
向AI转型的程序员都关注了这个号👇👇👇
大数据挖掘DT数据分析 公众号: datadw
前言
上月导师在组会上交我们用tensorflow写深度学习和卷积神经网络,并把其PPT的参考学习资料给了我们, 这是codelabs上的教程:《TensorFlow and deep learning,without a PhD》
https://codelabs.developers.google.com/codelabs/cloud-tensorflow-mnist/#0
当然需要安装python,教程推荐使用python3。
好多专业词太难译了,查了下,大家有些都是不译的。
比如:dropout,learning rate decay,pkeep什么的。。。。
dropout这个词应该翻译成什么?
1. 概述
在这个codelab中,您将学习如何创建和训练识别手写数字的神经网络。一路上,随着你增强神经网络的准确率达到99%,你还将学习到专业人员用来训练模型的高效工具。
该codelab使用MNIST数据集,收集了60,000个标记的数字。你将学会用不到100行Python / TensorFlow代码来解决深度学习问题。
你会学到什么
什么是神经网络和如何训练它
如何使用TensorFlow构建基本的1层神经网络
如何添加更多的神经网络层数
训练技巧和窍门:过度拟合(overfitting),丢失信息(dropout),学习速率衰退(learning rate decay)…
如何排查深层神经网络的故障
如何构建卷积神经网络(convolutional networks)
你需要什么
Python 2或3(推荐Python 3)
TensorFlow
Matplotlib(Python可视化库)
安装说明在实验室的下一步中给出。
2. 准备:安装TensorFlow,获取示例代码
在您的计算机上安装必要的软件:Python,TensorFlow和Matplotlib。
从GitHub的信息库,克隆源代码(也可以直接登入这个网址,直接下载)
git clone https://github.com/martin-gorner/tensorflow-mnist-tutorial
下载的文件夹中含多个文件。首先是让mnist_1.0_softmax.py运行起来。其他很多文件是用于加载数据和可视化结果的解决方案或支持代码。
当您启动初始python脚本时,您应该看到一个实时可视化的培训过程:
python3 mnist_1.0_softmax.py
如果python3 mnist_1.0_softmax.py不起作用,用python命令:
python mnist_1.0_softmax.py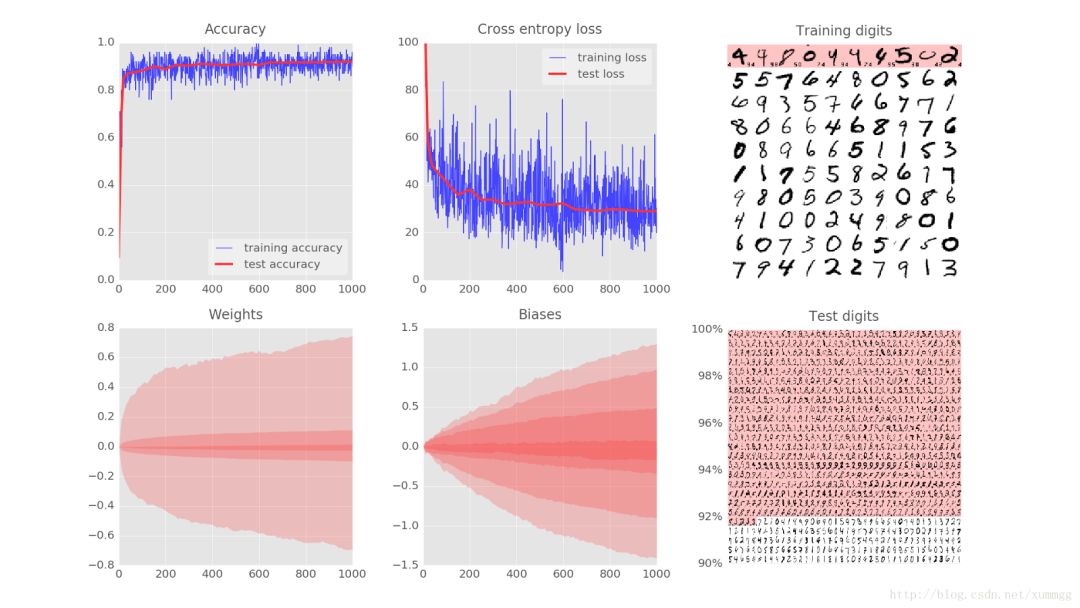
疑难解答:如果无法使实时可视化运行,或者您只希望仅使用文本输出,则可以通过注释掉一行并取消注释另一行来取消激活可视化。请参阅下载文件的底部的说明。
为TensorFlow构建的可视化工具是TensorBoard。其功能比我们本次教程中所需要的更多。它可以在远程服务器上跟踪您的分布式TensorFlow作业。对于我们在这个实验中我们只需要matplotlib的结果,能看到训练过程的实时动画,就当是个附带的奖励吧。但是,如果您需要使用TensorFlow进行跟踪工作,请确保查看TensorBoard。
3. 理论:训练神经网络
我们将首先观察正在接受训练的神经网络。代码将在下一节中进行说明,因此您先不需要看。
我们的用神经网络训练手写数字,并对它们进行分类,即将手写数字识别为0,1,2等等,最多为9。它的模型基于内部变量(“权重”(weights)和“偏差”(biases),这两个词稍后解释),只有将这些变量训练成正确值,分类工作才能正确进行,训练方式稍后也会详细解释。现在您需要知道的是,训练循环如下所示:
训练数据 => 更新权重和偏差 => 更好的识别 (循环这三步)
让我们逐个浏览可视化的六个面板,看看训练神经网络需要什么。
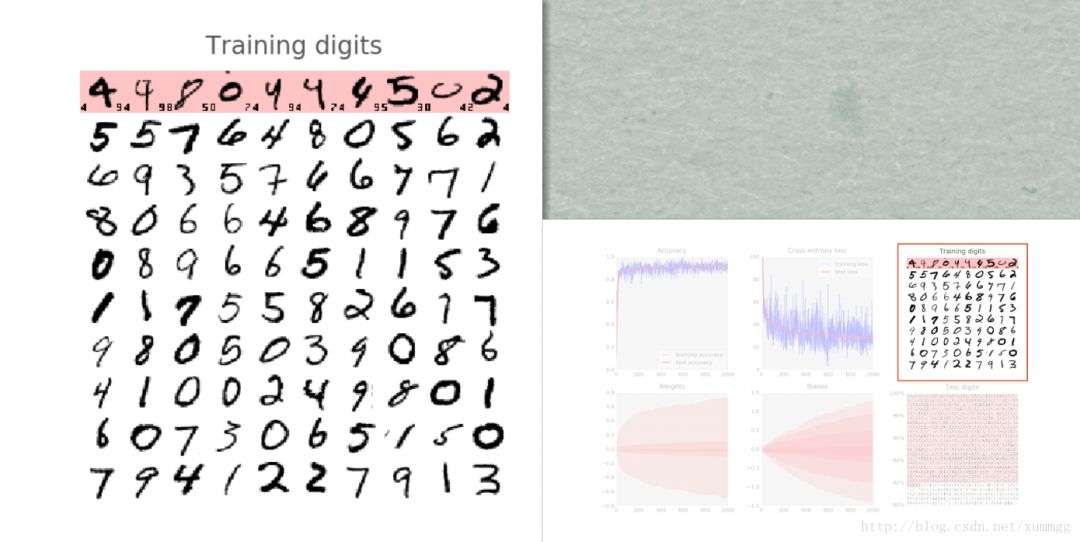
在这里,您可以看到100个训练数字被送入训练循环,注意是一次100个数字,这图显示的是这100个手写数据被训练的结果。在目前的训练状态下,神经网络已经能识别(包括白色背景和部分数字),当然也有些是识别错误的(图中红色背景的是计算机识别错误的手写数字,左侧小打印的数字是该书写字的正确标签,右侧小打印的数字是计算机标识别的错误标签)。
该数据集中有50,000个训练数字。我们在每次迭代中将其中每100个进行训练,因此系统将在500次迭代后看到所有数字被训练了一次。我们称之为“纪元(epoch)”。
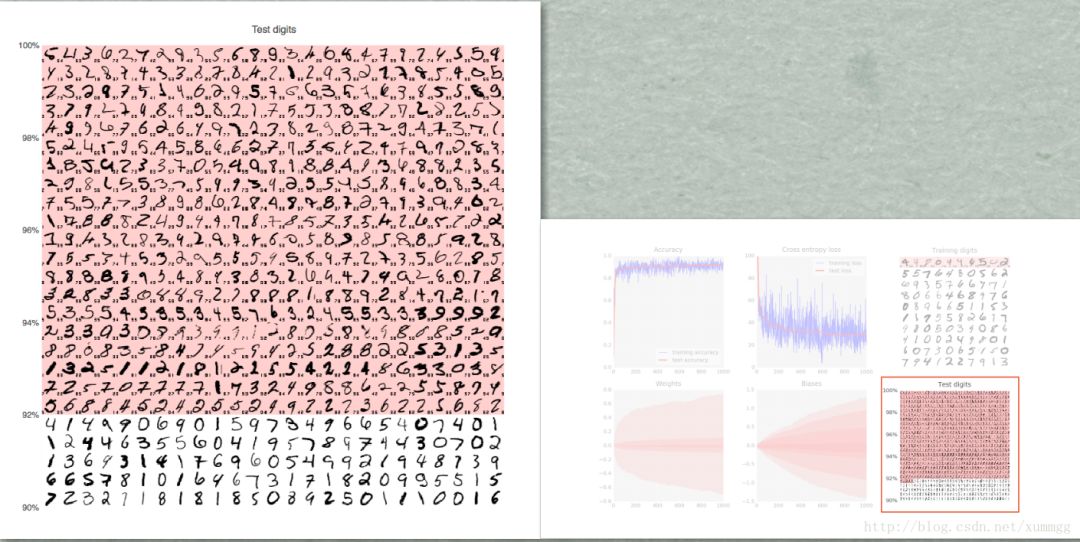
为了测试训练好后模型的识别质量,我们必须使用系统在训练期间没有用到过的手写数字。否则,模型可能会识别所有已训练的数字,但仍然不能识别我刚才新写的数字“8”。MNIST数据集中包含10,000个测试手写数字。在这图里,您可以看到大约1000个数字,其中所有被识别错误的,都放在顶部(红色背景上)。图左侧的比例可以大致表示分类器的准确性。
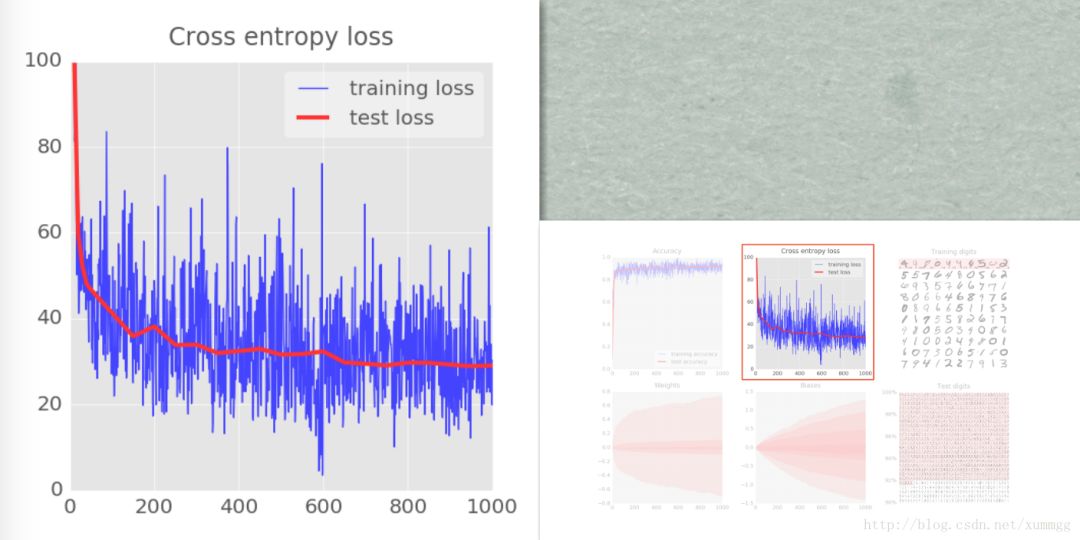
为了开展训练,我们将定义一个损失函数,即代表系统识别数字的程度值,并尝试将其最小化。损失函数的选择(这里是“交叉熵(cross-entropy)”)将在后面解释。您在这里看到的是,随着训练的进展,训练和测试数据的损失都会下降:这是好的。这意味着神经网络正在学习。X轴表示通过学习循环的迭代次数。
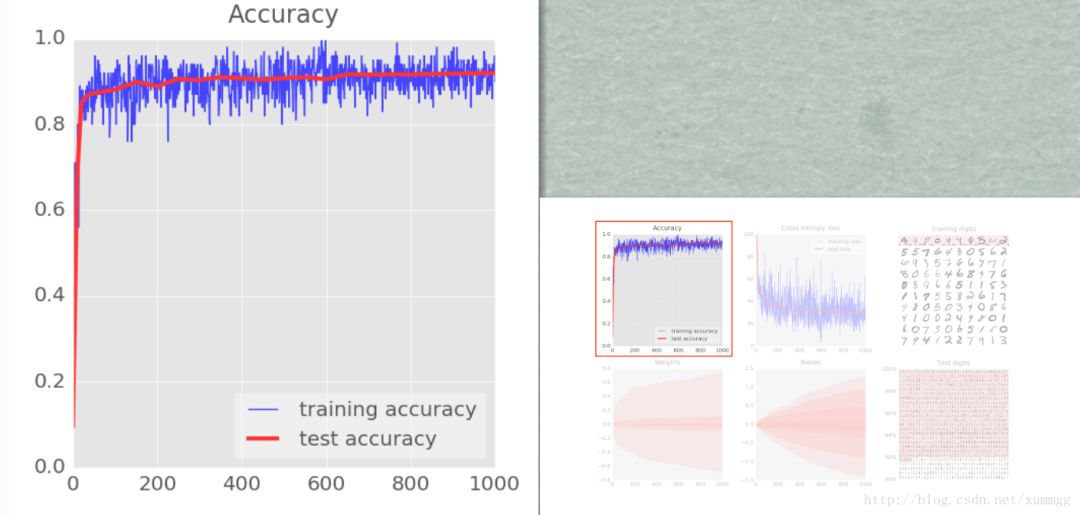
准确性只是正确识别的数字的百分比。这是在训练和测试集上计算的。如果训练顺利,你会看到它上升。
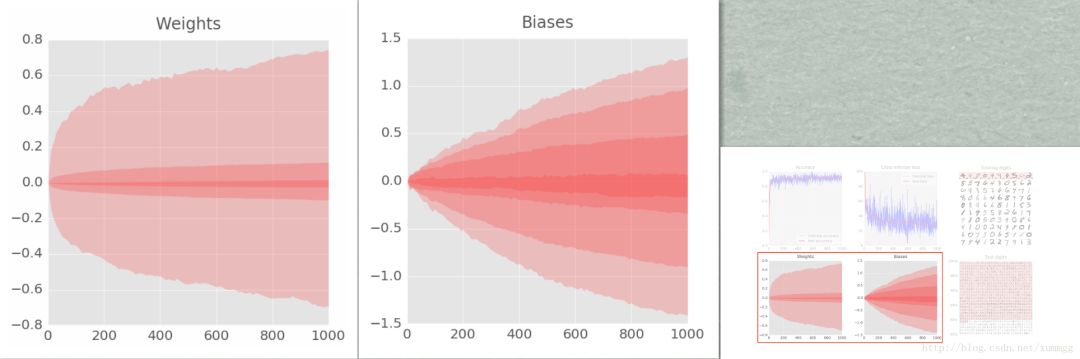
