大家在写报告、写总结时,是否会先去翻一下以前写过的类似的东西?是否有看过比较好的文章,想保存时却为归类而纠结?是否电脑里的文件越来越多,想删掉一些却又舍不得?身处大数据和人工智能的时代,如何节约时间,提高工作效率,快速积累知识并使用知识呢?本文分享一种知识整理术,并提供一个实用的小工具。
一、认识“元认知”
知识是什么,在信息时代之前,知识大部分依存于记忆;在信息时代初,知识主要变成了一种能搜索和利用信息的能力;而随着信息化的深入,个人要获取各种知识越来越容易,因此我们需要一种是整合内外部资源,结构化管理多种知识的技能。

也就是说,我们要强化我们的元认知,来管理好自己的技能库。元认知是美国心理学家J.H.Flavell在1976年提出的概念,意思是“反映或调节认知活动的任一方面的知识或认知活动,即认知的认知”。本文通俗地把其定义为一种高效学习知识、使用知识的技能。
二、使用笔记,节约认知资源,节约认知资源,更新知识树更新知识树
不断学习不断遗忘,是人的天性。遗忘也让宝贵的认知资源及时回收,让人脑轻装上阵,随时保持良好的状态。但是我们真的要抛弃以前做过的事情,或者说遗忘知识吗?不是的,人生不是小说创作,我们也不知道自己的终极技能是什么,向前走一步才能看到下一步的路,我们不能轻易遗忘,要做好笔记。随着经历增加,知识在不断积累,小心养好自己的知识树。世事迁移,某些枝叶可能变成主干,某些主干也可能变成枝叶。把过程保存下来,不仅能看到自己的进步,也能看到自己所朝着的方向,岂不很有意义?
如果把人脑比作电脑,人的记忆就是内存,容量小而响应速度快,而外部笔记就是硬盘。
要降低人脑的记忆负荷,就要更好的利用硬盘。硬盘读写速度越快越好,同理,好的笔记方法要能快速记录,方便查询,和结构化展示。现在市场上几乎没有集3个优点合一的笔记方法。要么是写入太麻烦,要么是查找不方便,能够结构化展示内容的更少。
