一.NoSQL
1.什么是NoSQL
NoSQL:not only SQL,非关系型数据库
NoSQL是一个通用术语
-
指不遵循传统RDBMS模型的数据库
-
数据是非关系的,且不使用SQL作为主要查询语言
-
解决数据库的可伸缩性和可用性问题
-
不针对原子性或一致性问题
2.NoSQL和关系型数据库对比如下表
|
对比
|
NoSQL
|
关系型数据库
|
|
常用数据库
|
HBase、MongoDB、Redis
|
Oracle、DB2、MySQL
|
|
存储格式
|
文档、键值对、图结构
|
表格式,行和列
|
|
存储规范
|
鼓励冗余
|
规范性,避免重复
|
|
存储扩展
|
横向扩展,分布式
|
纵向扩展(横向扩展有限)
|
|
查询方式
|
结构化查询语言SQL
|
非结构化查询
|
|
事务
|
不支持事务一致性
|
支持事务
|
|
性能
|
读写性能高
|
读写性能差
|
|
成本
|
简单易部署,开源,成本低
|
成本高
|
3.NoSQL和BI、大数据的关系
BI(Business Intelligence):商务智能
-
它是一套完整的解决方案
-
BI应用涉及模型,模型依赖于模式
-
BI主要支持标准SQL,对NoSQL支持弱于关系型数据库
NoSQL和大数据相关性较高,但是NoSQL != 大数据
-
NoSQL产品是为了帮助解决大数据存储问题,但是大数据不仅仅包含数据存储的问题
-
通常大数据场景采用列存储数据库,如:HBase
二.Hbase
1.概述
HBase是一个领先的NoSQL数据库
-
是一个面向列存储的NoSQL数据库
-
是一个分布式Hash Map,底层数据是Key-Value格式
-
基于Google Big Table论文
-
使用HDFS作为存储并利用其可靠性
HBase特点
-
数据访问速度快,响应时间约2-20毫秒
-
支持随机读写,每个节点20k~100k+ ops/s
-
可扩展性,可扩展到20,000+节点
-
高并发
2.HBase发展历史
|
时间
|
事件
|
|
2006年
|
Google发表了关于Big Table论文
|
|
2007年
|
第一个版本的HBase和Hadoop0.15.0一起发布
|
|
2008年
|
HBase成为Hadoop的子项目
|
|
2010年
|
HBase成为Apache顶级项目
|
|
2011年
|
Cloudera基于HBase0.90.1推出CDH3
|
|
2012年
|
HBase发布了0.94版本
|
|
2013-2014
|
HBase先后发布了0.96版本/0.98版本
|
|
2015-2016
|
HBase先后发布了1.0版本、1.1版本和1.2.4版本
|
|
2017年
|
HBase发布1.3版本
|
|
2018年
|
HBase先后发布了1.4版本和2.0版本
|
3.应用场景