最后两个图代表了内部变量采用的所有值的范围,即随着训练的进行,权重和偏差。在这里,您可以看到,偏差最初从0开始,最终获得的值大致均匀分布在-1.5和1.5之间。如果系统不能很好地收敛,这些图可能很有用。如果你看到权重和偏差扩展到100或1000,训练可能就有问题了。
本文来自 微信公众号 datadw 【大数据挖掘DT数据分析】
图中的方格代表是百分位数。有7个频带,所以每个频带是100/7 =所有值的14%。
Keyboard shortcuts for the visualisation GUI:
1 ……… display 1st graph only
2 ……… display 2nd graph only
3 ……… display 3rd graph only
4 ……… display 4th graph only
5 ……… display 5th graph only
6 ……… display 6th graph only
7 ……… display graphs 1 and 2
8 ……… display graphs 4 and 5
9 ……… display graphs 3 and 6
ESC or 0 .. back to displaying all graphs
SPACE ….. pause/resume
O ……… box zoom mode (then use mouse)
H ……… reset all zooms
Ctrl-S …. save current image
什么是“ 权重 ”和“ 偏差 ”?如何计算“ 交叉熵 ”?训练算法究竟如何工作?那么来看下一节内容吧。
4. 理论:1层神经网络
MNIST数据集中的手写数字是28x28像素的灰度图像。对于它们进行分类的最简单方法是使用28x28 = 784像素作为第1层神经网络的输入。
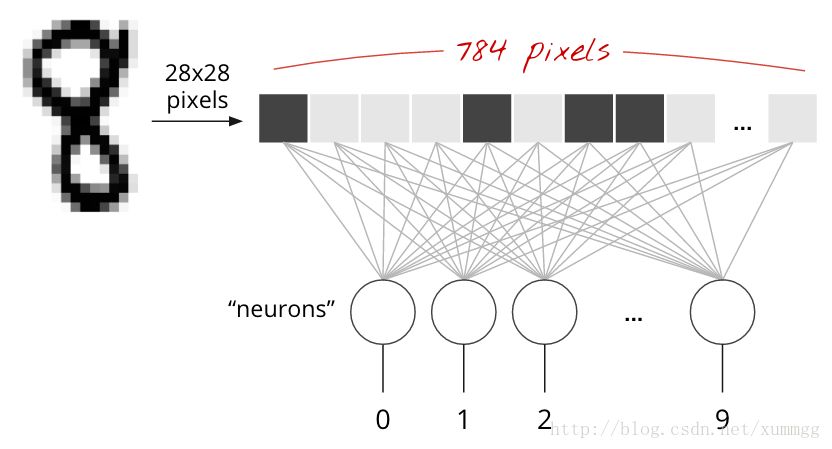
神经网络中的每个“神经元”都会对其所有输入进行加权和,增加一个称为“偏差”的常量,然后通过一些非线性激活函数来提取结果。
在这里,我们设计了一个具有10个神经元的1层神经网络,作为输出层,因为我们想将数字分为10个类(0到9),每个神经元都能分类处一个类。
对于一个分类问题,一个很好的激活函数是softmax。通过取每个元素的指数,然后归一化向量(使用任何范数,例如向量的普通欧几里德长度)来对向量应用softmax。

为什么“softmax”称为softmax?指数是急剧增长的函数。它将增加向量元素之间的差异。它也快速产生大的值。然后,当您规范化向量时,支配规范的最大元素将被归一化为接近1的值,而所有其他元素将最终除以一个较大的值,并归一化为接近零的值。清楚地显示出哪个是最大的元素,即“最大值”,但保留其价值的原始相对顺序,因此是“soft”。
我们现在将使用矩阵乘法将这个单层神经元的处理过程,用一个简单的公式表示。让我们直接用100张手写图片作为输入(如图中黑灰方块图所示,每行表示一张图片的784个像素值),产生100个预测(10个向量)作为输出。
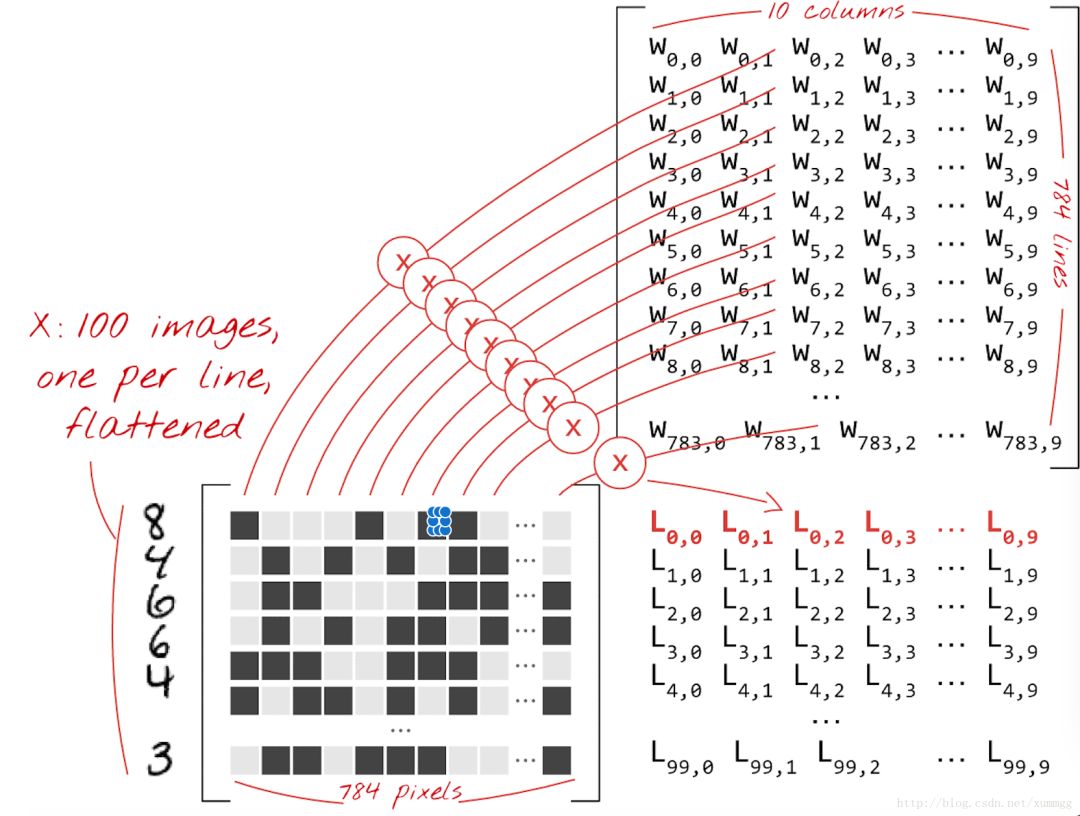
使用加权矩阵W中的第一列加权,我们计算第一张图像的所有像素的加权和。这个和值对应于第一个神经元。使用第二列权重,我们对第二个神经元做同样的事情,直到第10个神经元。然后,我们可以重复对剩余99张图像的操作。如果我们称X为包含我们100个图像的矩阵,则在100个图像上计算的我们10个神经元的所有加权和仅仅是XW(矩阵乘法)。
每个神经元现在必须加上它的偏差(一个常数)。由于我们有10个神经元,我们有10个偏置常数。我们将这个10个值的向量称为b。必须将其添加到先前计算的矩阵的每一行。使用一些名为“广播(broadcasting)”的方法,我们用简单的加号写下来。
“ 广播(broadcasting) ”是Python和numpy的标准技巧,它是科学计算库里的内容。它扩展了正常操作对具有不兼容尺寸的矩阵的作用范围。“广播添加”是指“如果要相加两个矩阵,但是由于其尺寸不兼容,请尝试根据需要复制小尺寸以使其能相加。”
我们最后应用softmax激活函数,得到描述1层神经网络的公式,应用于100幅图像:
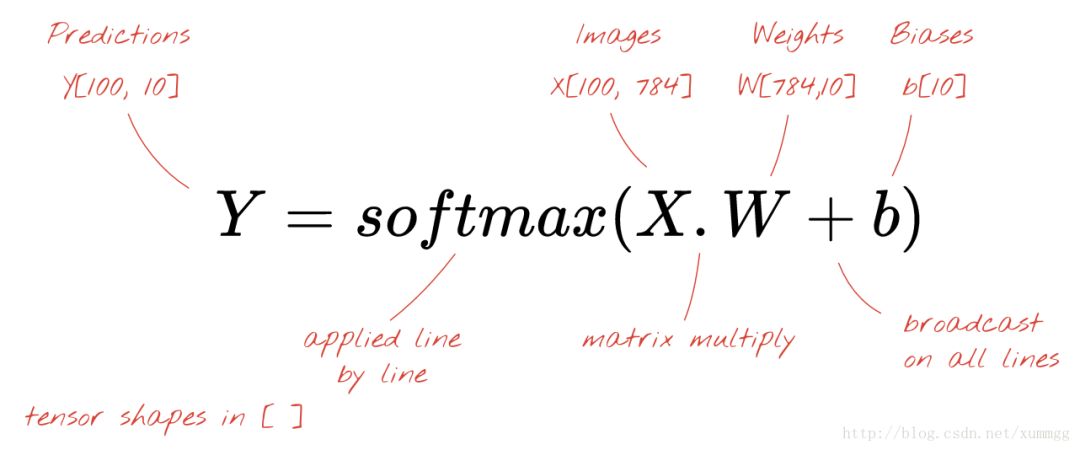
顺便说一下,什么是“ 张量(tensor) ”?
“张量(tensor)”就像一个矩阵,但是具有任意数量的维度。一维张量是向量。二维张量是矩阵。然后,您可以有3,4,5或更多维度的张量。
5. 理论:梯度下降
现在我们的神经网络产生了输入图像的预测,我们需要测量它们的好坏,即网络告诉我们与我们所知道的真相之间的距离。请记住,我们为此数据集中的所有图像的数字都有正确数字的标签。
任何距离都会有效,普通的欧几里得距离很好,但是对于分类问题,一个距离,称为“交叉熵(cross-entropy)”更有效率。

“ 一热(One-hot) ”编码意味着您使用10个值的矢量代表标签“6”,全部为零,但第6个值为1.这是因为格式非常类似于我们的神经网络输出预测,也作为10个值的向量。
“训练”神经网络实际上意味着使用训练图像和标签来调整权重和偏差,以便最小化交叉熵损失函数。下面是它的工作原理。
交叉熵是训练图像的权重,偏差,像素及其已知标签的函数。
如果我们相对于所有权重和所有偏差计算交叉熵的偏导数,我们获得了对于给定图像,权重和偏差的标签和现值计算的“梯度(gradient)”。记住,我们有7850个权重和偏差,所以计算梯度听起来好像有很多工作。幸运的是,TensorFlow将为我们做好准备。
梯度的数学属性是它指向“上”。由于我们想要走交叉熵低的地方,所以我们走向相反的方向。我们将权重和偏差更新一小部分梯度,并使用下一批训练图像再次执行相同的操作。希望这让我们到达交叉熵最小的坑底。
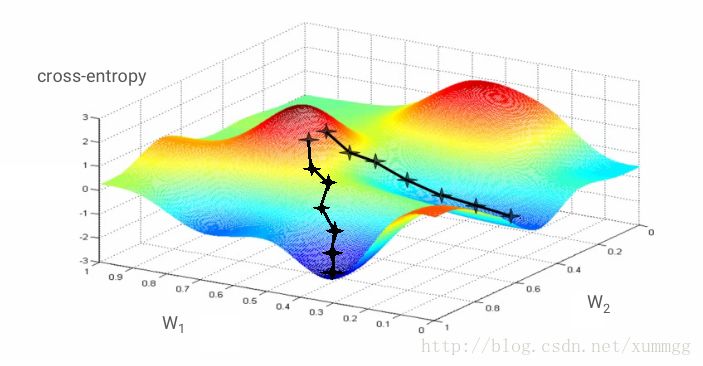
在该图中,交叉熵表示为2个权重的函数。实际上还有更多的。梯度下降算法遵循最快速下降到局部最小值的路径。训练图像也会在每次迭代中更改,以便我们收敛到适用于所有图像的局部最小值。
