本文的目标读者是想快速掌握矩阵、向量求导法则的学习者,主要面向矩阵、向量求导在机器学习中的应用。因此,本教程而非一份严格的数学教材,而是希望帮助读者尽快熟悉相关的求导方法并在实践中应用。另外,本教程假定读者熟悉一元函数的求导。
本文公式太多,微信上展示会有一些问题。所以本文适合读者了解矩阵、向量求导,而详细地学习与分析请下载本文的PDF版。
PDF 下载地址:https://pan.baidu.com/s/1pKY9qht
所谓矩阵求导,本质上只不过是多元函数求导,仅仅是把把函数的自变量以及求导的结果排列成了矩阵的形式,方便表达与计算 而已。复合函数的求导法则本质上也是多元函数求导的链式法则,只是将结果整理成了矩阵的形式。只是对矩阵的每个分量逐元素 地求导太繁琐而且容易出错,因此推导并记住一些常用的结论在实践中是非常有用的。
矩阵求导本身有很多争议,例如:
不同教材对此处理的结果不一样,这属于不同的 Layout Convention。本文以不转置为主,即求导结果与原矩阵/向量同型,术语叫 Mixed Layout。
最自然的结果当然是把结果定义成三维乃至四维张量,但是这并不好算。也有一些绕弯的解决办法 (例如把矩阵抻成一个 向量等),但是这些方案都不完美 (例如复合函数求导的链式法则无法用矩阵乘法简洁地表达等)。在本教程中,我们认为,这三种情形下导数没有定义。凡是遇到这种情况,都通过其他手段来绕过,后面会有具体的示例。
因此,本教程的符号体系有可能与其他书籍或讲义不一致,求导结果也可能不一致 (例如相差一次矩阵转置,或者是结果矩阵是否平铺成向量等),使用者需自行注意。另外,本教程中有很多笔者自己的评论,例如关于变形的技巧、如何记忆公式、如何理解其他的教程中给出的和本教程中形式不同的结果等。
文中如有错漏,欢迎联系 ruanchong_ruby@163.com,我会尽快订正。
符号表示
标量用普通小写字母或希腊字母表示,如  等。
等。
向量用粗体小写字母或粗体希腊字母表示,如 x 等,其元素记作 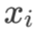 (注意这里
(注意这里 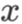 没有加粗。加粗的小写字母加下标,例如
没有加粗。加粗的小写字母加下标,例如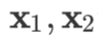 等,表示这是两个不同的常数向量)。向量默认为列向量,行向量需要用列向量的转置表示,例如
等,表示这是两个不同的常数向量)。向量默认为列向量,行向量需要用列向量的转置表示,例如 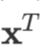 等。
等。
矩阵用大写字母表示,如A 等,其元素记作 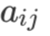 (注意这里 a 用的是小写字母。大写字母加下标,例如
