
本文以病马数据集为例,帮助你了解在机器学习领域如何利用统计策略来处理缺失值,对代码进行了较为详细的讲解。数据有可能会含有缺失值,而这可能会导致多种机器学习算法出现问题。同样地,在你对自己的预测任务进行建模之前,对数据每一列进行缺失值识别和替换是非常恰当的做法。这一步骤被称为数据缺失值插补处理,或者简称插补。一种常见的数据缺失值插补方式是计算每一列的统计值(例如均值),并用这个值来替换该列所有的缺失值。这是一个非常受欢迎的方法,因为对于训练集很容易计算出一列的统计值,另外这种方法所获得的效果也比较理想。在这篇教程中,你会了解到在机器学习领域如何利用统计插补来处理缺失值。缺失值必须被标记为NaN,且可以被用统计方法计算出的列的值来替代。
如何载入一份带有缺失值的CSV文件,用NaN来标识缺失值,展现出每一列的缺失值数量和百分比。
如何用统计量来填充缺失值,作为数据准备方法中的一个步骤,用于评估模型和用最终模型和新数据来拟合预测结果。

教程综述
3. 利用SimpleImputer来进行统计插补1. SimpleImputer 数据转换
2. SimpleImputer 和模型评估
3. 比较不同的插补统计量
4. 在预测时进行SimpleImputer转换
统计插补
缺失值是指一行数据中某一项或者多项的数据值没有意义。有可能是值为空,也有可能是用一些特殊的字符或值来表示,例如问号“?”。 “这些值有可能以多种形式来表示。我见过的形式比如有完全为空,一个空的字符串,“NULL”字段、“N/A”或“NaN”,再就是数字0等等。不管它们以什么样的形式出现在你的数据集里,你要清楚自己的目的,并且确定这些数据的作用匹配达到你的预期,这样将会使你在开始使用数据时减少问题的存在。”
——源自2012年出版的《Bad Data Handbook》,第10页书籍地址:https://amzn.to/3b5yutA
数据有可能因多种原因而造成缺失,这需要根据问题所在的具体领域来确定,比如说包括测量仪器的损坏或者说数据本身就无法获得。 “数据缺失的出现可能处于多种理由,比如说测量仪器出现故障,在数据收集阶段变更了实验设计,或者从多组近似却不相同的数据集中所进行采集。”——源自2016年出版的《Data Mining: Practical Machine Learning Tools and Techniques》,第63页书籍地址:https://amzn.to/3bbfIAP大部分机器学习算法都要求输入的类型为数值,而且数据集中的每一行每一列都有值的存在。既然如此,缺失值的出现可能会导致机器学习算法产生问题。像这样,普遍情况是识别出数据集中的缺失值,然后用数值来替代它。这个过程被称为数据插补或数据缺失值插补。一种简单且流行的数据插补是使用统计方法,对缺失值所在这一列估算出一个值,然后用这个统计方法计算出的统计量来代替这列中的缺失值。这种方法很简单,因为可以很快计算出统计量,另外这也是很受欢迎的,因为这种方法被证明是非常有效的。现在我们对这些用来缺失值插补的统计方法已经有所熟悉,接下来一起来看看带有缺失值的数据。病马数据集
病马数据集用来记录患有腹绞痛的马匹所出现的医学特征,还有马匹最终是生存下来还是死亡。该数据集共有300条记录(300行),有26个输入变量和1个输出变量。这是一个二分类预测问题,标签有两个值,马匹活着是1,马匹死亡则是2。一个简单的模型所能达到的分类准确率约为67%。一个表现极佳的模型,使用3次重复的10折交叉验证的话,预测结果的准确率能够达到85.2%。这定义了针对该数据集建模所能表现的预期范围。这个数据集在多个列上包含大量的缺失值,每一个缺失值都标有问号“?”。2,1,530101,38.50,66,28,3,3,?,2,5,4,4,?,?,?,3,5,45.00,8.40,?,?,2,2,11300,00000,00000,21,1,534817,39.2,88,20,?,?,4,1,3,4,2,?,?,?,4,2,50,85,2,2,3,2,02208,00000,00000,22,1,530334,38.30,40,24,1,1,3,1,3,3,1,?,?,?,1,1,33.00,6.70,?,?,1,2,00000,00000,00000,11,9,5290409,39.10,164,84,4,1,6,2,2,4,4,1,2,5.00,3,?,48.00,7.20,3,5.30,2,1,02208,00000,00000,1...