“ 学习率”:您无法在每次迭代时以渐变的整个长度更新您的权重和偏差。这就好比是一个穿着靴子的人,想去一个山谷的底部。他会从山谷的一边跳到另一边。要进入底部,他需要执行较小的步骤,即仅使用渐变的一小部分,通常在1/1000。我们将这个分数称为“学习率”。
总而言之,训练循环如下所示:
训练数据和标签 => 求损失函数=> 求梯度 (偏导数) => 最快下降 => 更新权重和偏差 => 重复下一个小批量的图像数据和标签
为什么要使用100个图像和标签,用这种“ 小批量 ”形式进行?
您只需一个示例图像即可计算您的渐变,并立即更新权重和偏差(在文献中称为“随机梯度下降”)。这样做100个例子给出了更好地表示不同示例图像所施加的约束的渐变,因此可能更快地收敛到解决方案。小批量的尺寸是可调参数。还有另一个更技术的原因:使用大批量也意味着使用更大的矩阵,这些通常更容易在GPU上进行优化。
6. 实验室:让我们跳入代码
已经写了1层神经网络的代码。请打开mnist_1.0_softmax.py文件并按照说明进行操作。
您在本节中的任务是了解此起始代码,以便以后可以改进。
您应该看到文件中的说明和代码之间只有微小的区别。它们对应于用于可视化的功能,并在注释中做了说明。你可以忽略它们。
mnist_1.0_softmax.py
import tensorflow as tfX = tf.placeholder(tf.float32, [None, 28, 28, 1])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
init = tf.initialize_all_variables()
首先我们定义TensorFlow变量和占位符。变量是您希望训练算法为您确定的所有参数。在我们的情况下,我们的权重和偏见。
占位符是在训练期间填充实际数据的参数,通常是训练图像。保持训练图像的张量的形状是[None,28,28,1],代表:
mnist_1.0_softmax.py
# modelY = tf.nn.softmax(tf.matmul(tf.reshape(X, [-1, 784]), W) + b)# placeholder for correct labelsY_ = tf.placeholder(tf.float32, [None, 10])# loss functioncross_entropy = -tf.reduce_sum(Y_ * tf.log(Y))# % of correct answers found in batchis_correct = tf.equal(tf.argmax(Y,1), tf.argmax(Y_,1))
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
第一行是我们的1层神经网络的模型。公式是我们在以前的理论部分中建立的公式。该tf.reshape命令将我们的28x28图像转换为784像素的单个向量。重塑命令中的“-1”表示“计算机,计算出来,只有一种可能性”。实际上,这将是一个小批量的图像数量。
然后,我们需要一个附加的占位符,用于提供与培训图像一起的标签数据。
现在,我们有模型预测和正确的标签,所以我们可以计算交叉熵。tf.reduce_sum总和一个向量的所有元素。
最后两行计算正确识别的数字的百分比。留给读者使用TensorFlow API参考书,以供读者理解。你也可以跳过它们。
mnist_1.0_softmax.py
optimizer = tf.train.GradientDescentOptimizer(0.003)
train_step = optimizer.minimize(cross_entropy)
这里将是TensorFlow展示它能力的时候了。您选择一个优化器(有很多可用),并要求它最小化交叉熵损失。在此步骤中,TensorFlow计算相对于所有权重和所有偏差(梯度)的损失函数的偏导数。这是一个正式的推导,而不是一个数字化的,太费时间了。
然后使用梯度来更新权重和偏差。0.003是学习率。
最后,现在是运行训练循环的时候了。到目前为止,所有的TensorFlow指令都已经在内存中准备了一个计算图,但还没有计算出来。
TensorFlow的“延迟执行”模型:TensorFlow是为分布式计算构建的。在开始实际将计算任务发送到各种计算机之前,必须知道要计算的内容,即执行图。这就是为什么它有一个延迟执行模型,您首先使用TensorFlow函数在内存中创建计算图,然后开始Session执行并使用实际的计算Session.run。在这一点上,计算图不能再改变了。
由于该模式,TensorFlow可以接管大量的分布式计算流。例如,如果您指示在计算机1上运行一部分计算,并在计算机2上运行另一部分,则可以自动进行必要的数据传输。
计算需要将实际数据输入到您在TensorFlow代码中定义的占位符。这是以Python字典的形式提供的,其中的键值是占位符的名称。
mnist_1.0_softmax.py
sess = tf.Session()
sess.run(init)
for i in range(1000): # load batch of images and correct answers
batch_X, batch_Y = mnist.train.next_batch(100)
train_data={X: batch_X, Y_: batch_Y} # train
sess.run(train_step, feed_dict=train_data)
在train_step当我们问到TensorFlow出最小交叉熵是这里执行获得。那就是计算梯度并更新权重和偏差的步骤。
最后,我们还需要计算一些可以显示的值,以便我们可以跟踪我们模型的性能。
在训练循环中使用该代码训练数据计算精度和交叉熵(例如每10次迭代):
