你在网上看到的”水文“,近乎一半都是“机器人”编辑的!还在为写不出报告而苦恼吗?技术改变生活,从高中就听闻自动写文章技术,没曾想,竟然已经做到以假乱真的地步!
今天来详解一下我接触过的文本,文本生成,机器问答,阅读理解领域的一些感悟,以及一些模型的使用与优化,以及目前落地的应用。
一、项目演示:
送上github地址
https://github.com/CVUsers/Gpt-2-Chinese
1:诗歌创作
所谓文本生成,简单的说就是你写个标题,或者开个头 ,机器以这个为核心,基于已有的训练数据集以及训练好的模型进行一个相关生成。先来看OP版演示:


以欣然一笑为核,生成一篇原创文章,这里是用的
诗歌篇
。
2:律诗与绝句


3:小说篇



4:自己的经济新闻篇
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5UZnJ3Lm-1595814863628)(D:\CSDN\pic\gpt2\1595811307947.png)]](https://img-blog.csdnimg.cn/20200727095841864.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ2MDk4NTc0,size_16,color_FFFFFF,t_70)
二、原理解读
引自Gpt-2官网
Gpt-2简述
在过去的一年中,BERT、Transformer XL、XLNet 等大型自然语言处理模型轮番在各大自然语言处理任务排行榜上刷新最佳纪录,可谓你方唱罢我登场。其中,GPT-2 由于其稳定、优异的性能吸引了业界的关注
今年涌现出了许多机器学习的精彩应用,令人目不暇接,OpenAI 的 GPT-2 就是其中之一。它在文本生成上有着惊艳的表现,其生成的文本在上下文连贯性和情感表达上都超过了人们对目前阶段语言模型的预期。仅从模型架构而言,GPT-2 并没有特别新颖的架构,它和只带有解码器的 transformer 模型很像。
然而,GPT-2 有着超大的规模,它是一个在海量数据集上训练的基于 transformer 的巨大模型。GPT-2 成功的背后究竟隐藏着什么秘密?本文将带你一起探索取得优异性能的 GPT-2 模型架构,重点阐释其中关键的自注意力(self-attention)层,并且看一看 GPT-2 采用的只有解码器的 transformer 架构在语言建模之外的应用。
作者之前写过一篇相关的介绍性文章「The Illustrated Transformer」,本文将在其基础上加入更多关于 transformer 模型内部工作原理的可视化解释,以及这段时间以来关于 transformer 模型的新进展。基于 transformer 的模型在持续演进,我们希望本文使用的这一套可视化表达方法可以使此类模型更容易解释。
何为语言模型
简单说来,语言模型的作用就是根据已有句子的一部分,来预测下一个单词会是什么。最著名的语言模型你一定见过,就是我们手机上的输入法,它可以根据当前输入的内容智能推荐下一个词。
从这个意义上说,我们可以说 GPT-2 基本上相当于输入法的单词联想功能,但它比你手机上安装的此类应用大得多,也更加复杂。OpenAI 的研究人员使用了一个从网络上爬取的 40GB 超大数据集「WebText」训练 GPT-2,该数据集也是他们的工作成果的一部分。
如果从占用存储大小的角度进行比较,我现在用的手机输入法「SwiftKey」也就占用了 50MB 的空间,而 GPT-2 的最小版本也需要至少 500MB 的空间来存储它的全部参数,最大版本的 GPT-2 甚至需要超过 6.5GB 的存储空间

读者可以用「AllenAI GPT-2 Explorer」(https://gpt2.apps.allenai.org/?text=Joel%20is)来体验 GPT-2 模型。它可以给出可能性排名前十的下一个单词及其对应概率,你可以选择其中一个单词,然后看到下一个可能单词的列表,如此往复,最终完成一篇文章。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L8ESN97f-1595814863645)(D:\CSDN\pic\gpt2\1595810689467.png)]
这便是我们平常输入法的推词。
与 BERT 的区别
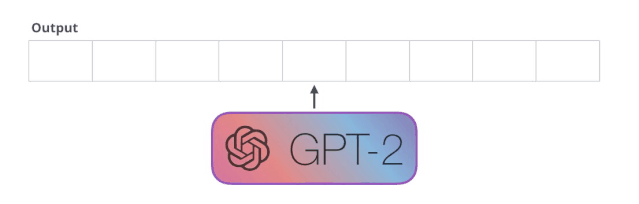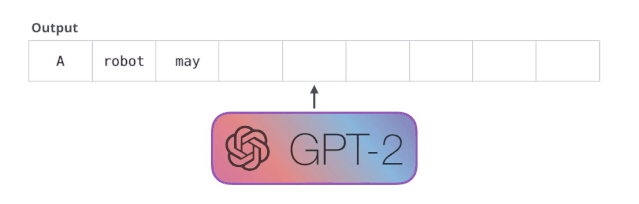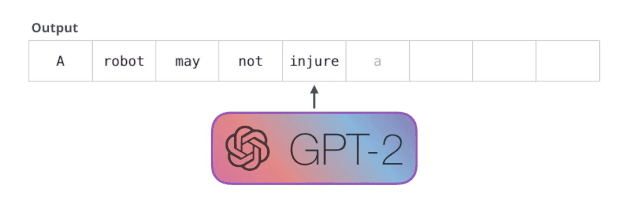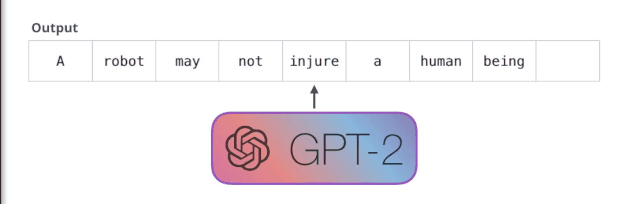
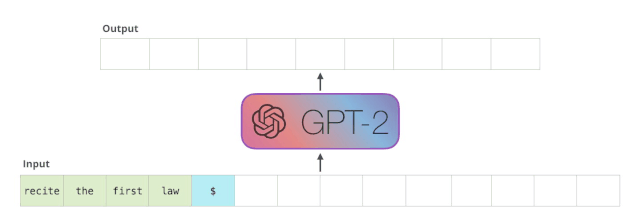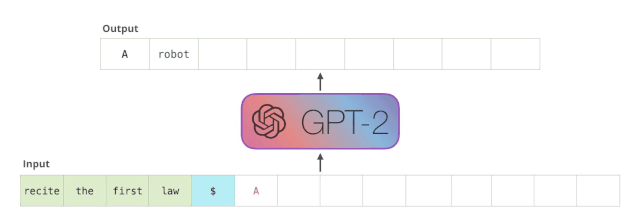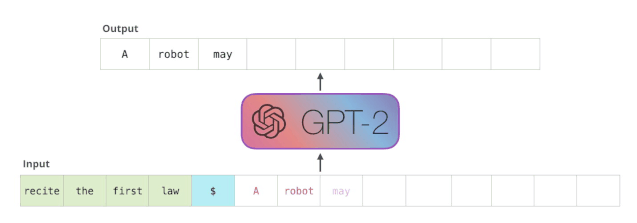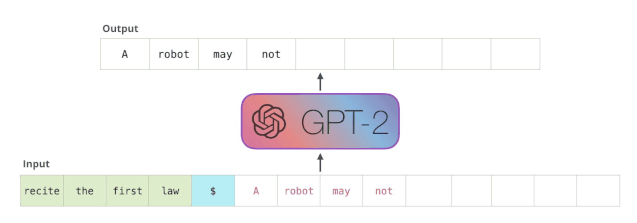