三、高效管理文件夹的方法,就是最好的笔记
要快速记录笔记,最好的方法就是让程序自动做”笔记”。把自己曾经做过的事情,按结构存放于各个文件夹中,自然就做成自己的知识树了。不知道大家有没有用过思维导图,我曾经很热衷于这样的结构工具,但它一个是要收费;而且画出如下的结构图(仅是举例,内容不重要)只能完全手动,花费时间长;最后它不开源,不能个性化新增功能。
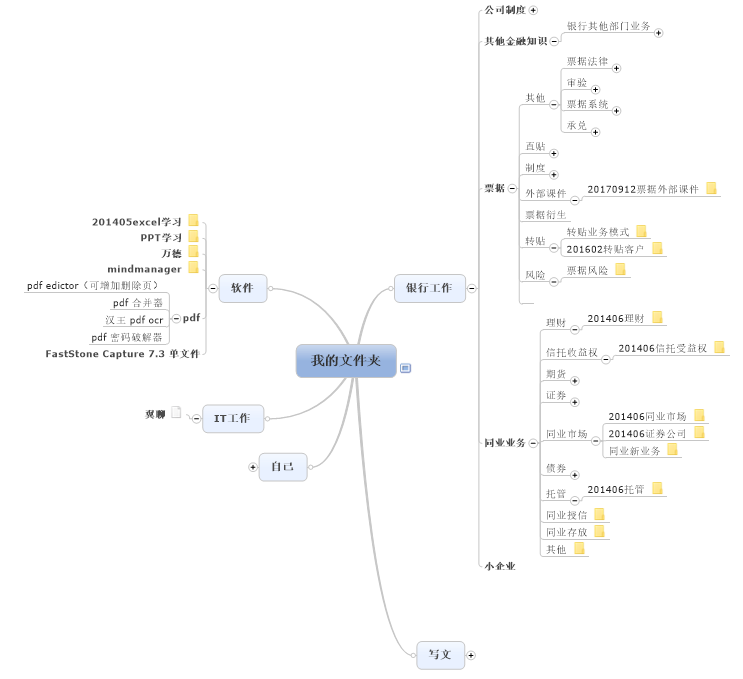
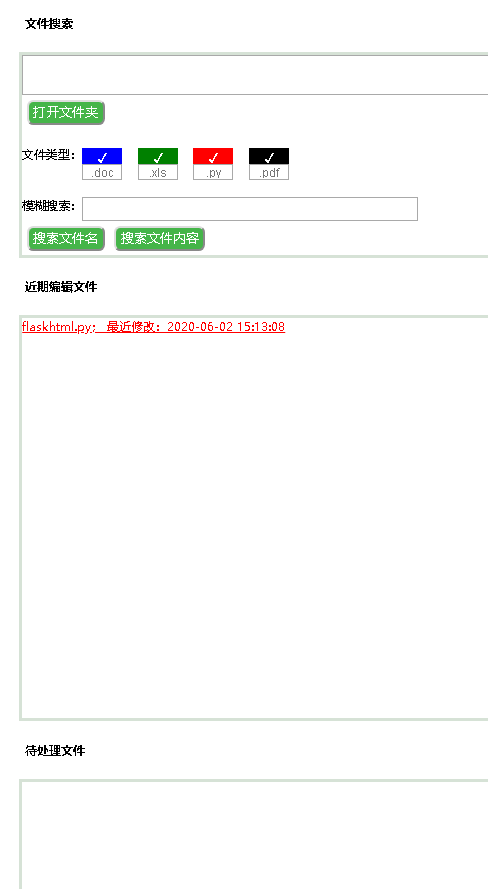
我这个程序的设想就是制作类似思维导图功能的工具,但最大优点是自动化,只要把这个工具放入所在文件夹中,就能根据文件夹结构生成图谱。还强化了文件夹的个性化操作功能。例如在某些文件夹或文件上标注“待处理”文字的话,能够将该文件名放置到待处理区域,提醒用户办理。整体界面如下:
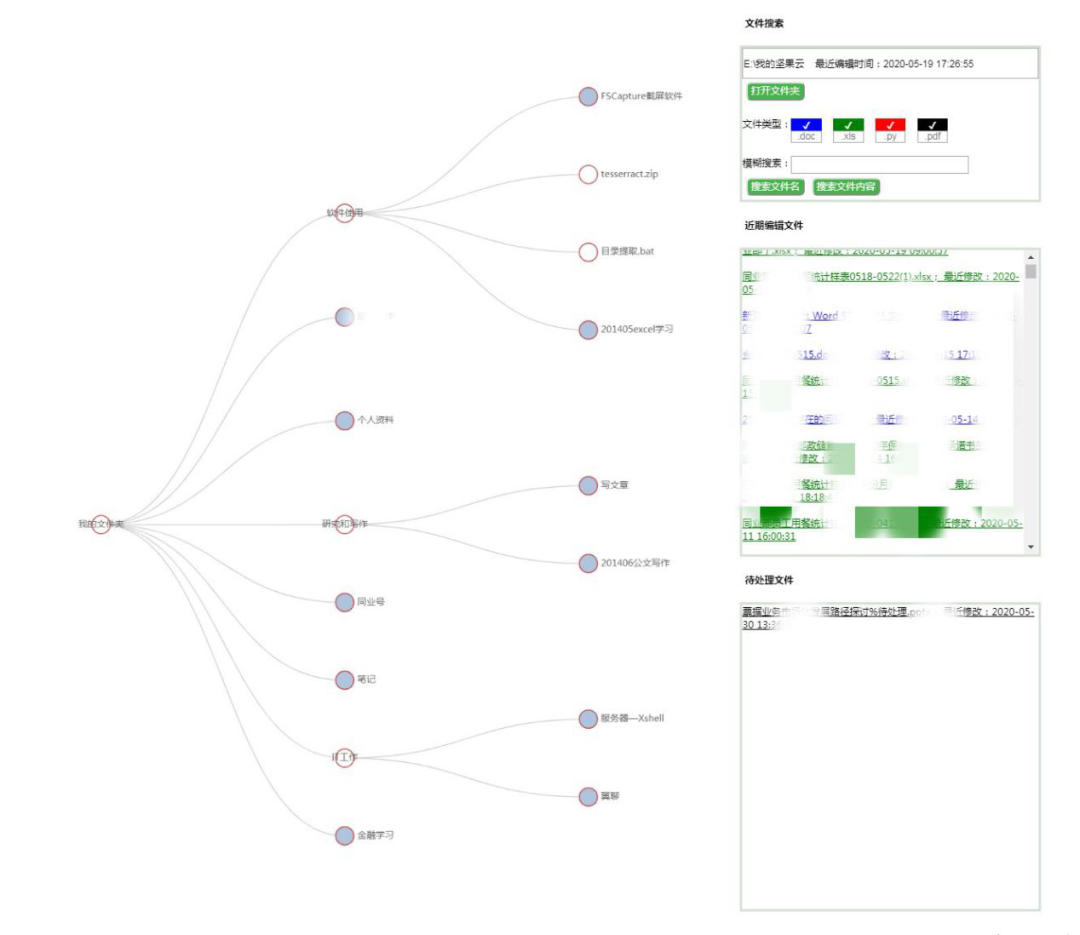
这个程序有如下的本地文件夹管理功能:
(一)能自动画出文件结构图,展开缩放。按照最近编辑时间先后排序。
(二)使用本程序打开本地文件夹。
(三)展示所有文件的最近编辑时间。
(四)展示待处理文件,提示待办事项。
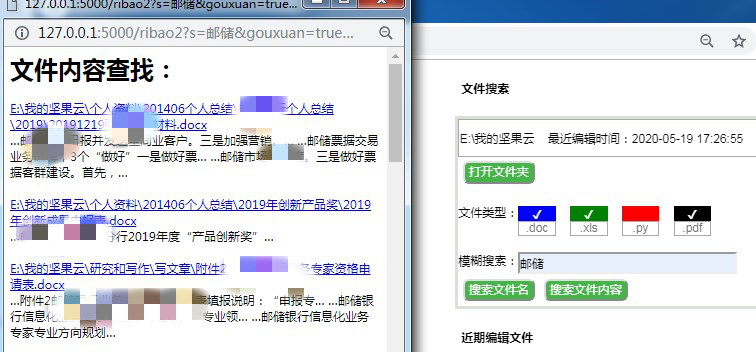
(五)可以根据关键词在目标文件夹中查找文件内容。例如深入查找docx文件中的段落,和python程序中的代码。
四、各步骤及核心代码
思路是用python的os库分析文件结构,用python的flask作为后台建立本地服务器,用html做前台展示界面,实现交互功能。文件结构如下,主程序为flaskhtml.py,在templates里面放上home.html,html中的文件结构图采用echarts的tree图。