https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csvhttps://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.names我们不需要下载该数据集,因为在接下来的代码样例中会自动下载。在使用Python语言来载入数据集时,将所有的缺失值标记为NaN(而不是使用一个数字),是一种很好的做法。我们可以使用Pandas库中的read_csv()函数来加载数据集,然后指定“na_values”来载入用“?”符号表示的缺失值。...# load dataseturl = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv'dataframe = read_csv(url, header=None, na_values='?')
在加载之后,我们来检查一下数据,确定所有的“?”都已被标注为NaN。
我们可以列举出数据集的每一列,观察下每一列缺失值的数量。...# summarize the number of rows with missing values for each columnfor i in range(dataframe.shape[1]): # count number of rows with missing values n_miss = dataframe[[i]].isnull().sum() perc = n_miss / dataframe.shape[0] * 100 print('> %d, Missing: %d (%.1f%%)' % (i, n_miss, perc))
试试下面这一整段的代码,用来完成数据样本的载入,并对整个数据集进行概述。# summarize the horse colic datasetfrom pandas import read_csv# load dataseturl = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv'dataframe = read_csv(url, header=None, na_values='?')# summarize the first few rowsprint(dataframe.head())# summarize the number of rows with missing values for each columnfor i in range(dataframe.shape[1]): # count number of rows with missing values n_miss = dataframe[[i]].isnull().sum() perc = n_miss / dataframe.shape[0] * 100 print('> %d, Missing: %d (%.1f%%)' % (i, n_miss, perc))
我们可以看到所有标记为“?”的缺失值已经被NaN所替代。 0 1 2 3 4 5 6 ... 21 22 23 24 25 26 270 2.0 1 530101 38.5 66.0 28.0 3.0 ... NaN 2.0 2 11300 0 0 21 1.0 1 534817 39.2 88.0 20.0 NaN ... 2.0 3.0 2 2208 0 0 22 2.0 1 530334 38.3 40.0 24.0 1.0 ... NaN 1.0 2 0 0 0 13 1.0 9 5290409 39.1 164.0 84.0 4.0 ... 5.3 2.0 1 2208 0 0 14 2.0 1 530255 37.3 104.0 35.0 NaN ... NaN 2.0 2 4300 0 0 2[5 rows x 28 columns]
接下来,我们可以看一下关于数据所有列的清单,以及每一列中缺失值的数量和所占的百分比。
我们可以看到有些列(比如说第1和第2列)没有缺失值,而有些列(比如说第15和第21列)有很多缺失值,甚至是缺失值占了大多数。> 0, Missing: 1 (0.3%)> 1, Missing: 0 (0.0%)> 2, Missing: 0 (0.0%)> 3, Missing: 60 (20.0%)> 4, Missing: 24 (8.0%)> 5, Missing: 58 (19.3%)> 6, Missing: 56 (18.7%)> 7, Missing: 69 (23.0%)> 8, Missing: 47 (15.7%)> 9, Missing: 32 (10.7%)> 10, Missing: 55 (18.3%)> 11, Missing: 44 (14.7%)> 12, Missing: 56 (18.7%)> 13, Missing: 104 (34.7%)> 14, Missing: 106 (35.3%)> 15, Missing: 247 (82.3%)> 16, Missing: 102 (34.0%)> 17, Missing: 118 (39.3%)> 18, Missing: 29 (9.7%)> 19, Missing: 33 (11.0%)> 20, Missing: 165 (55.0%)> 21, Missing: 198 (66.0%)> 22, Missing: 1 (0.3%)> 23, Missing: 0 (0.0%)> 24, Missing: 0 (0.0%)> 25, Missing: 0 (0.0%)> 26, Missing: 0 (0.0%)> 27, Missing: 0 (0.0%)
