
本文作者 Saurav Kaushik 是数据科学爱好者,还有一年他就从新德里 MAIT 毕业了,喜欢使用机器学习和分析来解决复杂的数据问题。看看以下40道题目,测试下你能答对多少。
作者 | Saurav Kaushik
翻译 | AI科技大本营(rgznai100)
介绍
创造出具有自我学习能力的机器——人们的研究已经被这个想法推动了十几年。如果要实现这个梦想的话,无监督学习和聚类将会起到关键性作用。但是,无监督学习在带来许多灵活性的同时,也带来了更多的挑战。
在从尚未被标记的数据中得出见解的过程中,聚类扮演着很重要的角色。它将相似的数据进行分类,通过元理解来提供相应的各种商业决策。在这次能力测试中,我们在社区中提供了聚类的测试,总计有1566人注册参与过该测试。
总结果
下面是分数的分布情况,可以帮你评估你的表现:
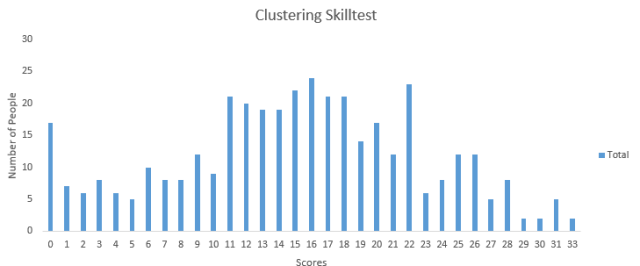
你也可以通过访问这里来查看自己的成绩,超过390个人参加了测试,最高分数是33分。下面是对分数分布的部分统计。
https://datahack.analyticsvidhya.com/contest/clustering-skilltest/lb
总分布:
平均分:15.11
中位数:15
模型分数:16
相关资源:
An Introduction toClustering and different methods of clustering
https://www.analyticsvidhya.com/blog/2016/11/an-introduction-to-clustering-and-different-methods-of-clustering/
Getting yourclustering right (Part I)
https://www.analyticsvidhya.com/blog/2013/11/getting-clustering-right/
Getting yourclustering right (Part II)
https://www.analyticsvidhya.com/blog/2013/11/getting-clustering-right-part-ii/
Questions & Answers
Q1. 电影推荐系统是以下哪些的应用实例:
分类
聚类
强化学习
回归
选项:
只有2
1和2
1和3
2和3
1 2 3
1 2 3 4
答案: E
一般来说,电影推荐系统会基于用户过往的活动和资料,将用户聚集在有限数量的相似组中。然后,从根本上来说,对同一集群的用户进行相似的推荐。
在某些情况下,电影推荐系统也可以归为分类问题,将最适当的某类电影分配给特定用户组的用户。与此同时,电影推荐系统也可以视为增强学习问题,即通过先前的推荐来改进以后的电影推荐。
Q2. 情感分析是以下哪些的实例:
回归
分类
聚类
强化学习
选项:
只有1
1和2
1和3
1 2 3
1 2 4
1 2 3 4
答案:E
在基本水平上的情感分析可以被认为是将图像、文本或语音中表示的情感,分类成一些情感的集合,如快乐、悲伤、兴奋、积极、消极等。同时,它也可以被视为对相应的图像、文本或语音按照从1到10的情感分数进行回归。
另一种方式则是从强化学习的角度来思考,算法不断地从过去的情感分析的准确性上进行学习,以此提高未来的表现。
Q3. 决策树可以用来执行聚类吗?
能
不能
答案:A
决策树还可以用在数据中的聚类分析,但是聚类常常生成自然集群,并且不依赖于任何目标函数。
Q4. 在进行聚类分析之前,给出少于所需数据的数据点,下面哪种方法最适合用于数据清理?
限制和增加变量
去除异常值
选项:
1
2
-
1和2
都不能
答案:A
在数据点相对较少的时候,不推荐去除异常值,在一些情况下,对变量进行剔除或增加更合适。
Q5. 执行聚类时,最少要有多少个变量或属性?
0
1
2
3
答案:B
进行聚类分析至少要有一个变量。只有一个变量的聚类分析可以在直方图的帮助下实现可视化。
Q6. 运行过两次的K均值聚类,是否可以得到相同的聚类结果?
