
当前关于AI/ML的讨论大多偏向算法和应用,关于底层的基础设施却少有讨论,形成了一个不容忽视的缺环。系统研究的滞后会从根本上延缓AI/ML技术的创新和实践。另一方面,开发适用于AI/ML的硬件也需要与传统硬件不同的思路和方法,如何找到两者更好的结合?
在这样的背景下,一群AI/ML界的大牛发起了一个新的会议——SysML,这个会议专门针对系统和机器学习交叉研究领域,目的是在这些领域之间建立新的联系,包括确定学习系统的最佳实践和设计原则,以及开发针对实际机器学习工作流程的新颖学习方法和理论。
看看SysML的这些发起人:
Jennifer Chayes 微软Technical Fellow,微软新英格兰研究院和微软纽约研究院院长
Bill Dally,英伟达VP兼首席科学家
-
Jeff Dean,谷歌大脑负责人
Michael I. Jordan,统计机器学习宗师
李飞飞,斯坦福人工智能实验室主任/谷歌云首席科学家
Yann LeCun,Facebook首席科学家
Alex Smola,亚马逊云机器学习负责人
Dawn Song,伯克利教授
邢波,CMU教授
SysML 2018在斯坦福举行,200篇接收论文,注册名额5分钟内就被抢购一空。
会上,Michael Jordan发表了《SysML:前景与挑战》的演讲,其中提到了机器学习近期和远期的挑战。Jordan认为,目前机器学习还存在很多不确定性、推理、决策、鲁棒性和可扩展的问题,远远没有得到解决,更不用提社会、经济和法律问题了。

乔丹提到的机器学习近期挑战,包括管理端云互动系统、设计能够自动寻找抽象的系统,以及能够自我解释的系统。经济会发展,市场会变得更好,但我们做机器学习的人应该把目标定得更高,不止是更好的做BP。
Jordan还指出,当前的“系统+ML”研究的目标还定得非常低,很多人只想着构建一个“平台”(platform),而不是一个“生态”(ecosystem),比如推荐电影的平台跟推荐餐厅或股票的平台各不兼容。
下面,我们重点介绍Jeff Dean在SysML 2018的主旨演讲《系统与机器学习的共生》(Systems and Machine Learning Symbiosis)。这是一个宏大的目标,也是挑战,正如Jeff Dean演讲PPT所示,现在上传到arXiv的论文数量已经超过了摩尔定律的增长;直接在ML模型里批处理(batching),也常常让“让他感到头痛”。

演讲的第一部分是用于机器学习的系统。他首先介绍了通用处理器性能趋势,指出经过数十年的指数式增长,单核性能保持稳定。
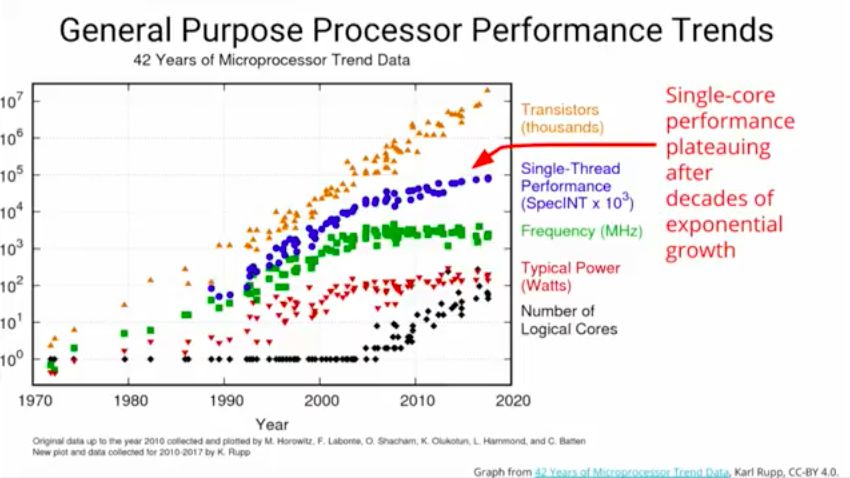
就在那时深度学习创造出了巨大的计算需求。在terabyte甚至petabyte大小的训练数据集上训练强大却昂贵的深度模型。再加上AutoML等技巧,可以将期望训练算力扩大5到1000倍。

在系统中使用昂贵深度模型的推理,有以下特点:每秒数十万的请求;延迟要求几十毫秒;数十亿用户。

因此我们需要更多的计算力,而深度学习正在改变我们设计计算机的方式。深度学习具有的两种特殊计算性能:可以降低精度,浮点计算;出现了很多专门的深度学习模型运算。

为此,谷歌研发了TPU,第一代TPU是用于神经网络推理的芯片:92 T ops/秒 of 8位 量化整数运算,用于搜索请求、神经机器翻译、言语和图像识别、AlphaGo比赛等。


第一代TPU对推理起到了巨大的帮助,但不能做训练。对于研究者的生产力和不断增多的问题来说,加快训练速度至关重要。于是,谷歌推出了第二代TPU,一个TPU由四个专用集成电路组成,配有64GB的“超高带宽”内存。这一组合单元可以提供高达180 teraflops的性能,内存为64 GB HBM, 2400 GB/秒mem BW。