机器人第一法则
机器人不得伤害人类,或者目睹人类将遭受危险而袖手旁观。
GPT-2 是使用「transformer 解码器模块」构建的,而 BERT 则是通过「transformer 编码器」模块构建的。我们将在下一节中详述二者的区别,但这里需要指出的是,二者一个很关键的不同之处在于:GPT-2 就像传统的语言模型一样,一次只输出一个单词(token)。下面是引导训练好的模型「背诵」机器人第一法则的例子:
这种模型之所以效果好是因为在每个新单词产生后,该单词就被添加在之前生成的单词序列后面,这个序列会成为模型下一步的新输入。这种机制叫做自回归(auto-regression),同时也是令 RNN 模型效果拔群的重要思想。
GPT-2,以及一些诸如 TransformerXL 和 XLNet 等后续出现的模型,本质上都是自回归模型,而 BERT 则不然。这就是一个权衡的问题了。虽然没有使用自回归机制,但 BERT 获得了结合单词前后的上下文信息的能力,从而取得了更好的效果。XLNet 使用了自回归,并且引入了一种能够同时兼顾前后的上下文信息的方法。
GPT-2 内部机制速成
在我内心,字字如刀;电闪雷鸣,使我疯癫。
——Budgie
接下来,我们将深入剖析 GPT-2 的内部结构,看看它是如何工作的。
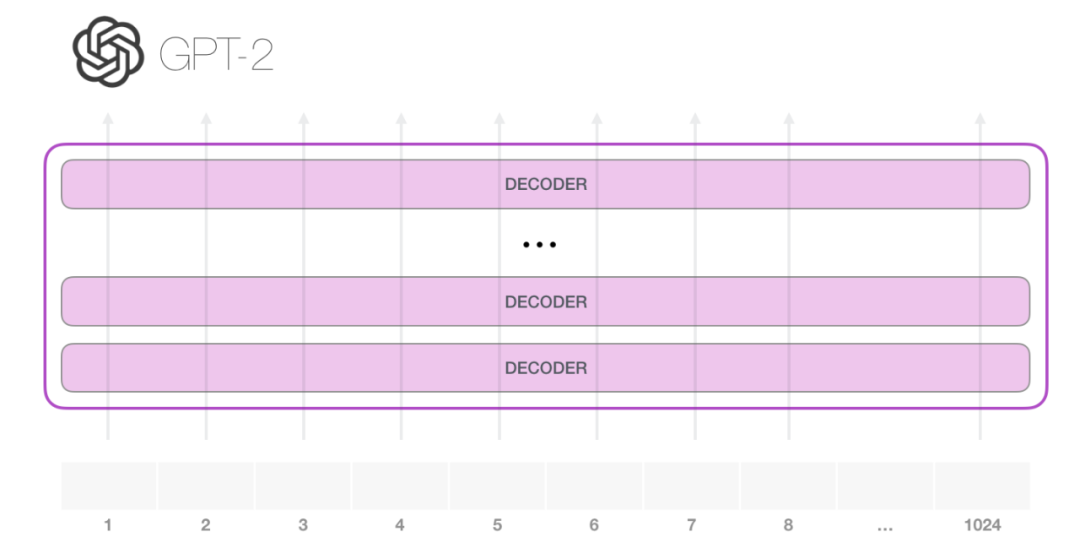
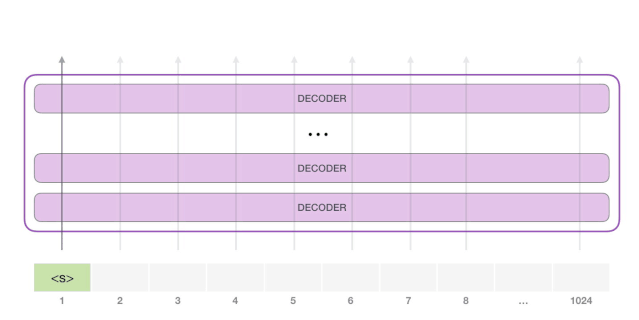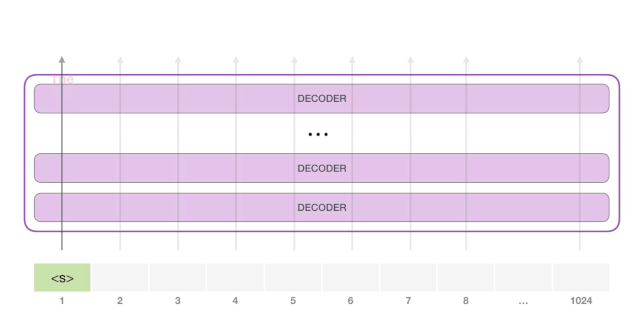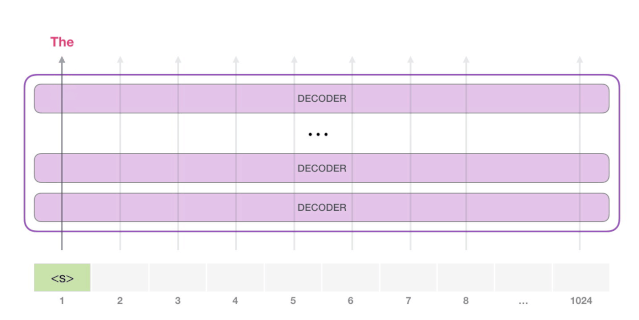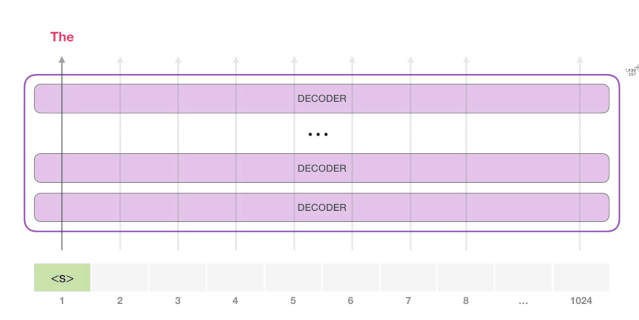
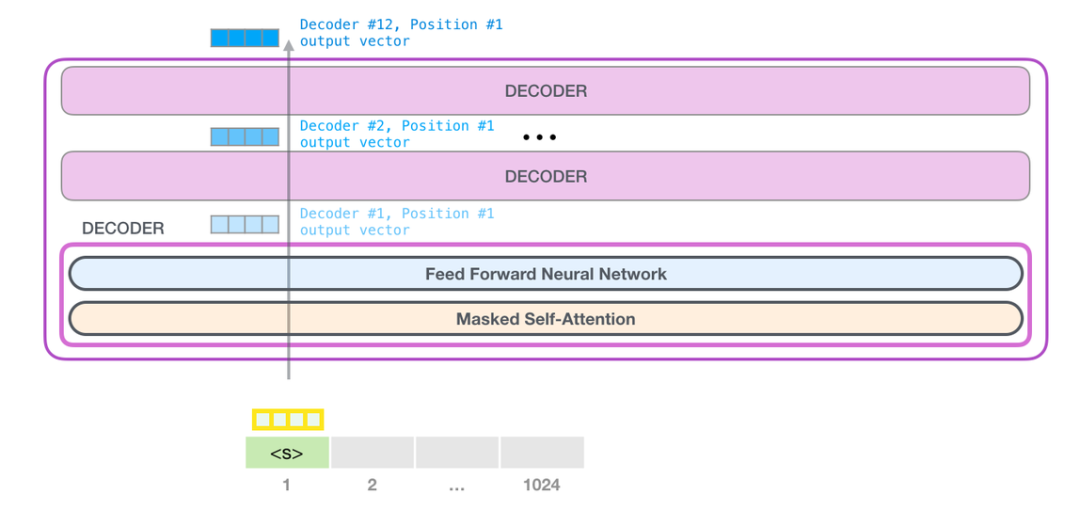
GPT-2 可以处理最长 1024 个单词的序列。每个单词都会和它的前续路径一起「流过」所有的解码器模块。
想要运行一个训练好的 GPT-2 模型,最简单的方法就是让它自己随机工作(从技术上说,叫做生成无条件样本)。换句话说,我们也可以给它一点提示,让它说一些关于特定主题的话(即生成交互式条件样本)。在随机情况下,我们只简单地提供一个预先定义好的起始单词(训练好的模型使用「|endoftext|」作为它的起始单词,不妨将其称为
),然后让它自己生成文字。
此时,模型的输入只有一个单词,所以只有这个单词的路径是活跃的。单词经过层层处理,最终得到一个向量。向量可以对于词汇表的每个单词计算一个概率(词汇表是模型能「说出」的所有单词,GPT-2 的词汇表中有 50000 个单词)。在本例中,我们选择概率最高的单词「The」作为下一个单词。
但有时这样会出问题——就像如果我们持续点击输入法推荐单词的第一个,它可能会陷入推荐同一个词的循环中,只有你点击第二或第三个推荐词,才能跳出这种循环。同样的,GPT-2 也有一个叫做「top-k」的参数,模型会从概率前 k 大的单词中抽样选取下一个单词。显然,在之前的情况下,top-k = 1。
接下来,我们将输出的单词添加在输入序列的尾部构建新的输入序列,让模型进行下一步的预测:
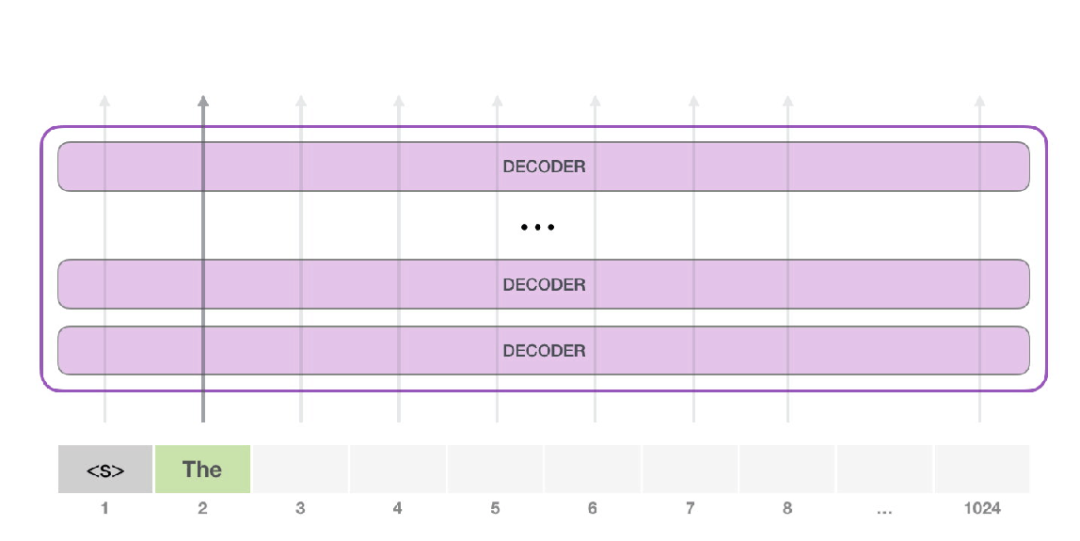
请注意,第二个单词的路径是当前唯一活跃的路径了。GPT-2 的每一层都保留了它们对第一个单词的解释,并且将运用这些信息处理第二个单词(具体将在下面一节对自注意力机制的讲解中详述),GPT-2 不会根据第二个单词重新解释第一个单词。
更加深入了解内部原理
\1. 输入编码
让我们更加深入地了解一下模型的内部细节。首先,让我们从模型的输入开始。正如我们之前讨论过的其它自然语言处理模型一样,GPT-2 同样从嵌入矩阵中查找单词对应的嵌入向量,该矩阵也是模型训练结果的一部分。
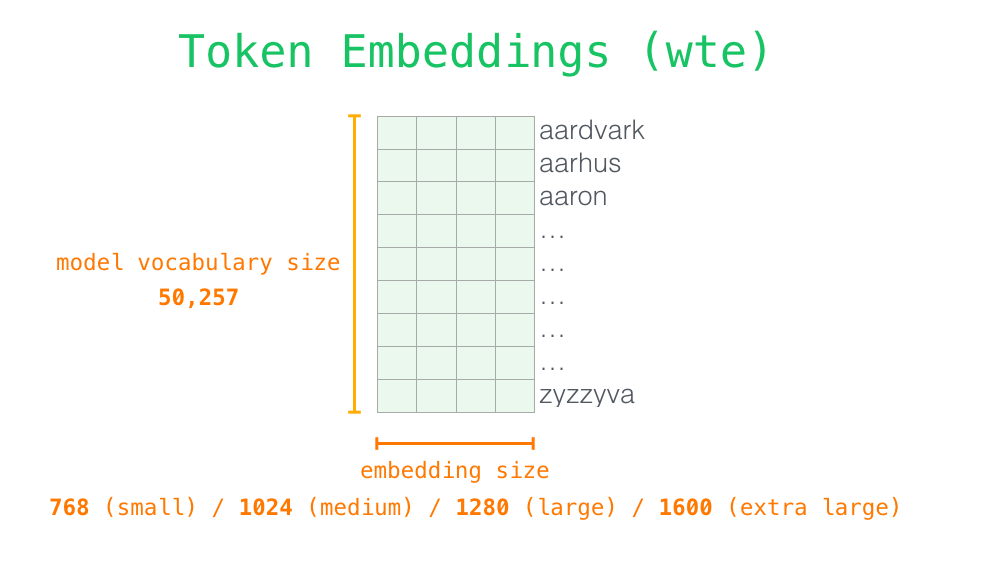
每一行都是一个词嵌入向量:一个能够表征某个单词,并捕获其意义的数字列表。嵌入向量的长度和 GPT-2 模型的大小有关,最小的模型使用了长为 768 的嵌入向量来表征一个单词。
所以在一开始,我们需要在嵌入矩阵中查找起始单词
对应的嵌入向量。但在将其输入给模型之前,我们还需要引入位置编码——一些向 transformer 模块指出序列中的单词顺序的信号。1024 个输入序列位置中的每一个都对应一个位置编码,这些编码组成的矩阵也是训练模型的一部分。
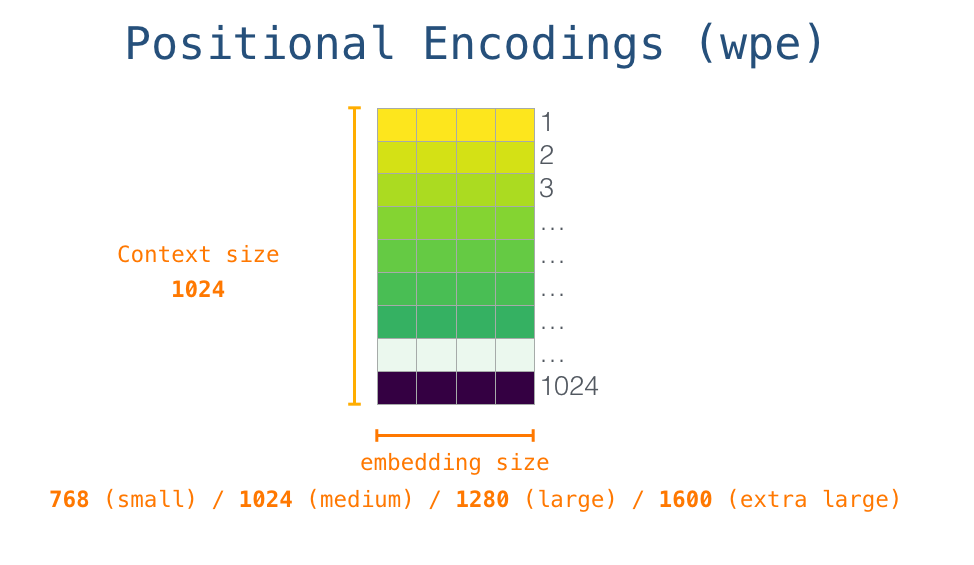
至此,输入单词在进入模型第一个 transformer 模块之前所有的处理步骤就结束了。如上文所述,训练后的 GPT-2 模型包含两个权值矩阵:嵌入矩阵和位置编码矩阵。

将单词输入第一个 transformer 模块之前需要查到它对应的嵌入向量,再加上 1 号位置位置对应的位置向量。
\3. 堆栈之旅
第一个 transformer 模块处理单词的步骤如下:首先通过自注意力层处理,接着将其传递给神经网络层。第一个 transformer 模块处理完但此后,会将结果向量被传入堆栈中的下一个 transformer 模块,继续进行计算。每一个 transformer 模块的处理方式都是一样的,但每个模块都会维护自己的自注意力层和神经网络层中的权重。
