数据的回滚和多版本控制。一个段包含256个区(256M大小)。
区是页的集合,一个区包含64个连续的页,默认大小为 1MB (64*16K)。
页是 InnoDB 管理的最小单位,常见的有 FSP_HDR,INODE, INDEX 等类型。所有页的结构都是一样的,分为文件头(前38字节),页数据和文件尾(后8字节)。页数据根据页的类型不同而不一样。
FILE_SPACE_HEADER 页:用于存储区的元信息。ibd文件的第一页 FSP_HDR 页通常就用于存储区的元信息,里面的256个 XDES(extent descriptors) 项存储了256个区的元信息,包括区的使用情况和区里面页的使用情况。
IBUF_BITMAP 页:用于记录 change buffer的使用情况。
INODE 页:用于记录文件段(FSEG)的信息,每页有85个INODE entry,每个INODE entry占用192字节,用于描述一个文件段。每个INODE entry包括文件段ID、属于该段的区的信息以及碎片页数组。区信息包括 FREE(完全空闲的区), NOT_FULL(至少使用了一个页的区), FULL(没空闲页的区)三种类型的区的List Base Node(包含链表长度和头尾页号和偏移的结构体)。碎片页数组则是不同于分配整个区的单独分配的32个页。
INDEX 页:索引页的叶子结点的data就是数据,如聚集索引存储的行数据,辅助索引存储的主键值。
3.3 InnoDB File-Per-Table表空间
采用 File-Per-Table 的优缺点如下:
优点:
可以方便回收删除表所占的磁盘空间。
如果使用系统表空间的话,删除表后空闲空间只能被 InnoDB 数据使用。
TRUNCATE TABLE 操作会更快。
可以单独拷贝表空间数据到其他数据库(使用 transportable tablespace 特性),可以更方便的观测每个表空间数据的大小。
缺点:
fsync 操作需要作用的多个表空间文件,比只对系统表空间这一个文件进行fsync操作会多一些 IO 操作。
此外,mysqld需要维护更多的文件描述符。
表空间文件结构
InnoDB 表空间文件 .ibd 初始大小为 96K,而InnoDB默认页大小为 16K,页大小也可以通过 innodb_page_size 配置为 4K, 8K…64K 等。在ibd文件中,0-16KB偏移量即为0号数据页,16KB-32KB的为1号数据页,以此类推。页的头尾除了一些元信息外,还有Checksum校验值,这些校验值在写入磁盘前计算得到,当从磁盘中读取时,重新计算校验值并与数据页中存储的对比,如果发现不同,则会导致 MySQL 崩溃。
ibd文件存储结构如下所示:

ibd文件存储结构
InnoDB页分为INDEX页、Undo页、系统页,IBUF_BITMAP页, INODE页等多种。
第0页是 FSP_HDR 页,主要用于跟踪表空间,空闲链表、碎片页以及区等信息。
第1页是 IBUF_BITMAP 页,保存Change Buffer的位图。
第2页是 INODE 页,用于存储区和单独分配的碎片页信息,包括FULL、FREE、NOT_FULL 等页列表的基础结点信息(基础结点信息记录了列表的起始和结束页号和偏移等),这些结点指向的是 FSP_HDR 页中的项,用于记录页的使用情况,它们之间关系如下图所示。
- 第3页开始是索引页 INDEX(B-tree node),从 0xc000(每页16K) 开始,后面还有些分配的未使用的页。
可以在 innodb_sys_tables 表中查到表t的表空间ID为28,然后可以在 innodb_buffer_page查到所有页信息,一共4个页。分别是 FSP_HDR, IBUF_BITMAP, INODE, INDEX。
select * from information_schema.innodb_sys_tables where name='test/t';
select * from information_schema.innodb_buffer_page where SPACE=28;
索引页分析
InnoDB引擎索引页的结构如下图,可以用 hexdump查看 t.ibd 文件,然后对照InnoDB页的结构分析下各个页的字段。

索引页结构