3.1.增量数据-时间序列数据
-
高容量,高速写入
-
HBase之上有OpenTSDB模块,可以满足时序类场景,比如传感器,系统监控,股票行情监控等
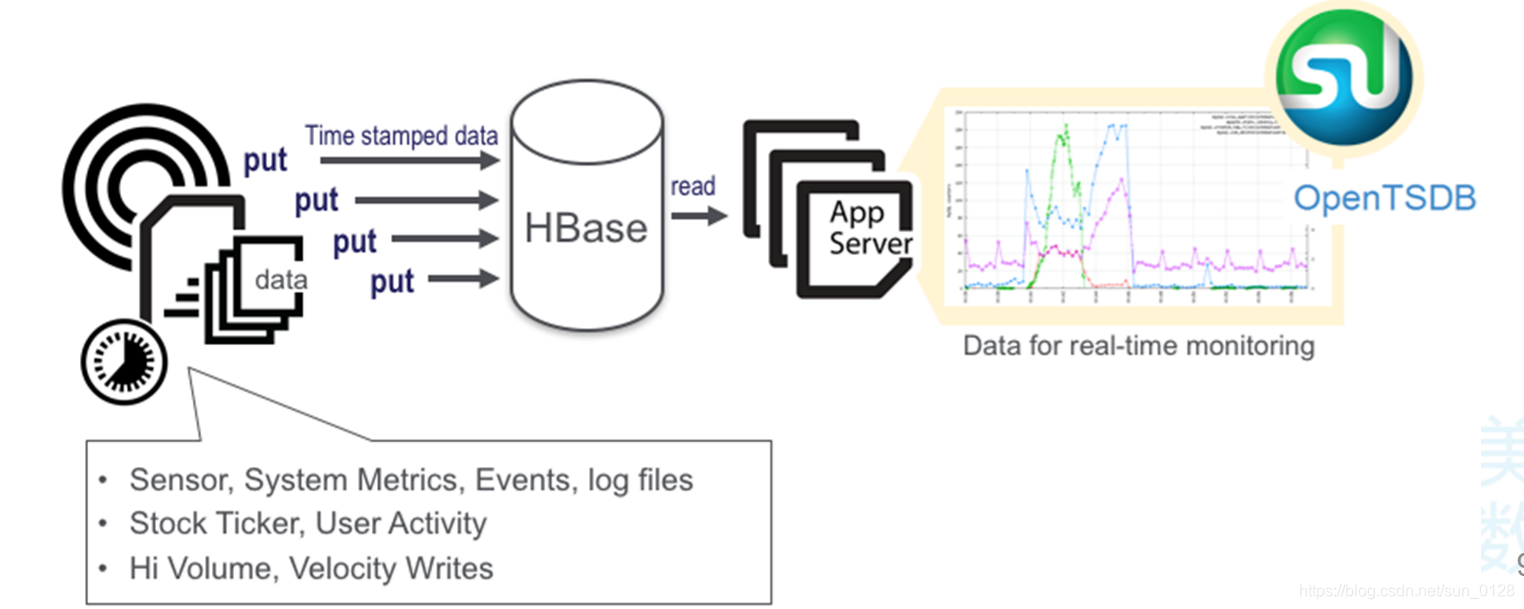
3.2.信息交换-消息传递
-
高容量,高速读写
-
通信、消息同步的应用构建在HBase之上,比如email,FaceBook等
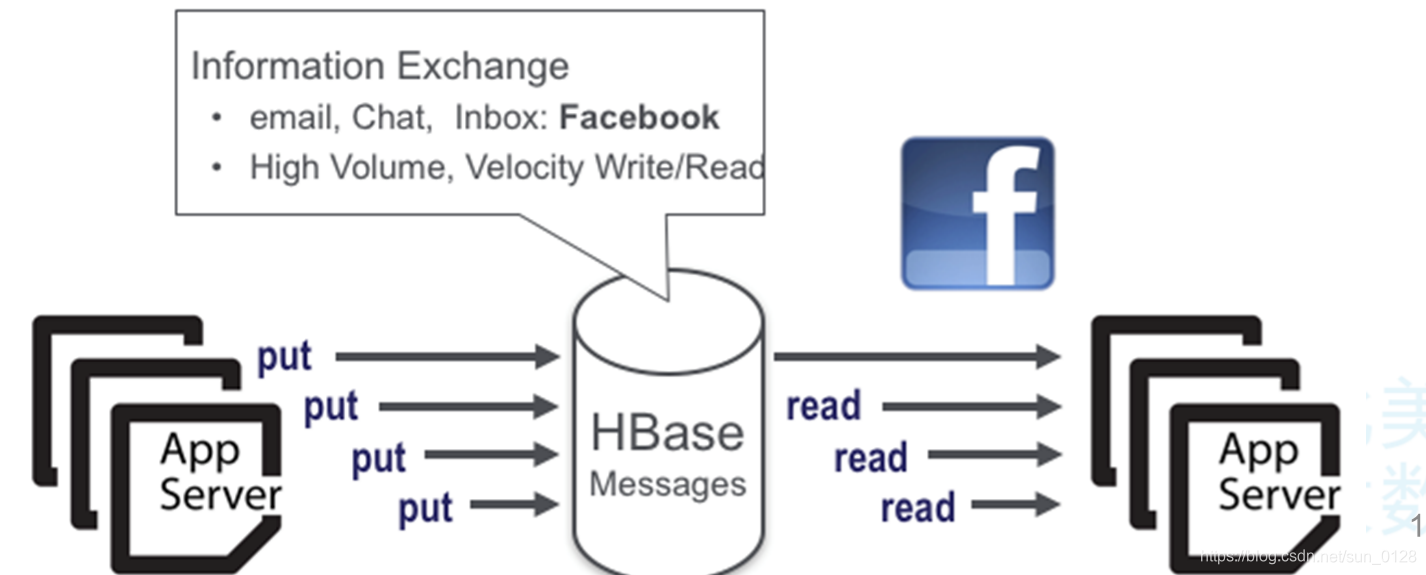
3.3.内容服务-Web后端应用程序
-
高容量,高速读写
-
头条类、新闻类的的新闻、网页、图片存储在HBase中
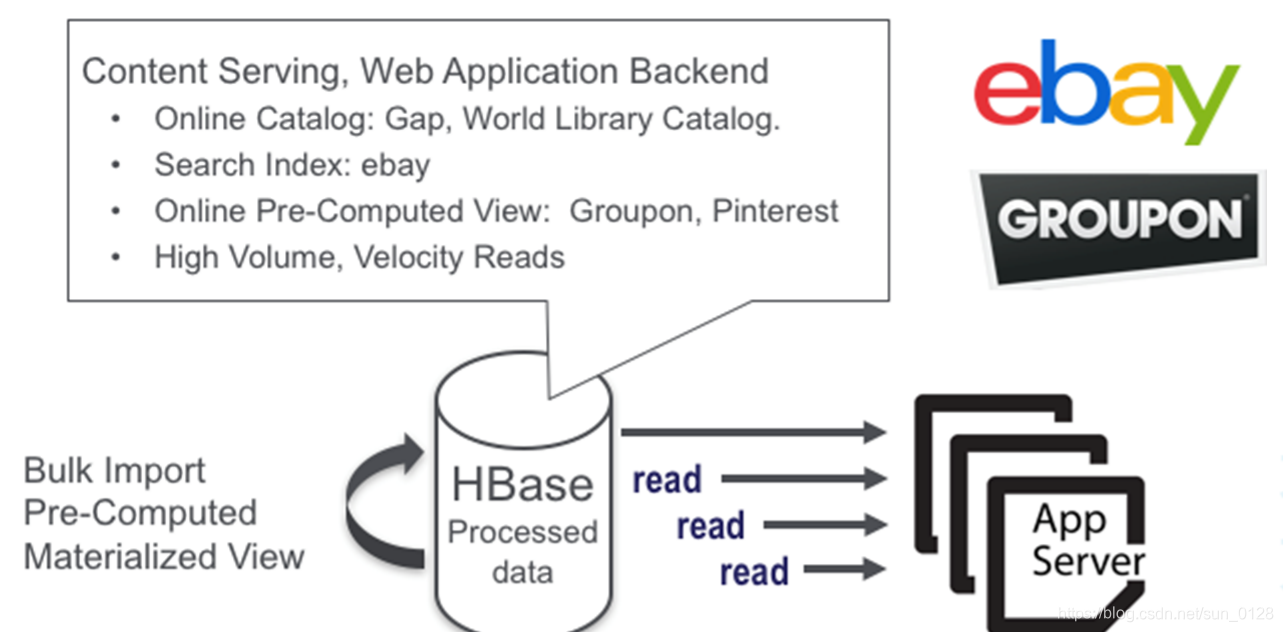
3.4.HBase应用场景示例
Facebook
-
9000 memcached instances,4000 shards mysql
-
2011全部迁移到HBase
Alibaba
-
自2010年以来,HBase一直为阿里搜索系统的核心存储
-
当前规模
-
3 个集群,每个有1000+ nodes
-
在Yarn上与Flink共享
-
每天提供超过10M+ ops/s 的服务
4.Apache HBase生态圈
HBase生态圈技术
-
Lily – 基于HBase的CRM
-
OpenTSDB – HBase面向时间序列数据管理
-
Kylin – HBase上的OLAP
-
Phoenix – SQL操作HBase工具
-
Splice Machine – 基于HBase的OLTP
-
Apache Tephra – HBase事务支持
-
TiDB – 分布式SQL DB
-
Apache Omid - 优化事务管理
-
Yarn application timeline server v.2 迁移到HBase
-
Hive metadata存储可以迁移到HBase
-
Ambari Metrics Server将使用HBase做数据存储
5.HBase分布式环境部署见如下链接
hbase安装
6.HBase架构
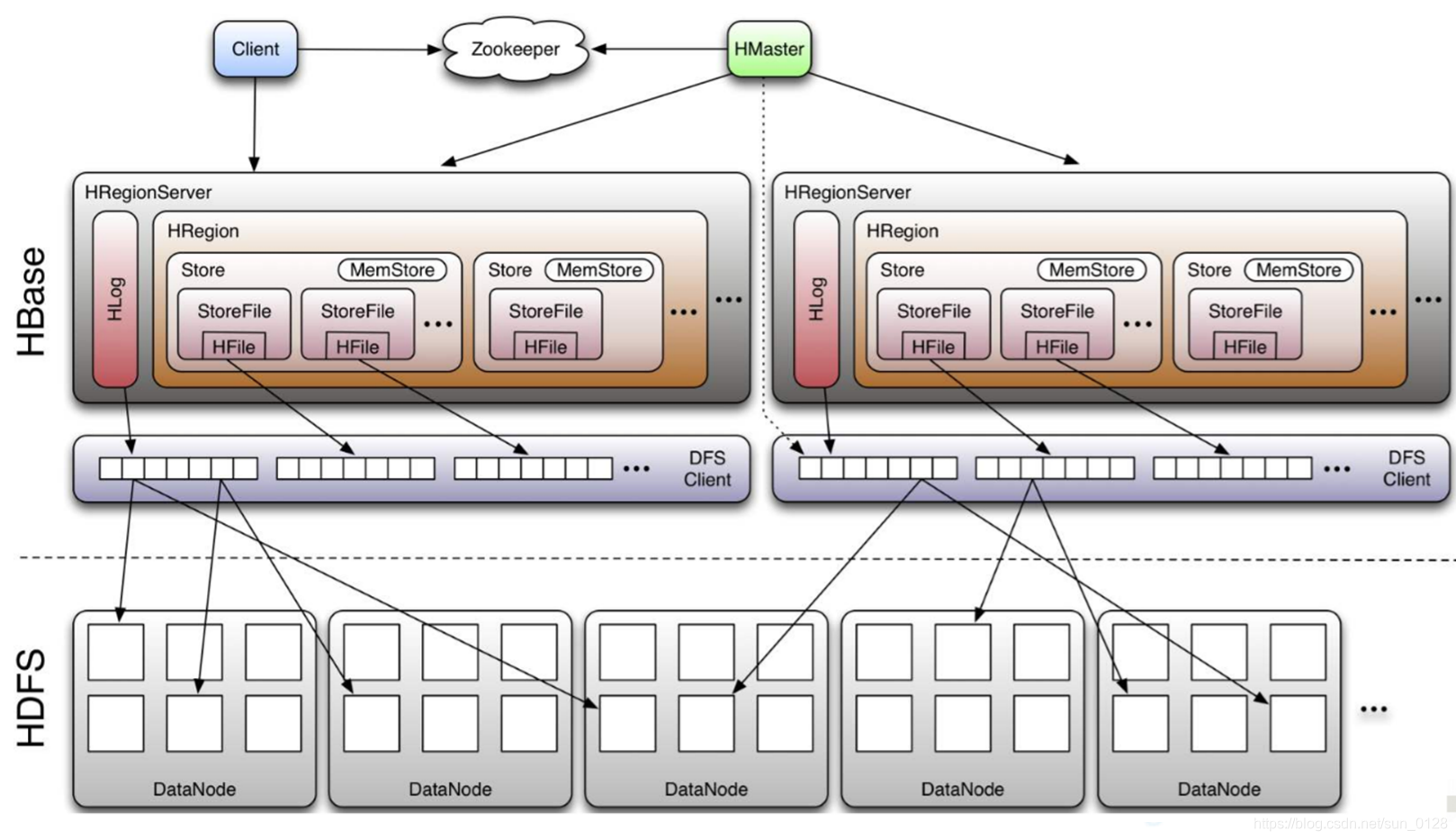
HBase采用Master/Slave架构
-
HMaster
-
RegionServer
-
Zookeeper
-
HBase Client
-
Region
HMaster的作用
-
是HBase集群的主节点,可以配置多个,用来实现HA
-
处理元数据的变更
-
监控RegionServer
-
负责RegionServer的负载均衡
-
处理RegionServer故障转移
-
通过ZooKeeper发布自己的位置给客户端
RegionServer
负责管理维护Region,存储HBase实际数据
-
一个RegionServer包含一个WAL、一个BlockCache (读缓存)和多个Region
