
Python部落(python.freelycode.com)组织翻译,禁止转载,欢迎转发。
介绍
在这个kernel中,我将演示如何使用 Sohier 的 BigQuery 辅助模块来安全查询我们在 Kaggle 中获得的最大 BigQuery 数据集.数据大小总共3TB,通过扫描大量大表格,你可以看到对于我来说快速耗尽5TB/30天 的配额实在是太容易了.
bq_helper 模块简化了我们在 Kaggle 中通过 BigQuery Python 客户端库要做的日常只读任务,让资源管理变得很轻松.由于我们做了身份验证工作,这个辅助类只能在 Kernels 中运行.这意味着你不必担心诸如管理证书或输入信用卡信息才能学习如何使用 BigQuery 数据集等事项.
你会学到以下内容:
1. 创建一个 BigQueryHelper 对象
2. 了解数据集中的表格
3. 在执行前预估查询量大小
4. 安全查询,转化为 pandas.dataframe 并可视化结果集
在 kernel 的最后,你不仅能学习如何安全查询 BigQuery 数据集,还能得出 GitHub 开源项目中使用的最流行的许可证. 现在让我们开始吧!

创建一个 BigQueryHelper 对象
首先, 我们利用 bq_helper 来创建一个 BigQueryHelper 对象.这需要传递两个参数:工程名称和数据集名称.点击 kernel 的 "Data" 选项卡,就可以找到工程名称和数据集名称.选择任一表格,可以找到被 . 分隔的地址的前两部分内容(在蓝色 BigQuery 表格框中),分别对应工程名称和数据集名称:
bigquery-public-data
github_repos
让我们为 GitHub 数据集创建一个 BigQueryHelper 对象:

如果你使用的是你自己的 kernel, 点击编辑器面板底部控制台中的 "Environment Variables" 选项卡,你就会看到在你的环境中已经创建了一个 BigQueryHelper 对象
通过只读函数来了解你的数据
既然我们已经有了 GitHub 数据集的 BigQueryHelper 对象,现在就可以通过一些超级简单的只读函数来了解数据的更多信息,包含:
接下来,我们来运行一个最简单的只读任务来列出数据集中的所有表格.当然你也可以通过查看 "Data" 选项卡来预览这些表格.