# success ?
a,c = sess.run([accuracy, cross_entropy],
feed_dict=train_data)
通过提供测试训练数据,可以在测试数据上计算相同的数值(例如,每100次重复一次,有10,000个测试数字,因此需要一些CPU时间):
# success on test data ?
test_data={X: mnist.test.images, Y_: mnist.test.labels}
a,c = sess.run([accuracy, cross_entropy], feed=test_data)
TensorFlow和NumPy的是朋友:准备计算图时,你只有操纵TensorFlow张量和如命令tf.matmul,tf.reshape等等。
然而,一旦执行Session.run命令,它返回的值就是Numpy张量,即Numpy numpy.ndarray可以使用的对象以及基于它的所有科学comptation库。这就是使用matplotlib(这是基于Numpy的标准Python绘图库)为这个实验室建立的实时可视化。
7. 实验室:添加图层
为了提高识别精度,我们将为神经网络添加更多层数。第二层中的神经元,而不是计算像素的加权和,将计算来自上一层的神经元输出的加权和。这里是一个5层完全连接的神经网络:
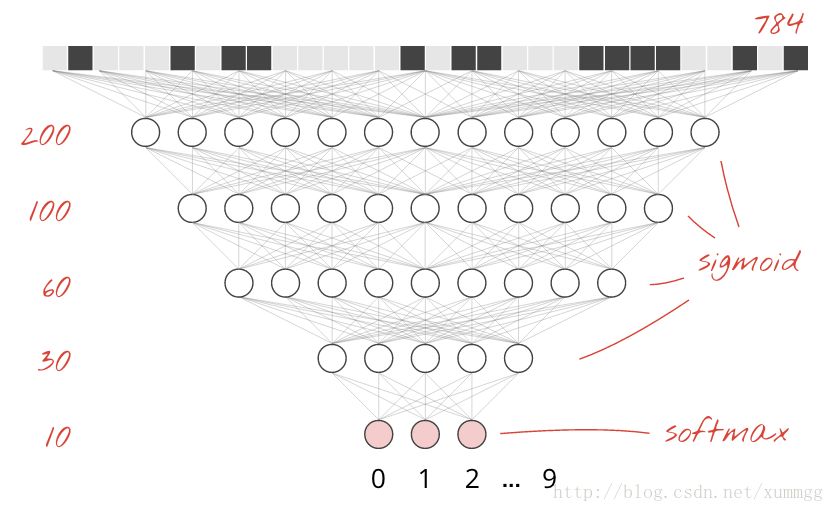
我们保持softmax作为最后一层的激活功能,因为这是最适合分类的。在中间层上,我们将使用最经典的激活函数:sigmoid:
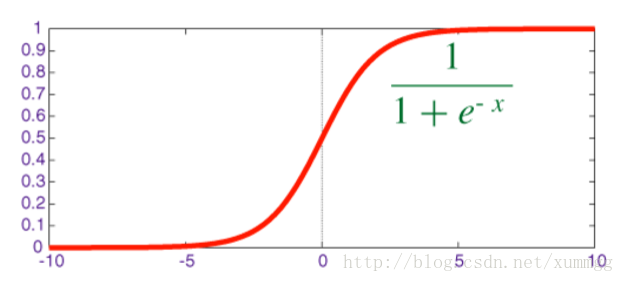
您在本节中的任务是将一个或两个中间层添加到您的模型中以提高其性能。
解决方案可以在文件中找到mnist_2.0_five_layers_sigmoid.py。使用它,如果你不能写出来,被卡住了!
要添加图层,您需要一个额外的权重矩阵和中间层的附加偏置向量:
W1 = tf.Variable(tf.truncated_normal([28*28, 200] ,stddev=0.1))
B1 = tf.Variable(tf.zeros([200]))
W2 = tf.Variable(tf.truncated_normal([200, 10], stddev=0.1))
B2 = tf.Variable(tf.zeros([10]))
权重矩阵的形状是[N,M],其中N是层的输入数量和M的输出。在上面的代码中,我们在中间层中使用了200个神经元,在最后一层使用了10个神经元。
提示:当你深入时,重要的是用随机值初始化权重。如果没有,优化器可能会停留在初始位置。tf.truncated_normal是一个TensorFlow函数,它产生遵循-2* stddev和+ 2 * stddev之间的正态(高斯)分布的随机值。
现在将1层模型更改为2层模型:
XX = tf.reshape(X, [-1, 28*28])
Y1 = tf.nn.sigmoid(tf.matmul(XX, W1) + B1)
Y = tf.nn.softmax(tf.matmul(Y1, W2) + B2)
您现在应该可以使用2个中间层(例如200和100个神经元)将精度推送到97%以上的精度。
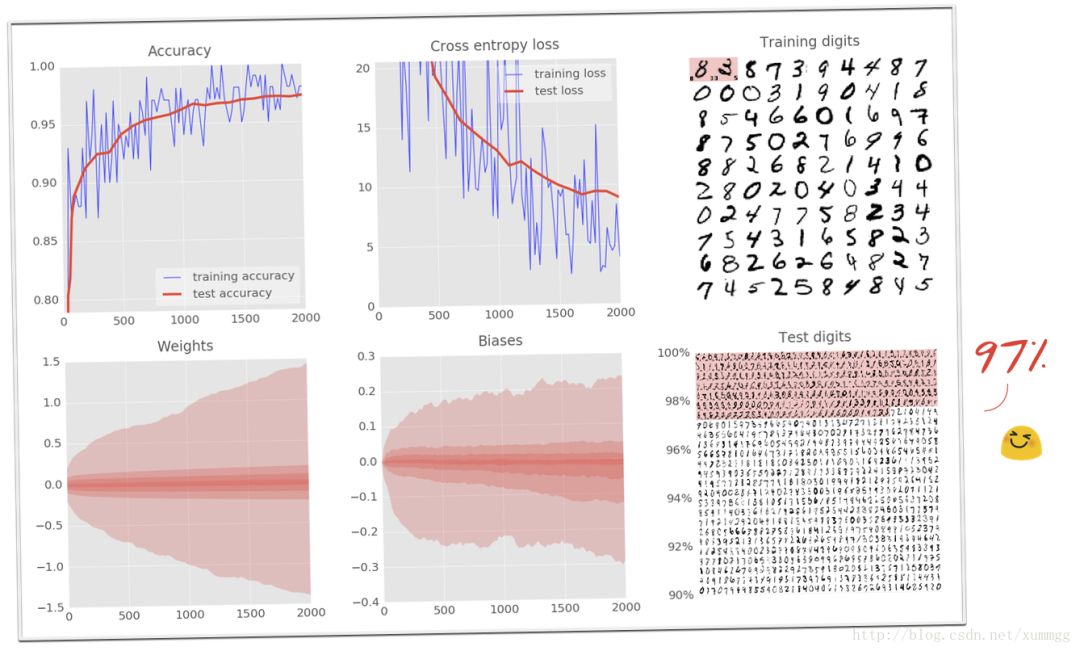
8. 实验室:深度网络的特别照顾
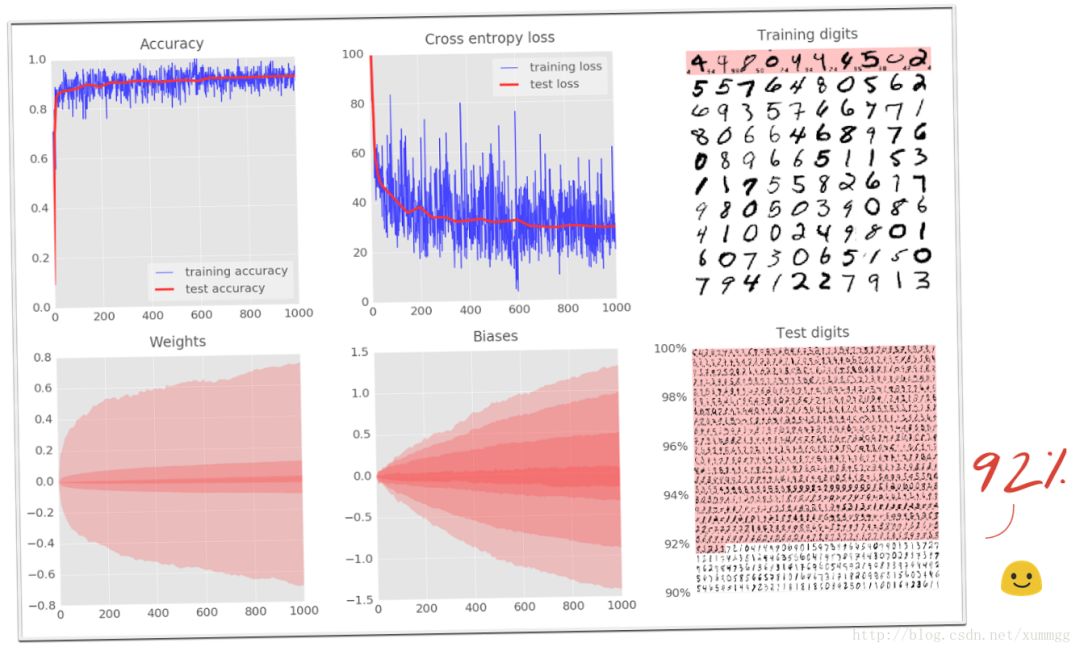
随着层次的增加,神经网络趋向于收敛更多困难。但我们今天知道如何使他们的工作。如下图,如果您看到这样的精度曲线,本节将对您有所帮助:
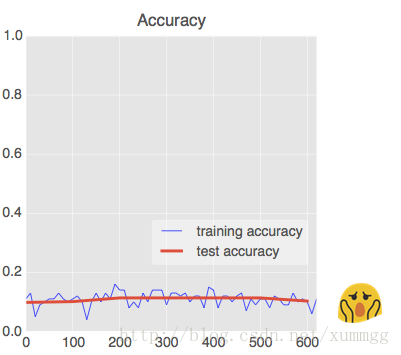
Relu激活功能
在深层网络中,S形激活函数(sigmoid函数)实际上是相当有问题的。它压缩0和1之间的所有值,当您反复进行时,神经元输出及其渐变可以完全消失。改进的方法,可以使用如下所示的RELU函数(整流线性单元):
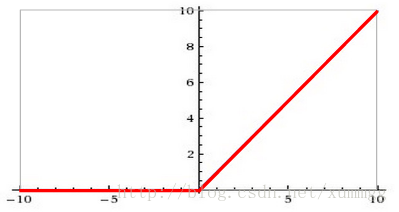
更新1/4:现在用RELU替换所有的S型,并且在加入图层时,您将获得更快的初始收敛,避免出现问题。只需在你的代码中简单更换tf.nn.sigmoid用tf.nn.relu。
一个更好的优化器
在这样的非常高的维度空间中,我们有10K的权重和偏差 - “鞍点”是频繁的。这些是不是局部最小值的点,但梯度仍然为零,梯度下降优化器仍然停留在那里。TensorFlow拥有一系列可用的优化器,其中包括一些可以使用一定惯量的优化器,并可以安全避开鞍点。
更新2/4:替换tf.train.GradientDescentOptimiser为tf.train.AdamOptimizer现在。
随机初始化
精确度仍然在0.1?你用随机值初始化了你的权重吗?对于偏差,当使用RELU时,最佳做法是将其初始化为小的正值,以使神经元最初在RELU的非零范围内运行。
W = tf.Variable
(tf.truncated_normal([K, L] ,stddev=0.1))
B = tf.Variable(tf.ones([L])/10)
更新3/4:现在检查所有的权重和偏差是否适当初始化。如上图所示的0.1将作为初始偏差。
NaN ???
