
我们有下面一张PDF格式存储的表格,现在需要使用Python将它提取出来。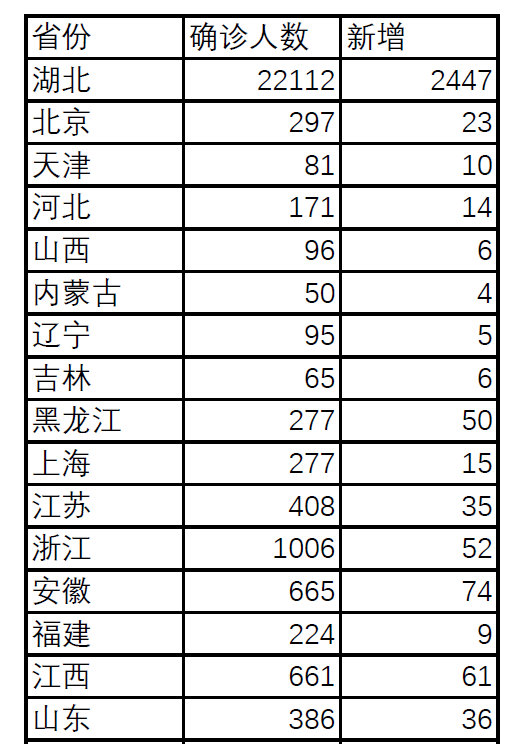

使用Python提取表格数据需要使用pdfplumber模块,打开CMD,安装代码如下:1import pdfplumber
2import pandas as pd
1# 使用with语句打开pdf文件
2with pdfplumber.open("D:\\python\\cai\\yq.pdf") as pdf:
3 # pages[0]表示取第1页
4 page = pdf.pages[0]
我们来打印输出下获取到的文本,这句语句只是帮我们验证下是否成功获取到PDF里的内容1print(page.extract_text())

然后可以使用extract_table()函数获取表格,如果有多个表格,可以使用extract_tables()函数,就是多了个s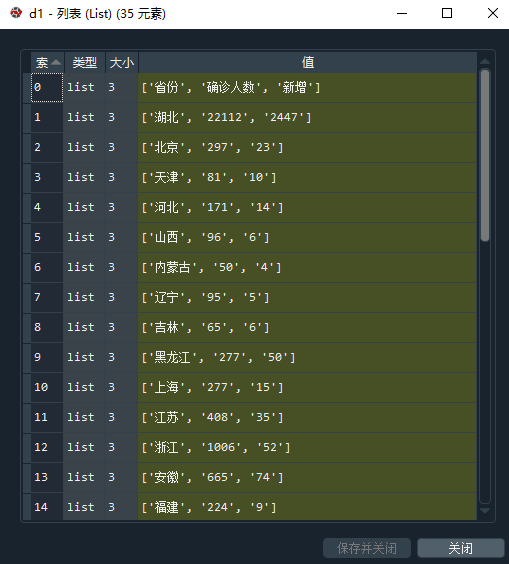
所以最后一步就是将列表转为数据框就可以了,代码如下:1df = pd.DataFrame(d1[1:], columns=d1[0])
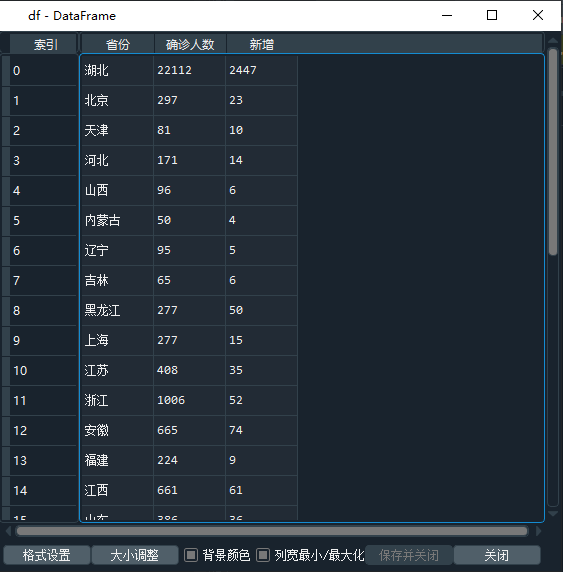
1.pdf表格中的数据,对于同一个数据或内容,不要有换行,如果换行,可能被识别为2个数据;2.pdf中的表格一定要有边框,没有边框的话,否则使用extract_table()函数就无法获取表格数据,extract_text()还是可以获取文本信息的,不要问我是怎么知道的,说多了都是泪。
希望系统、快速学习Python数据分析知识,可以学习
数据分析专家@文彤老师的
《跟文彤老师学Python数据分析》系列视频课程

包含以下三门课程
Python数据分析--玩转Pandas
Python数据分析--玩转数据可视化
玩转Python统计分析
以上顺序也是学习的建议顺序
课程提供讲义(含代码)与数据供练习
学习过程有问题可加Q群与老师交流讨论

如还有其他问题也可添加课程助理微信号咨询,添加时请注明所咨询的课程

现参加课程学习,可享受6折优惠
购买课程直接点击文末“阅读原文”进入即可