现在我们知道了病马数据集中含有缺失值,接下来看看如何使用统计插补。
用SimpleImputer来进行统计插补
scikit-learn机器学习工具库提供SimpleImputer类来支持数据缺失值插补。在这一章节,我们会探索如何高效地使用SimpleImputer。SimpleImputer数据转换
SimpleImputer 是一个数据转换工具,基于每一列所计算出的统计量类型进行初始配置,例如平均值。...# define imputerimputer = SimpleImputer(strategy='mean')
接下来这个插补器会适配数据集,并计算每一列的统计量。...# fit on the datasetimputer.fit(X)
这个适配的插补器会被应用于数据集上,创建一个数据集复本,复本中每一列的缺失值都已经被统计量值所替换。
...# transform the datasetXtrans = imputer.transform(X)
我们可以将这一工具用在病马数据集上,先后显示下转换前和转换后的缺失值总数,从而确认这个方法是有效的。
# statistical imputation transform for the horse colic datasetfrom numpy import isnanfrom pandas import read_csvfrom sklearn.impute import SimpleImputer# load dataseturl = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv'dataframe = read_csv(url, header=None, na_values='?')# split into input and output elementsdata = dataframe.valuesX, y = data[:, :-1], data[:, -1]# print total missingprint('Missing: %d' % sum(isnan(X).flatten()))# define imputerimputer = SimpleImputer(strategy='mean')# fit on the datasetimputer.fit(X)# transform the datasetXtrans = imputer.transform(X)# print total missingprint('Missing: %d' % sum(isnan(Xtrans).flatten()))
执行示例代码,首次加载数据集时缺失值的总数为1605。
当转换工具完成配置、适配和执行三步后,新数据集的结果中已经不再存在缺失值,这说明这个功能达到了我们的预期。
SimpleImputer 和模型评估
在评估机器学习模型方面,使用K折交叉验证是一种不错的方法。为了正确地使用缺失值插补方法,避免出现数据泄露的情况,这要求被计算的统计量范围仅仅针对训练集的每一列,然后再应用于每一折的训练数据和测试数据上。如果我们利用重采样的方法来调参,或者用于评估模型的性能,缺失值插补需要包含在重采样过程之内。——源自2013年出版的《Applied Predictive Modeling》,第42页书籍地址:https://amzn.to/3b2LHTL这可以在创造建模流水线(Pipeline)过程中完成,其中第一步就是缺失值插补,第二步才是模型。这一过程可以利用Pipeline类。比如说,下面的Pipeline 使用了 SimpleImputer 方法,将平均值作为统计策略,随后利用了随机森林模型。...# define modeling pipelinemodel = RandomForestClassifier()imputer = SimpleImputer(strategy='mean')pipeline = Pipeline(steps=[('i', imputer), ('m', model)])
针对病马数据集,利用平均值进行缺失值插补和随机森林模型的建模流水线,外加使用10折交叉验证,我们可以评估下上述内容结合后所呈现的效果。