(注意这里 a 用的是小写字母。大写字母加下标,例如
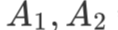 等,表示不同 的常数矩阵)。
等,表示不同 的常数矩阵)。
用字母表中靠前的字母 (如 a,b,c等) 表示常量,用 f,g,h 或字母表中靠后的字母 (如u,v等)等表示变量或函数。
有特殊说明的除外。
综上所述,本文进行如下约定:
劈形算子 :
:
对上述约定的理解
变量多次出现的求导法则
规则:若在函数表达式中,某个变量出现了多次,可以单独计算函数对自变量的每一次出现的导数,再把结果加起来。
这条规则很重要,尤其是在推导某些共享变量的模型的导数时很有用,例如 antoencoder with tied weights(编码和解码部分的权重矩阵互为转置的自动编码器)和卷积神经网络(同一个 feature map 中卷积核的权重在整张图上共享)等。
举例(该规则对向量和矩阵也是成立的,这里先用标量举一个简单的例子):假设函数表达式是 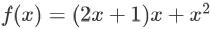 ,可以先把三个 x 看成三个不同的变量,即把 f 的表达式看成
,可以先把三个 x 看成三个不同的变量,即把 f 的表达式看成 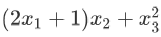 ,然后分别计算
,然后分别计算 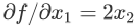 ,
, 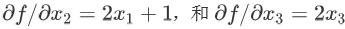 ,最后总的导数就是这三项加起来:
,最后总的导数就是这三项加起来: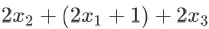 ,此时再把 x 的下标抹掉并化简,就得到 6x+1。熟悉这个过程之后,可以省掉添加下标再移除的过程。
,此时再把 x 的下标抹掉并化简,就得到 6x+1。熟悉这个过程之后,可以省掉添加下标再移除的过程。
如果用计算图(computation graph,描述变量间依赖关系的示意图,后面会举例)的语言来描述本条法则,就是:若变量 x 有多条影响函数 f 的值的路径,则计算 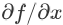 时需要对每条路经求导最后再加和。 如果想更多地了解计算图和反向传播,推荐阅读 [Colah 君的文章](http://colah.github.io/posts/2015-08-Backprop/)。其中详细讲述了计算图如何工作,不仅讲反向传播还讲了前向传播(前向传播对于目前的机器学习算法来说似乎没有太大的用处,但是对于加深计算图的理解很有帮助。RNN 有一种学习算法叫 RTRL 就是基于前向传播的,不过近年来不流行了)。