是
否
答案:B
K均值聚类算法通常会对局部最小值进行转换,个别时候这个局部最小值也是全局最小值,但这种情况比较少。因此,更建议在绘制集群的推断之前,多次运行K均值算法。
然而,每次运行K均值时设置相同的种子值是有可能得出相同的聚类结果的,但是这样做只是通过对每次的运行设置相同的随机值来进行简单的算法选择。
Q7. 在K均值的连续迭代中,对簇的观测值的分配没有发生改变。这种可能性是否存在?
是
否
不好说
以上都不对
答案:A
当K均值算法达到全局或局部最小值时,两次连续迭代所产生的数据点到簇的分配不会发生变化。
Q8. 以下哪项可能成为K均值的终止条件?
对固定数量的迭代。
在局部最小值不是特别差的情况下,在迭代中对簇观测值的分配不发生变化。
在连续迭代中质心不发生变化。
当 RRS 下降到阈值以下时终止。
选项:
1 3 4
1 2 3
1 2 4
全部都是
答案:D
这四种条件都可能成为K均值聚类的终止条件:
这个条件限制了聚类算法的运行时间,但是在一些情况下,由于迭代次数不足,聚类的质量会很差。
在局部最小值不是特别差的情况下,会产生良好的聚类,但是运行时间可能相当长。
这种条件要确保算法已经收敛在最小值以内。
在 RRS 下降到阈值以下时终止,可以确保之后聚类的质量。实际上,这是一个很好的做法,在结合迭代次数的同时保证了K均值的终止。
Q9. 以下哪种算法会受到局部最优的聚焦问题的影响?
K均值聚类算法
层次聚类算法
期望-最大化聚类算法
多样聚类算法
选项:
1
2 3
2 4
1 3
1 2 4
以上都是
答案:D
在上面四个选项中,只有K均值聚类和期望-最大化聚类算法有在局部最小值出收敛的缺点。
Q10. 以下哪种算法对离群值最敏感?
K均值聚类算法
K中位数聚类算法
K模型聚类算法
K中心点聚类算法
答案:A
在上面给出的选项中,K均值聚类算法对离群值最敏感,因为它使用集群数据点的平均值来查找集群的中心。
Q11. 在对数据集执行K均值聚类分析以后,你得到了下面的树形图。从树形图中可以得出那些结论呢?
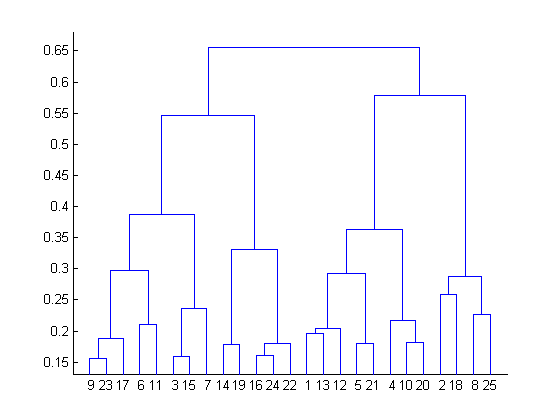
在聚类分析中有28个数据点
被分析的数据点里最佳聚类数是4
使用的接近函数是平均链路聚类
对于上面树形图的解释不能用于K均值聚类分析
答案:D
树形图不可能用于聚类分析。但是可以根据K聚类分析的结果来创建一个簇状图。
Q12. 如何使用聚类(无监督学习)来提高线性回归模型(监督学习)的准确性:
为不同的集群组创建不同的模型。
将集群的id设置为输入要素,并将其作为序数变量。
将集群的质心设置为输入要素,并将其作为连续变量。
将集群的大小设置为输入要素,并将其作为连续变量。
选项:
1
1 2
1 4
3
2 4
以上都是
答案:F
将集群的 id 设置为序数变量和将集群的质心设置为连续变量,这两项可能不会为多维数据的回归模型提供更多的相关信息。但是当在一个维度上进行聚类分析时,上面给出的所有方法都有望为多维数据的回归模型提供有意义的信息。举个例子,根据头发的长度将人们分成两组,将聚类 ID 存储为叙述变量,将聚类质心存储为连续变量,这样一来,多维数据的回归模型将会得到有用的信息。
Q13. 使用层次聚类算法对同一个数据集进行分析,生成两个不同的树形图有哪些可能的原因:
使用了接近函数
数据点的使用
变量的使用
只有B和C
以上都有
答案:E
接近函数、数据点、变量,无论其中哪一项的改变都可能使聚类分析产生不同的结果,并产生不同的树状图。
Q14. 在下面的图中,如果在y轴上绘制一条y=2的水平线,将产生多少簇?