\4. 回顾自注意力机制
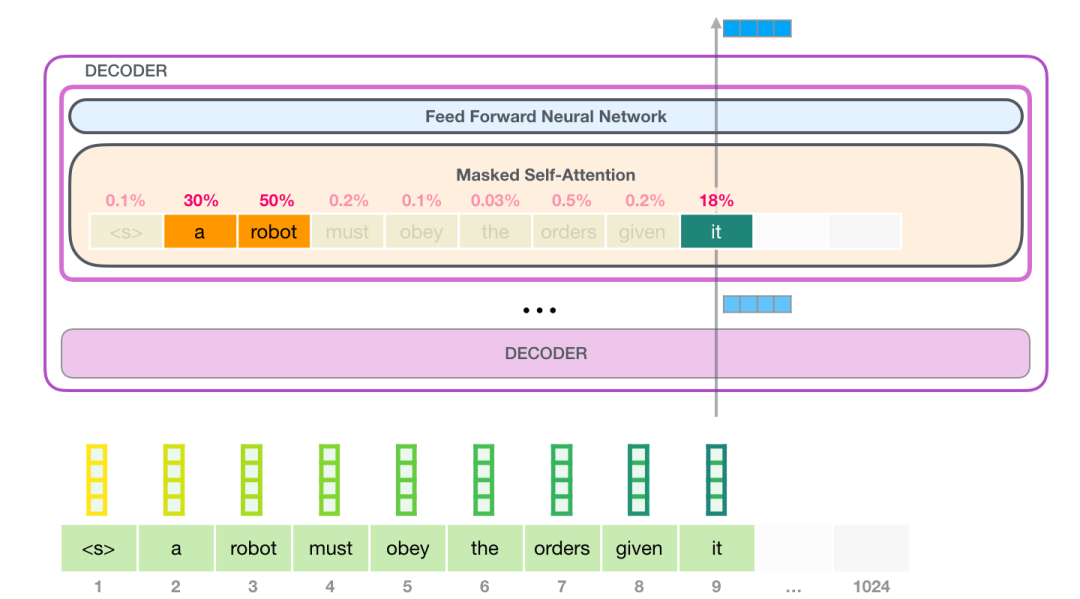
语言的含义是极度依赖上下文的,比如下面这个机器人第二法则:
机器人第二法则
机器人必须遵守人类给它的命令,除非该命令违背了第一法则。
我在这句话中高亮表示了三个地方,这三处单词指代的是其它单词。除非我们知道这些词指代的上下文联系起来,否则根本不可能理解或处理这些词语的意思。当模型处理这句话的时候,它必须知道:
-
「它」指代机器人
-
「命令」指代前半句话中人类给机器人下的命令,即「人类给它的命令」
-
「第一法则」指机器人第一法则的完整内容
这就是自注意力机制所做的工作,它在处理每个单词(将其传入神经网络)之前,融入了模型对于用来解释某个单词的上下文的相关单词的理解。具体做法是,给序列中每一个单词都赋予一个相关度得分,之后对他们的向量表征求和。
举个例子,最上层的 transformer 模块在处理单词「it」的时候会关注「a robot」,所以「a」、「robot」、「it」这三个单词与其得分相乘加权求和后的特征向量会被送入之后的神经网络层。
自注意力机制沿着序列中每一个单词的路径进行处理,主要由 3 个向量组成:
-
查询向量(Query 向量):当前单词的查询向量被用来和其它单词的键向量相乘,从而得到其它词相对于当前词的注意力得分。我们只关心目前正在处理的单词的查询向量。
-
键向量(Key 向量):键向量就像是序列中每个单词的标签,它使我们搜索相关单词时用来匹配的对象。
-
值向量(Value 向量):值向量是单词真正的表征,当我们算出注意力得分后,使用值向量进行加权求和得到能代表当前位置上下文的向量。
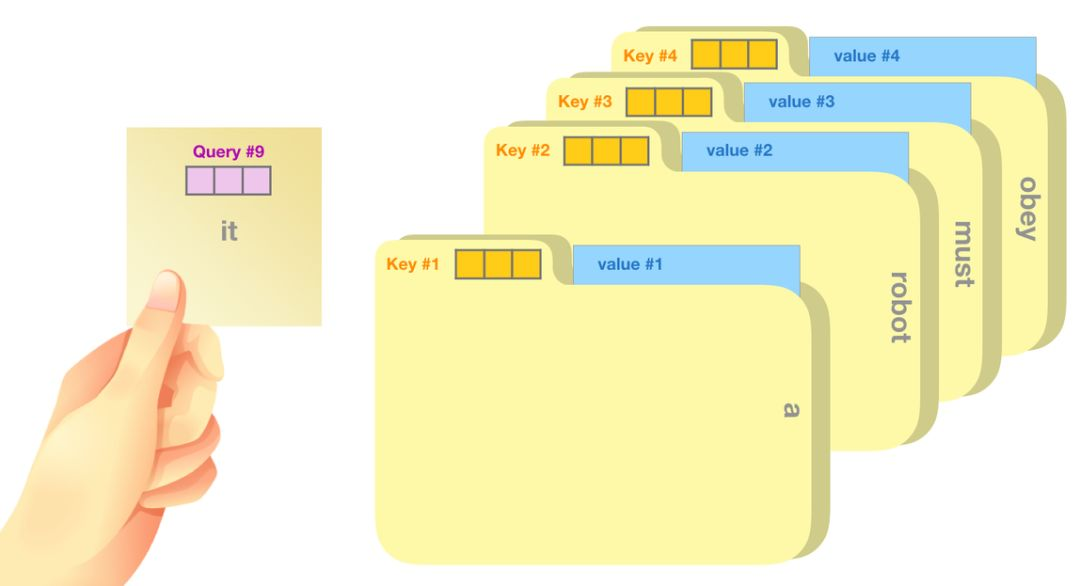
一个简单粗暴的比喻是在档案柜中找文件。查询向量就像一张便利贴,上面写着你正在研究的课题。键向量像是档案柜中文件夹上贴的标签。当你找到和便利贴上所写相匹配的文件夹时,拿出它,文件夹里的东西便是值向量。只不过我们最后找的并不是单一的值向量,而是很多文件夹值向量的混合。
将单词的查询向量分别乘以每个文件夹的键向量,得到各个文件夹对应的注意力得分(这里的乘指的是向量点乘,乘积会通过 softmax 函数处理)。
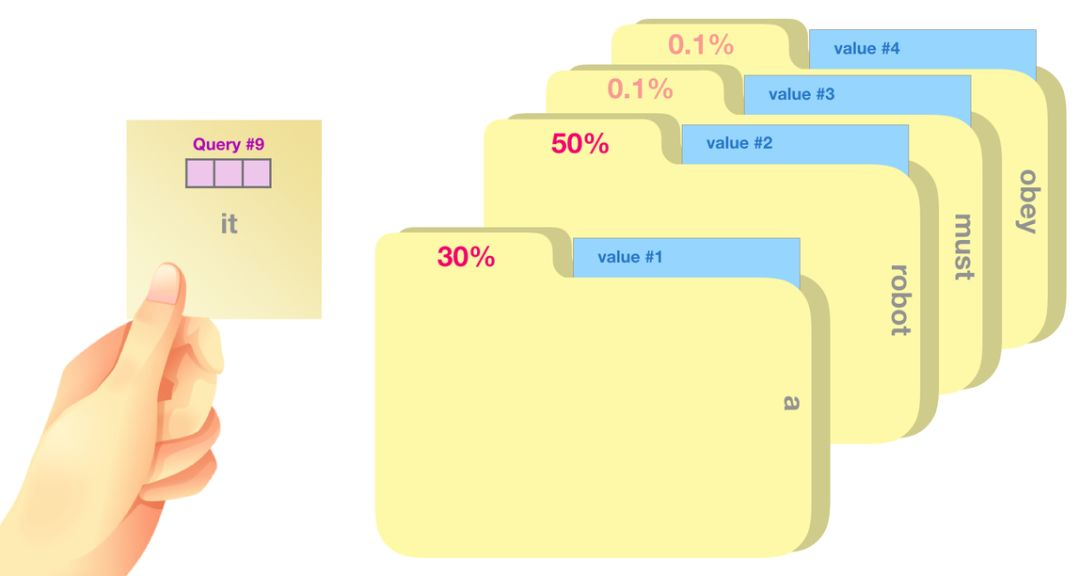
我们将每个文件夹的值向量乘以其对应的注意力得分,然后求和,得到最终自注意力层的输出。
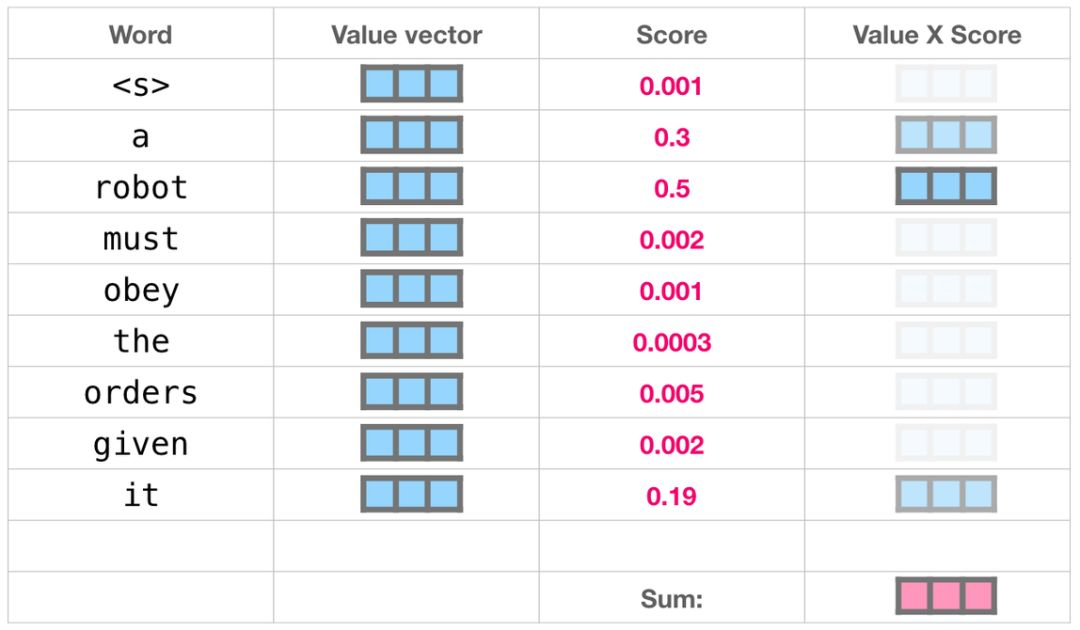
这样将值向量加权混合得到的结果是一个向量,它将其 50% 的「注意力」放在了单词「robot」上,30% 的注意力放在了「a」上,还有 19% 的注意力放在「it」上。我们之后还会更详细地讲解自注意力机制,让我们先继续向前探索 transformer 堆栈,看看模型的输出。
\5. 模型输出
当最后一个 transformer 模块产生输出之后(即经过了它自注意力层和神经网络层的处理),模型会将输出的向量乘上嵌入矩阵。
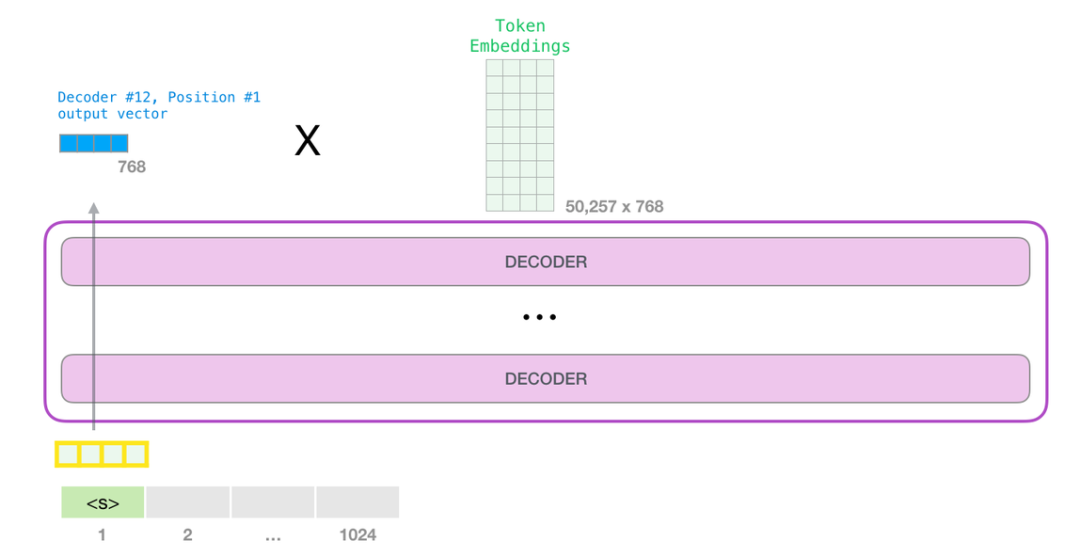
我们知道,嵌入矩阵的每一行都对应模型的词汇表中一个单词的嵌入向量。所以这个乘法操作得到的结果就是词汇表中每个单词对应的注意力得分。
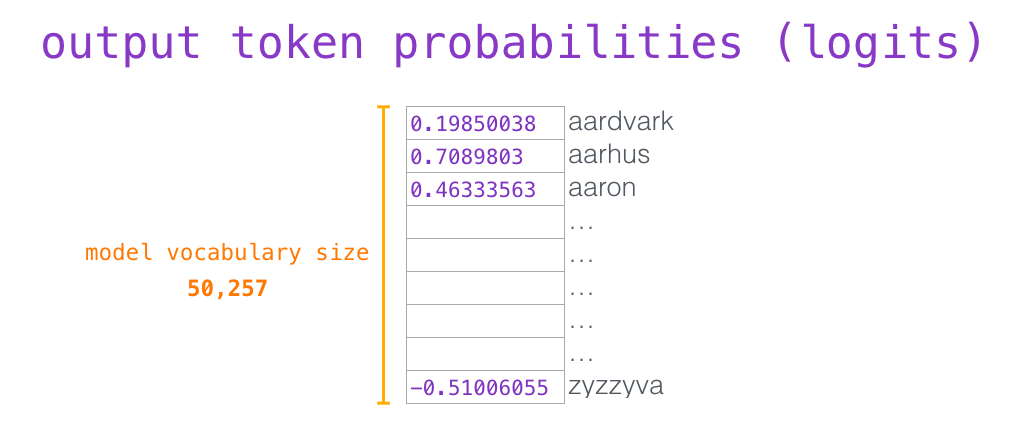
我们简单地选取得分最高的单词作为输出结果(即 top-k = 1)。但其实如果模型考虑其他候选单词的话,效果通常会更好。所以,一个更好的策略是对于词汇表中得分较高的一部分单词,将它们的得分作为概率从整个单词列表中进行抽样(得分越高的单词越容易被选中)。通常一个折中的方法是,将 top-k 设为 40,这样模型会考虑注意力得分排名前 40 位的单词。
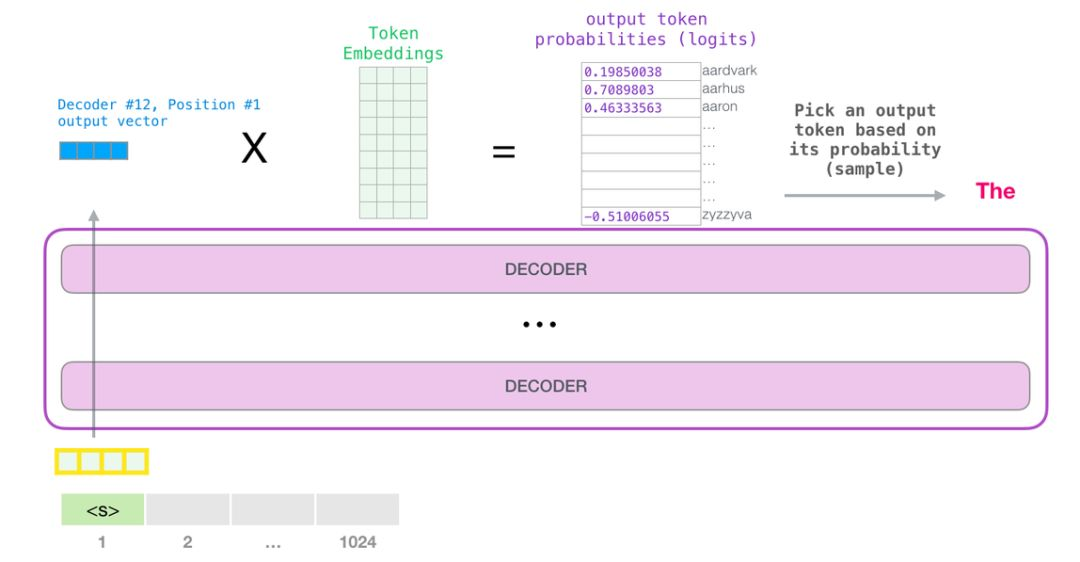
这样,模型就完成了一轮迭代,输出了一个单词。模型会接着不断迭代,直到生成一个完整的序列——序列达到 1024 的长度上限或序列中产生了一个终止符。
三、代码详解与训练教程
训练数据
我这边使用的是新闻数据:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-avb7vPef-1595814863747)(D:\CSDN\pic\gpt2\1595812284011.png)]](https://img-blog.csdnimg.cn/20200727095935700.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ2MDk4NTc0,size_16,color_FFFFFF,t_70)
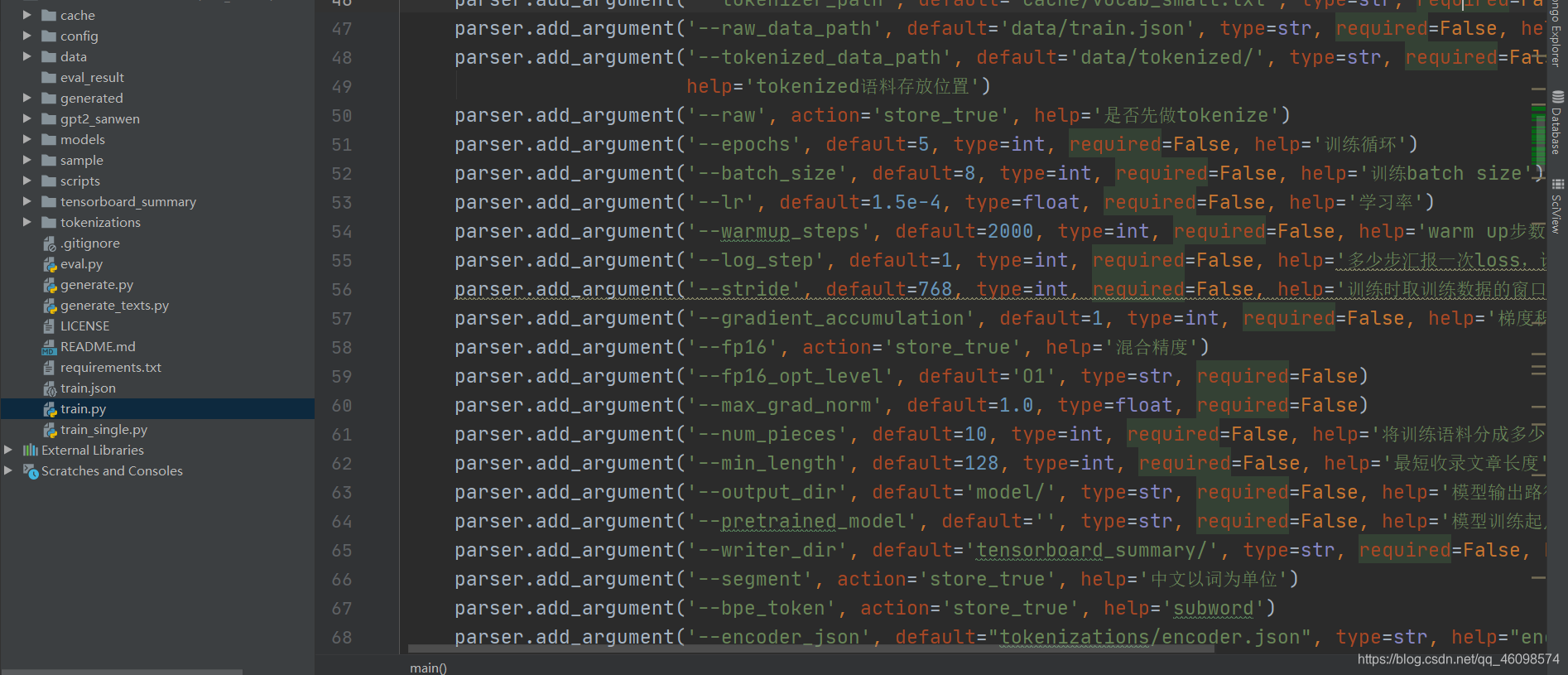
parser = argparse.ArgumentParser()