# hexdump -C t.ibd
0000c000 95 45 82 8a 00 00 00 03 ff ff ff ff ff ff ff ff |.E..............|
0000c010 00 00 00
00 00 28 85 7c 45 bf 00 00 00 00 00 00 |.....(.|E.......|
0000c020 00 00 00 00 00 1c 00 02 00 b0 80 04 00 00 00 00 |................|
0000c030 00 9a 00 02 00 01 00 02 00 00 00 00 00 00 00 00 |................|
0000c040 00 00 00 00 00 00 00 00 00 2f 00 00 00 1c 00 00 |........./......|
0000c050 00 02 00 f2 00 00 00 1c 00 00 00 02 00 32 01 00 |.............2..|
0000c060 02 00 1c 69 6e 66 69 6d 75 6d 00 03 00 0b 00 00 |...infimum......|
0000c070 73 75 70 72 65 6d 75 6d 03 00 00 00 10 00 1b 80 |supremum........|
0000c080 00 00 01 00 00 00 00 05 68 d1 00 00 01 54 01 10 |........h....T..|
0000c090 61 62 63 05 00 00 00 18 ff d6 80 00 00 02 00 00 |abc.............|
0000c0a0 00 00 05 69 d2 00 00 01 55 01 10 64 65 66 67 68 |...i....U..defgh|
0000c0b0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
0000fff0 00 00 00 00 00 70 00 63 95 45 82 8a 00 28 85 7c |.....p.c.E...(.||
00010000 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 |................|
FIL Header(38字节): 记录文件头信息。前4字节 95 45 82 8a 是 checksum,接着 00 00 00 03 是页偏移值 3,即这是第3页。接着 4 字节是上一页偏移值,因为只有一个数据页,所以这里为 ff ff ff ff,接着 4 字节是下一页偏移值 ff ff ff ff。然后 8 字节 00 00 00 00 00 28 85 7c 是日志序列号 LSN。随后的 2 字节45 bf是页类型,代表是 INDEX 页。接着 8 字节00 00 00 00 00 00 00 00表示被更新到的LSN,在 File-Per-Table 表空间中都是0。然后 4 字节00 00 00 1c` 表示该数据页属于的表t的表空间ID是 0x1c(28)。
INDEX Header(36字节): 记录的是 INDEX 页的状态信息。前2字节 00 02 表示页目录的 slot 数目为2;接着2字节 00 b0 是页中第一个记录的指针。80 04是这页的格式为DYNAMIC和记录数4(包括2条System Records我们插入的2条记录)。接着 00 00是可重用空间首指针,再后面2字节00 00是已删除记录数;00 9a是最后插入记录的位置偏移,即最后插入位置是 0xc09a,即第2条记录开始地址。00 02 是最后插入的方向,2 表示 PAGE_DIRECTION_RIGHT,即自增长方式插入。00 01 指一个方向连续插入的数量,这里为1。接着的00 02是 INDEX 页中的真实记录数,我们只有2条记录。然后8字节00…00为修改该页的最大事务ID,这个值只在辅助索引中存在,这里为0。接着2字节00 00为页在索引树的层级,0表示叶子结点。最后8个字节 00…2f为索引ID 47(索引ID可以在information_schema.INNODB_SYS_INDEXES 中查询,可以确认 47 正好是表 t 的主索引)。
