
全文约4400字,建议阅读18分钟
本文为大家介绍了机器学习中常见的四种分类任务。分别是二分类、多类别分类、多标签分类、不平衡分类,并提供了实战代码。
标签:机器学习
机器学习是一个研究领域,其涉及到从示例中学习的算法。分类是一项需要使用机器学习算法去学习如何根据问题域为示例分配类标签的任务。一个简单易懂的例子是将电子邮件分为“垃圾邮件”或“非垃圾邮件”。在机器学习中,你可能会遇到许多不同类型的分类任务,并且每种模型都会使用专门的建模方法。在本教程中,您将了解机器学习中不同类型的分类预测建模。
在机器学习中,分类是指针对输入数据中的给定示例预测其类别标签的预测性建模问题。从建模的角度来看,分类需要一个训练数据集,其中包含许多可供学习的输入和输出示例。模型将会使用训练数据集并计算如何将输入数据映射到最符合的特定类别标签。因此,训练数据集必须具有一定代表性,并且每一个类别都应有许多的样本。类别标签通常是字符串,例如“垃圾邮件”,“非垃圾邮件”。必须先将类别标签映射为数值,然后才能用于建模算法。该过程通常称为标签的编码,标签编码将唯一的整数分配给每个类标签,例如“垃圾邮件” = 0,“非垃圾邮件” = 1。
对于分类预测建模问题进行建模,有许多不同类型的分类算法可供使用。关于如何对某一问题选择一个最合适的算法,目前没有很好的理论。反而我们通常建议相关人员通过受控试验来探究什么样的算法和算法配置在给定的分类问题上能实现最佳性能。分类模型的好坏通常用分类预测算法的结果进行评估。分类准确率是一种流行的度量标准,用于根据预测的类别标签评估模型的性能。分类准确率并不是完美的,但对于许多分类任务来说是一个很好的起点。某些分类任务可能会要求预测每个样本属于各个类别的概率而不是给出一个类别标签,对于应用程序或用户随后的预测而言,这增加了额外的不确定性。用于评估预测概率的常用方法是ROC曲线。
电子邮件垃圾邮件检测(是否为垃圾邮件)。
用户的流失预测(流失与否)。
用户的转化预测(购买或不购买)。
通常,二分类任务包含一个属于正常状态的类别和另一个属于异常状态的类别。例如,“非垃圾邮件”是正常状态,“垃圾邮件”是异常状态。另一个例子是“未检测到癌症”是医学测试任务的正常状态,而“检测到癌症”是异常状态。正常状态的类别分配为类别标签0,状态异常的类别分配为类别标签1。通常使用预测每个样本的伯努利概率分布的模型来对二分类任务进行建模。伯努利分布是一种离散概率分布,它包含了事件的二元结果,即要么为1,要么为0。对于分类问题,这种模型将预测样本属于“1”这种类别的概率,或者说是异常类别的概率。有些算法是专为二分类而设计的,它们本身并不支持两个以上的类别,例如逻辑回归和支持向量机。接下来,让我们通过数据集找到一些对二分类问题的直观感受。我们可以使用make_blobs()函数生成一个合成的二分类数据集。下面的例子生成一个包含1000个样本的数据集,这些样本属于两个类别之一,每个类具有两个输入特征。# example of binary classification task
from numpy import where
from collections import Counter
from sklearn.datasets import make_blobs
from matplotlib import pyplot
# define dataset
X, y = make_blobs(n_samples=1000, centers=2, random_state=1)
# summarize dataset shape
print(X.shape, y.shape)