# evaluate mean imputation and random forest for the horse colic datasetfrom numpy import meanfrom numpy import stdfrom pandas import read_csvfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.impute import SimpleImputerfrom sklearn.model_selection import cross_val_scorefrom sklearn.model_selection import RepeatedStratifiedKFoldfrom sklearn.pipeline import Pipeline# load dataseturl = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv'dataframe = read_csv(url, header=None, na_values='?')# split into input and output elementsdata = dataframe.valuesX, y = data[:, :-1], data[:, -1]# define modeling pipelinemodel = RandomForestClassifier()imputer = SimpleImputer(strategy='mean')pipeline = Pipeline(steps=[('i', imputer), ('m', model)])# define model evaluationcv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)# evaluate modelscores = cross_val_score(pipeline, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores)))
正确地执行上面的示例,每一折交叉验证过程中都有使用缺失值插补。
流水线用来评估三次重复10折交叉验证的效果,得到的结果是三次分类的准确率平均值约为84.2%,成绩不错。Mean Accuracy: 0.842 (0.049)
比较不同的插补统计量
我们利用“均值”的统计策略来插补缺失值,这个方法对于该数据集来说是好是坏呢?答案是,如果我们是随意选择一种方法的话,我们肯定无法来评价它的好坏。
我们可以设计一个实验,检测每种统计策略,通过比较均值、中位数、众数(更常用)和常数(0)四种策略,得出哪种策略对这个数据集是最好的策略。每个方法的平均准确率可以用作比较的依据。# compare statistical imputation strategies for the horse colic datasetfrom numpy import meanfrom numpy import stdfrom pandas import read_csvfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.impute import SimpleImputerfrom sklearn.model_selection import cross_val_scorefrom sklearn.model_selection import RepeatedStratifiedKFoldfrom sklearn.pipeline import Pipelinefrom matplotlib import pyplot# load dataseturl = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv'dataframe = read_csv(url, header=None, na_values='?')# split into input and output elementsdata = dataframe.valuesX, y = data[:, :-1], data[:, -1]# evaluate each strategy on the datasetresults = list()strategies = ['mean', 'median', 'most_frequent', 'constant']for s in strategies: # create the modeling pipeline pipeline = Pipeline(steps=[('i', SimpleImputer(strategy=s)), ('m', RandomForestClassifier())]) # evaluate the model cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(pipeline, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # store results results.append(scores) print('>%s %.3f (%.3f)' % (s, mean(scores), std(scores)))# plot model performance for comparisonpyplot.boxplot(results, labels=strategies, showmeans=True)pyplot.xticks(rotation=45)pyplot.show()