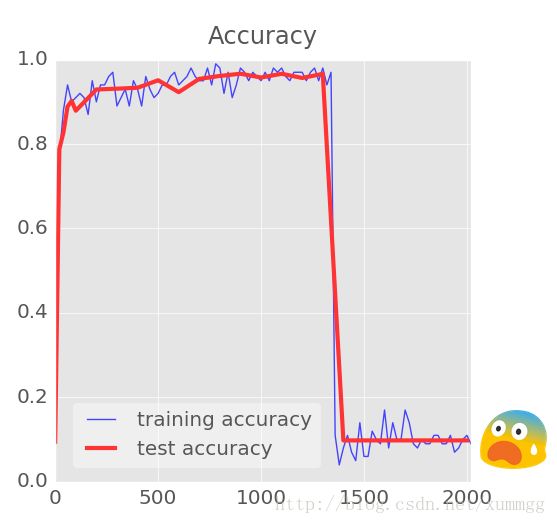
如果您看到准确度曲线崩溃,并且控制台输出NaN作为交叉熵,请不要惊慌,您正在尝试计算一个不是数(NaN)的值(0)。请记住,交叉熵涉及在softmax层的输出上计算的日志。由于softmax本质上是一个指数,从不为零,所以我们应该很好,但使用32位精度浮点运算,exp(-100)已经是一个真正的零。说白了就是,小数点后0太多,超出计算机精度,计算机将其判断为0,并作了分母,然后就出现这种现象。
幸运的是,TensorFlow具有一个方便的功能,可以在数字稳定的方式下实现单步骤中的softmax和交叉熵。要使用它,您需要在应用softmax之前,将最后一层的原始加权和加上偏差取对数(logits)。
如果您的模型的最后一行是:
Y = tf.nn.softmax(tf.matmul(Y4, W5) + B5)
您需要更换它:
Ylogits = tf.matmul(Y4, W5) + B5Y = tf.nn.softmax(Ylogits)
现在,您可以以安全的方式计算交叉熵:
cross_entropy = tf.nn.softmax_cross_entropy_
with_logits(Ylogits, Y_)
还添加这条线,使测试和训练交叉熵达到相同的显示尺度:
cross_entropy = tf.reduce_mean(cross_entropy)*100
更新4/4:请添加tf.nn.softmax_cross_entropy_with_logits到您的代码。您也可以跳过此步骤,当您在输出中实际看到NaN时,可以回到该步骤。
你现在准备好深入
9. 实验:学习率衰减
使用两个,三个或四个中间层,如果将迭代推送到5000或更高,您现在可以获得接近98%的准确性。但是你会看到结果不是很一致。
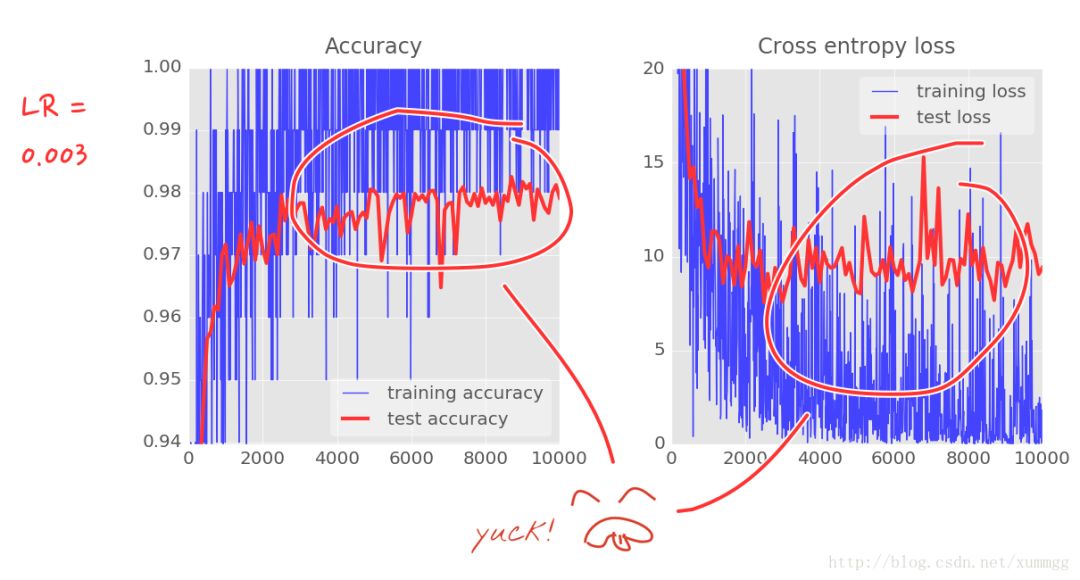
这些曲线真的很嘈杂,看看测试的准确性:它全部上下跳跃。这意味着即使学习率为0.003,我们也走得太快了。但是,我们不能将学习率除以十,否则训练将永远存在。良好的解决方案是开始快速,并将学习速率以指数方式衰减为0.0001。
这一点变化的影响是壮观的。您可以看到大部分噪音已经消失,测试精度现在高达98%以上
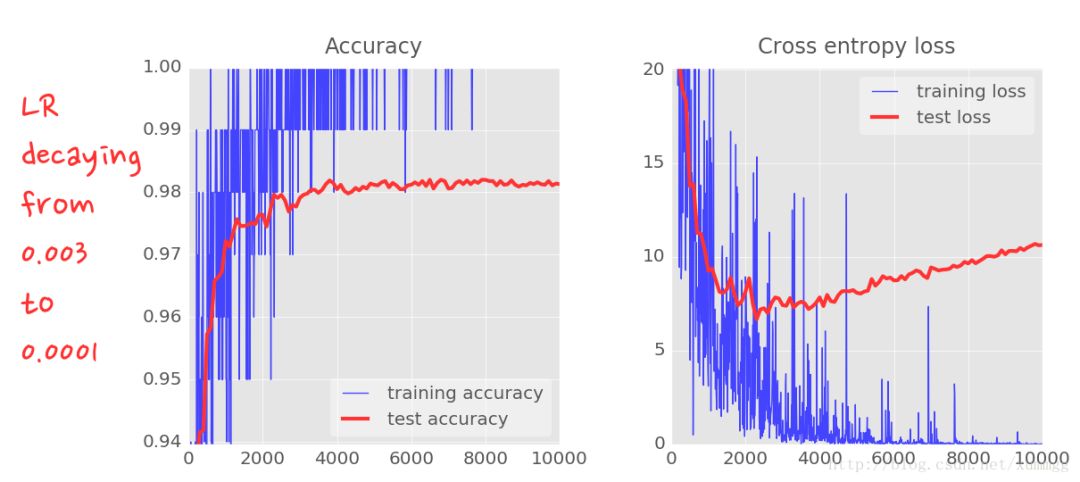
还要看训练精度曲线。现在已经达到了几个纪元的100%(1个纪元= 500次迭代=训练了所有的训练图像一次)。第一次,我们能够学习完美地识别训练图像。
请添加学习率衰减到你的代码。为了在每次迭代时将不同的学习率传递给AdamOptimizer,您将需要定义一个新的占位符,并在每次迭代时向它提供一个新的值feed_dict。
以下是指数衰减的公式: lr = lrmin+(lrmax-lrmin)*exp(-i/2000)
解决方案可以在文件中找到mnist_2.1_five_layers_relu_lrdecay.py。
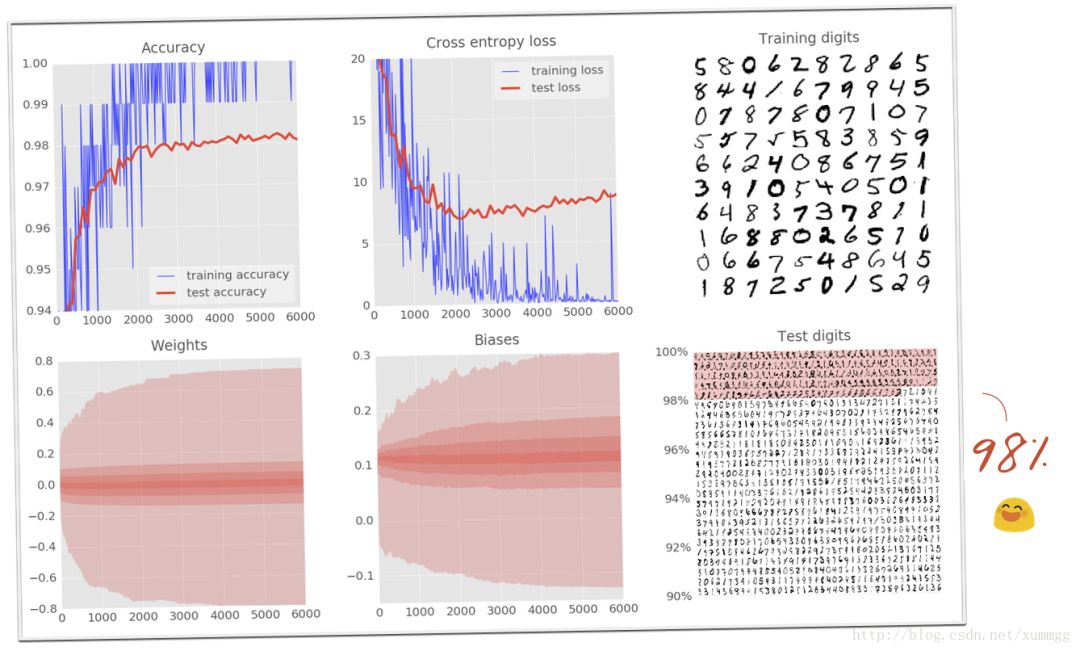
10. 实验室:丢失信息,过度配合
您将注意到,测试和训练数据的交叉熵曲线在数千次迭代后开始断开连接。学习算法仅用于训练数据,并相应地优化训练交叉熵。它从来没有看到测试数据,所以毫不奇怪,一段时间后,它的工作不再对测试交叉熵产生影响,测试交叉熵停止下降,有时甚至反弹。
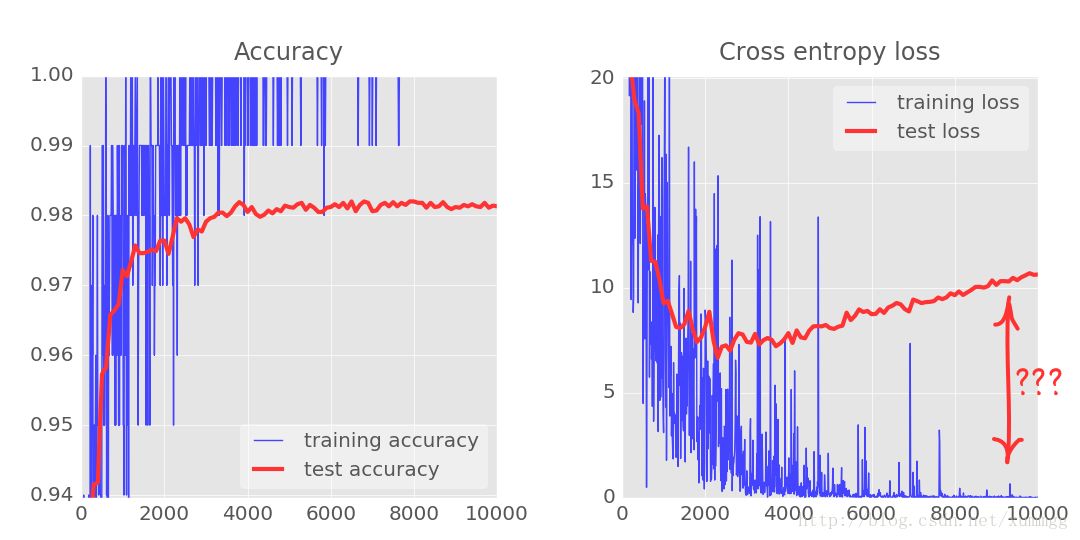
这不会立即影响您的模型的真实识别能力,但它将阻止您运行许多迭代,并且通常是训练不再具有积极作用的迹象。这个断开连接通常被标记为“过度拟合”,当您看到它时,您可以尝试应用称为“丢失信息”的正则化技术。