-
一个Region包含多个存储区,每个存储区对应一个列族
-
一个存储区由多个StoreFile和MemStore组成
-
一个StoreFile对应于一个HFile和一个列族
-
HFile和WAL作为序列化文件保存在HDFS上
-
Client与RegionServer交互
RegionServer功能
-
负责管理HBase的实际数据
-
处理分配给它的Region
-
刷新缓存到HDFS
-
维护HLog
-
执行Compaction
-
负责处理Region分片
Region和Table
-
单个Table(表)被分区成大小大致相同的Region
-
Region是HBase集群分布数据的最小单位
-
Region被分配给集群中的RegionServer
-
一个Region只能分配给一个RegionServer
逻辑架构 - Row
-
Rowkey(行键)是唯一的并已排序
-
Schema可以定义何时插入记录
-
每个Row都可以定义自己的列,即使其他Row不使用,相关列定义为列族
-
使用唯一时间戳维护多个Row版本,在不同版本中值类型可以不同
-
HBase数据全部以字节存储
HBase元数据管理
-
数据管理目录
-
系统目录表hbase:meta
-
存储元数据
-
ZooKeeper存储hbase:meta表的位置信息
-
HBase实际数据存储在HDFS上
7.HBase Shell
HBase Shell是一种操作HBase的交互模式,支持完整的HBase命令集
|
命令类别
|
命令
|
|
General
|
version, status, whoami, help
|
|
DDL
|
alter, create, describe, disable, drop, enable, exists, is_disabled, is_enabled, list
|
|
DML
|
count, delete, deleteall, get, get_counter, incr, put, scan, truncate
|
|
Tools
|
assign, balance_switch, balancer, close_region, compact, flush, major_compact, move, split, unassign, zk_dump
|
|
Replication
|
add_peer, disable_peer, enable_peer, remove_peer, start_replication, stop_replication
|
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv \
-Dimporttsv.separator=, \
-Dimporttsv.columns="HBASE_ROW_KEY,order:numb,order:date" \