# summarize observations by class label
counter = Counter(y)
print(counter)
# summarize first few examples
for i in range(10):
print(X[i], y[i])
# plot the dataset and color the by class label
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()
首先运行示例代码,对创建的数据集进行汇总并显示1000个示例分为输入(X)和输出(y)元素的数据集。然后这段代码将汇总类标签的分布,显示样本属于类0或类1,并且每个类中有500个示例。接下来,这段代码会为我们展示数据集中的前十个样本属于类0还是类1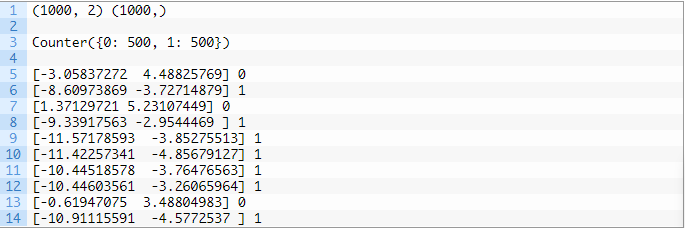
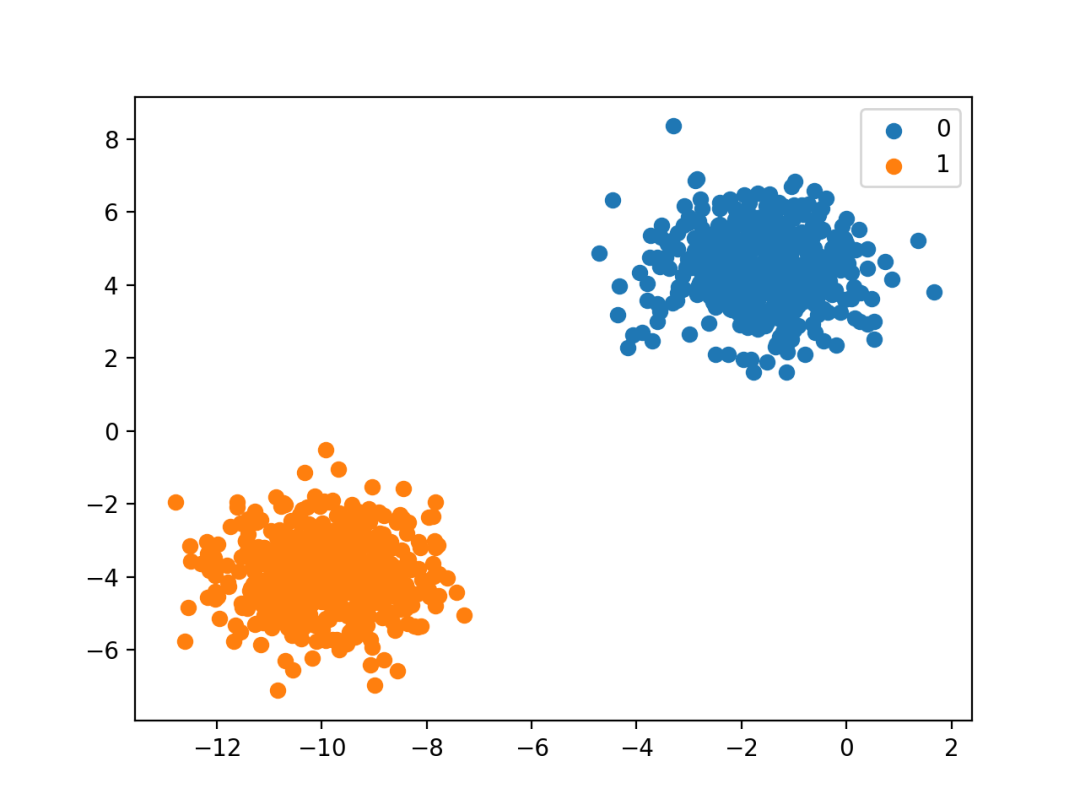
最后,使用数据集中的输入变量创建散点图,并根据每个点所属的类别对点进行着色。
与二分类不同,多分类没有正常和异常结果的概念。相反,样本被分类为属于一系列已知类别中的一个。在某些问题上,类标签的数量可能非常大。例如,模型可以预测照片属于脸部识别系统中成千上万的脸中的一个。涉及预测单词序列的问题,例如文本翻译模型,也可以视为一种特殊类型的多类别分类。要预测的单词序列中的每个单词都涉及一个多类别分类,其中词汇的大小定义了可以预测的类别数量,其大小可能是成千上万个单词。通常使用多元概率分布模型来对多类别分类任务进行建模。多元分布是一种离散概率分布,它包含的事件具有确定的分类结果,例如{1,2,3,…,K}中的K。对于这种分类任务,这意味着模型可以预测样本属于每个类别标签的概率。k最近邻算法。
决策树。
朴素贝叶斯。
随机森林。
梯度提升。
这涉及使用一种策略,该策略为每个类别与所有其他类别(称为“一对多”)拟合多个二分类模型,或者为每一对类别(称为“一对一”)拟合一个模型。
接下来,让我们通过数据集找到一些对于多分类问题的直观感受。我们可以使用make_blobs()函数生成一个合成的多分类数据集。下面的示例生成一个数据集,其中包含1,000个样本,这些样本属于三个类之一,每个类具有两个输入特征。
# example of multi-class classification task
from numpy import where
from collections import Counter
from sklearn.datasets import make_blobs
from matplotlib import pyplot
# define dataset
X, y = make_blobs(n_samples=1000, centers=3, random_state=1)
# summarize dataset shape
print(X.shape, y.shape)
# summarize observations by class label
counter = Counter(y)
print(counter)
# summarize first few examples
for i in range(10):
print(X[i], y[i])
# plot the dataset and color the by class label
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()