FSEG Header:这是INDEX页中的根结点才有的,非根结点的为0。前10字节 00 00 00 1c 00 00 00 02 00 f2 是叶子结点所在段的segment header,分别记录了叶子结点的表空间ID 0x1c,INODE页的页号 2 和 INODE项偏移 0xf2。而后10字节 00 00 00 1c 00 00 00 02 00 32 是非叶子结点所在段的segment header,偏移分别是0xf2 和 0x32,即INODE页的前2个Entry,文件段ID分别是1和2。FSEG Header中存储了该 INDEX 页的INODE项,INODE项里面则记录了该页存储所在的文件段以及文件段页的使用情况。对于 File-Per-Table情况下,每个单独的表空间文件的 FSP_HDR 页负责管理页使用情况。
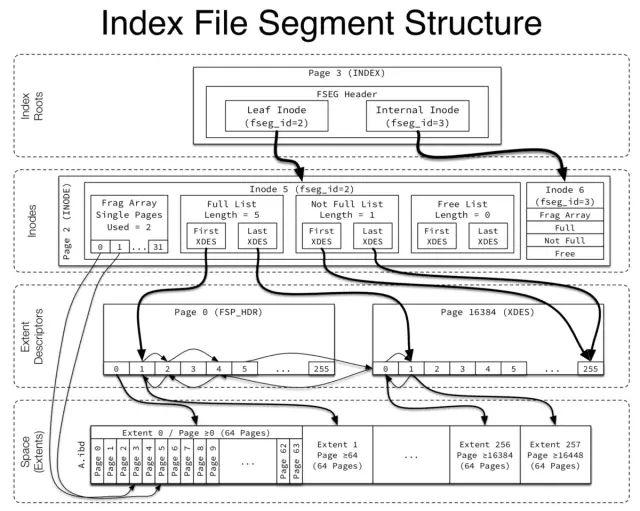
FSEG结构关系图
System Records(26字节): 每个 INDEX 页都有两条虚拟记录 infimum 和 supremum,用于限定记录的边界,各占 13 个字节。其中记录头的5个字节分别标识了拥有记录的数目和类型(拥有记录数目是即后面页目录部分的owned值,当前页目录只有两个槽,infimum拥有记录数只有它自己为1,而supremum拥有我们插入的2条记录和它自己,故为3)、下一条记录的偏移 0x1c,即位置是 0xc07f,这就是我们实际记录开始位置。后面8个字节为 infimum + 空值,supremum类似,只是它下一条记录偏移为0。
01 00 02 00 1c 69 6e 66 69 6d 75 6d 00 # infimum
03 00 0b 00 00 73 75 70 72 65 6d 75 6d # supermum
User Records: 接下来是2条我们插入的记录。第1条记录前面7字节是记录头(Record Header),其中前面的 1字节记录的是可变变量的长度03,因为我们记录中c的值是 abc。然后1字节记录的是可为NULL的变量是否是NULL,这里不为 NULL,故为0。接着的5字节记录了插入顺序2(infimum插入顺序固定是0,supremum插入顺序是1,其他记录则是从2开始),下一个记录的偏移 0x1b(即下一个记录开始位置是0xc078+0x1b=0xc093),删除标记等。后面就是记录内容。第2条记录同理。这里的事务ID可以通过 select * from information_schema.innodb_trx 进行验证。
03 00 00 00 10 00 1b # 记录头
80 00 00 01 # 主键值1
00 00 00 00 05 68 # 事务ID
d1 00 00 01 54 01 10 # 回滚指针
61 62 63 # ch的值 abc
05 00 00 00 18 ff d6 # 第2条记录头
80 00 00 02 # 主键值2
00 00 00 00 05 69 # 事务ID
d2 00 00 01 55 01 10 # 回滚指针
64 65 66 67 68 # ch的值 defgh
B+树页详细结构
Page Directory(4字节):因为页目录的slot只有2个,每个slot占2字节,故页目录为 00 70 00 63 这4字节,存储的是相对于最初行的位置。其中 0xc063 正好是 infimum 记录的开始位置,而 0xc070 正好是 supremum 记录的开始位置。使用页目录进行二分查找,可以加速查询,详细见后面分析。
FIL Tail (8字节): 最后8字节为 95 45 82 8a 00 28 85 7c,其中 95 45 82 8a 为 checknum,跟 FIL Header的checksum一样。后4字节00 28 85 7c 与 FIL Header的LSN的后4个字节一致。
当然,我们也可以通过 innodb_ruby 工具来分析表空间文件。