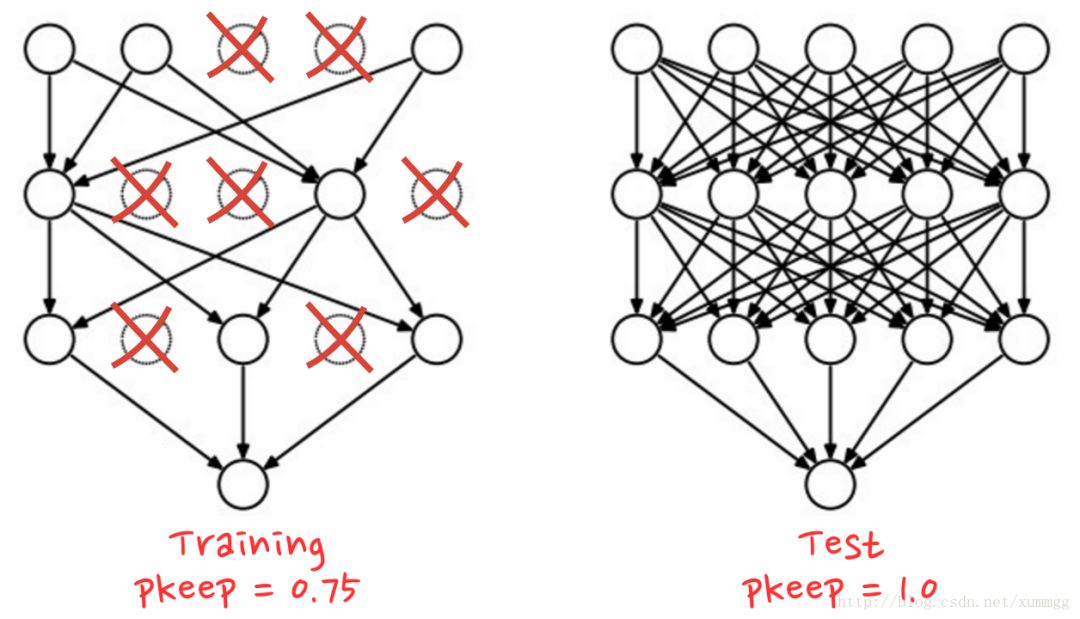
在丢失数据期间,在每次训练迭代中,您从网络中丢弃随机神经元。您选择pkeep保留神经元的概率,通常在50%至75%之间,然后在训练循环的每次迭代中,随机移除所有权重和偏差的神经元。不同的神经元将在每次迭代中被丢弃(并且您还需要按比例提升剩余神经元的输出,以确保下一层的激活不会移动)。当您测试网络的性能时,您将所有神经元都放回(pkeep=1)。
TensorFlow提供了一个用于神经元层输出的压差函数。它随机排除一些输出,并将其余的输出提高1 / pkeep。以下是您如何在两层网络中使用它:
# feed in 1 when testing, 0.75 when training
pkeep = tf.placeholder(tf.float32)
Y1 = tf.nn.relu(tf.matmul(X, W1) + B1)
Y1d = tf.nn.dropout(Y1, pkeep)Y = tf.nn.softmax(
tf.matmul(Y1d, W2) + B2)
您可以在网络中的每个中间层之后添加丢失数据(dropout)。这是实验室的可选步骤。
解决方案可以在文件中找到mnist_2.2_five_layers_relu_lrdecay_dropout.py。
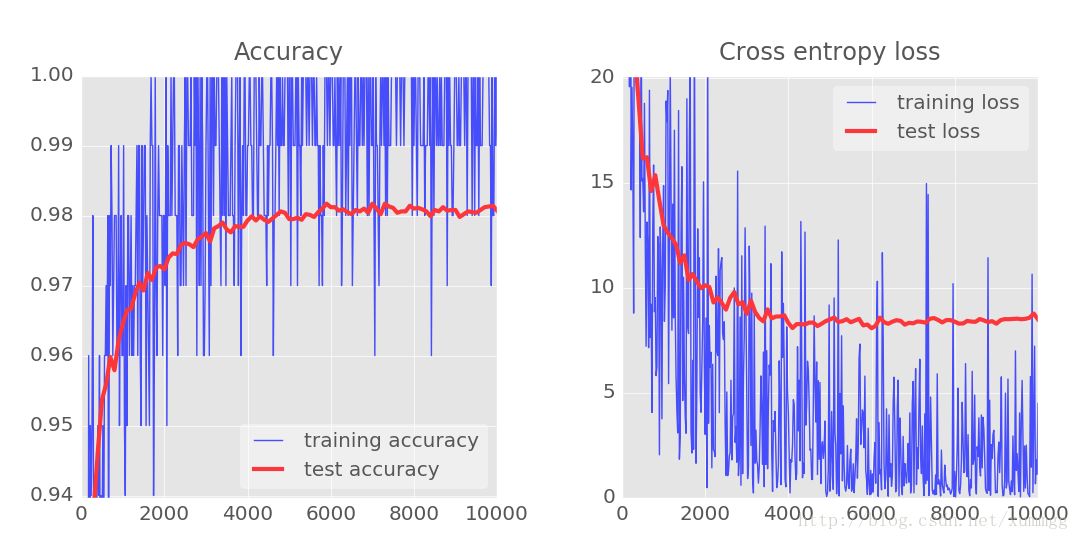
您应该看到,测试损失在很大程度上被控制,噪音重新出现,但在这种情况下,至少测试精度保持不变,这是有点令人失望。这里出现“过度配合”的另一个原因。
在我们继续之前,总结一下我们迄今为止所尝试的所有工具:
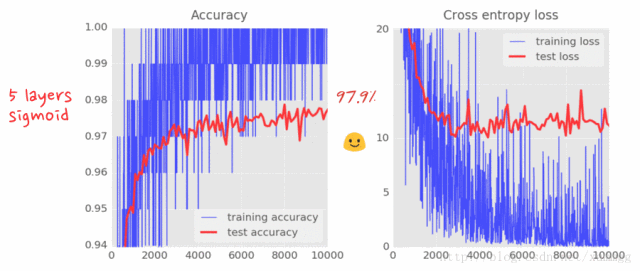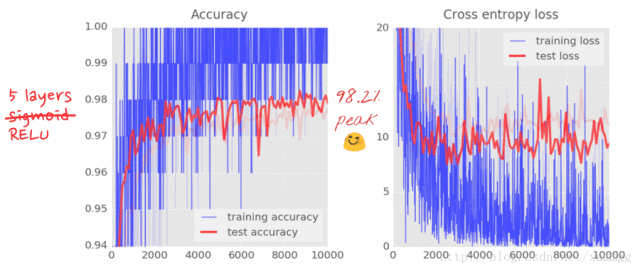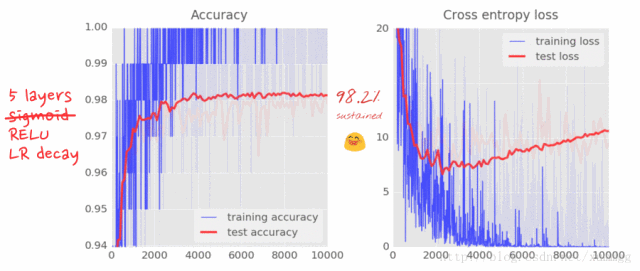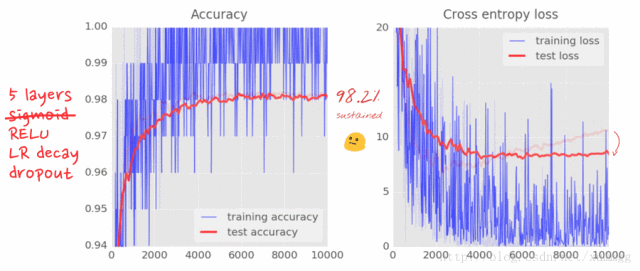
无论我们做什么,我们似乎无法以显著的方式打破98%的障碍,我们的损失曲线仍然表现出“过拟合”的问题。什么是真正的“过拟合”?当一个神经网络学习“不好”时,过拟合就会发生,这种方式对于训练样例起作用,但对于现实世界的数据却不太好。有正规化技术,如丢失数据(dropout),可以强制它以更好的方式学习,但过拟合也有更深的根源。
当神经网络对于手头的问题具有太多的自由度时,会发生基本的过拟合。想象一下,我们有这么多神经元,网络可以存储我们所有的训练图像,然后通过模式匹配识别它们。它将完全失真在真实世界的数据。一个神经网络必须有一定的约束。
如果你有很少的培训数据,即使一个小的网络也可以完成学习。一般来说,你总是需要大量的数据来训练神经网络。
最后,如果你做的一切都很好,尝试不同大小的网络,以确保其自由度受到限制,应用丢失数据(dropout),并训练大量的数据,你可能仍然被困在一个性能水平,似乎没有什么可以提高。这意味着您的神经网络目前的形状不能从您的数据中提取更多的信息,就像我们在这里一样。
记住我们如何使用手写图像,将所有像素平坦化为单个向量?那是一个很糟糕的主意 手写数字由形状组成,当我们平铺像素时,我们舍弃了形状信息。然而,有一种类型的神经网络可以利用形状信息:卷积网络。让我们试试看吧。
11. 理论:卷积网络

在卷积网络的层中,一个“神经元”仅在图像的小区域上进行恰好在其上方的像素的加权和。然后,通过添加偏置并通过其激活功能馈送结果来正常地起作用。最大的区别是每个神经元都会重复使用相同的权重,而在之前看到的完全连接的网络中,每个神经元都有自己的权重集。
