
作者:博观厚积
简书专栏:
https://www.jianshu.com/u/2f376f777ef1
01 logisitic回归与梯度下降法
logisitic回归是因变量是分类的回归模型或算法,它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别),所以利用了Logistic函数(或称为Sigmoid函数),函数形式为:
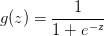
其中:
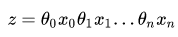
向量表示为:
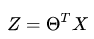
梯度下降法则是一种最优化算法,它是用迭代的方法求解目标函数得到最优解,是在最小二乘法cost function(成本函数)的基础上,利用梯度迭代求出局部最优解。在这里关于梯度下降法不做过多介绍,相关资料已经很多且后边还会分析,对其的理解借用一位网友的描述吧:
梯度下降法被比喻成一种方法,一个人蒙着眼睛去找从山坡到溪谷最深处的路。 他看不到地形图,所以只能沿着最陡峭的方向一步一步往前走。每一步的大小(也就是梯度)与地势陡峭的程度成正比。 如果地势很陡峭,他就走一大步,因为他相信他仍在高出,还没有错过溪谷的最低点。如果地势比较平坦,他就走一小步。这时如果再走大步,可能会与最低点失之交臂。 如果真那样,他就需要改变方向,重新朝着溪谷的最低点前进。 他就这样一步一步的走啊走,直到有一个点走不动了,因为路是平的了,于是他卸下眼罩,已经到了谷底深处。
02 用梯度下降法求解logisitic回归
用梯度下降法求解logisitic回归的步骤为:
(1)构建损失函数
预测函数为:
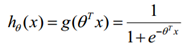
函数hθ(x)的值有特殊的含义,它表示结果取1的概率,因此对于输入x分类结果为类别1和类别0的概率分别为:
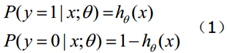
(1)式综合起来可以写成:
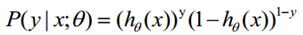
取似然函数为:

对数似然函数为:
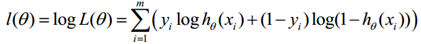
最大似然估计就是求使l(θ)取最大值时的θ,将J(θ)取为下式,即:

因为乘了一个负的系数-1/m,所以取J(θ)最小值时的θ为要求的最佳参数。
注:在这里为什么加了个系数-1/m,编者翻阅了相关资料,因为不加的话,说是不能用梯度下降法(而是梯度上升法),所以要加负号,而1/m代表了样本平均。
最终得到:

(2)梯度下降法求解最小值
采用与线性回归中一样的梯度下降法来确定θ的值,即设置一个合适的学习率α之后,同步更新所有j=1 to n:
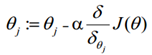
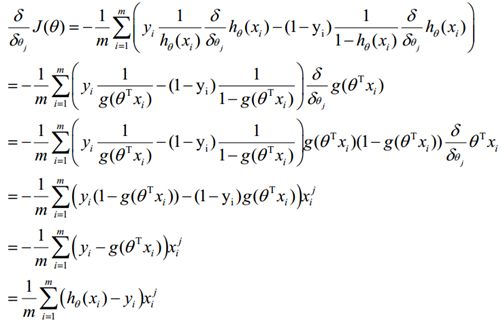
θ更新过程可以写成:
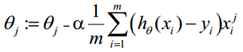
重复更新步骤,直到损失函数的值收敛为止。
03 python代码的实现
在这里采用了python2.7 版本,并分为两大步骤:构建梯度下降法函数与创建数据函数。而经过上面的推导,对我们编程最有用的不是那些过程,而是得到的结果,即最后一个公式,因此,将围绕最后得到的梯度下降法求解公式来构建函数。
-*- coding: UTF-8 -*-
import numpy as np #科学计算(矩阵)包
import random #生成随机数的包
#梯度下降算法函数,x/y是输入变量,theta是参数,alpha是学习率,m是实例,numIterations梯度下降迭代次数
def gradientDescent(x, y, theta, alpha, m, numIterations):
xTrans = x.transpose() #矩阵转置
#在1-numIterations之间for循环
for i in range(0,numIterations):
hypothesis = np.dot(x,theta) #矩阵相乘
loss = hypothesis - y #预测值减去实际值
# avg cost per example (the 2 in 2*m doesn't really matter here.
# But to be consistent with the gradient, I include it)
cost = np.sum(loss **2)/(2 * m)
#成本函数:loss方差的平均加总,在这里采用了常用的成本函数,而非logistic特有的
print("Iteration %d | Cost: %f" % (i, cost))
# avg gradient per example
gradient = np.dot(xTrans, loss) / m #计算梯度
# update
theta = theta - alpha * gradient #参数theta的计算,即更新法则
return theta
#创建数据,numPoints实例数,bias加一些偏倚或偏差,variance:方差
def genData(numPoints,bias,variance):
x = np.zeros(shape=(numPoints,2)) #生成0矩阵,shape表示矩阵的形状,参数1是行,后边是列
y = np.zeros(shape=(numPoints))
#对x、y的0矩阵填充数值
for i in range(0,numPoints):
x[i][0] = 1 #第i行第1列全部等于1
x[i][1] = i # 第i行第2列等于i
y[i] = (i + bias) + random.uniform(0,1) * variance # 第i行第2列等于i+bias(偏倚),再加,0-1的随机数,以及方差
return x, y
x, y = genData(100, 25, 10) #传入参数
print "x:"
print x
print "y:"
print y
m, n = np.shape(x) #检查x的行列数,是否一致
numIterations = 100000
alpha = 0.0005 #学习率,不能太大也不能太小
theta = np.ones(n) #初始化
theta = gradientDescent(x, y, theta, alpha, m, numIterations)
print(theta)
可以根据不同的数据,利用gradientDescent()函数来求解。
赞赏作者

Python爱好者社区福利大放送!!!
扫码或者点击阅读原文,领取福利

扫码或者点击阅读原文,领取福利