运行正常.我们能够确认看到的9个表格和 "Data" 选项卡中展示的是相同的.
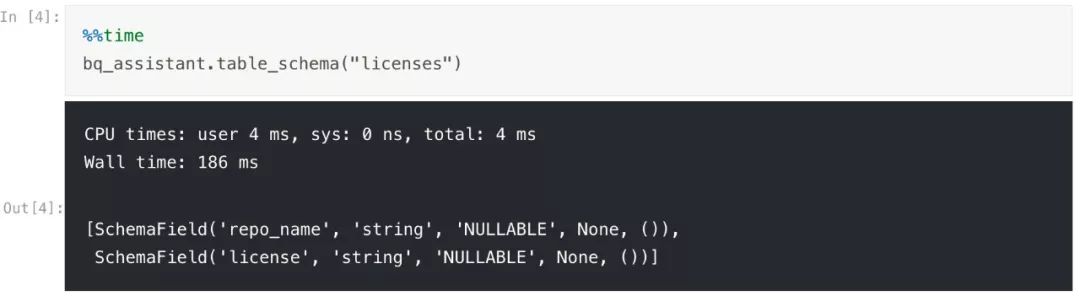
GitHub BigQuery 的数据集并不包含任何表的列级别描述(否则你在 "Data" 选项卡的文件预览中也能看到它们).在包含列级别描述的情况,可以通过调用 bq_helper 查看表格概要来展示它们:
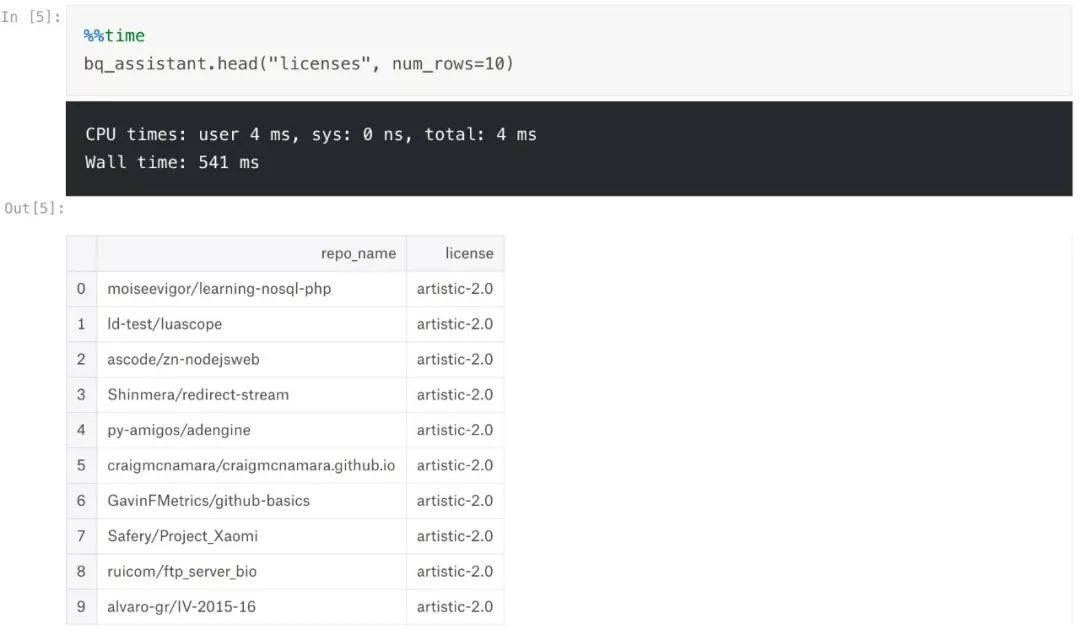
最后,除了可以通过 "Data" 选项卡来预览表格的前100行,还有另外一种查看前几行的方式是调用 bq_helper .
由于 SELECT * 会扫描你指定列的所有行(这会潜在的消耗很多配额),所以在仅仅浏览数据的情况下,最好避免使用它.这里你可以参照 Sohier notes 中使用 list_rows 这个高效方法一样,通过使用 head 来查看前几行.让我们在 licenses 这个表中试一下:
目前, bq_helper 提供了一些可用的辅助函数,让你在编写查询语句之前能安全的了解你的数据.如果你希望看到更多的功能,可以随时开启问题或者提交 PR 到 GitHub repo 来通知我们.
预估查询大小
最精彩的部分开始了.我们渴望马上开始分析 GitHub BigQuery 数据集以便深入分析开源软件的发展,但考虑到在查询中需要扫描的数据量,还是应该谨慎一些.毕竟我们只有5TB的量!