customer file:///home/vagrant/hbase_import_data.csv
8.使用Java API操作HBase
-1)创建Maven项目并添加依赖
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>1.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.2.0</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
package com.sunyong;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
public class HBaseClient {
private Admin admin;
private Connection conn;
private Configuration conf;
@Before
public void init() throws IOException {
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "192.168.56.120");
conf.set("hbase.zookeeper.property.clientPort", "2181");
conn = ConnectionFactory.createConnection(conf);
admin = conn.getAdmin();
}
@After
public void end(){
admin=null;
conn=null;
conf=null;
}
@Test
public void createTable() throws IOException {
HTableDescriptor student = new HTableDescriptor(TableName.valueOf("student"));
student.addFamily(new HColumnDescriptor("info"
));
student.addFamily(new HColumnDescriptor("score"));
admin.createTable(student);
}
@Test
public void isTableExists() throws IOException {
System.out.println(admin.tableExists(TableName.valueOf("student")));;
}
@Test
public void putData2Table() throws IOException {
Table student=conn.getTable(TableName.valueOf("student"));
Put put = new Put(Bytes.toBytes("1001"));
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("name"),Bytes.toBytes("zhangsan"));
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("sex"),Bytes.toBytes("female"));
put.addColumn(Bytes.toBytes("score"),Bytes.toBytes("course"),Bytes.toBytes("math"));
put.addColumn(Bytes.toBytes("score"),Bytes.toBytes("score"),Bytes.toBytes("89"));
student.put(put);
}
@Test
public void getDataFromTable() throws IOException {
Table student=conn.getTable(TableName.valueOf("student"));
Get get = new Get(Bytes.toBytes("1001"));
Result result = student.get(get);
Cell[] cells = result.rawCells();
for (Cell cell :
cells) {
System.out.println("rowkey:"+Bytes.toString(CellUtil.cloneRow(cell)));
System.out.println("列簇 :"+Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.println("列名 :"+Bytes.toString(CellUtil.cloneQualifier(cell)));
System.out.println("值 :"+Bytes.toString(CellUtil.cloneValue(cell)));
System.out.println("*****************");
}
}
@Test
public void dropTable() throws IOException {
admin.disableTable(TableName.valueOf("student"));
admin.deleteTable(TableName.valueOf("student"));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106









