
使用concurrent.futures并发执行简单任务
用Python编写并发代码可能很棘手。在您开始之前,您必须考虑很多令人讨厌的事情,比如手头的任务是I/O密集型还是计算密集型、为实现并发性所付出的代价是否会给您带来所需要的提升。此外,由于全局解释器锁的存在,进一步限制了编写真正并发的代码。但为了理智起见,你可以这样简化并发编程,而不必大错特错:
在Python中,如果手头的任务是I/O密集型,可以使用标准库的threading 模块,或者如果任务是计算密集型,那么multiprocessing模块很有助益。threading和multiprocessing为您提供了很多控制权和灵活性,但它们的代价是必须编写相对低级的冗长代码,在核心逻辑的基础上增加额外的并具有复杂性的层。有时,当目标任务很复杂时,在添加并发时通常无法避免复杂性。然而,许多简单的任务可以并发而不增加太多额外的开销。
Python标准库还包含一个名为concurrent.futures的模块。这个模块是在Python3.2中添加的,为开发人员提供了一个高级接口来启动异步任务。它是在threading和multiprocessing 之上的一个通用抽象层,用于提供一个接口,以便使用线程池或进程池并发地执行任务。如果您只想同时运行一段合格的代码,而不需要threading和multiprocessing api所暴露的附加特性,那么它就是一个完美的工具。
从官方文件来看,concurrent.futures模块为异步执行可调用函数提供了一个高级接口。
它的意思是,您可以使用线程或进程通过公共的高级接口异步运行子例程。总体来看,模块提供了一个名为Executor的抽象类。不能直接实例化它,而是需要使用它提供的两个子类之一来运行任务。
在内部,这两个类与线程池交互并管理其中的 workers。Future用于管理线程计算的结果。若要使用池中的 workers,应用程序将创建相应executor 的实例,然后将 workers提交给实例运行。当每个任务启动时,将返回一个Future 实例。当需要任务的结果时,应用程序可以使用Future对象来阻塞程序直到结果可用为止。提供了各种api,以方便等待任务完成,从而无需直接管理Future对象。
由于ThreadPoolExecutor和ProcessPoolExecutor都有相同的API接口,在这两种情况下,我将主要讨论它们提供的两个方法。他们的描述是从官方文件中一字不差地收集来的。接收将要执行的可调用函数fn作为fn(*args**kwargs),并返回表示可调用函数执行结果的Future对象。
map(func, *iterables, timeout=None, chunksize=1)
类似于map(func,*iterables),除了:立即收集iterables 而不是惰性收集;func是异步执行的,对func的几个调用可以同时进行。
如果调用了 __next__(),并且在对Executor.map()的原始调用超时后结果仍不可用,则返回的迭代器将抛出concurrent.futures.TimeoutError。超时时间可以是int或float。如果超时时间未指定或为None,则等待时间没有限制。
如果func调用引发异常,则在从迭代器检索其值时将引发该异常。
当使用ProcessPoolExecutor时,此方法将iterable分为若干块,并作为单独的任务提交给池。这些块的(近似)大小可以通过将chunksize设置为正整数来指定。对于很长的iterable,使用一个较大的chunksize值与默认大小1相比可以显著提高性能。对于ThreadPoolExecutor,chunksize没有任何效果。

在这里,get_tasks返回一个iterable,其中包含需要执行特定任务函数的目标任务或参数。任务通常是阻塞的可调用函数,它们一个接一个地运行,一次只运行一个任务。由于其顺序执行,逻辑很容易推理。当任务数量较少或单个任务的执行时间要求和复杂性较低时,是很方便的。然而,当任务数量巨大或单个任务耗时很长时,可能会很快失控。
一般的经验法则是在I/O密集型任务中使用ThreadPoolExecutor,比如向多个URL发送多个http请求,将大量文件保存到磁盘等等。在计算密集型任务中应该使用ProcessPoolExecutor,比如在大量的图像上运行计算量很大的预处理函数,同时操作许多文本文件等。
当您有许多任务时,您可以将它们放到一次运行计划中,并等待它们全部完成,然后您可以收集结果。
在这里,您首先创建一个Executor,它管理正在运行的所有任务----在单独的进程或线程中。使用with语句创建一个上下文调度器,它确保在完成后通过隐式调用executor.shutdown()方法清除所有不需要的线程或进程。
在实际代码中,基于callables的性质,您需要用ThreadPoolExecutor或ProcessPoolExecutor替换Executor。然后使用set comprehension开始所有的任务。executor.submit()方法调度每个任务。这将创建一个Future对象,该对象表示要完成的任务。一旦所有的任务都安排好了,就调用concurrent.futures_as_completed()方法,这会在每个任务完成时生成future。executor.result()方法提供perform(task)的返回值,或者在失败时抛出异常。
executor.submit()方法异步调度任务,不保存与原始任务相关的任何上下文。所以如果你想把结果和最初的任务对应起来,你需要自己去追踪它们。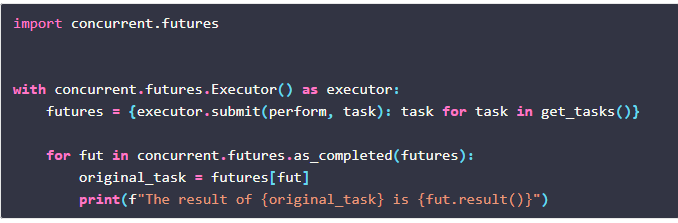 注意变量futures,其中原始任务使用字典映射到对应的futures。
注意变量futures,其中原始任务使用字典映射到对应的futures。
另一种方法是使用execuror.map()方法,按照预定的顺序收集结果。
注意map函数如何一次获取整个iterable。它会立即而不是惰性地把结果按预定的顺序显示出来。如果在操作过程中发生任何未处理的异常,它也将立即抛出,并且不会继续执行。