root@stretch:/home/vagrant# innodb_space -s /var/lib/mysql/ibdata1 -T test/t space-page-type-regions
start end count type
0 0 1 FSP_HDR
1 1 1 IBUF_BITMAP
2 2 1 INODE
3 3 1 INDEX
4 5 2
FREE (ALLOCATED)
root@stretch:/home/vagrant# innodb_space -s /var/lib/mysql/ibdata1 -T test/t -p 3 page-records
Record 127: (id=1) → (ch="abc")
Record 154: (id=2) → (ch="defgh")
索引结构
InnoDB数据文件本身就是索引文件,其索引分聚集索引和辅助索引,聚集索引的叶节点包含了完整的数据记录,辅助索引叶节点数据部分是主键的值,除了空间索引外,InnoDB的索引实现基本都是 B+ 树,如图所示。其中非叶子结点存储的是子页的最小的键值和子页的页号,叶子结点存储的是数据,数据按照索引键排序。同一层的页之间用双向链表连接(前面提到的FIL Header中PREV PAGE 和 NEXT PAGE),同一页内的记录用单向链表连接(Record Header中记录了下一条记录的偏移)。每一页设置了两个虚拟记录Infimum和Supremum用于标识页的开始和结束。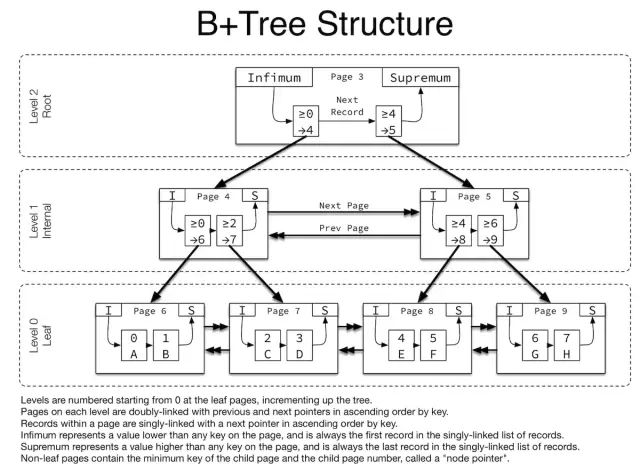
在InnoDB中根据辅助索引查询,如果除了主键外还有其他字段,则需要查询两遍,先根据辅助索引查询主键的值,然后再到主索引中查询得到记录。此外,因为辅助索引的数据部分是主键值,主键不能过大,否则会导致辅助索引占用空间变大,用自增ID做主键是个不错的选择。mysql> create table t2(id int auto_increment primary key, ch varchar(10), key(ch));
mysql> insert into t2(ch) values('ab');
创建一个新的测试表 t2,有主索引 id 和 辅助索引 ch,分析 t2.ibd 文件可验证:
对比表t,表t2多一个INDEX页,用于存储辅助索引的根结点。
辅助索引的INDEX页也有两个系统记录 infimum 和 supremum。
而用户记录内容格式跟前面分析基本一致,内容为辅助索引 ch 列的值 ab 和 主键值1。
页目录
前面提到INDEX页内的记录是通过单向链表连接在一起的,遍历列表性能会比较差,而INDEX页的页目录就是为了加速记录搜索。表 t2 中的页目录只有两项,分别是 0x63 和 0x70,即 99 和 112。
下面的ownedkey为这个页目录槽拥有的小于等于它的记录数目,显然 infimum 的ownedkey为 1,即只有它自己,没有key会比infimum小。而 supremum 的owned是3,分别是我们插入的两条记录和它自己。
slot offset type owned key
0 99 infimum 1
1 112 supremum 3
每个页目录槽最少要包含4个记录,最多包含8个记录(包括它自己)。如果我们在表 t2 中另外插入 7 条记录,则会增加一个新的slot,即 id 为 4 的记录,如下:
slot offset type owned key
0 99 infimum 1
1 207 conventional 4 (i=4)
2 112 supremum 5
下图是页目录结构图,可以通过页目录的二分查找提高页内数据的查询性能。
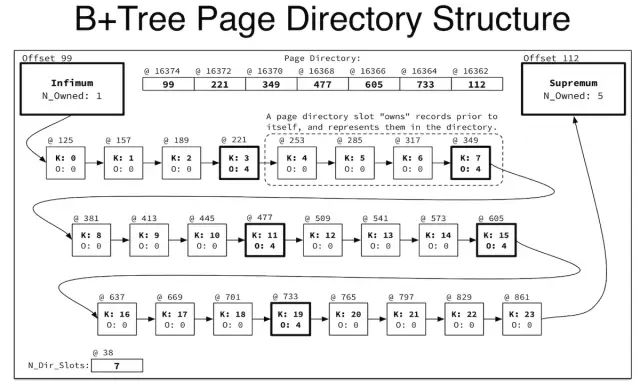
页目录结构
3.4 InnoDB 系统表空间
系统表空间包含内容有:数据字典,双写缓冲,修改缓冲,undo日志,以及在系统表空间创建的表的数据和索引。可以看到,除了分配未使用的页外, UNDO_LOG,SYS, INDEX 页占据了不少的空间。UNDO_LOG 页存储的是Undo log,SYS 页存储的是数据字典、回滚段、修改缓存等信息,INDEX 是索引页,TRX_SYS 页用于InnoDB的事务系统。数据字典就是数据表的元信息,修改缓冲前面提到是为了提高IO性能也不再赘述,这里主要分析下 Undo 日志和双写缓冲。