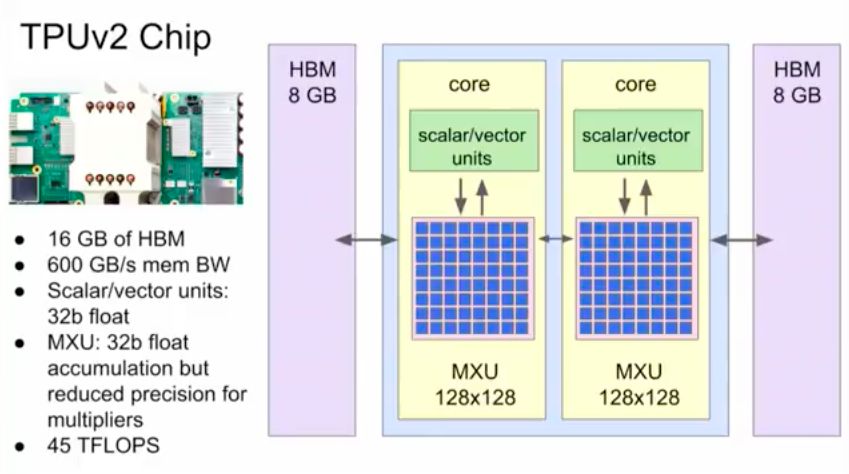


今年晚些时候,谷歌计划增加一个集群选项,让云客户将多个TPU聚合成一个“Pod”,速度达到petaflop的范围。而当时内部使用的Pod包括64个TPU,总吞吐为11.5 petaflops。

Cloud TPU是谷歌设计的硬件加速器,为加速、拓展特定tensorflow机器学习workload而优化。每个TPU里内置了四个定制ASIC,单块板卡的计算能力达每秒180 teraflops,高带宽内存有64GB。某些程序只会对CPU、GPU、TPU进行微小的修改,某些程序通过同步数据并行度进行缩放,而不能在TPU pod上进行修改。