时需要对每条路经求导最后再加和。 如果想更多地了解计算图和反向传播,推荐阅读 [Colah 君的文章](http://colah.github.io/posts/2015-08-Backprop/)。其中详细讲述了计算图如何工作,不仅讲反向传播还讲了前向传播(前向传播对于目前的机器学习算法来说似乎没有太大的用处,但是对于加深计算图的理解很有帮助。RNN 有一种学习算法叫 RTRL 就是基于前向传播的,不过近年来不流行了)。
有了上面的基础,我们就可以推导 Batch normalization(以下简称 BN)的求导公式了。 BN 的计算过程为:

其中 m 是批的大小,x_1 到 x_m 分别是 m 个不同样本对于某个神经元的输入,l 是这个批的总的损失函数,所有变量都是标量。求导的第一步是画出变量依赖图,如下所示(根据左边的变量可以计算出右边的变量,如果为了强调,也可以在边上添加从左向右的箭头):
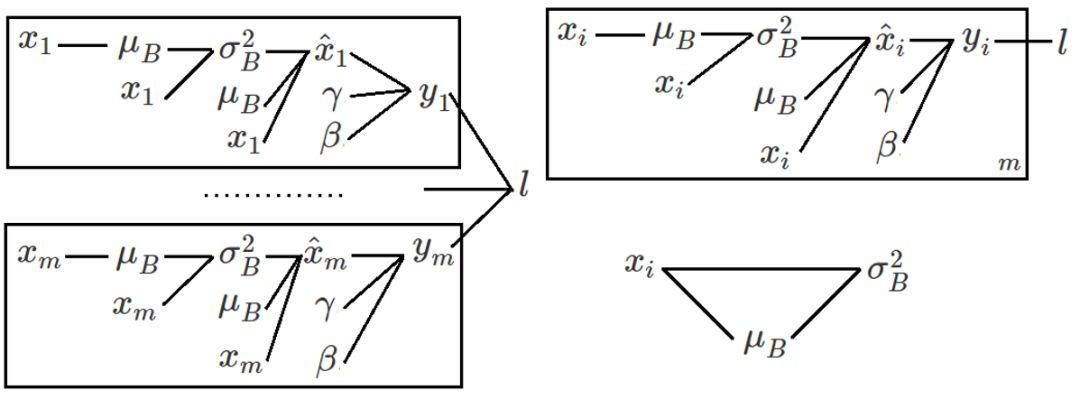
左侧,右上,右下分别是三种不同的画法(读者也可以尝试其他的画法):左边的图是把所有变量 x_i 都画了出来,比较清楚,如果想不清楚变量之间是如何相互依赖的,这样画可以帮助梳理思路;右上是我自创的一种方法,借鉴了概率图模型中的盘记号(plate notation),把带下标的变量用一个框框起来,在框的右下角指明重复次数;右下我只画了一个局部,只是为了说明在有些资料中,相同的变量(如本例中的  )只出现一次,而非像左图那样出现多次,从而图中会出现环。不过要不要复制同一个变量的多个拷贝没有本质的区别。在右下这种表示法中,如果要求 partial σ^2 除以 partial x_i,需要对
)只出现一次,而非像左图那样出现多次,从而图中会出现环。不过要不要复制同一个变量的多个拷贝没有本质的区别。在右下这种表示法中,如果要求 partial σ^2 除以 partial x_i,需要对 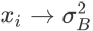 和
和 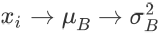 这两条路径求导的结果做加和。(事实上,这种带下标的画法有点儿丑,因为我们现在的计算图里的变量都是标量……如果用 X 表示
这两条路径求导的结果做加和。(事实上,这种带下标的画法有点儿丑,因为我们现在的计算图里的变量都是标量……如果用 X 表示 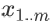 组成的向量,计算图会更简洁,看起来更舒服。不过这种丑陋的表示对于我们现在的目的已经够用了。 )
组成的向量,计算图会更简洁,看起来更舒服。不过这种丑陋的表示对于我们现在的目的已经够用了。 )
BN 原论文中也给出了反向传播的公式,不过我们不妨试着自己手算一遍:
常用公式
向量求导的链式法则
易发现雅克比矩阵的传递性:若多个向量的依赖关系为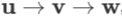 ,则:
,则:
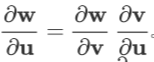
证明:只需逐元素求导即可。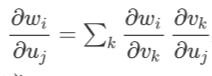 ,即
,即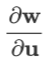 的
的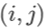 元等于矩阵
元等于矩阵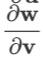 的 i 行 和 矩阵
的 i 行 和 矩阵 的第 j 列的内积,这正是矩阵乘法的定义。
的第 j 列的内积,这正是矩阵乘法的定义。
注:将两项乘积的和转化成向量内积或矩阵相乘来处理,是很常用的技巧。
雅克比矩阵的传递性可以很容易地推广到多层中间变量的情形,采用数学归纳法证明即可。
若中间变量都是向量,但最后的结果变量是一个实数,例如变量依赖关系形如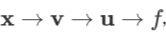 ,则:
,则:
由雅克比矩阵的传递性知:

再根据 f 退化时雅克比矩阵和函数导数的关系,有:
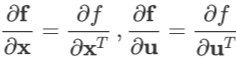
以上三式相结合,可以得到如下链式法则:
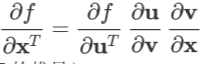
上面的结果显然也可以推广到任意多层复合的情形(可用于 RNN 的 BPTT 的推导)。
上面的公式是把导数视为行向量(即以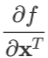 和
和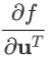 的形式)给出的。如果需要把导数视为列向量,只需将公式两边同时转置即可。由于实践中复合一次的情形较常用,这里只给出将变量视为列向量时复合一次的公式:
的形式)给出的。如果需要把导数视为列向量,只需将公式两边同时转置即可。由于实践中复合一次的情形较常用,这里只给出将变量视为列向量时复合一次的公式:
若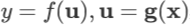 ,则:
,则:
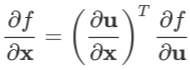
或写作
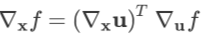 。
。
这里再给出一个特例:若变量依赖关系为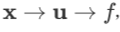 ,u 和x 维度相同且
,u 和x 维度相同且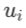 仅由
仅由
计算出而与 x 的其他分量无关,则易知 是对角阵,所以上面的公式可以化简为:
是对角阵,所以上面的公式可以化简为:
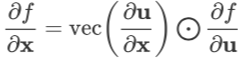