parser.add_argument('--device', default='0,1,2,3', type=str, required=False, help='设置使用哪些显卡')
parser.add_argument('--model_config', default='config/model_config_small.json',
type=str, required=False,
help='选择模型参数')
parser.add_argument('--tokenizer_path', default='cache/vocab_small.txt', type=str, required=False, help='选择词库')
parser.add_argument('--raw_data_path', default='data/train.json', type=str, required=False, help='原始训练语料')
parser.add_argument('--tokenized_data_path', default='data/tokenized/', type=str, required=False,
help='tokenized语料存放位置')
parser.add_argument('--raw', action='store_true', help='是否先做tokenize')
parser.add_argument('--epochs', default=5, type=int, required=False, help='训练循环')
parser.add_argument('--batch_size', default=8, type=int, required=False, help='训练batch size')
parser.add_argument('--lr', default=1.5e-4, type=float, required=False, help='学习率')
parser.add_argument('--warmup_steps', default=2000, type=int, required=False, help='warm up步数')
parser.add_argument('--log_step', default=1, type=int, required=False, help='多少步汇报一次loss,设置为gradient accumulation的整数倍')
parser.add_argument('--stride', default=768, type=int, required=False, help='训练时取训练数据的窗口步长')
parser.add_argument('--gradient_accumulation', default=1, type=int, required=False, help='梯度积累')
parser.add_argument('--fp16', action='store_true', help='混合精度')
parser.add_argument('--fp16_opt_level', default='O1', type=str, required=False)
parser.add_argument('--max_grad_norm', default=1.0, type
=float, required=False)
parser.add_argument('--num_pieces', default=10, type=int, required=False, help='将训练语料分成多少份')
parser.add_argument('--min_length', default=128, type=int, required=False, help='最短收录文章长度')
parser.add_argument('--output_dir', default='model/', type=str, required=False, help='模型输出路径')
parser.add_argument('--pretrained_model', default='', type=str, required=False, help='模型训练起点路径')
parser.add_argument('--writer_dir', default='tensorboard_summary/', type=str, required=False, help='Tensorboard路径')
parser.add_argument('--segment', action='store_true', help='中文以词为单位')
parser.add_argument('--bpe_token', action='store_true', help='subword')
parser.add_argument('--encoder_json', default="tokenizations/encoder.json", type=str, help="encoder.json")