选项:
1
2
3
4
答案:B
因为在树状图中,与 y=2 红色水平线相交的垂直线有两条,因此将形成两个簇。
Q15. 根据下面的树形图,数据点所产生的簇数最可能是?
选项
2
4
6
8
答案:B
通过观察树状图,可以很好的判断出不同组的簇数。根据下图,水平线贯穿过的树状图中垂直线的数量将是簇数的最佳选择,这条线保证了垂直横穿最大距离并且不与簇相交。
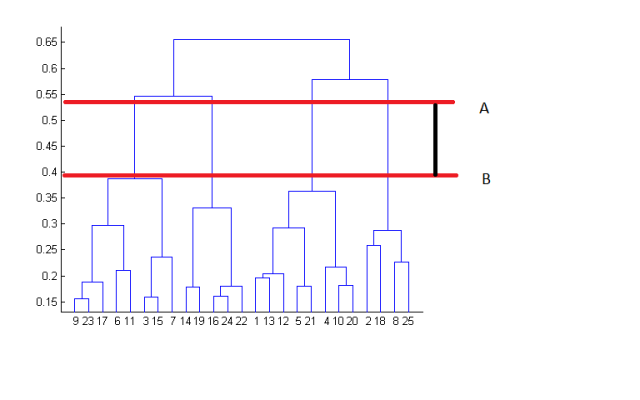
在上面的例子中,簇的数量最佳选择是4,因为红色水平线涵盖了最大的垂直距离AB。
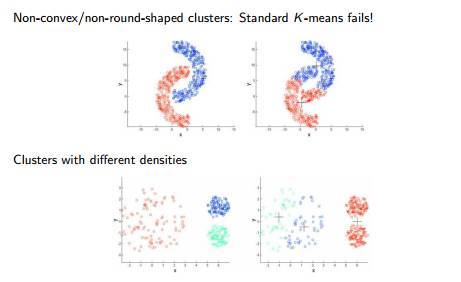
Q16. K均值聚类分析在下面哪种情况下无法得出好的结果?
具有异常值的数据点
具有不同密度的数据点
具有非环形的数据点
具有非凹形的数据点
选项:
1 2
2 3
2 4
1 2 4
1 2 3 4
答案:D
在数据包含异常值、数据点在数据空间上的密度扩展具有差异、数据点为非凹形状的情况下,K均值聚类算法的运行结果不佳。
Q17. 通过以下哪些指标我们可以在层次聚类中寻找两个集群之间的差异?
单链
完全链接
平均链接
选项:
1 2
1 3
2 3
1 2 3
答案:D
通过单链接、完全链接、平均链接这三种方法,我们可以在层次聚类中找到两个集群的差异。
Q18. 下面哪些是正确的?
特征性多重共线性对聚类分析有负面效应
异方差性对聚类分析有负面效应
选项:
1
2
1 2
以上都不是
答案:A
聚类分析不会受到异方差性的负面影响,但是聚类中使用的特征/变量多重共线性会对结果有负面的影响,因为相关的特征/变量会在距离计算中占据很高的权重。
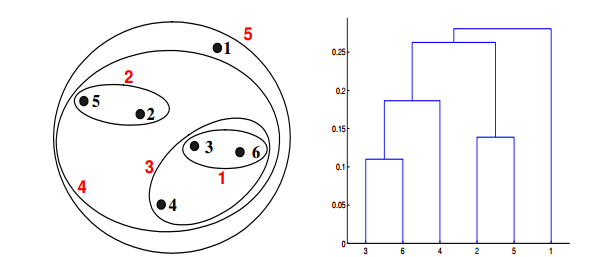
Q19. 给定具有以下属性的六个点:

如果在层次聚类中使用最小值或单链接近函数,可以通过下面哪些聚类表示和树形图来描述?