其中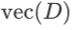 表示取对角矩阵 D 的对角线上的元素组成列向量,
表示取对角矩阵 D 的对角线上的元素组成列向量, 表示两个向量逐元素相乘。
表示两个向量逐元素相乘。
由于最终的结果是两个向量逐元素相乘,所以也可以交换一下相乘的顺序,写成:

本条规则在神经网络中也很常用,常见的情形包括但不限于:逐元素地应用激活函数
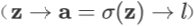 ,以及现代 RNN 单元中的门限操作(以 LSTM 为例:
,以及现代 RNN 单元中的门限操作(以 LSTM 为例:
 。
。
* 因为依赖关系简单,本公式也可以直接根据导数逐分量的定义直接推出来:
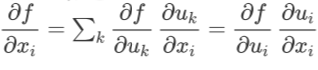
此即前述公式的分量形式。
记忆:只需记住结果是一堆雅克比矩阵的乘积,相乘的顺序根据维度相容原则调整即可(假设每个中间变量的维度都不一样,看怎么摆能把雅克比矩阵的维度摆成矩阵乘法规则允许的形式。只要把矩阵维度倒腾顺了,公式也就对了。)
注:网络上各种资料质量参差不齐,在其他教程中时常会见到向量对矩阵求导的表达式。例如介绍 RNN 的梯度消失问题的文章中,经常会见到 这种式子。如果文中出现这个式子是定性的,只是为了说明链式法则中出现了很多连乘项导致了梯度消失,那么读者也只需定性地理解即可。如果文中出现这个式子是定量的,是为了推导反向传播的公式,那么笔者建议读者用如下两种方式之一理解:
这种式子。如果文中出现这个式子是定性的,只是为了说明链式法则中出现了很多连乘项导致了梯度消失,那么读者也只需定性地理解即可。如果文中出现这个式子是定量的,是为了推导反向传播的公式,那么笔者建议读者用如下两种方式之一理解:
其一是把 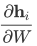 理解成一种简写形式:先把 W 抻成一个向量,然后公式中的每一个雅克比矩阵就都可以计算了,最后再把结果向量重新整理成 W 的同型矩阵。但是这种方法非常复杂,因为把 W 抻成向量以后目标函数关于 W 的表达式就变了,很难推导 这个雅克比矩阵。一个具体的算例见《Optimizing RNN performance》(https://svail.github.io/rnn_perf/)一文中最后的推导。(如果你不打算熟练掌握这种方法,只浏览一下看看大意即可。相信我,如果你学了本文中的方法,你不会再想用这种把矩阵抻开的方法求导的。)
理解成一种简写形式:先把 W 抻成一个向量,然后公式中的每一个雅克比矩阵就都可以计算了,最后再把结果向量重新整理成 W 的同型矩阵。但是这种方法非常复杂,因为把 W 抻成向量以后目标函数关于 W 的表达式就变了,很难推导 这个雅克比矩阵。一个具体的算例见《Optimizing RNN performance》(https://svail.github.io/rnn_perf/)一文中最后的推导。(如果你不打算熟练掌握这种方法,只浏览一下看看大意即可。相信我,如果你学了本文中的方法,你不会再想用这种把矩阵抻开的方法求导的。)