执行上面的示例代码,利用重复交叉验证方法,评估作用在病马数据集的每种统计插补策略。
你所得到的特定结果可能会非常多样化,这归咎于学习算法的随机性。你可以尝试去多次执行这段代码。每一种统计策略所得到的平均准确率结果如下。结果显示利用常数(例如0)作为填充值的效果最佳,准确率为86.7%,优于其他结果。>mean 0.851 (0.053)>median 0.844 (0.052)>most_frequent 0.838 (0.056)>constant 0.867 (0.044)
在执行完代码之后,绘制一个盒须图来表示所对应的结果集,让我们来看一下结果的分布,从而用对其进行比较。
我们可以清楚地看到用常数来进行缺失值填充的统计策略,所得到的准确率优于其他策略。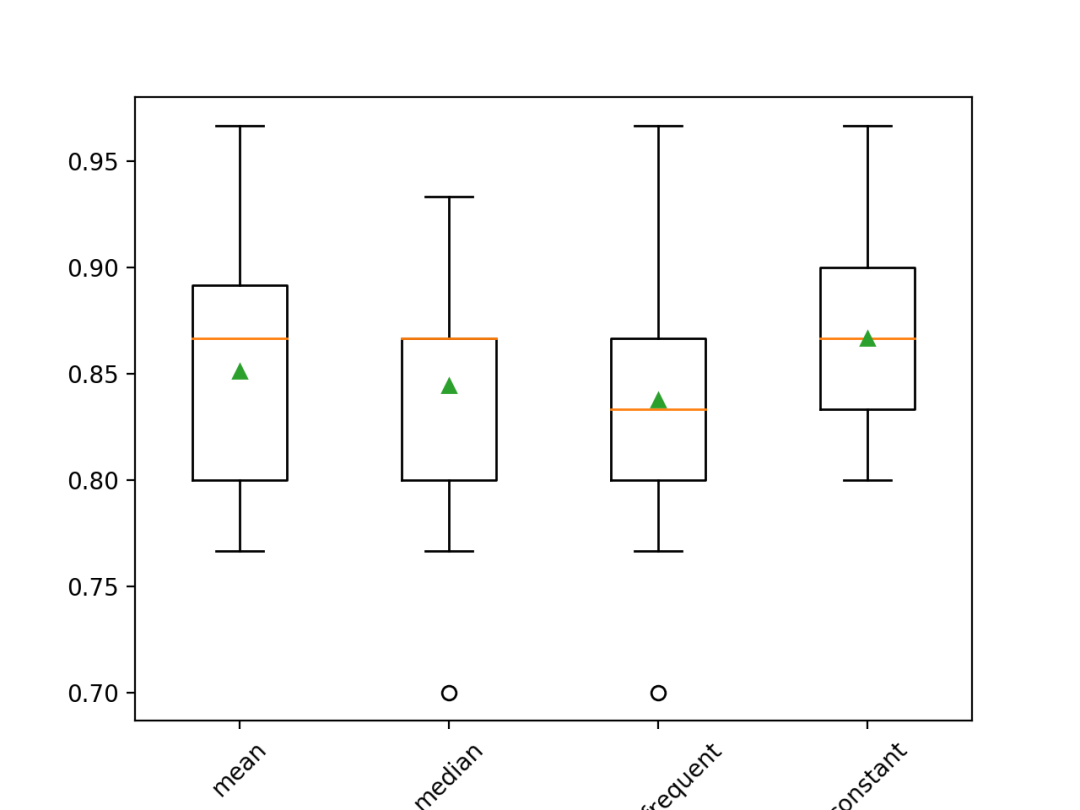
在病马数据集上利用不同统计策略的缺失值填充后所得模型结果的盒须图
在进行预测时的SimpleImputer转换
我们可能希望创作一个最终的模型流水线,利用的是常数填充缺失值的方式,使用随机森林算法,对新数据进行预测。我们可以先定义一个流水线,然后在所有可用数据上进行拟合,最后用predict() 函数进行转换,把新数据作为一个参数。重要的是,新数据中每一行的缺失值必须用NaN来表示。...# define new datarow = [2,1,530101,38.50,66,28,3,3,nan,2,5,4,4,nan,nan,nan,3,5,45.00,8.40,nan,nan,2,2,11300,00000,00000]
# constant imputation strategy and prediction for the hose colic datasetfrom numpy import nanfrom pandas import read_csvfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.impute import SimpleImputerfrom sklearn.pipeline import Pipeline# load dataseturl = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv'dataframe = read_csv(url, header=None, na_values='?')# split into input and output elementsdata = dataframe.valuesX, y = data[:, :-1], data[:, -1]# create the modeling pipelinepipeline = Pipeline(steps=[('i', SimpleImputer(strategy='constant')), ('m', RandomForestClassifier())])# fit the modelpipeline.fit(X, y)# define new datarow = [2,1,530101,38.50,66,28,3,3,nan,2,5,4,4,nan,nan,nan,3,5,45.00,8.40,nan,nan,2,2,11300,00000,00000]# make a predictionyhat = pipeline.predict([row])# summarize predictionprint('Predicted Class: %d' % yhat[0])
针对一行带有以NaN来标识缺失值的新数据,分类预测顺利完成。
总结
在这篇教程中,你找到了如何使用统计策略在机器学习中进行数据缺失值填充。
缺失值必须以NaN来标识,可以计算出一列数据的统计值,然用其来替换缺失值。
如何载入一份带有缺失值的CSV文件,并用NaN来标识缺失值,展现出每一列的缺失值数量和百分比。
如何用统计策略来填充缺失值,作为数据准备方法中的一个步骤,用于评估模型和用最终模型和新数据来拟合预测结果。
作者简介
Jason Brownlee,机器学习专业博士,通过亲自动手写教程的方式来指导开发人员如何使用现代机器学习方法来取得结果。原文标题:
Statistical Imputation for Missing Values in Machine Learning
原文链接:
https://machinelearningmastery.com/statistical-imputation-for-missing-values-in-machine-learning/
吴振东,法国洛林大学计算机与决策专业硕士。现从事人工智能和大数据相关工作,以成为数据科学家为终生奋斗目标。来自山东济南,不会开挖掘机,但写得了Java、Python和PPT。
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”拥抱组织