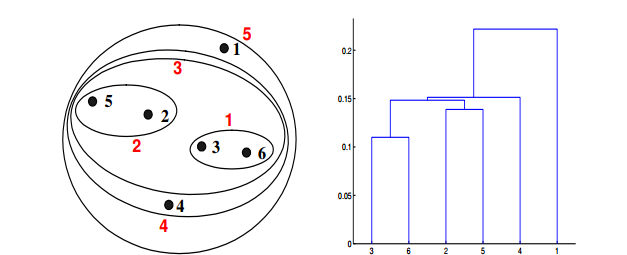


答案:A
对于层级聚类的单链路或者最小化,两个簇的接近度指的是不同簇中任何两个点之间的距离的最小值。例如,我们可以从图中看出点3和点6之间的距离是0.11,这正是他们在树状图中连接而成的簇的高度。再举一个例子,簇{3,6}和{2,5}之间的距离这样计算:dist({3, 6}, {2, 5}) =min(dist(3, 2), dist(6, 2), dist(3, 5), dist(6, 5)) = min(0.1483, 0.2540,0.2843, 0.3921) = 0.1483.
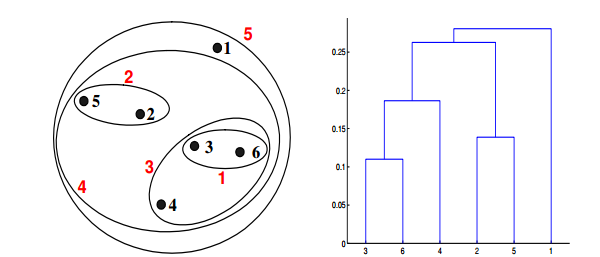
Q20. 给定具有以下属性的六个点:
如果在层次聚类中使用最大值或完全链接接近函数,可以通过下面哪些聚类表示和树形图来描述?
答案:B
对于层级聚类的单链路或者最大值,两个簇的接近度指的是不同簇中任何两个点之间的距离的最大值。同样,点3和点6合并在了一起,但是{3,6}没有和{2,5}合并,而是和{4}合并在了一起。这是因为dist({3, 6}, {4}) = max(dist(3, 4), dist(6, 4)) = max(0.1513,0.2216) = 0.2216,它小于dist({3, 6}, {2, 5}) = max(dist(3,2), dist(6, 2), dist(3, 5), dist(6, 5)) = max(0.1483, 0.2540, 0.2843, 0.3921) =0.3921 and dist({3, 6}, {1}) = max(dist(3, 1), dist(6, 1)) = max(0.2218,0.2347) = 0.2347。
Q21. 给定具有以下属性的六个点:
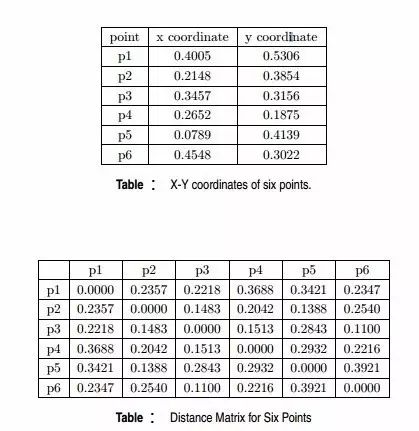
如果在层次聚类中使用组平均值接近函数,可以通过下面哪些聚类表示和树形图来描述?

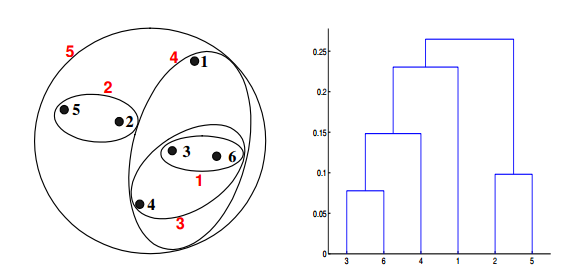
答案:C
对于层次聚类的的群平均值,两个簇的接近度指的是不同集群中的每一对点对的近似值的平均值。这是最大值和最小值方法之间的中间方法,下面的等式可以表示:
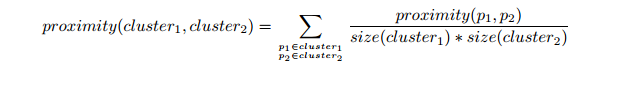
我们来计算一下某些簇之间的距离。dist({3, 6, 4}, {1}) = (0.2218 + 0.3688 + 0.2347)/(3 ∗ 1) = 0.2751,dist({2, 5}, {1}) = (0.2357 + 0.3421)/(2 ∗1) = 0.2889. dist({3, 6, 4}, {2, 5}) = (0.1483 + 0.2843 + 0.2540 + 0.3921 +0.2042 + 0.2932)/(6∗1) = 0.2637。因为dist({3, 6, 4}, {2, 5})小于dist({3, 6, 4},{1}) 和dist({2, 5}, {1}),所以这两个簇在第四阶段被合并到了一起。
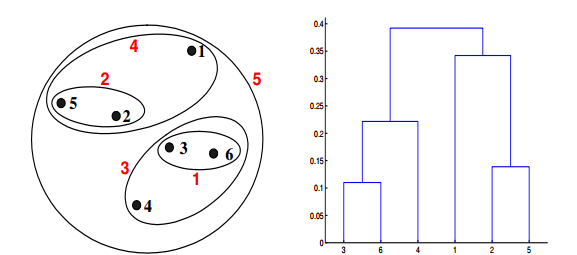
Q22. 给定具有以下属性的六个点:
如果在层次聚类中使用 Ward 方法的接近函数,可以通过下面哪些聚类表示和树形图来描述?