其二是把最后一项分母中的 W 理解成矩阵 W 中的任一个元素 w_ij,从而上述表达式中的四项分别是向量(此处看作行向量)、矩阵、矩阵、向量(列向量),从而该表达式可以顺利计算。但是这也很麻烦,因为得到的结果不是直接关于 W 的表达式,而是关于其分量的,最后还要合并起来。
其他理解方式,恕我直言,基本上都是作者自己就没弄懂瞎糊弄读者的。
实值函数对向量求导
未作特殊说明即为对变量 x 求导。
几个基本的雅克比矩阵:
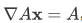 ,特别地,
,特别地,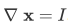 。
。
向量内积的求导法则:
这是最基本的公式,正确性是显然的,因为 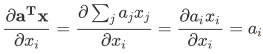 。
。
向量内积的求导法则: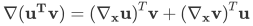
向量数乘求导公式
矩阵迹求导

推导:利用变量多次出现的求导法则:
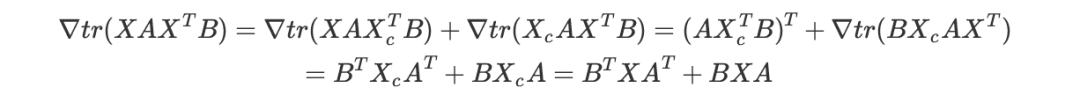
(X_c 表示将 X 的此次出现视作常数)
大部分都是上述核心公式的简单推论,不必强记
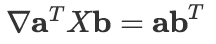
行列式的求导公式:
矩阵求导的链式法则
设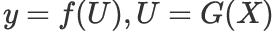 ,则:
,则:
设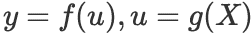 ,则:
,则: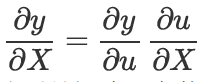 (等式右边是实数和矩阵的数乘)
(等式右边是实数和矩阵的数乘)
向量的线性变换是上式的退化情形,即:
向量的线性变换还可以求二阶导:
其他公式
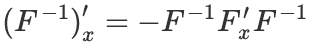
常见技巧及注意事项
实数在与一堆矩阵、向量作数乘时可以随意移动位置。且实数乘行向量时,向量数乘与矩阵乘法(1x1 矩阵和 1xm 矩阵相乘)的规则是一致的。
遇到相同下标求和就联想到矩阵乘法的定义,即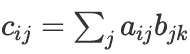 。特别地,一维下标求和联想到向量内积
。特别地,一维下标求和联想到向量内积 ,二维下标求和联想到迹
,二维下标求和联想到迹 (A,B 应为同型矩阵)。
(A,B 应为同型矩阵)。
如果在一个求和式中,待求和项不是实数而是矩阵的乘积,不要想着展开求和式,而要按照上面的思路,看成分块矩阵的相乘!