当然,Jeff Dean重点推荐了谷歌刚刚发布不久的Cloud TPU。谷歌设计Cloud TPU是为了给TensorFlow的workload提供差异化性能,并让机器学习工程师和研究人员更快速地进行迭代。
Lyft 自动驾驶的软件总监Anantha Kancherla说自从用了谷歌云TPU,最让我们惊艳的是它的速度,通常需要几天才能完成的工作现在几个小时就可以了。
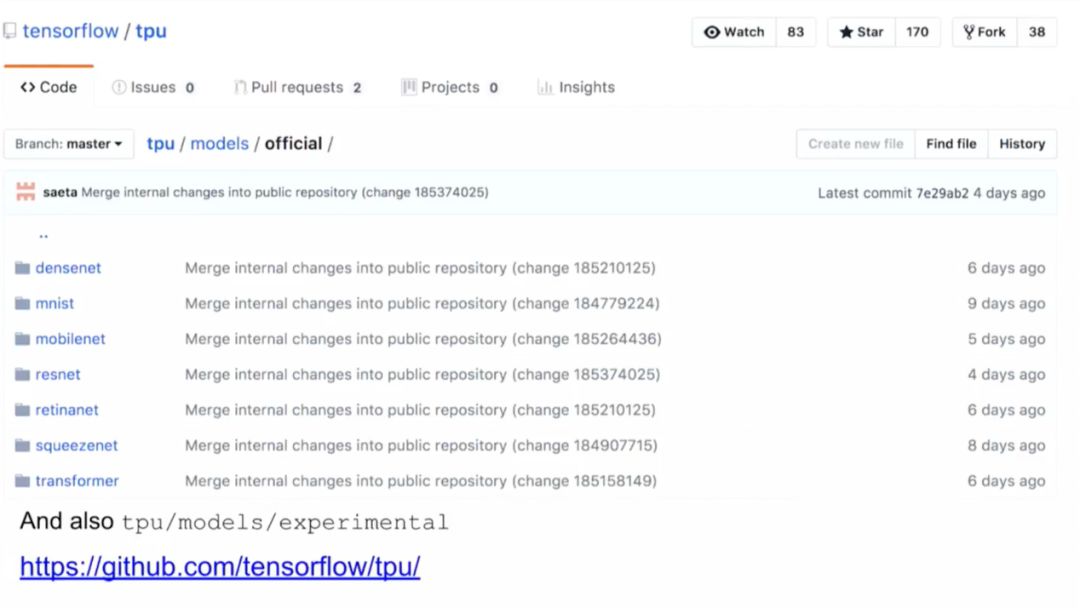
如Resnet,MobileNet,DenseNet和SqueezeNet(物体分类),RetinaNet(对象检测)和Transformer(语言建模和机器翻译)等模型实现可以帮助用户快速入门:https://github.com/tensorflow/tpu/
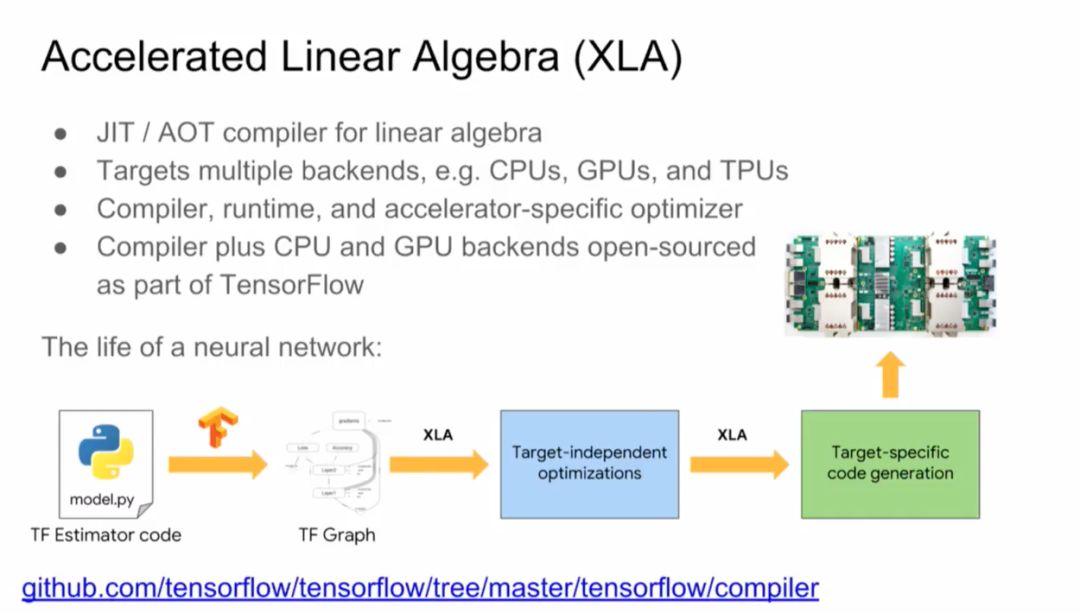
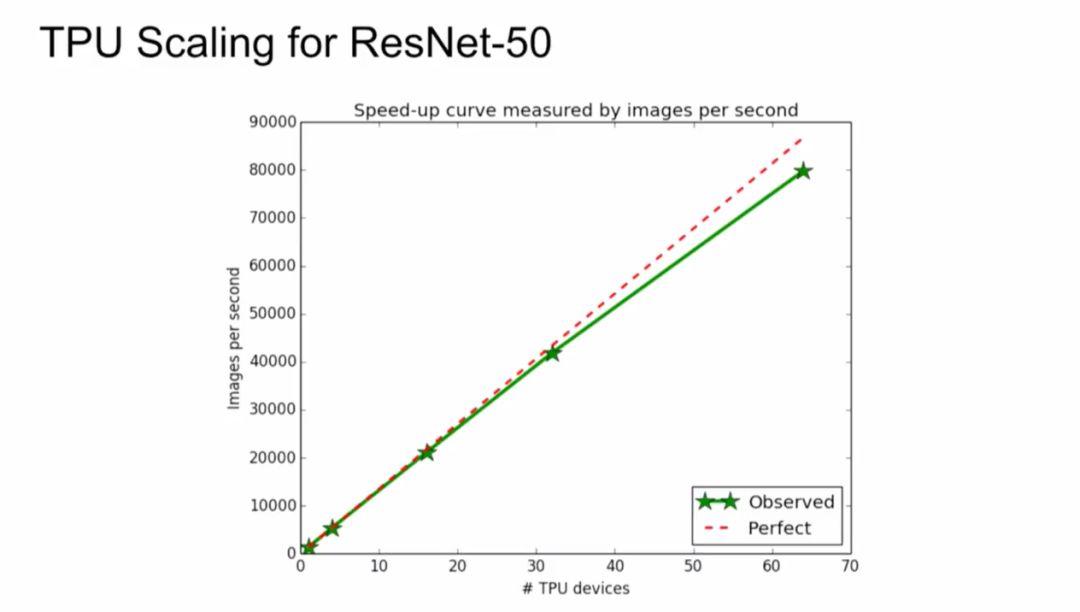
使用单个 Cloud TPU,训练 ResNet-50 使其在 ImageNet 基准挑战上达到期望的准确率。
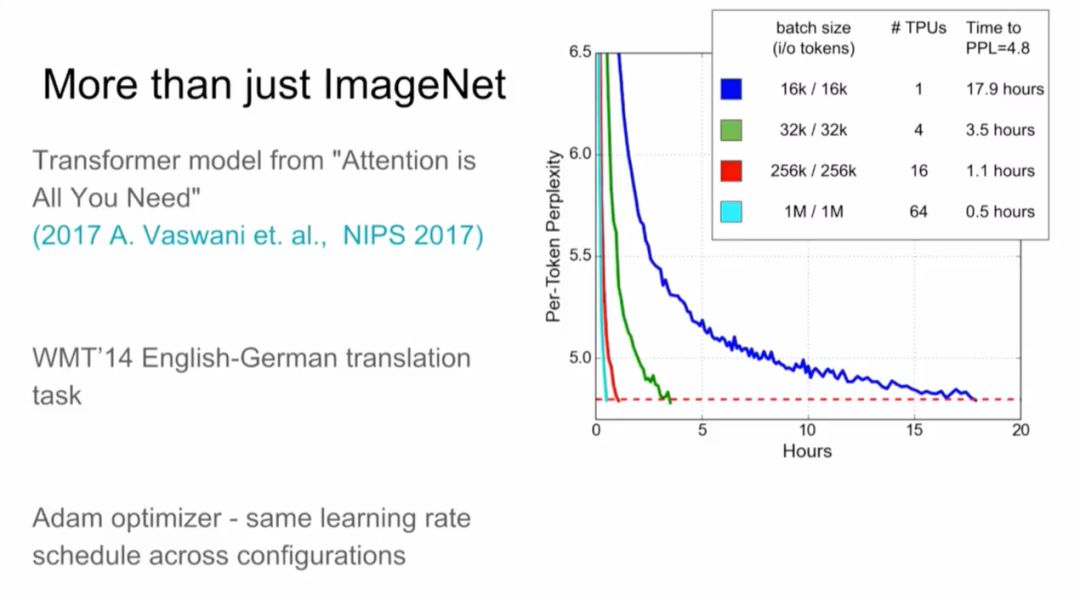