答案:D
Ward 方法是一种质心算法。质心方法通过计算集群的质心之间的距离来计算两个簇的接近度。对于 Ward 方法来说,两个簇的接近度指的是当两个簇合并时产生的平方误差的增量。在6%的样本数据集中,使用 Ward 方法产生的结果和使用最大值、最小值、组平均值的聚类结果会有所不同。
Q23. 根据下图,簇的数量的最佳选择是?

1
2
3
4
答案:C
轮廓系数旨在将某个对象与自己的簇的相似程度和与其他簇的相似程度进行比较。轮廓系数最高的簇的数量表示簇的数量的最佳选择。
Q24. 在聚类分析之前处理缺失值的有效迭代策略有哪些?
平均值插补法
由最近的值进行分配
用期望最大化算法进行插补
以上都是
答案:C
上面提到的所有方法都可以有效的在聚类分析之前处理缺失值,但是只有期望最大化算法是可以迭代的。
Q25. K均值算法有一些局限性。 其中的一个是,把一个点(完全属于一个集群或根本不属于一个集群的点)强制分配到一个集群。(注意:软性分配可以被认为是被分配给每个聚类的概率:例如 K= 3 时对于一些点 Xn,p1 = 0.7,p2 = 0.2,p3 = 0.1)
下面哪些算法允许软性分配?
高斯模糊模型
模糊K均值
选项:
1
2
1 2
以上都不是
答案:C
高斯模糊模型和模糊K均值都允许进行软性分配。
Q26. 假设你想使用K均值聚类算法将7个观测值聚类到3个簇中。在第一次迭代簇之后,C1、C2和C3具有以下观测值:
C1: {(2,2), (4,4), (6,6)}
C2: {(0,4), (4,0)}
C3: {(5,5), (9,9)}
如果继续进行第二次迭代,哪一个将成为集群的质心?
C1: (4,4), C2: (2,2), C3: (7,7)
C1: (6,6), C2: (4,4), C3: (9,9)
C1: (2,2), C2: (0,0), C3: (5,5)
以上都不是
答案:A
找到集群中数据点的质心 C1 = ((2+4+6)/3,(2+4+6)/3) = (4, 4)
找到集群中数据点的质心 C2 = ((0+4)/2, (4+0)/2) =(2, 2)
找到集群中数据点的质心 C3 = ((5+9)/2, (5+9)/2) =(7, 7)
因此, C1: (4,4), C2: (2,2), C3: (7,7)
Q27. 假设你想用K均值聚类方法将7个观测值聚类到3个簇中,在第一次迭代簇之后,C1、C2、C3具有以下观测值:
C1: {(2,2), (4,4), (6,6)}
C2: {(0,4), (4,0)}
C3: {(5,5), (9,9)}
在第二次迭代中,观测点(9,9)到集群质心C1的 Manhattan 距离是?
10
5 * sqrt(2)
13 * sqrt(2)
以上都不是
答案:A
(4,4)和(9,9)的 Manhattan 距离是:(9-4)+(9-4)= 10。
Q28. 如果聚类分析现在有两个变量V1和V2,对于K均值分析(k=3)的描述,下面哪些是正确的?