root@stretch:/home/vagrant# innodb_space -s /var/lib/mysql/ibdata1 space-page-type-summary
type count percent description
ALLOCATED 427 55.60 Freshly allocated
UNDO_LOG 125 16.28 Undo log
SYS 110 14.32 System internal
INDEX 71 9.24 B+Tree index
INODE 11 1.43 File segment inode
FSP_HDR 9 1.17 File space header
IBUF_BITMAP 8 1.04 Insert buffer bitmap
BLOB
5 0.65 Uncompressed BLOB
TRX_SYS 2 0.26 Transaction system header
Undo 日志
MySQL的MVCC(多版本并发控制)依赖Undo Log实现。MySQL的表空间文件 t.ibd 存储的是记录最新值,每个记录都有一个回滚指针(见前面图中的Roll Ptr),指向该记录的最近一条Undo记录,而每条Undo记录都会指向它的前一条Undo记录,如下图所示。默认情况下 undo log存储在系统表空间 ibdata1 中。
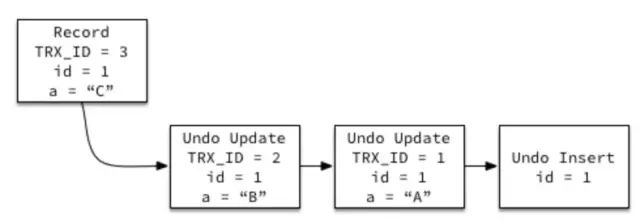
Undo Log示意图
CREATE TABLE `t3` (
`id` int(11) NOT NULL,
`a` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into t3 values(1, 'A');
update t3 set a='B' where id=1;
update t3 set a='C' where id=1;
插入一条数据后,可以发现当前 t3.ibd 文件中的记录是 (1, ‘A’),而 Undo Log此时有一条 insert 的记录。如下:
root@stretch:/var/lib/mysql# innodb_space -s ibdata1 -T test/t3 -p 3 -R 127 record-history
Transaction Type Undo record
(n/a) insert (id=1) → ()
执行后面的update语句,可以看到 undo log如下:
root@stretch:/var/lib/mysql# innodb_space -s ibdata1 -T test/t3 -p 3 -R 127 record-history
Transaction Type Undo record
2333 update_existing (id=1) → (a="B")
2330 update_existing (id=1) → (a="A")
(n/a) insert (id=1) → ()
需要注意的是,Undo Log 在事务执行过程中就会产生,事务提交后才会持久化,如果事务回滚了则Undo Log也会删除。
另外,删除记录并不会立即在表空间中删除该记录,而只是做个标记(delete-mark),真正的删除则是等由后台运行的 purge 进程处理。除了每条记录有Undo Log的列表外,整个数据库也会有一个历史列表,purge 进程会根据该历史列表真正删除已经没有再被其他事务使用的 delete-mark 的记录。purge 进程会删除该记录以及该记录的 Undo Log。
双写缓冲
先回顾下InnoDB的记录更新流程:先在Buffer Pool中更新,并将更新记录到 Redo Log 文件中,Buffer Pool中的记录会标记为脏数据并定期刷到磁盘。由于InnoDB默认Page大小是16KB,而磁盘通常以扇区为单位写入,每次默认只能写入512个字节,无法保证16K数据可以原子的写入。
如果写入过程发生故障(比如机器掉电或者操作系统崩溃),会出现页的部分写入(partial page writes),导致难以恢复。因为 MySQL 的重做日志采用的是物理逻辑日志,即页间是物理信息,而页内是逻辑信息,在发生页部分写入时,无法确认数据页的具体修改而导致难以恢复。