1000个TPU会无偿给到最顶尖的研究人员,他们将开放自己机器学习的研究,我们非常期待这些研究结果。

在未来,我们将如何建造深度学习加速器?
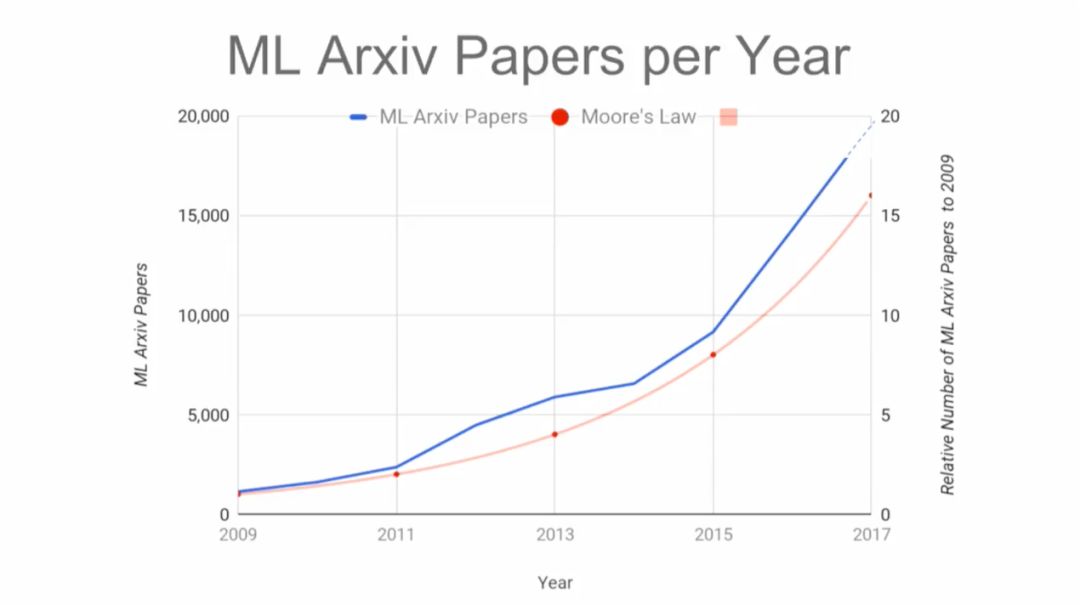
在Arxiv上的机器学习的论文逐年增长,速度已经超过摩尔定律。如果你现在开始做ASIC,大约两年后能够流片,而这款芯片需要能够持续使用3年。换句话说,必须看清楚未来5年的技术发展,但是,我们能够看清吗?怎样看清?


一些必须考虑的问题包括精度、稀疏性和嵌入等等。Jeff Dean说,因为不得不直接在ML模型中进行批处理(batching),他常常感到很头痛。
极低精度训练(1-4位权重,1-4位激活)能否适用于通用问题?我们应该如何处理疏密混合的专家路由?如何处理针对某些问题非常巨大的嵌入?我们是否应该专门为处理大的批量建立机器?至于训练算法,SGD一类的算法还会是主流训练范式吗?像K-FAC一类的大批量二阶方法会是更好的选择吗?


在System for ML这节,Jeff Dean谈了机器学习如何直接影响系统。现在,很多系统实际上都没有用到机器学习,但这一点应该得到转变。一个很好的例子就是高性能机器学习模型,这也是谷歌大脑最近在从事的一个研究重点。


对于大规模模型来说,并行计算很重要,模型的并行也很重要。让不同的机器计算不同的模型,或者模型的不同部分,就避免了单台机器内存不足的问题,将来让模型扩展到更多机器上也更加方便。
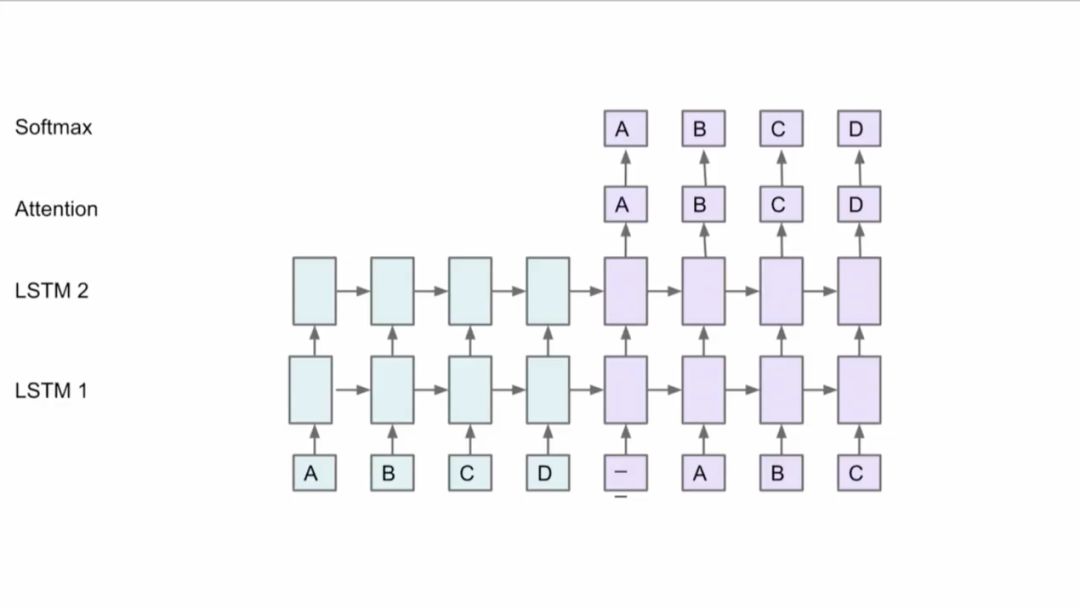
但是,如何将模型分布到不同机器上并且取得好的性能是很难的。Jeff Dean以下面这个网络为例,比如有两个LSTM,有Attention机制,在顶层有Softmax,你可以将方框中的部分放到不同的GPU卡上,因为这些部分都有同样的参数,这些层也不用移动。