幸运的是, bq_helper 模块早已经为我们提供了工具,我们可以很容易的估计出查询量大小.只需要依据 BigQuery 的 SQL 规范简单的写一个查询语句,然后调用 estimate_query_size 函数就可以得到以 GB 为单位的查询大小.现在我们试一下.
在 kernel 中,我写了一个查询,从 commits 表中 SELECTS 了2000条短的提交消息.让我们使用 estimate_query_size 看一下会扫描的数据量.
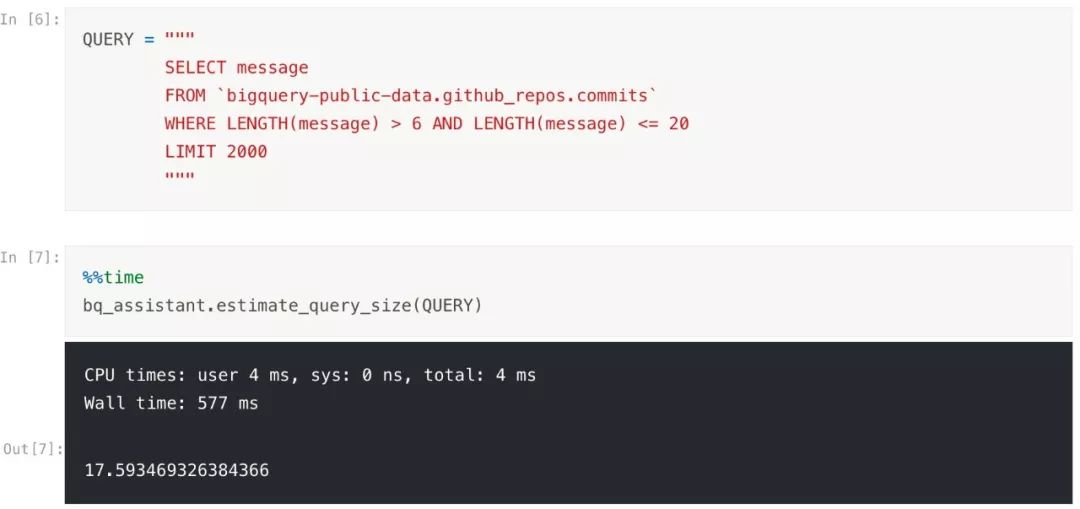
运行完毕后,刚才的查询消耗大概会接近18GB. 现在你能体会到在不需要实际消耗配额的情况下就能知道数据量大小实在是太有用了! 请注意查询并不会返回一个17.6GB 的对象--它仅仅返回了2000条非常短的提交消息.
现在我们把返回结果扩大一倍,再来估计一下查询大小:
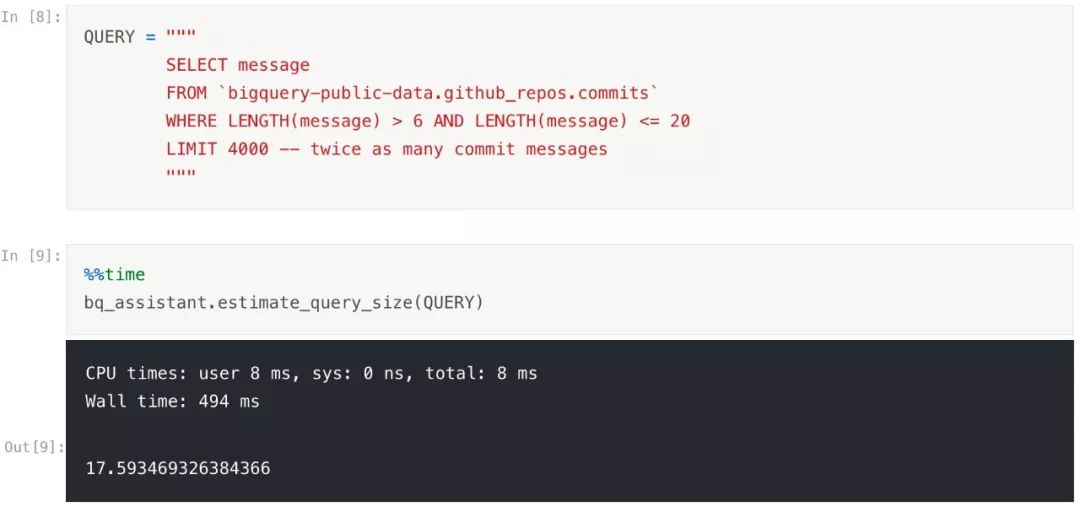
哈哈,怎么返回了完全相同的估计值? 这表明使用 LIMIT 来减少查询返回的数据量实际上并没有改变查询扫描的数据量.对于你的配额来说,这是一个不利的消息.
让我们再做一个实验,是有关我包含的 WHERE 子句的,我们去掉 WHERE 和 LIMIT之后,看看是否会增加查询扫描的数据量:

