
题图是书的封面(大陆和台湾)
读过我文章或听过我课的朋友也应该知道我喜欢按以下四个理念讲东西:
体系化,故事化,可视化,抽象化
体系化(systematize)可以把握全局
故事化(dramatize)可以引人入迷
可视化(visualize)可以增强记忆
抽象化(generalize)可以认清本质
下面配着「快乐机器学习」一书,来讲讲上面“四个化”。

将零碎的知识点体系化真的很重要,机器学习的基本要点都总结在一张思维脑图里了。

机器学习包含四个元素:
数据 (Data)
任务 (Task)
性能度量 (Quality Metric)
模型 (Model)
数据包括结构化和非结构化数据:
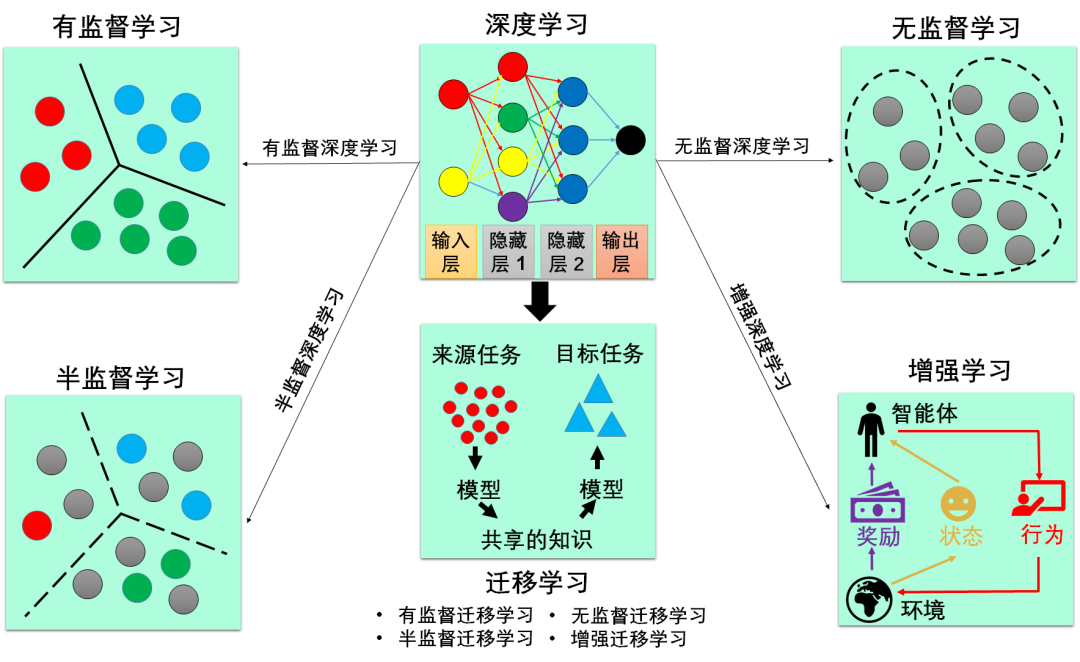
根据学习的任务模式 (训练数据是否有标签),机器学习可分为四大类:
有监督学习 (有标签)
无监督学习 (无标签)
半监督学习 (有部分标签)
增强学习 (有评级标签)
高度概括一下:
有监督学习的目标是推广 (generalize)
无监督学习的目标是压缩 (compress)
半监督学习是前两者的混合
增强学习的目标是反应 (act)
深度学习只是一种方法,而不是任务模式,因此与上面四类不属于同一个维度,但是深度学习与它们可以叠加成:深度有监督学习、深度非监督学习、深度半监督学习和深度增强学习。迁移学习也是一种方法,也可以分类为有监督迁移学习、非监督迁移学习、半监督迁移学习和增强迁移学习。
本书主要讲监督式学习,其下的回归和分类任务里最常见的误差函数以及一些有用的性能度量如下。