在Python3.5+中,executor.map()接收一个可选参数:chunksize。当使用ProcessPoolExecutor时,对于很长的iterable,使用一个较大的chunksize值与默认大小1相比可以显著提高性能。对于ThreadPoolExecutor,chunksize没有效果。
在继续示例之前,让我们编写一个小的decorator,它将有助于度量和比较并发代码和顺序代码的执行时间。
可以这样使用decorator:
首先,让我们从一堆url下载一些pdf文件并将它们保存到磁盘。这可能是一个I/O密集型的任务,我们将使用ThreadPoolExecutor类来执行该操作。但在此之前,我们先按顺序来做。
在上面的代码片段中,我主要定义了两个函数。下载功能从给定的URL下载pdf文件并将其保存到磁盘。它检查URL中的文件是否具有扩展名,如果没有扩展名,则会引发运行时错误。如果在文件名中找到扩展名,它将逐块下载文件并保存到磁盘。第二个函数download_all只是遍历一个url序列,并对每个url应用download_one函数。顺序执行花费了22.8s。现在让我们看看相同代码的多线程版本的表现。代码的并发版本只需要顺序版本用时的1/4左右。注意,在这个并发版本中,download_one函数与之前相同,但是在download_all函数中,ThreadPoolExecutor上下文管理器包含了execute.map()方法。download_one与包含url的iterable一起传递到map中。timeout参数确定线程在多久之后放弃管道中的某个任务。max_workers表示要部署多少工作线程来生成和管理线程。一般经验法则是使用2 * multiprocessing.cpu_count() + 1。我的机器有6个物理内核和12个线程。所以我设置为13。
注意:您还可以尝试通过相同的接口使用ProcessPoolExecutor运行上述函数,并注意到多线程版本的性能由于任务性质合适而表现稍好。
使用Multi-processing运行计算密集型子例程
下面的示例显示了一个计算密集型的哈希函数。主函数将按顺序多次运行计算密集型哈希算法。然后另一个函数将再次多次运行加密操作。让我们先按顺序运行函数。
如果您分析hash-one和hash-all函数,您可以看到它们实际上是两个计算密集型的嵌套for循环。上述代码在顺序模式下运行大约需要18秒。现在让我们使用ProcessPoolExecutor并行运行它。
如果仔细观察,即使在并发版本中,hash中的for循环也会按顺序运行。然而,hash_all函数中的另一个for循环正在通过多个进程执行。在这里,我用将workers数量设置为10,chunksize设置为2。调整了workers数量和chunksize以获得最大性能。如您所见,上述计算密集型操作的并发版本比其顺序操作的版本快11倍。
既然concurrent.futures提供这样一个简单的API,您可能会尝试将并发性应用于手头的每个简单任务。不过,这不是个好主意。首先,简单性有其合理的限制。这样,您只能将并发性应用于最简单的任务,通常是将函数映射到iterable或同时运行几个子例程。如果您手头的任务需要排队,从多个进程生成多个线程,那么您仍然需要使用较低级别的threading和multiprocessing模块。
使用并发的另一个陷阱是使用ThreadPoolExecutor时可能出现的死锁情况。当与Future 关联的可调用函数等待另一个Future的结果时,它们可能永远不会释放对线程的控制并导致死锁。让我们看看官方文档中稍微修改过的示例。
在上面的例子中,函数wait_on_b依赖于函数wait_on_a的结果(Future对象的结果),同时后一个函数的结果依赖于前一个函数的结果。因此,上下文管理器中的代码块永远不会执行,因为它具有相互依赖性。这就造成了死锁。让我们从官方文档中解释另一个死锁情况。
当子例程生成嵌套的future对象并在单个线程上运行时,通常会发生上述情况。在函数wait_on_future中,executor.submit(pow,5,2)创建另一个future
对象。因为我使用一个线程运行整个过程,所以内部的future对象正在阻塞线程,并且上下文管理器中的外部executor.submit()方法不能使用任何线程。使用多个线程可以避免这种情况,但通常,这本身就是一个糟糕的设计。
在某些情况下,并发代码的性能可能比顺序代码的性能低。这可能有多种原因。
线程用于执行计算密集型的任务
多进程用于执行I/O密集型任务
这些任务太琐碎,无法使用线程或多个进程
生成和调度多个线程或进程会带来额外的开销。通常线程的生成和调度速度比进程快得多。然而,使用错误的并发类型实际上会降低代码的速度,而不是使其更高效。下面是一个简单的示例,其中ThreadPoolExecutor和ProcessPoolExecutor的性能都比它们的顺序版本差。
以上示例验证列表中的数字是否为素数。我们在1000个数字上运行这个函数来确定它们是不是质数。顺序版本大约花了67毫秒。但是,请看下面,同一代码的多线程版本执行同一任务所需的时间(140ms)竟是两倍多。
同一代码的多线程版本甚至更慢。这些任务并不能证明开放多进程是正确的。
虽然从直观上看,检查质数的任务似乎应该是一个计算密集型操作,但确定任务本身的计算量是否足以证明使用多个线程或进程的合理性也很重要。否则,您可能会得到比简单解决方案性能更差的复杂代码。
博客中的所有代码都是在运行Ubuntu 18.04的机器上,用python 3.8编写和测试的。
concurrent.futures-官方文档(https://docs.python.org/3/library/concurrent.futures.html)Easy Concurrency in Python(http://pljung.de/posts/easy-concurrency-in-python/)Adventures in Python with concurrent.futures(https://alexwlchan.net/2019/10/adventures-with-concurrent-futures/)
英文原文:https://rednafi.github.io/digressions/python/2020/04/21/python-concurrent-futures.html
译者:阿布铥