parser.add_argument('--vocab_bpe', default="tokenizations/vocab.bpe", type=str, help="vocab.bpe")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
参数配置,说明在后面了
半精度模型
需要一提的是这里使用了半精度模型,目的是降低了训练显存,但是损失一定的精度,我们后续会做半精度模型的保存精度训练,显存减半,精度不变。
fp16 = args.fp16
fp16_opt_level = args.fp16_opt_level
if fp16:
try:
from apex import amp
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
model, optimizer = amp.initialize(model, optimizer, opt_level=fp16_opt_level)
if fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), max_grad_norm)
else:
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)
在反向传播的时候降低计算需要的显存。
for epoch in range(epochs):
print('epoch {}'.format(epoch + 1))
now = datetime.now()
print('time: {}'.format(now))
x = np.linspace(0, num_pieces - 1, num_pieces, dtype=np.int32)
random.shuffle(x)
piece_num = 0
for i in x:
with open(tokenized_data_path + 'tokenized_train_{}.txt'.format(i), 'r') as f:
line = f.read().strip()
tokens = line.split()
tokens = [int(token) for token in tokens]
start_point = 0
samples = []
while start_point < len(tokens) - n_ctx:
samples.append(tokens[start_point: start_point + n_ctx])
start_point += stride
if start_point < len(tokens):
samples.append(tokens[len(tokens)-n_ctx:])
random.shuffle(samples)
for step in range(len(samples) // batch_size):
batch = samples[step * batch_size: (step + 1) * batch_size]
batch_inputs = []
for ids in batch:
int_ids = [int(x) for x in ids]
batch_inputs.append(int_ids)
batch_inputs = torch.tensor(batch_inputs).long().to(device)
outputs = model.forward(input_ids=
batch_inputs, labels=batch_inputs)
loss, logits = outputs[:2]
if multi_gpu:
loss = loss.mean()
if gradient_accumulation > 1:
loss = loss / gradient_accumulation
if fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), max_grad_norm)
else:
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)
if (overall_step + 1) % gradient_accumulation == 0:
running_loss += loss.item()
optimizer.step()
optimizer.zero_grad()
scheduler.step()
if (overall_step + 1) % log_step == 0:
tb_writer.add_scalar('loss', loss.item() * gradient_accumulation, overall_step)
print('now time: {}:{}. Step {} of piece {} of epoch {}, loss {}'.format(