此外,谷歌大脑还在进行一项研究,用强化学习来替代一部分硬件上的计算。你将计算视为算子和dependencies组成的graph,然后给一组硬件,比如你想在4块GPU或者8块GPU上运行这个模型,结果整个过程成了很好的强化学习过程(见下图)。
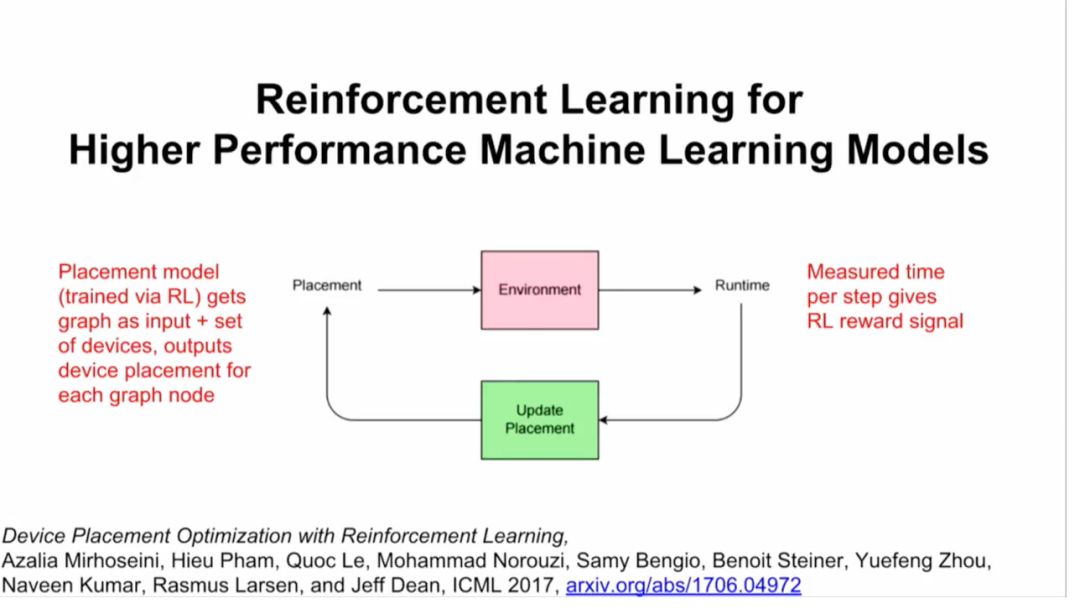
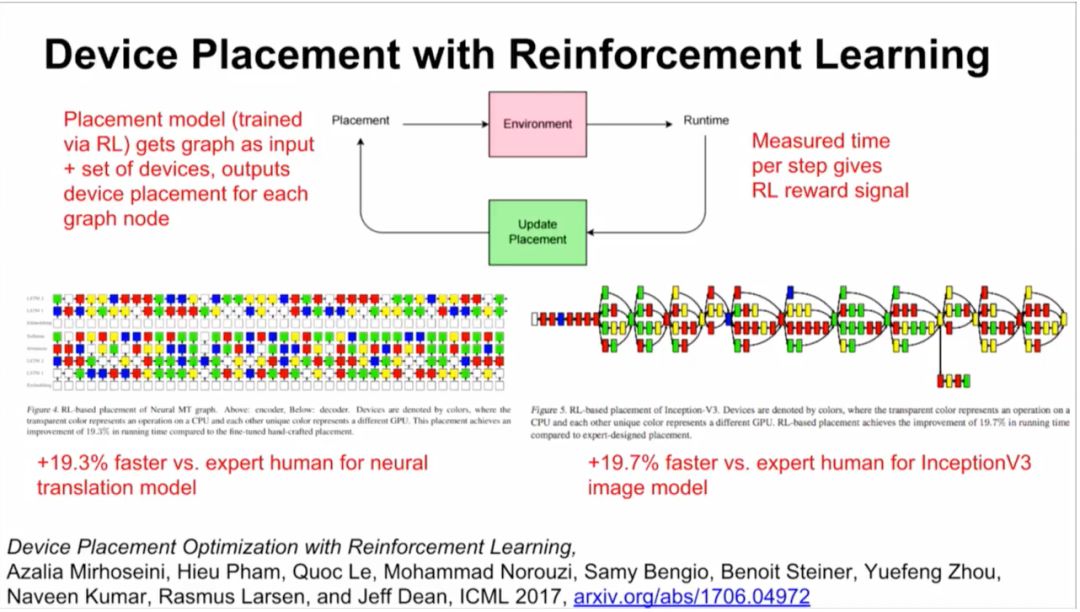
结果:比人类专家要快19.3%(神经转换模型)和19.7%(InceptionV3图像模型)。
之后,谷歌大脑将上述研究泛化,提出了一个层次模型(Hierarchical Model),将计算图有效地放置到硬件设备上,特别是在混合了CPU,GPU和其他计算设备的异构环境中。这项研究提出了一种方法,叫做“分层规划器”(Hierarchical Planner),能够将目标神经网络的runtime最小化,这里的runtime包括一次前向传播,一次BP,一次参数更新。
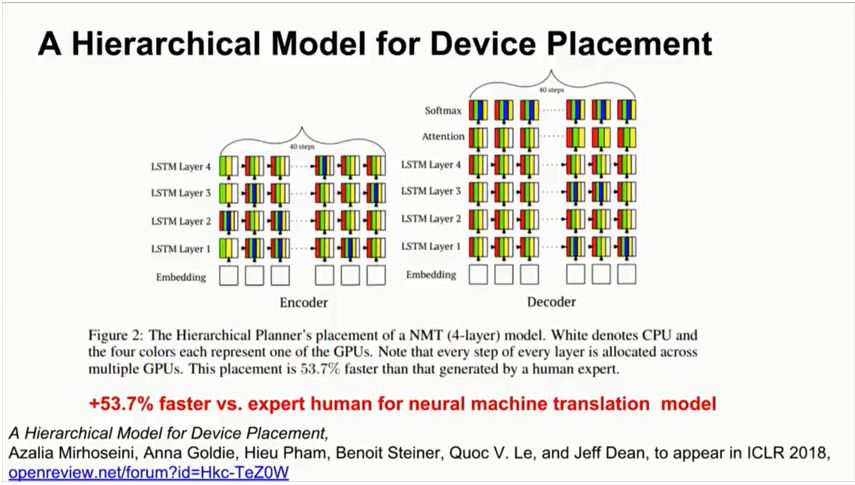
为了测量运行时间,预测全部在实际的硬件上运行。方法完全是端到端的,扩展到包含超过80,000个运算的计算图。最终,新方法在图中找到了高度细化的并行性,比以前的方法大幅提高速度。