在上面的动画中,您可以看到,通过在两个方向(卷积)上滑过图像的权重块,您可以获得与图像中的像素一样多的输出值(尽管边缘需要一些填充)。
要使用4x4的补丁大小和彩色图像作为输入生成一个输出值平面,如动画中那样,我们需要4x4x3 = 48的权重。这还不够 为了增加更多的自由度,我们用不同的权重重复相同的事情。
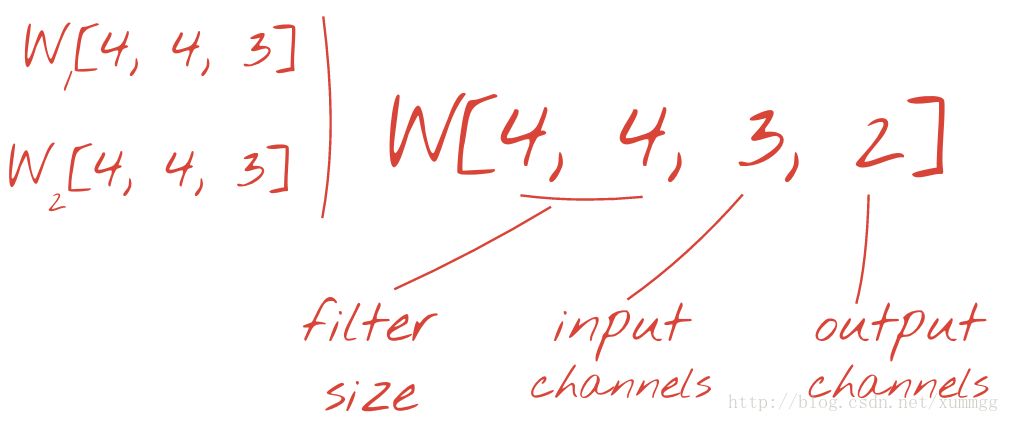
通过向张量添加维度,可以将两个(或多个)权重组重写为一个,这给出了卷积层的权重张量的通用形状。由于输入和输出通道的数量是参数,我们可以开始堆叠和链接卷积层。
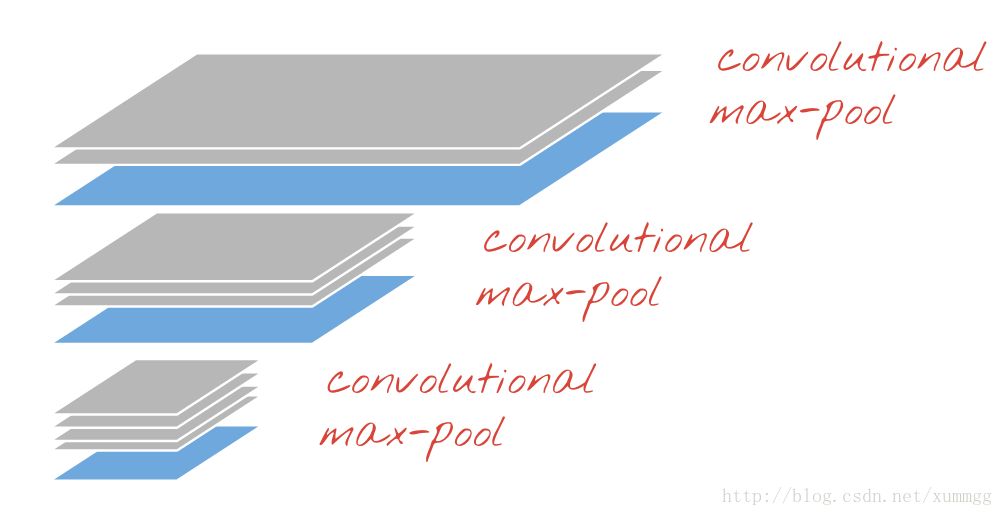
最后一个问题仍然存在。我们仍然需要将信息调低。在最后一层,我们仍然只需要10个神经元来代替我们的10个数字。传统上,这是通过“最大池”层完成的。即使今天有更简单的方法,“最大池(max-pooling)”有助于直观地了解卷积网络的运行情况:如果您假设在训练过程中,我们的小块权重会演变成过滤器,可以识别基本形状(水平和垂直线,曲线,……)然后一种将有用信息向下传递的方式是通过层数保持最大强度识别形状的输出。实际上,在最大池层中,神经元输出以2x2为一组进行处理,只保留最多一个。
有一种更简单的方法:如果您以2像素而不是1像素的速度滑过图像,则还会获得较少的输出值。这种方法已被证明是同样有效的,而今天的卷积网络仅使用卷积层。
让我们建立一个手写数字识别的卷积网络。我们将在顶部使用三个卷积层,我们的传统softmax读出层在底部,并连接到一个完全连接的层:
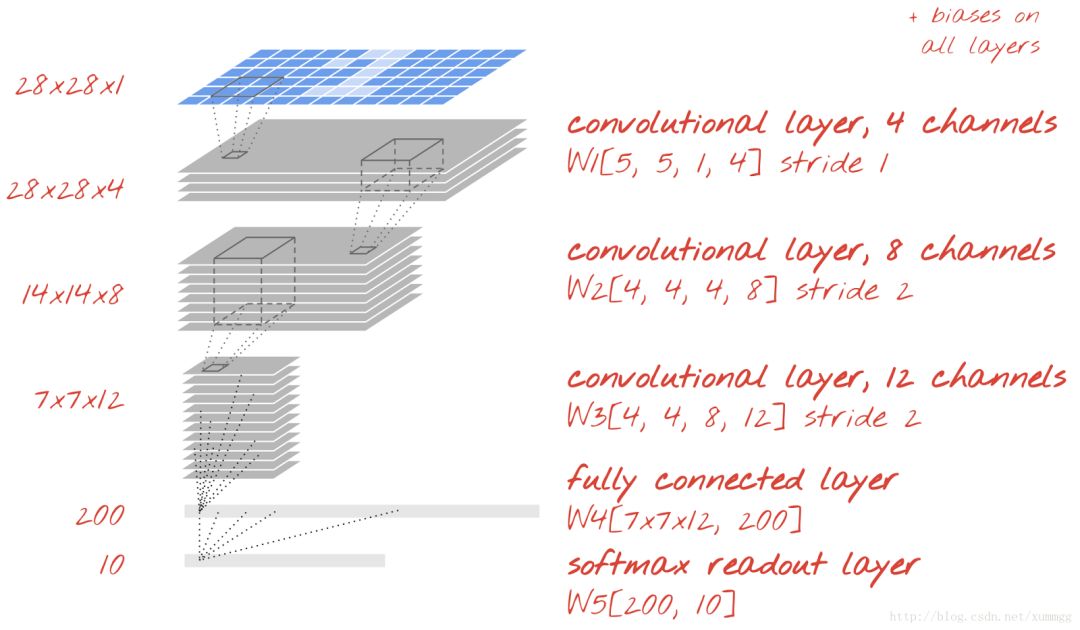
请注意,第二和第三卷积层有两个步长,这说明为什么它们将输出值从28x28降低到14x14,然后是7x7。完成这些层的大小,使得神经元的数量在每一层大致下降2倍:28x28x4≈3000→14x14x8≈1500→7x7x12≈500→200.跳转到下一节执行。
12. 实验室:卷积网络
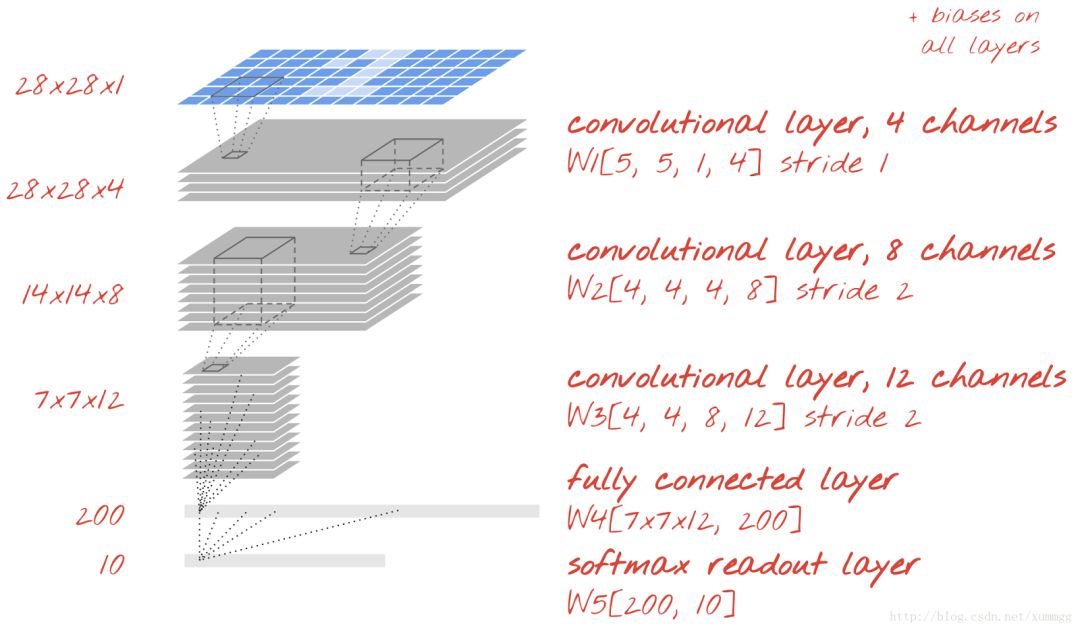
要将我们的代码切换到卷积模型,我们需要为卷积层定义适当的权重张量,然后将卷积图层添加到模型中。
我们已经看到卷积层需要以下形状的权重张量。这是初始化的TensorFlow语法:

W = tf.Variable(tf.truncated_normal([4, 4, 3, 2],
stddev=0.1))
B = tf.Variable(tf.ones([2])/10)
# 2 is the number of output channels
可以tf.nn.conv2d使用使用提供的权重在两个方向上执行输入图像的扫描的功能在TensorFlow中实现卷积层。这只是神经元的加权和部分。您仍然需要添加偏差并通过激活功能提供结果。
stride = 1 # output is still 28x28Ycnv = tf.nn.conv2d(
X, W, strides=[1, stride, stride, 1],
padding='SAME')
Y = tf.nn.relu(Ycnv + B)
不要太多地关注跨步的复杂语法。查看文档的完整详细信息。在这里工作的填充策略是从图像的两边复制像素。所有数字都在统一的背景上,所以这只是扩展了背景,不应该添加任何不需要的形状。
轮到你玩了,修改你的模型,把它变成一个卷积模型。您可以使用上图中的值来对其进行调整。你可以保持你的学习速度衰减,但是现在请删除丢失信息(dropout)。
解决方案可以在文件中找到mnist_3.0_convolutional.py。
您的模型应该能够轻松地打破98%的屏障。看看测试交叉熵曲线。你是不是能马上想到解决方案呢?