如果V1和V2完全相关,簇的质心会在一条直线上
如果V1和V2完全不相关,簇的质心会在一条直线上
选项:
1
-
2
1 2
以上都不是
答案:A
如果变量V1和V2完全相关,那么所有的数据点都会在同一条直线上,三个簇的质心也会在同一条直线上。
Q29. 应用K均值算法之前,特征缩放是一个很重要的步骤。这是为什么呢?
在距离计算中,它为所有特征赋予相同的权重
不管你用不用特征缩放,你总是会得到相同的簇
在Manhattan距离中,这是重要的步骤,但是Euclidian中则不是
以上都不是
答案:A
特征缩放保证了在聚类分析中每一个特征都有同样的权重。想象这样一个例子,对体重范围在55-100(kg)和身高在5.6到6.4(英寸)的人进行聚类分析。因为体重的范围远远高于身高的范围,如果不进行缩放,产生的簇会对结果产生误导。因此,使它们具有相同的级别就显得很有必要了,只有这样才能保证聚类结果权重相同。
Q30. 为了在K均值算法中找到簇的最优值,可以使用下面哪些方法?
Elbow 法
Manhattan 法
Ecludian 法
以上都是
以上都不是
答案:A
在上面给出的选项中,只有 Elbow 方法是用来寻找簇数的最优值的。方差百分比是一个与簇数有关的函数,Elbow 方法关注的就是方差百分比:分析时应该选择多个簇,以便在添加另一个簇时,不会给出更好的数据建模。
Q31. 关于K均值聚类的描述正确的是?
K均值对簇中心初始化非常敏感
初始化不良会导致收敛速度差
初始化不良可能导致整体聚集不良
选项:
1 3
1 2
2 3
1 2 3
答案:D
上面给出的三个描述都是正确的。K均值对簇中心初始化非常敏感。而且,初始化不良会降低收敛的速度差并会使得整体聚集效果不佳。
Q32. 可以用下面哪一种方法来获得和全局最小值有关的K均值算法的良好结果?
试着运行不同的质心初始化算法
调整迭代的次数
找出最佳的簇数
选项:
2 3
1 3
1 2
以上都是
答案:D
上面列举的所有选项都是为了获得良好的聚类结果而采用的标准实践。
Q33. 根据下图的结果,簇的数量的最好选择是?
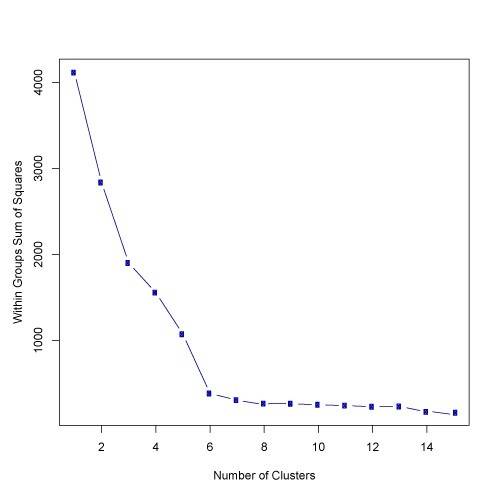
5
6
14
大于14
答案:B
根据上面的结果,使用 elbow 方法的簇数的最优选择是6。
Q34. 根据下图的结果,簇的数量的最好选择是?
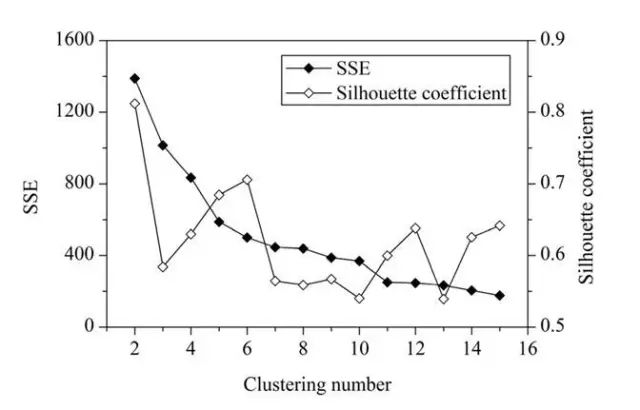
2
4
6
8
答案:C
一般来说,平均轮廓系数越高,聚类的质量也相对较好。在这道题中,对于研究区域的网格单元,最优聚类数应该是2,这时平均轮廓系数的值最高。但是,聚类结果(k=2)的 SSE 值太大了。当 k=6 时,SEE 的值会低很多,但此时平均轮廓系数的值非常高,仅仅比 k=2 时的值低一点。因此,k=6 是最佳的选择。
Q35. 对于在初始化中使用了 Forgy 方法的K均值算法,下面哪个顺序是正确的?