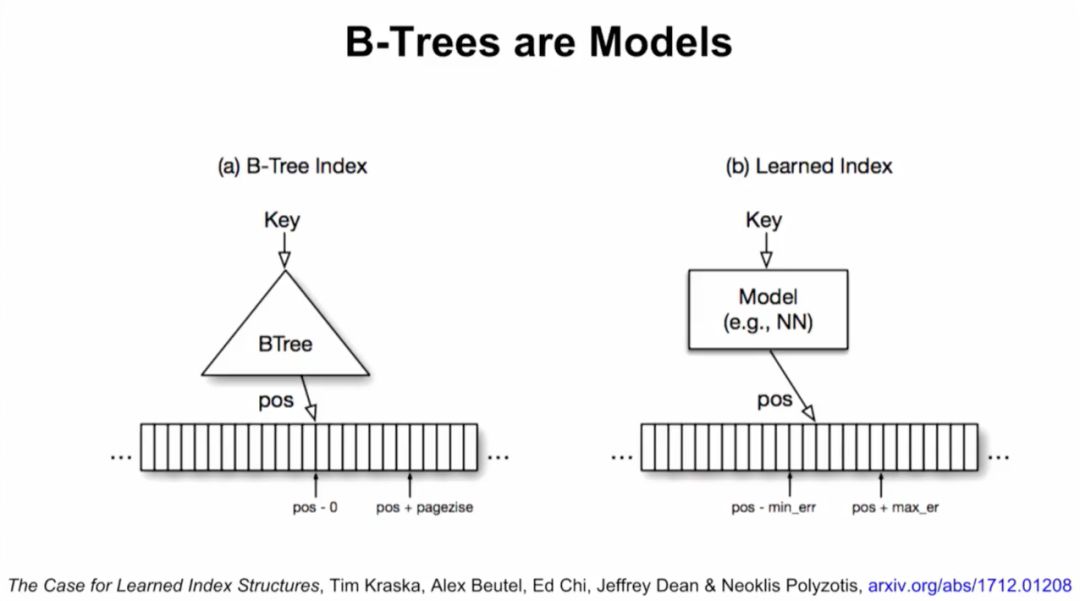
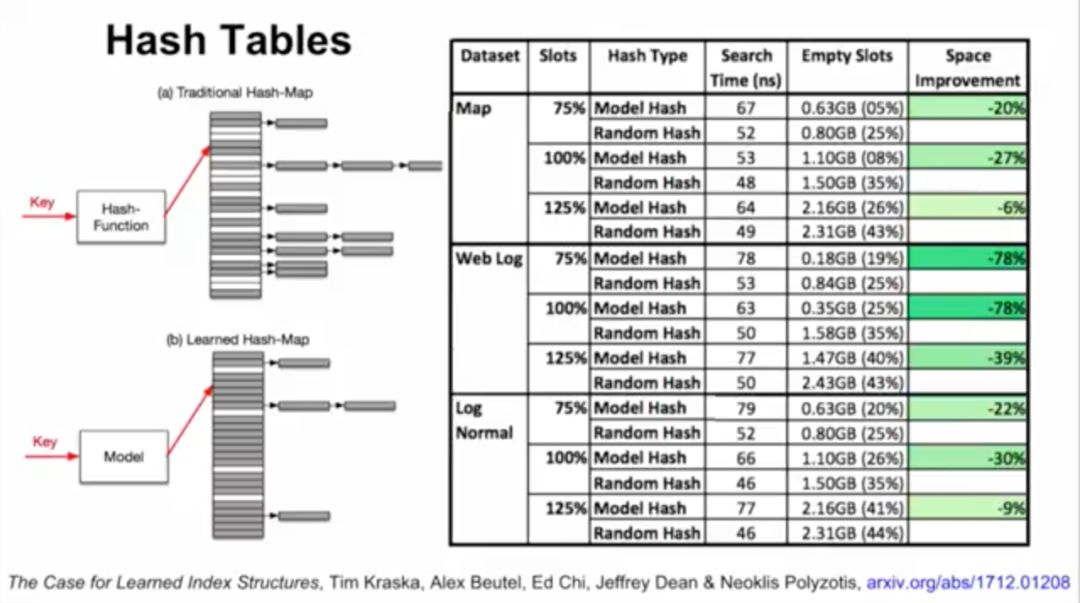
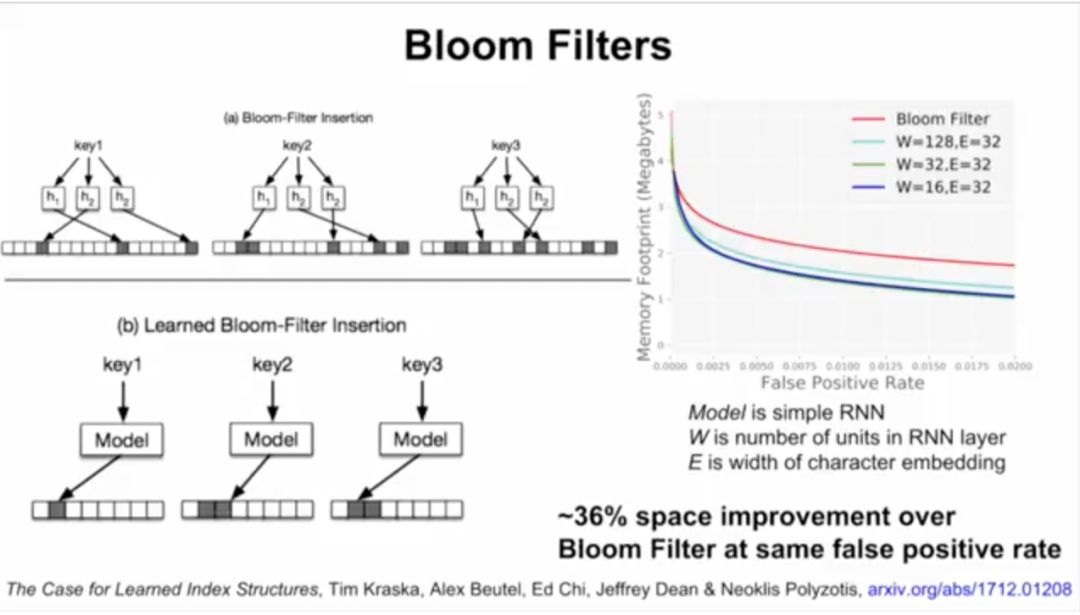
接下来,Jeff Dean介绍了谷歌大脑的研究,用ML模型替代数据库组件。他们将神经网络应用于三种索引类型:B树,用于处理范围查询;哈希映射(Hash-map),用于点查找查询;以及Bloom-filter,用于设置包含检查。
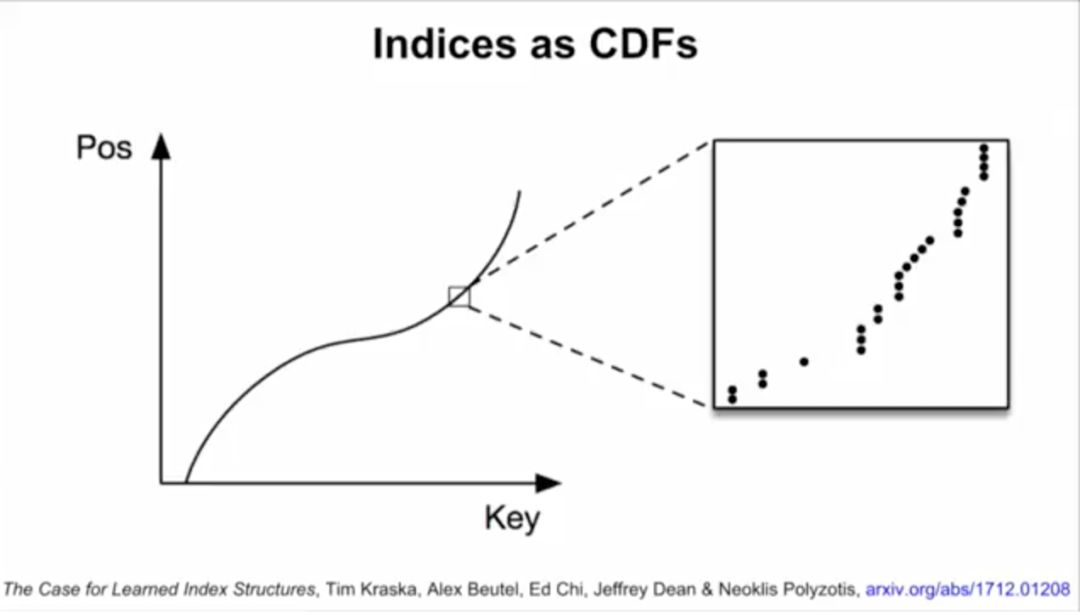
B-tree实际上可以看做模型。数据的累积分布函数(CDF)可以作为索引。举例来说,如果键的范围在0到500m之间,比起用哈希,直接把键当索引速度可能更快。如果知道了数据的累积分布函数(CDF),“CDF*键*记录大小”可能约等于要查找的记录的位置,这一点也适用于其他数据分布的情况。