我们再次扫描了同样的 17.6GB 的数据,现在我们已经清楚的知道这是信息字段的总大小.我希望你能得到的经验是你扫描的数据与你期望作为查询结果返回的数据并不相等.我建议你查看 BigQuery 的最佳实践文档来获取更多信息.
不要泄气,还是有一些好消息的! 当你运行了一个查询请求,结果将会默认缓存一段时间.所以只要你在同一个 notebook 交互式会话中,你就可以多次运行 cell/query 而不用消耗额外的配额.这是特别有用的,因为当你点击"New Snapshot"来保存作业时,你的 kernel 会从上到下重新执行.
安全查询
既然我们满意与手头上的大批数据,并且有把握估计到查询量大小,让我们实际取一些数据!
query_to_pandas_safe 是另外一个 bq_helper 函数,用来执行查询.相比基本的BigQuery Python 客户端库,它有两个优点:
尝试使用 query_to_pandas_safe 来执行一条查询.因为它要扫描 17.6GB 的数据,在正常情况下,查询将会运行失败.

由于 query_to_pandas_safe, 我们并没有真正执行大于1GB 的查询.如果想让查询量大一些,可以添加一个参数 max_gb_scanned. 例如如果想成功执行这个查询,我需要设置 max_gb_scanned=18
合并为四步
通过以上学习,我们已经知道如何处理 BigQuery 大数据集了.现在尝试将以下操作结合在一起:创建合理大小查询,获取pandas dataframe返回值,可视化结果集.
回到 kernel 刚开始的问题,得到在 GitHub 工程中最经常使用的许可证.写完查询语句后,我将:
预估查询量大小,确保不要太大
使用 query_to_pandas_safe 执行查询并返回 pandas dataframe 结果集
探查结果集
可视化结果集
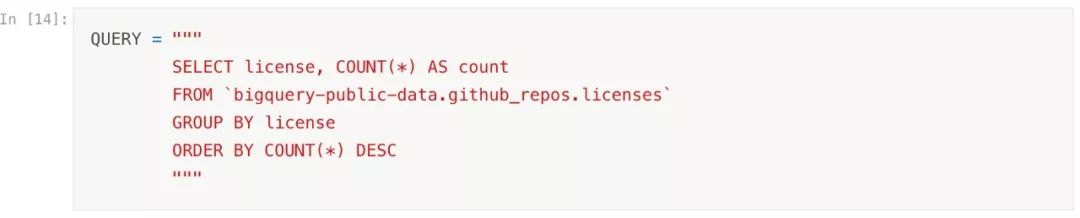
步骤1.预估上面语句的查询量

执行此次查询将仅消耗我0.02GB的配额.而令我满意的是,我的配额是30天5TB.
步骤2.使用 query_to_pandas_safe 获取 pandas dataframe 返回值

执行正常,由于我的查询量小于1GB,没有异常退出.
步骤3.探查结果集
现在结果已经在 pandas dataframe 中,操作数据会变得超简单.我们先来确认 dataframe 的大小并与我们刚刚扫描过的数据大小(0.02GB)做个比较:

小很多! 再次重申一下你所扫描的数据与查询后作为结果集返回的数据是完全不一样的.这是因为 BigQuery 扫描了 licenses 表格中 license 字段的所有内容.
我们看一下返回的前几行的内容:
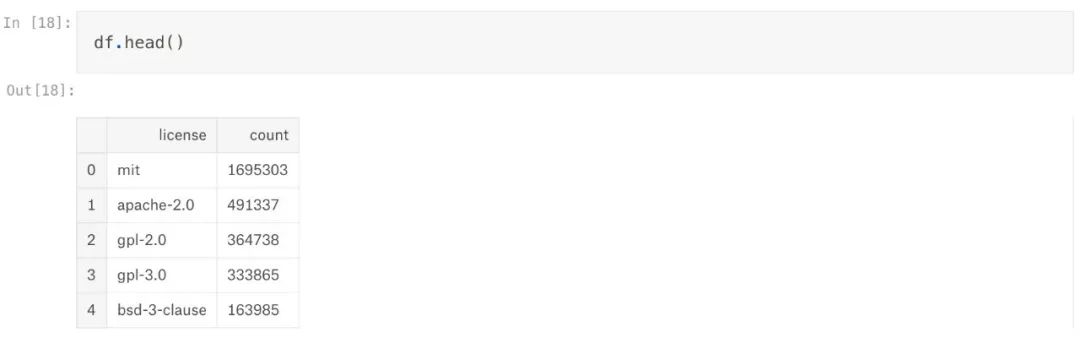
很明显, MIT 是 GitHub BigQuery 开源项目数据集中最流行的许可证.另外我们返回了多少个许可证呢?