模型见下图的下半部分。
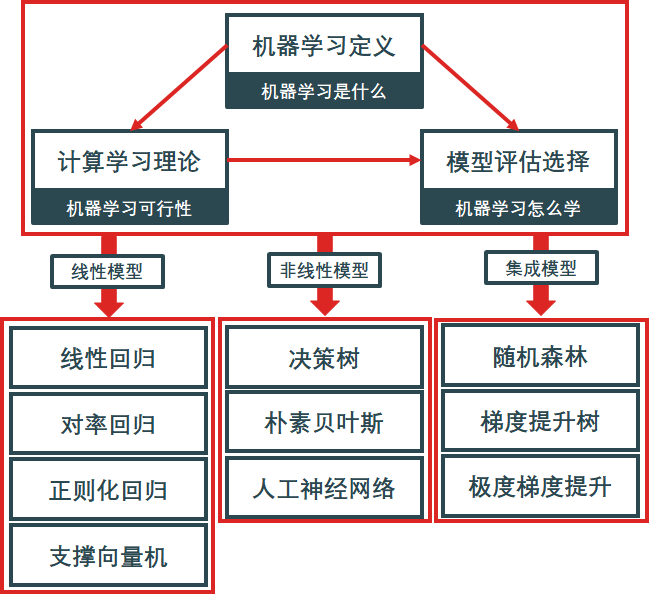
学习并精通一门学科无外乎要经过四个步骤:它是什么?它可行吗?怎么学它?如何学好它?学习机器学习也不例外,本书就以这四个步骤来解读机器学习。
第 1 章介绍“机器学习是什么”,即从定义开始,详细介绍机器学习涉及的知识、数据和性能度量。
第 2 章介绍“机器学习可行吗”,即机器具备学习样本以外的数据的能力。本章从概率的角度证明样本内误差和样本外误差的关系。
第 3 章介绍“机器学习怎么学”,即机器如何选出最优模型。本章介绍机器学习版本的样本内误差(训练误差)和样本外误差(测试误差),再通过验证误差来选择模型。
前 3 章属于机器学习的概述:第 1 章介绍机器学习的概念,为了让读者打好基础;第 2 章为证明机器学习是可行的,让读者做到心中有数;第 3 章运用机器学习性能指标而构建框架,看懂它们不需要精通任何机器学习的算法。作者在这 3 章的写作上花费的时间最多,光这 3 章的内容就绝对让读者有所收获。
第 4 ~14 章介绍“如何学好机器学习”,重点介绍机器学习的各类算法和调参技巧。在本书中,机器学习模型分为线性模型、非线性模型和集成模型。
第 4 ~ 8 章 介绍线性模型,包括线性回归模型、对率回归模型、正则化回归模型、支持向量机模型。
第 9 ~11 章介绍非线性模型,包括朴素贝叶斯模型、决策树模型、人工神经网络模型、正向/反向传播模型。
第 12 ~14 章介绍集成模型,包括随机森林模型、提升树模型、极度梯度提升模型。
第 15 章介绍机器学习中一些非常实用的经验,包括学习策略、目标设定、误差分析、偏差和方差分析。
体系化可以把握全局
生动的故事总是比枯燥的陈述更能让人感兴趣,下面拿随机森林来举例。
故事开始
挑剔的王妮梅搞砸了妈妈给她安排的与 40 位不同男士的约会,妈妈又给她介绍了 20 位男士。妮梅很苦恼,失败了这么多次,她开始怀疑自己对男士做出“见或不见”的判断标准不准确了。这时,她向她的好朋友刘舒求助。

刘舒(柳树)是判断妮梅应该见谁的一棵决策树(Decision Tree)。但刘舒并不能总是很好地概括妮梅的喜好,并且提的问题不全面。为了获得更准确的建议,妮梅去询问其他朋友自己应该见哪一位?结果,所有人都认为妮梅应该见 X 先生。妮梅的朋友叫宋舒(松树)、杨舒(杨树)和佰舒(柏树),他们组成了判断妮梅应该见谁的一片森林(Forest)。
现在,妮梅不想让她的每个朋友都做同样的事情,给出一样的答案,所以,妮梅决定给宋舒、杨舒和佰舒的数据与给刘舒的数据不一样,她在数据中随机加一些轻微的干扰项。而且有时候,妮梅也并不完全确定自己的喜好。

妮梅不会改变自己的喜好,只会加一些“很”“超级”“非常”之类的感情色彩词。这时,妮梅给每个朋友的是原始数据的自助采样(Bootstrap)版本。妮梅希望朋友们能给她一些相互独立的建议。比如,刘舒觉得妮梅喜欢 X 和 Z 先生,宋舒觉得妮梅喜欢 X 和 Y 先生,而杨舒觉得妮梅讨厌所有人。其中可能产生的误判会在他们一起投票时相互抵消。现在他们组成了判断妮梅应该见谁的一片随机森林(Random Forest)。
虽然妮梅喜欢 X 和 Y 先生,但并不是因为他们都是对冲基金经理,也许另有原因。因此,妮梅不希望她的朋友们都根据“收入”这个条件而提出建议,她限制每个朋友提的问题。