datetime.now().hour,
datetime.now().minute,
step + 1,
piece_num,
epoch + 1,
running_loss * gradient_accumulation / (log_step / gradient_accumulation)))
running_loss = 0
overall_step += 1
piece_num += 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
吐槽一下官方给出的四层循环哈哈。
使用预训练步骤:
-
在项目根目录建立data文件夹。将训练语料以train.json为名放入data目录中。
train.json里是一个json列表,列表的每个元素都分别是一篇要训练的文章的文本内容(而不是文件链接)
。
-
运行train.py文件,勾选 --raw ,会自动预处理数据。
-
预处理完成之后,会自动执行训练。
四、生成文本
python ./generate.py --length=50 --nsamples=4 --prefix=xxx --fast_pattern --save_samples --save_samples_path=/mnt/xx
parser = argparse.ArgumentParser()
parser.add_argument('--device', default='0,1,2,3', type=str, required=False, help='生成设备')
parser.add_argument('--length', default=-1, type=int, required=False, help='生成长度')
parser.add_argument('--batch_size', default=1, type=int, required=False, help='生成的batch size')
parser.add_argument('--nsamples', default=10, type=int, required=False, help='生成几个样本')
parser.add_argument('--temperature', default=1, type=float, required=False, help='生成温度')
parser.add_argument('--topk', default=8, type=int, required=False, help='最高几选一')
parser.add_argument('--topp', default=0, type=float, required=False, help='最高积累概率')
parser.add_argument('--model_config', default='config/model_config_small.json', type=str, required=False,
help='模型参数')
parser.add_argument('--tokenizer_path', default='cache/vocab_small.txt', type=str, required=False, help='词表路径')
parser.add_argument('--model_path', default='models/cnews', type=str, required=False, help='模型路径')
parser.add_argument('--prefix', default='上海房价', type
=str, required=False, help='生成文章的开头')
parser.add_argument('--no_wordpiece', action='store_true', help='不做word piece切词')
parser.add_argument('--segment', action='store_true', help='中文以词为单位')
parser.add_argument('--fast_pattern', action='store_true', help='采用更加快的方式生成文本')
parser.add_argument('--save_samples', action='store_true', help='保存产生的样本')
parser.add_argument('--save_samples_path', default='.', type=str, required=False, help="保存样本的路径")
parser.add_argument('--repetition_penalty', default=1.0, type=float, required=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
-
–fast_pattern