首先运行这段示例代码,它将会对创建的数据集进行汇总并显示1000个样本分为输入(X)和输出(y)元素的数据集。然后汇总的类标签的分布,显示样本属于类0,类1或类2,并且每个类中大约有333个样本。接下来,汇总数据集中的前10个样本,显示输入值是数字,目标值是对应类别的整数。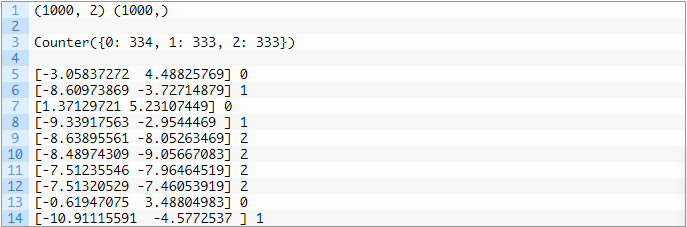
最后,为数据集中的输入变量创建散点图,并根据其类别对点进行着色。我们可以看到,正如我们所期望的,数据集被区分为三个不同的区域。多标签分类是指具有两个或以上分类标签的分类任务,其中每个样本可以预测为一个或多个类别。
考虑照片分类的示例,其中给定照片可能在场景中具有多个对象,并且模型可以预测照片中存在多个已知对象,例如“自行车”,“苹果”,“人”等。这与二分类和多分类不同,在二分类和多分类中,每个样本的预测只含有单个分类标签。通常使用预测多个输出的模型来对多标签分类任务进行建模,而每个输出都将作为伯努利概率分布进行预测。本质上,这是一个对每个样本进行多个二分类预测的模型。用于二分类或多分类的分类算法不能直接用于多标签分类。可以使用标准分类算法的专用版本,即所谓的算法的多标签版本,包括:另一种方法是使用单独的分类算法来预测每个类别的标签。接下来,让我们通过数据集找到一些对于多标签问题的直观感受。我们可以使用make_multilabel_classification()函数生成一个合成的多标签分类数据集。下面的例子生成一个包含1000个样本的数据集,每个样本都有两个输入特征。一共有三个类别,每个类别可能带有两个标签(0或1)之一。# example of a multi-label classification taskfrom sklearn.datasets import make_multilabel_classificationX, y = make_multilabel_classification(n_samples=1000, n_features=2, n_classes=3, n_labels=2, random_state=1)# summarize dataset shape# summarize first few examples首先运行这段示例代码,它会对创建的数据集进行汇总并显示1,000个样本分为输入(X)和输出(y)元素的数据集。接下来,汇总数据集中的前10个样本,显示输入值是数字,目标值是类别对应的整数。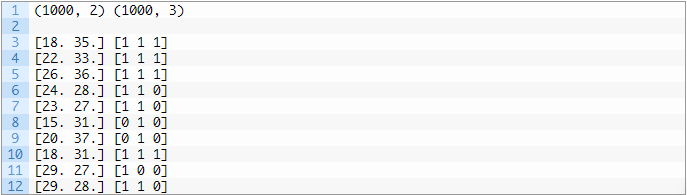
不平衡分类是指其中每个类别中的示例数不均匀分布的分类任务。通常,不平衡分类任务是二分类任务,其中训练数据集中的大多数样本属于正常类,而少数样本属于异常类。
这些问题在建模中被视为二分类任务,尽管可能需要专门的技术。可以使用专门的方法例如对多数类进行欠采样或对少数类进行过采样来更改训练数据集中样本的组成。在将模型拟合到训练数据集上时,可以使用专门的建模算法来采集少数类别的数据,例如成本敏感型机器学习算法。成本敏感的Logistic回归。
成本敏感的决策树。
成本敏感的支持向量机。
最后,由于分类报告的准确性可能会产生误导,因此可能需要其他性能指标。接下来,让我们通过数据集找到一些对于不平衡问题的直观感受。我们可以使用make_classification()函数生成一个合成的不平衡二分类数据集。下面的示例生成一个数据集,其中包含1000个样本,这些样本属于两类之一,每个类具有两个输入特征。