指定簇的数量
随机分配簇的质心
将每个数据点分配给最近的簇质心
将每个点重新分配给最近的簇质心
重新计算簇的质心
选项:
1 2 3 5 4
1 3 2 4 5
2 1 3 4 5
以上都不是
答案:A
用于K均值初始化的方法是 Forgy 和随机分区。Forgy 方法从数据集中随机选择k个观测值,并将其作为初始值。随机分区方法是先随机为每个观测值分配一个簇,随后进行更新,簇的随机分配点的质心就是计算后得到的初始平均值。
Q36. 如果你要用具有期望最大化算法的多项混合模型将一组数据点聚类到两个集群中,下面有哪些重要的假设?
所有数据点遵循两个高斯分布
所有数据点遵循n个高斯分布(n>2)
所有数据点遵循两个多项分布
所有数据点遵循n个多项分布(n>2)
答案:C
在聚类中使用期望最大化算法,本质是将数据点按照所选数量的簇进行分类,这个数量和预期生成的不同分布的数量是相同的,而且分布也必须是相同的类型。
Q37. 下面对基于质心的K均值聚类分析算法和基于分布的期望最大化聚类分析算法的描述,哪些是不正确的?
都从随机初始化开始
都是可迭代算法
两者对数据点的假设很强
都对异常值敏感
期望最大化算法是K均值的特殊情况
都需要对所需要的簇数有先验知识
结果是不可再现的。
选项:
1
5
1 3
6 7
4 6 7
以上都不是
答案:B
上面的描述中只有第五个是错的,K均值是期望最大化算法的特殊情况,K均值是在每次迭代中只计算聚类分布的质心。
Q38. 下面关于 DBSCAN 聚类算法的描述不正确的是?
集群中的数据点必须处于到核心点的距离阈限内
它对数据空间中数据点的分布有很强的假设
它具有相当高的时间复杂度O(n3)
它不需要预先知道期望出现的簇的数量
它对于异常值具有强大的作用
选项:
1
2
4
2 3
1 5
1 3 5
答案:D
DBSCAN 可以形成任意形状的聚类,数据点在数据空间的分布很难预测。
DBSCAN 有比较低的时间复杂度 O(n log n)。
Q39. 以下哪项的F分数存在上限和下限?
[0,1]
(0,1)
[-1,1]
以上都不是
答案:A
F分数的最小可能值是0,最大可能值是1。1表示每个数据点都被分配给了正确的聚类,0表示聚类分析的旋进和(或)回调为0。在聚类分析中,我们期望出现的是F分数的高值。
Q40. 下面是对6000个数据点进行聚类分析后聚集成的3个簇:A、B和C:
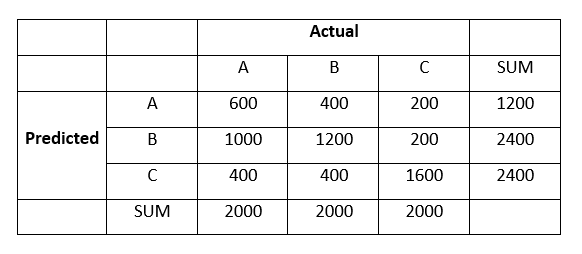
集群B的F1分数是多少?
3
4
5
6
答案:D
True Positive, TP = 1200
True Negative, TN = 600 + 1600 = 2200
False Positive, FP = 1000 + 200 = 1200
False Negative, FN = 400 + 400 = 800
因此,
Precision = TP / (TP + FP) = 0.5
Recall = TP / (TP + FN) = 0.6
最后,
F1 = 2 * (Precision * Recall)/(Precision + recall) = 0.54 ~ 0.5
结语
真心希望这次测试的答案对你有用。本次测试的重点主要集中在概念、聚类基本原理以及各种技术的实践知识等方面。
原文链接
https://www.analyticsvidhya.com/blog/2017/02/test-data-scientist-clustering/
扫描二维码,关注「人工智能头条」
回复“技术路线图”获取AI 技术人才成长路线图