我们已经得到了数据集中使用的15个许可证中每一个的数目.
步骤4.可视化结果集
将查询得到的结果集可视化后会变得更加真实.我会使用 matplotlib 结合 seaborn 创建一个条形图来展示 GitHub 工程中所使用的许可证数目.
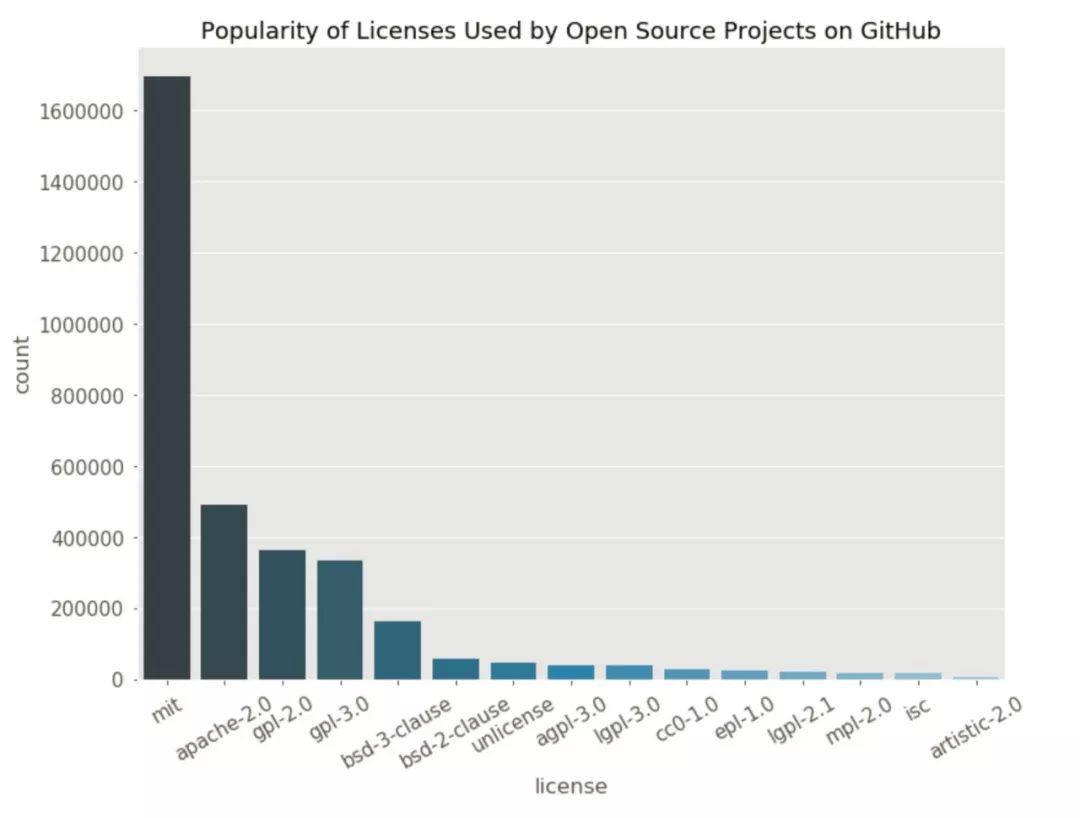
干的漂亮!目前,我们已经知道 MIT 是最流行的许可证了,但通过条形图我们可以很直白对比出次流行的许可证分别是: Apache 2.0, GPL 2.0 和 GPL 3.0. 顺便说一下, 我的这个 kernel 是 Apache 2.0的许可证:)
结尾
我希望你能喜欢这个 kernel,并且至少学到了一些新东西.在知道 bq_helper 中的函数可以防止我意外超过我的配额后, 我对探索这个庞大的3TB数据集有了信心.以下是 Kaggle Kernels 中使用 BigQuery 数据集的一些资源:
SQL 新手?注册2月15日开始为期5天的 SQL Scavenger Hunt 来学习这种实用的语言
Kaggle 中 BigQuery 资源汇总
来这里了解更多 BigQuery Python 客户端库
探索 Kaggle 中所有可用的 BigQuery 数据集--每个都有各自的"starter kernel"让你来 fork
英文原文:https://www.kaggle.com/mrisdal/safely-analyzing-github-projects-popular-licenses/notebook
译者:郭明