# example of an imbalanced binary classification taskfrom collections import Counterfrom sklearn.datasets import make_classificationfrom matplotlib import pyplotX, y = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_classes=2, n_clusters_per_class=1, weights=[0.99,0.01], random_state=1)# summarize dataset shape# summarize observations by class label# summarize first few examples# plot the dataset and color the by class labelfor label, _ in counter.items():row_ix = where(y == label)[0]pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))首先运行这段示例代码,它会对创建的数据集进行汇总并显示1000个示例分为输入(X)和输出(y)元素的数据集。然后汇总类标签的分布,其显示出严重的类别不平衡,其中约980个样本属于类0,约20个样本属于类1。接下来,汇总数据集中的前10个样本,显示输入值是数字,目标值是类别对应的整数。在这种情况下,我们可以看到大多数样本都属于类0。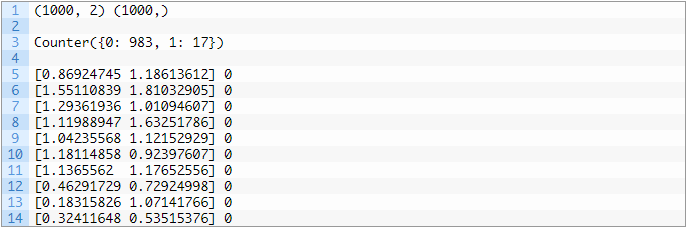
最后,为数据集中的输入变量创建散点图,并根据其类别对点进行着色。我们可以看到一个主要的聚类,其中包含属于类0的样本,还有一些零散的样本,属于类1。一般认为,具有这种不平衡类标签属性的数据集在建模时更具挑战性。 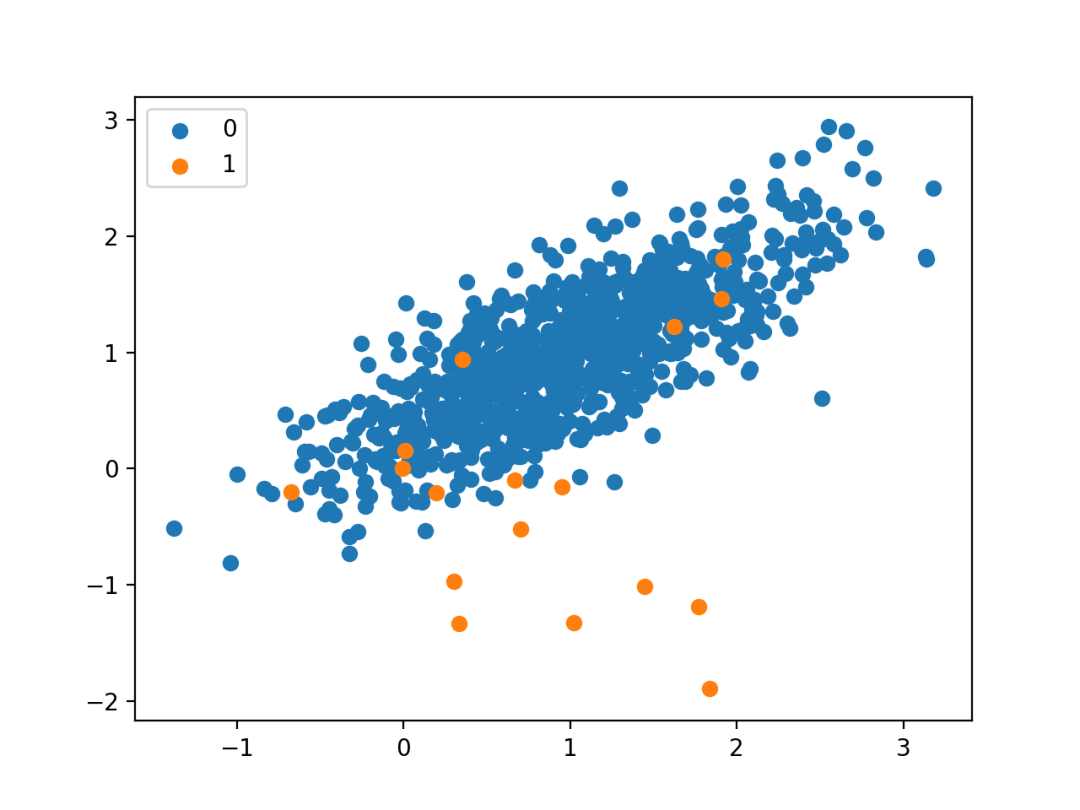
如果您想进行更深入了解,本节提供了更多的有关该主题的资源。https://en.wikipedia.org/wiki/Statistical_classification
https://en.wikipedia.org/wiki/Binary_classificationhttps://en.wikipedia.org/wiki/Multiclass_classificationhttps://en.wikipedia.org/wiki/Multi-label_classification多类别和多标签算法——scikit-learn API:https://scikit-learn.org/stable/modules/multiclass.html在本教程中,你了解到了机器学习中不同类型的分类预测建模。原文标题:
4 Types of Classification Tasks in Machine Learning
原文链接:
https://machinelearningmastery.com/types-of-classification-in-machine-learning/
如您想与我们保持交流探讨、持续获得数据科学领域相关动态,包括大数据技术类、行业前沿应用、讲座论坛活动信息、各种活动福利等内容,敬请扫码加入数据派THU粉丝交流群,红数点恭候各位。
陈丹,复旦大学大三在读,主修预防医学,辅修数据科学。对数据分析充满兴趣,但初入这一领域,还有很多很多需要努力进步的空间。希望今后能在翻译组进行相关工作的过程中拓展文献阅读量,学习到更多的前沿知识,同时认识更多有共同志趣的小伙伴!
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。