MySQL 的数据页在真正写入到表空间文件前,会先写到系统表空间文件的一段连续区域双写缓冲(Double-Write Buffer,默认大小为 2MB,128个页)并 fsync 落盘,等双写缓冲写入成功后才会将数据页写到实际表空间的位置。
因为双写缓冲和数据页的写入时机不一致,如果在写入双写缓冲出错,可以直接丢弃该缓冲页,而如果是写入数据页时出错,则可以根据双写缓冲区数据恢复表空间文件。
4、InnoDB 事务隔离级别
InnoDB的多版本并发控制是基于事务隔离级别实现的,而事务隔离级别则是依托前面提到的 Undo Log 实现的。当读取一个数据记录时,每个事务会使用一个读视图(Read View),读视图用于控制事务能读取到的记录的版本。
InnoDB的事务隔离级别分为:Read UnCommitted,Read Committed,Repeatable Read以及Serializable。其中Serializable是基于锁实现的串行化方式,严格来说不是事务可见性范畴。
Read Uncommitted:
未提交读也称为脏读,它读取的是当前最新修改的记录,即便这个修改最后并未生效。
Read Committed:
提交读。
它基于的是当前事务内的语句开始执行时的最大的事务ID。
如果其他事务修改同一个记录,在没有提交前,则该语句读取的记录还是不会变。
但是这种情况会产生不可重复读,即一个事务内多次读取同一条记录可能得到不同的结果(该记录被其他事务修改并提交了)。
Repeatable Read:
可重复读。
它基于的是事务开始时的读视图,直到事务结束。
不读取其他新的事务对该记录的修改,保证同一个事务内的可重复读取。
InnoDB提供了 next-key lock来解决幻读问题,不过在一些特殊场景下,可重复读还是可能出现幻读的情况。
在实际开发中影响不大,就不赘述了。
5、InnoDB 和 ACID 模型
事务有 ACID 四个属性, InnoDB 是支持事务的,它实现 ACID 的机制如下:
Atomicity
innodb的原子性主要是通过提供的事务机制实现,与原子性相关的特性有:
Autocommit 设置。
COMMIT 和 ROLLBACK 语句(通过 Undo Log实现)。
Consistency
innodb的一致性主要是指保护数据不受系统崩溃影响,相关特性包括:
InnoDB 的双写缓冲区(doublewrite buffer)。
InnoDB 的故障恢复机制(crash recovery)。
Isolation
innodb的隔离性也是主要通过事务机制实现,特别是为事务提供的多种隔离级别,相关特性包括:
Autocommit设置。
SET ISOLATION LEVEL 语句。
InnoDB 锁机制。
Durability
innodb的持久性相关特性:
Redo log。
双写缓冲功能。
可以通过配置项 innodb_doublewrite 开启或者关闭。
配置 innodb_flush_log_at_trx_commit。
用于配置innodb如何写入和刷新 redo 日志缓存到磁盘。
默认为1,表示每次事务提交都会将日志缓存写入并刷到磁盘。
innodb_flush_log_at_timeout 可以配置刷新日志缓存到磁盘的频率,默认是1秒。
配置 sync_binlog。
用于设置同步 binlog 到磁盘的频率,为0表示禁止MySQL同步binlog到磁盘,binlog刷到磁盘的频率由操作系统决定,性能最好但是最不安全。
为1表示每次事务提交前同步到磁盘,性能最差但是最安全。
MySQL文档推荐是 sync_binlog 和 innodb_flush_log_at_trx_commit 都设置为 1。
操作系统的 fsync 系统调用。
UPS设备和备份策略等。
参考资料
https://blog.jcole.us/innodb/
https://dev.mysql.com/doc/refman/5.7/en/innodb-storage-engine.html
http://ourmysql.com/archives/1228
看完本文有收获?请转发分享给更多人
关注「数据分析与开发」加星标,提升数据技能

好文章,我在看❤️