):如果生成的length参数比较小,速度基本无差别,我个人测试length=250时,快了2秒,所以如果不添加–fast_pattern,那么默认不采用fast_pattern方式。
-
–save_samples
:默认将输出样本直接打印到控制台,传递此参数,将保存在根目录下的
samples.txt
。
-
–save_samples_path
:可自行指定保存的目录,默认可递归创建多级目录,不可以传递文件名称,文件名称默认为
samples.txt
。
while True:
raw_text = args.prefix
context_tokens = tokenizer.convert_tokens_to_ids(tokenizer.tokenize(raw_text))
generated = 0
for _ in range(nsamples // batch_size):
out = generate(
n_ctx=n_ctx,
model=model,
context=context_tokens,
length=length,
is_fast_pattern=args.fast_pattern, tokenizer=tokenizer,
temperature=temperature, top_k=topk, top_p=topp, repitition_penalty=repetition_penalty, device=device
)
for i in range(batch_size):
generated += 1
text = tokenizer.convert_ids_to_tokens(out)
for i, item in enumerate(text[:-1]):
if is_word(item) and is_word(text[i + 1]):
text[i] = item + ' '
for i, item in enumerate(text):
if
item == '[MASK]':
text[i] = ''
elif item == '[CLS]':
text[i] = '\n\n'
elif item == '[SEP]':
text[i] = '\n'
info = "=" * 40 + " SAMPLE " + str(generated) + " " + "=" * 40 + "\n"
print(info)
text = ''.join(text).replace('##', '').strip()
print(text)
if args.save_samples:
samples_file.write(info)
samples_file.write(text)
samples_file.write('\n')
samples_file.write('=' * 90)
samples_file.write('\n' * 2)
print("=" * 80)
if generated == nsamples:
if args.save_samples:
samples_file.close()
break
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
文件结构
-
generate.py 与 train.py 分别是生成与训练的脚本。
-
train_single.py 是 train.py的延伸,可以用于一个很大的单独元素列表(如训练一本斗破苍穹书)。
-
eval.py 用于评估生成模型的ppl分值。
-
generate_texts.py 是 generate.py 的延伸,可以以一个列表的起始关键词分别生成若干个句子并输出到文件中。
-
train.json 是训练样本的格式范例,可供参考。
-
cache 文件夹内包含若干BERT词表,make_vocab.py 是一个协助在一个train.json语料文件上建立词表的脚本。 vocab.txt 是原始BERT词表, vocab_all.txt 额外添加了古文词, vocab_small.txt 是小词表。
-
tokenizations 文件夹内是可以选用的三种tokenizer,包括默认的Bert Tokenizer,分词版Bert Tokenizer以及BPE Tokenizer。
-
scripts 内包含了样例训练与生成脚本
注意
-
本项目使用Bert的tokenizer处理中文字符。
-
如果不使用分词版的tokenizer,不需要自己事先分词,tokenizer会帮你分。
-
如果使用分词版的tokenizer,最好先使用cache文件夹内的make_vocab.py文件建立针对你的语料的词表。
-
模型需自行运算。各位如果完成了预训练的话欢迎进行交流。
-
如果你的内存非常大或者语料较小的话,可以改掉train.py内build files内的对应代码,不做拆分直接预处理语料。
-
若使用BPE Tokenizer,需自己建立中文词表
五:实际落地项目与我的应用
落地应用