在测试时,研究人员将机器学习索引与B树进行比较,使用了3个真实世界数据集,其中网络日志数据集(Weblogs)对索引而言极具挑战性,包含了200多万个日志条目,是很多年的大学网站的请求,而且每个请求都有单一的时间戳,数据中含有非常复杂的时间模式,包括课程安排、周末、假期、午餐休息、部门活动、学期休息,这些都是非常难以学习的。
对于网络日志数据,机器学习索引带来的速度提升最高达到了53%,对应的体积也有76%的缩小,相比之下误差范围稍有加大。
精确了解数据分布,可以大幅优化当前数据库系统使用的几乎所有索引结构。
这里有一个关键点,那就是用计算换内存,计算越来越便宜,CPU-SIMD/GPU/TPU的功能越来越强大,在论文里,谷歌大脑的研究人员指出,“运行神经网络的高昂成本在未来可以忽略不计——谷歌TPU能够在一个周期内最高完成上万次神经网络运算。有人声称,到2025年CPU的性能将提高1000倍,基于摩尔定律的CPU在本质上将不复存在。利用神经网络取代分支重索引结构,数据库可以从这些硬件的发展趋势中受益。”
Jeff Dean说,这代表了一个非常有前景且十分有趣的方向,传统系统开发中,使用ML的视角,就能发现很多新的应用。