以前妮梅在数据层面注入随机性(轻微改变自己对男生的喜好),现在她在问题层面注入随机性(让她的朋友们提出不同的问题)。现在她的朋友们组成了判断妮梅应该见谁的一片更为随机的随机森林。
最终,妮梅拿到所有人对这 20 位男士的建议,再根据自己对这些朋友的信任度和品位,在他们的建议上加一个权重。例如妮梅信任刘舒多一些,就多注重他的建议,信任杨舒少一些,就少注重他的建议。这种结合方式类似于提升法里的非均匀结合法。

上式中权重越大,字体越大 
现在我相信即便你还不太懂随机森林模型,但也能大概了解它是做什么的了 - 它能够降低预测的方差。
这样你们学起来会很轻松,但对我而言就要下很大功夫,但是我愿意。
故事化可以引人入迷
一图胜千言,人是感官动物,从图表中接收的信息速度绝对比从文字快。
在学习集成模型时,有装袋法(bagging)、提升法(boosting)和堆积法(stacking)。
看着上面的文字是不是感觉一头雾水,但如果配着下面的图呢?
装袋法概念图

要点:并联结合
提升法概念图

要点:串联结合
堆积法概念图
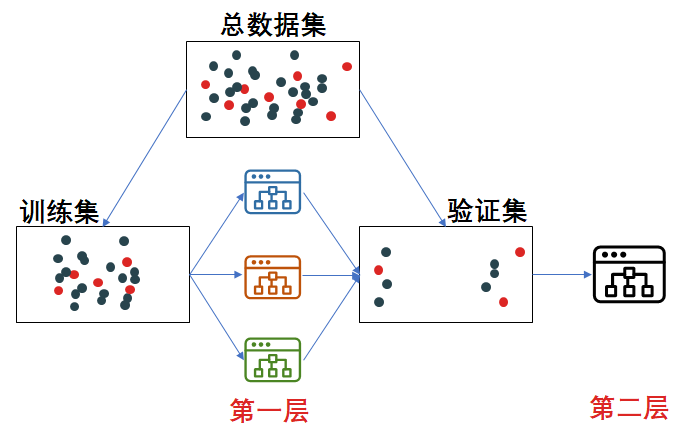
要点:分堆结合
具体而言,与装袋法“最后通过投票或者求平均值来结合所有学习器的预测”不同,堆积法通过训练一个学习器(元学习器,Meta Learner)来完成这个结合。
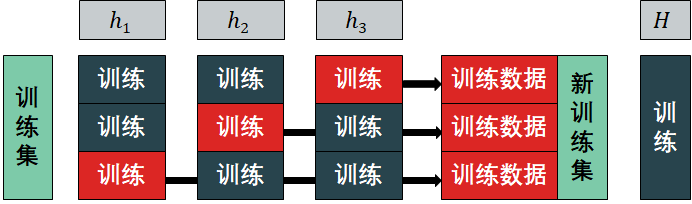
堆积法有三个核心步骤
训练一级分类器:首先将训练数据分为 3 份:D1, D2, D3。h1 在 D1 和 D2 上训练,h2 在 D1 和 D3 上训练,h3 在 D2 和 D3 上训练。
新训练数据:包含 h1 在 D3 上的输出,h2 在 D2 上的输出,h3 在 D1 上的输出。
训练二级分类器:通过新训练数据和对应的标签,训练出第二级分类器 。
从具体问题能抽出本质是一种很重要的能力,人一旦会举一反三才算会学习。
拿支持向量机(SVM)举例
这些知识点都是零散的,但拉格朗日方法连接着原始问题和对偶问题,空间转换通过提升维度将线性重度不可分转成线性轻度不可分,然后高维空间的计算量太大,又需要核技巧来提高效率。
通过抽象化总结出下图,将所有 SVM 的知识点连起来,融会贯通。

抽象化可以认清本质
我就喜欢用框架总结,抓住重点
我就喜欢用故事类比,妙趣横生
我就喜欢用图表剖析,简单易懂
我就喜欢用通式归纳,举一反三
如果你同意我上面说的「体系化、故事化、可视化、抽象化」理念,看过并喜欢我的文章,那么可以买一本看看,现在京东上有活动,扫以下二维码去买书满 100 返 50。

最后献上本书的前言,飨你