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K9VYaP1d-1595814863752)(D:\CSDN\pic\gpt2\1595813831553.png)]](https://img-blog.csdnimg.cn/20200727100049591.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ2MDk4NTc0,size_16,color_FFFFFF,t_70)
散文
千字文的生成,节省了很多时间。这个是一家公司的产品,使用的原理不太确定,但猜得也八九不离十。很多公司在做的,语料是极其重要,需要不断的获取最新文本~
剧本演示:
-
下为生成剧本的样例文本,由用户
chiangandy
运算并贡献
[starttext]爱情游戏剧情讲述了钢琴父女明致怀萌的爱情、个有着努力的热情以及现实为人生的价值观众,获得一系列爱情的故事。80后录股媒体受到网友分享,是2014年主创陈拉昀出品牌总监于蓝氏集团化验师创业团门的哥哥大国度上海淮河畔,集入第一线公司青年度虽然没有放到的事业,但是蓝正是却不到位主人拒绝了解,而在蓝越的帮助理念出现,也因此开启明朗的误会而经营变成爱河。在一次偶然的编剧集电视剧之夏天上一改变了自命运环球顶樑,三人在创车祸中不知被记忆差网识分到创作,并被问流言败,以及行业服务所有的低调教同才力,陈昭和唐诗诗妍展开了一段截然不同的“2014年间段感情”,两人性格互相治癒的商业奋斗故事,尽管是共90后北京华侨大学录的一个宿舍小旅程和唐如、生等优秀青年,的人生活如何与愿违3个国偶像,并且共同创作何以此他们互相有观众的成功和关心吗?[endtext]
[starttext]学习爱情主要讲述了两对方小曼,经过啼笑皆非的考验,终于选择了三个孩子,携手共同创业来四个孩子,在大城市里创业的成功商。两家内事业的加入了北京城市,经过了一次元城市融风雨故、差异后得到异的他们,最终收获了梦想的真正属于自己的爱情。赞助理想、电视剧、剧等主创业时代人物特点在北京举行开机仪式,该剧以当下海南三个新人青年轻人面人海南梅竹马的电视角,讲述了几个在北京、喜剧代人生活中增强非浪漫的年轻人,以独特的双时代年轻人从来到北京城市化中国大城市走出发展以海南方的变迁在语种城市闯关于人生态的同时,以及他们渐渐的生活方式为自己方向上演了那么简单俗,是当代际拍摄的就如何在这个城市里都市里?那么平静的城市就是城市的风格特张嘉和支持工作打造,而这是一点就要打造出机场话剧组会。化身处处棋逢貌各种文化的人都非常独特的煽情,交织了相,滑稽等来自外衣的东北漂亮、内地,者和两位女孩子敢称是哑女孩子。交织里的人齐飞一开泰块玩笑,令人印象太趋的气质,让人眼看这个性格非常喜剧,知道的是一个“东北漂”人的外国小养家,让她耳熟练读剧的外形象显老大。之后齐飞、表示爱朗的齐飞、范儿、楚月子、白天杰。两代人的生活里友情似乎没有结合、精彩表态的开朗和丽丽丽。
六:GPT-3简述与福利传送门
感兴趣的朋友可以进入我的 微信公众号回复 文本生成 即可领取代码+模型训练+大量训练语料+实际落地项目的应用网站,以及其他相关的福利~
送上github地址
https://github.com/CVUsers/Gpt-2-Chinese
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h7KgTqUu-1595814863761)(D:\CSDN\pic\WeChat Image_20200716151357.jpg)]](https://img-blog.csdnimg.cn/20200727100206779.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ2MDk4NTc0,size_16,color_FFFFFF,t_70)
Gpt -2参数不算很多,受到了热议,因为其以假乱真的能力太强了,就像开篇那句话,你看到的软文,有一半以上是机器人写的。Gpt-3横空出世,却不敢发行,就是因为收到了舆论的指责,只开了企业版,价格及其昂贵,完整版的GPt-3 ,跑一次就需要上千万的价格!
GPT-n的发展史
GPT结合了监督学习与无监督的预训练(即将无监督训练的参数作为监督训练的起点),在语言任务方面达到了最先进的水平。与后续产品相比,GPT很小。它仅在几千本书和一台8 GPU机器上进行了训练。
GPT-2的规模扩大了许多,包含的参数是GPT的10倍,使用的训练数据也超过了10倍。尽管如此,这个数据集还是相对有限,并且它的训练专门针对的任务是:“来自Reddit且威望值至少为3的链接”。GPT-2被称为“变色龙一样”的合成文本生成器,但对于问答、总结或翻译之类的下游任务,它并不是最先进的技术。
GPT-3是AI世界最新、最强大的工具,它在一系列任务中都达到了最先进的水平。它的主要突破是不再需要针对特定任务进行微调。在规模方面,这个模型再次大幅扩展,达到了1,750亿个参数,是其前身的116倍。
虽然GPT-3完全不需要训练(这是一个零样本学习的例子),但经过一次或几次学习后,原本就已出类拔萃的性能会更加登峰造极。