那么,除了数据库,ML还能使用在系统的哪些方面?一个很大的机会是启发式方法。计算机系统里大量应用启发式方法,因此,ML在用到启发式方法的地方,都有机会带来改变。


编译器:指令调度,寄存器分配,循环嵌套并行策略
网络:TCP窗口大小决定,退避重传,数据压缩
操作系统:进程调度,缓冲区缓存插入/替换,文件系统预取
作业调度系统:哪些任务/ VM要在同一台机器上定位,哪些任务要抢先……
ASIC设计:物理电路布局,测试用例选择
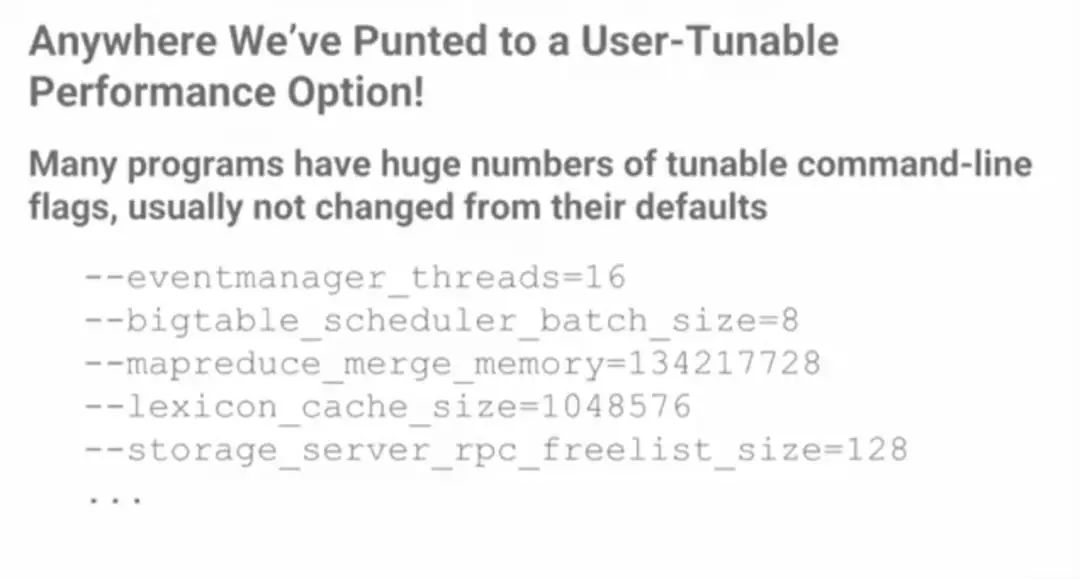
许多程序都有大量可调的命令行标记,通常不会从默认值中更改。
所有都可以元学习(meta-learn)
ML:
计算机体系结构/数据中心网络设计

在这些设置中取得成功的几个关键:
(1)有一个数字指标来衡量和优化
(2)具有清晰的接口,可以轻松地将学习整合到所有这些系统
目前的工作:探索API和实现
基本的想法:
在某些情况下做出一系列选择
最终获得关于这些选择的反馈
即使在分布式设置中,也可以以非常低的开销工作
支持核心接口的许多实现
总结
ML硬件尚处于起步阶段。更快的系统和更广泛的部署将导致更广泛的领域取得更多突破。
我们的所有计算机系统核心的学习将使它们更好/更具适应性。这方面有很多机会
会议地址(含所有Poster链接):http://www.sysml.cc/

【2018新智元AI技术峰会重磅开启,599元早鸟票抢票中!】
2017年,作为人工智能领域最具影响力的产业服务平台——新智元成功举办了「新智元开源·生态技术峰会」和「2017AIWORLD 世界人工智能大会」。凭借超高活动人气及行业影响力,获得2017年度活动行“年度最具影响力主办方”奖项。
其中「2017 AI WORLD 世界人工智能大会」创人工智能领域活动先河,参会人次超5000;开场视频在腾讯视频点播量超100万;新华网图文直播超1200万。
2018年的3月29日,新智元再汇AI之力,共筑产业跃迁之路。在北京举办2018年中国AI开年盛典——2018新智元AI技术峰会,本次峰会以“产业·跃迁”为主题,特邀诺贝尔奖评委、德国人工智能研究中心创始人兼CEO Wolfgang Wahlster 亲临现场,与谷歌、微软、亚马逊、BAT、科大讯飞、京东和华为等企业重量级嘉宾,共同研讨技术变革,助力领域融合发展。
新智元诚挚邀请关心人工智能行业发展的各界人士 3 月 29 日亲临峰会现场,共同参与这一跨领域的思维碰撞。
关于大会更多信息,请关注新智元微信公众号或访问活动行页面(点击阅读原文):http://www.huodongxing.com/event/8426451122400