向量的模长平方(或实数的平方和)转化为内积运算: 。矩阵的 F 范数的平方转化为迹运算:
。矩阵的 F 范数的平方转化为迹运算: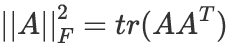 。
。
-
多个矩阵相乘时,多用矩阵迹的求导公式转化、循环移动各项。实数也可看成 1X1 矩阵的迹!
需要用到向量(或矩阵)对矩阵求导的情形,要么把矩阵按列拆开转化成向量对向量求导(最终很有可能通过分块矩阵乘法再合并起来。本文后面的算例 PRML(3.33) 说明了这种方法怎么用),要么套用线性变换的求导公式(常见于神经网络的反向传播过程)。
算例
最小二乘法
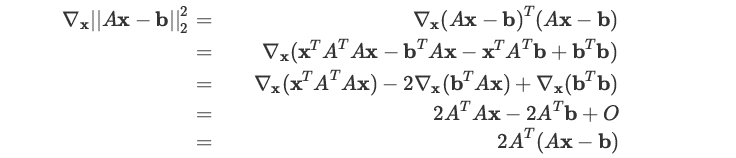
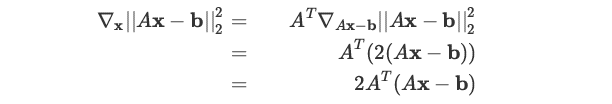
F 范数的求导公式推导
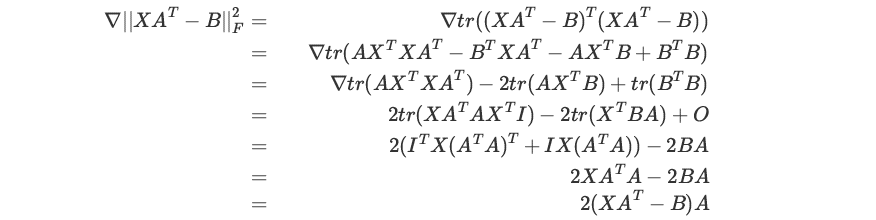
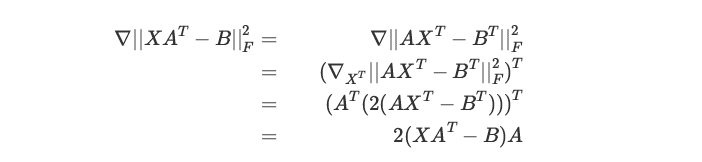
PRML (3.33) 求导
求 关于 W 的导数。
关于 W 的导数。
说明:上面的  的结果应当是一个向量,但是希腊字母打不出加粗的效果。
的结果应当是一个向量,但是希腊字母打不出加粗的效果。

上述几步的依据分别是:
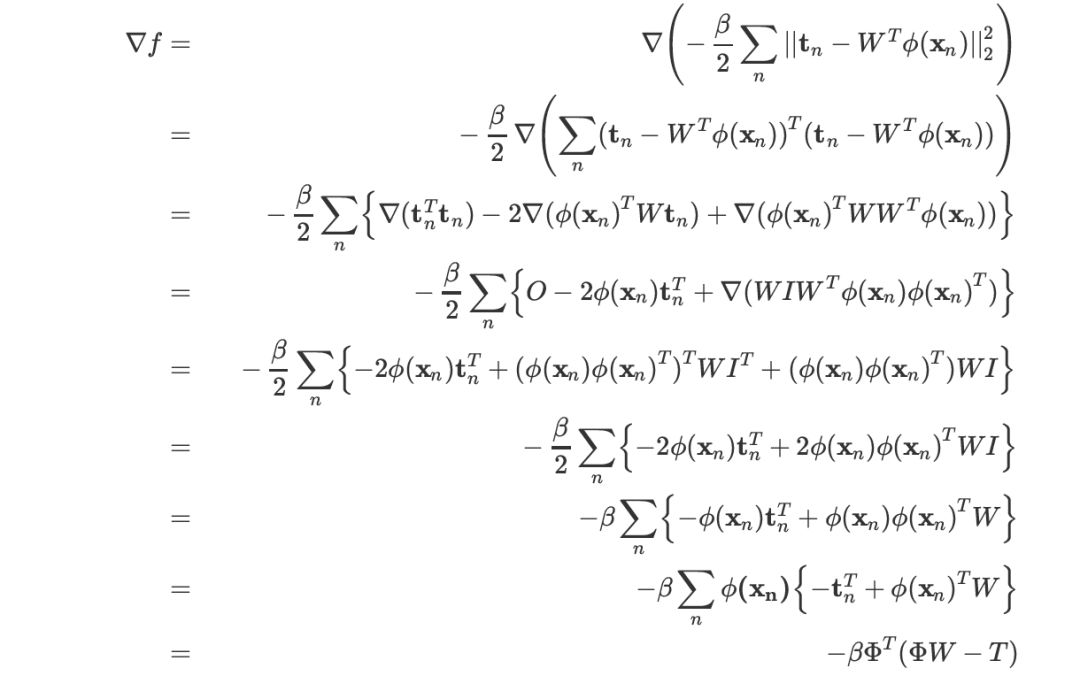
最后一步的化简的思考过程是把对 n 求和视为两个分块矩阵的乘积:
第一个矩阵是分块行向量,共 1xN 个块,且第 n 个分量是。因此第一个矩阵是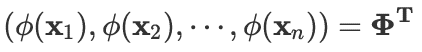
第二个矩阵是分块列向量,共 Nx1 个块,且第 n 个分量是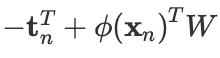 。因此,第二个矩阵是:
。因此,第二个矩阵是:
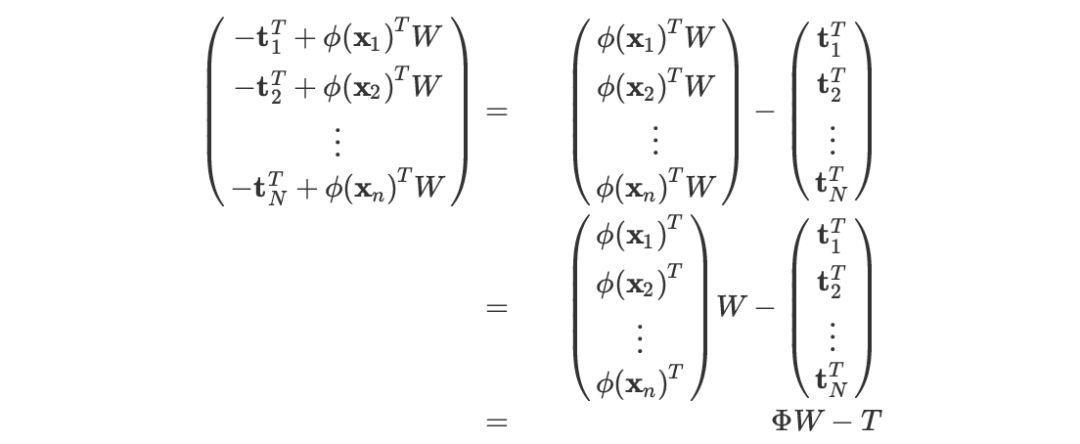
,注意第二个等号的推导过程中,前一项能够拆开是因为它被看做两个分块矩阵的乘积,两个分块矩阵分别由 Nx1和 1x1 个块组成。
这种方法虽然比较繁琐,但是更具有一般性。
RNN 的梯度消失爆炸问题
Autoencoder with Tied-weight
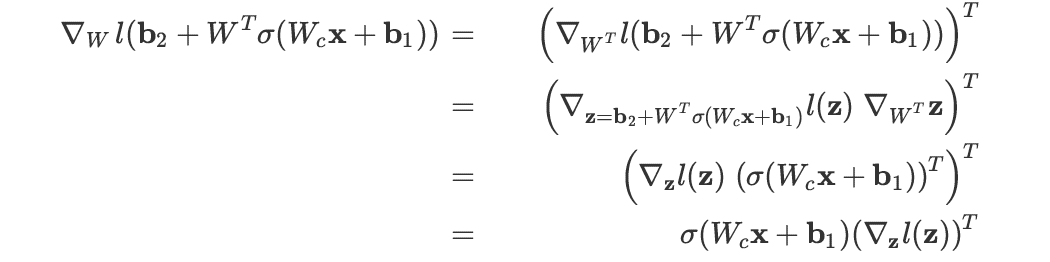
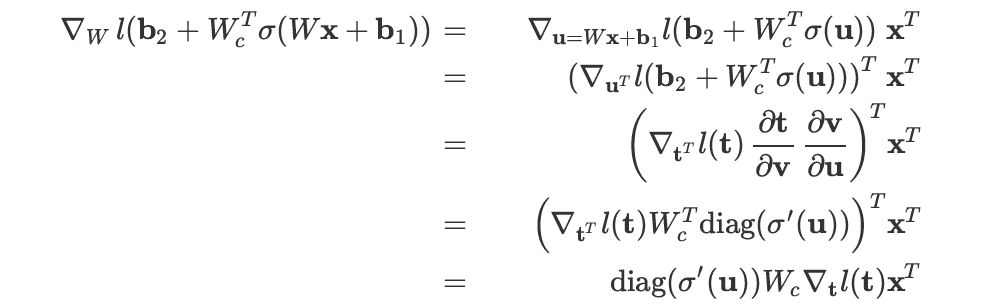
,其中第三个等号里定义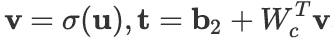 。
。
本文最先由七月发表于知乎专栏:https://zhuanlan.zhihu.com/p/25063314
本文为机器之心专栏,转载请联系原作者七月获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com