(一)使用python的os库分析文件结构。将这个结构保存为dataframe格式。这
部分关键就是要写个循环,遍历到所有文件夹的最内层。用os.listdir获取文件名list,把文件名记录到一个dataframe,核心代码如下:
1.获取第二层文件夹名字(第一层就是默认以“我的文件夹”为名)
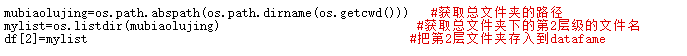
2.用循环获取第三层直至最后一层的文件夹名字(再次用os.listdir打开储存在dataframe中的文件夹路径,获取该链接下的文件名,如果本层级的所有文件夹下面都没有文件了,就跳出循环;否则就继续深入。)
我这里先设定了深入到20层,一般文件夹用不到20层,就会结束循环。

3.获取文件的最近一次修改时间

4.最终得到如下的层级结构

(二)将dataframe(df)转化成符合tree图要求的list格式数据。
tree图中,每个点的属性有三个:name,value,children。name是某个点的名字,value是该点的自定义内容,我把每个文件夹的链接地址和修改时间储存到value中。每一个点不一定都有childeren属性,它是包含该点下一层级支点的信息,下一层支点又可以带有以上三个属性。
也是类似地按照第一步一层层地将dataframe转变成list,不同的是,第一步的层级结构是要从文件夹里分析出来的,这一步是从那个df里面读取的。
(三)在html中增加其他功能的按钮,使其能和本地python程序交互。例如根据文件夹路径打开文件夹;根据搜索的关键词,查找本地文件夹名字或者文件内容。
(四)最后,使用flask搭建本地服务器,在浏览器上使用本软件。

用flask将本地处理好的数据上传到html。运行flaskhtml.py之后,出现如下界面,就代表本地网站服务器已经运行了,打开浏览器,输入网址127.0.0.1:5000,就可以打开主页面了。

作者:杨炳,心理学者在银行写代码。
赞 赏 作 者

Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。


▼点击成为社区会员 喜欢就点个在看吧