13. 实验室:99%的挑战
调整神经网络的一个很好的方法是实现一个有点太限制的网络,然后给它一个更多的自由度,并添加丢失信息(dropout),以确保它不是过拟合。这样最终可以为您的问题提供一个相当理想的神经网络。
这里例如,我们在第一个卷积层中只使用了4个像素。如果您接受这些权重补丁在训练过程中演变成形状识别器,您可以直观地看到这可能不足以解决我们的问题。手写数字是超过4个像素形状的模式。
所以让我们稍微增加像素大小,将卷积层中的补丁数量从4,8,12提高到6,12,24,然后在完全连接的层上添加dropout。为什么不在卷积层上?他们的神经元重复使用相同的权重,所以通过在一次训练迭代纪元,冻结一些权重有效地起作用的dropout将不起作用。
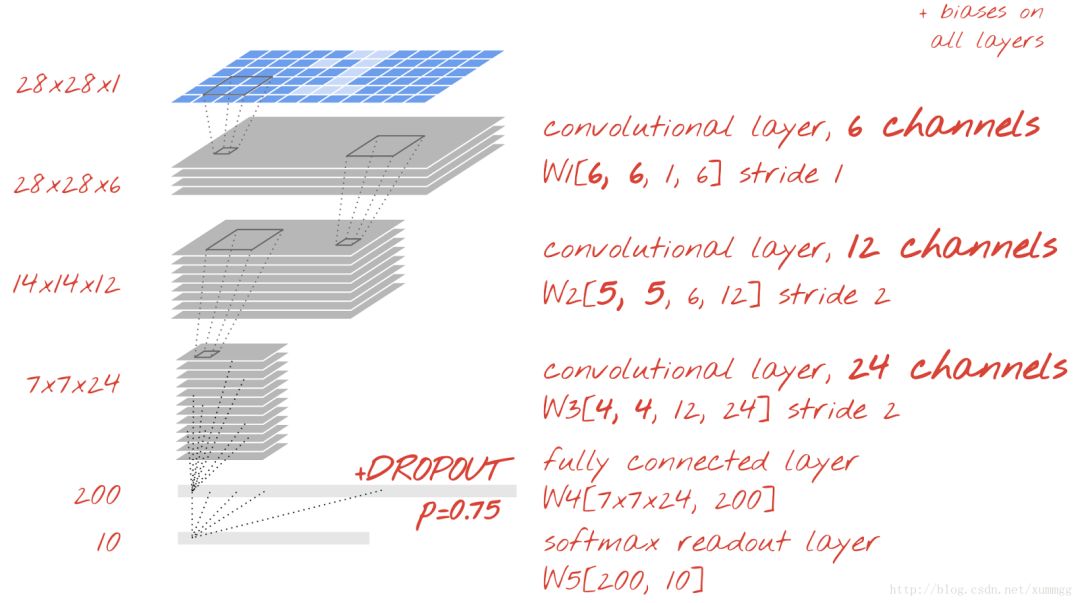
去吧,打破99%的限制。增加像素大小和通道数,如上图所示,并在卷积层上添加dropout。
解决方案可以在文件中找到mnist_3.1_convolutional_bigger_dropout.py
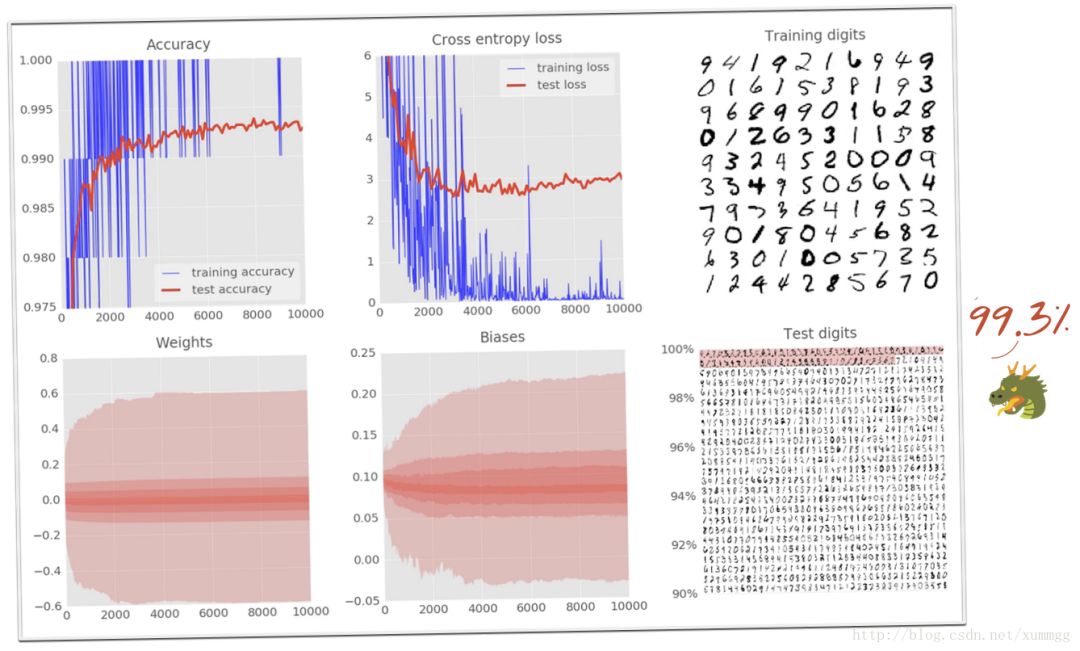
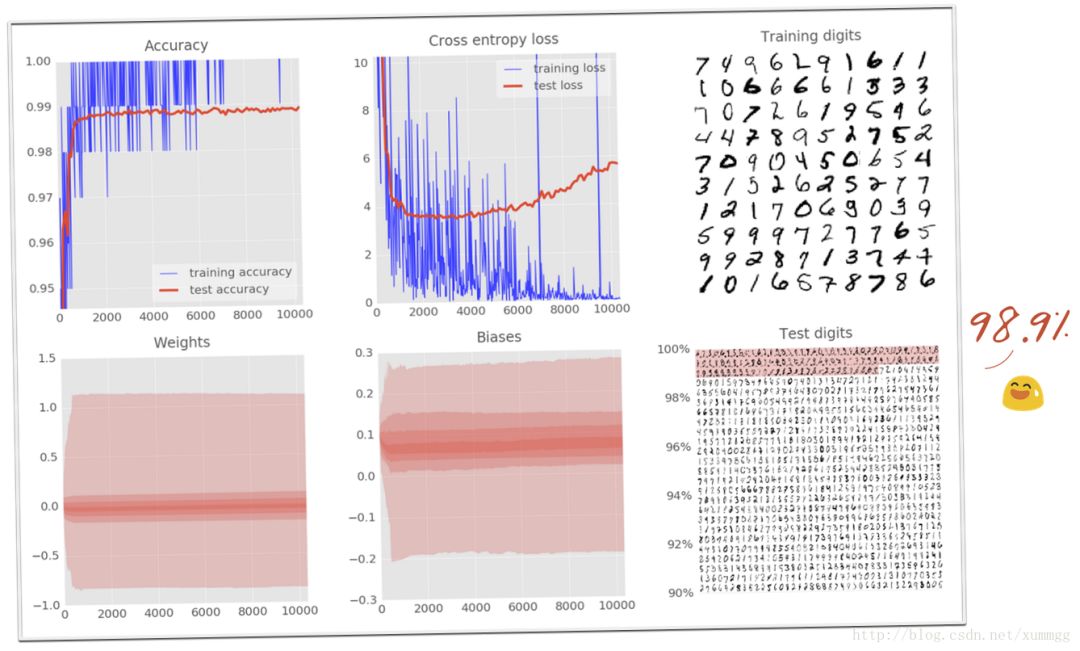
上图所示的模型仅识别错了10,000个测试数字中的72个。在MNIST网站上可以找到的世界纪录约为99.7%。我们距离我们的模型建立了100行Python / TensorFlow距离世界纪录就差0.4个百分点。
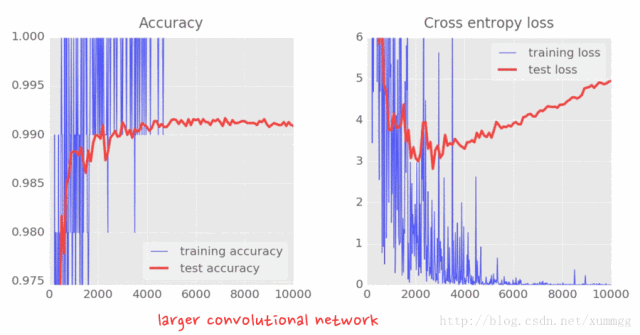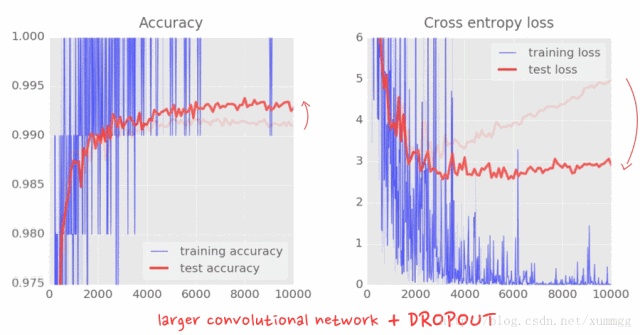
要完成,这是对我们更大的卷积网络的差异。给神经网络增加自由度,将最终准确度从98.9%提高到99.1%。增加dropout不仅驯服了测试损失,而且使我们能够安全地航行99%以上,甚至达到99.3%
14. 恭喜!
您已经建立了您的第一个神经网络,并一直训练到99%的准确性。沿途学到的技术并不特定于MNIST数据集,实际上它们在使用神经网络时被广泛使用。作为一个分手的礼物,这里是实验室的“悬崖笔记”卡,卡通版本。你可以用它回忆起你学到的东西:

下一步
在完全连接和卷积网络之后,您应该看看循环神经网络。
在本教程中,您已经学习了如何在矩阵级构建Tensorflow模型。Tensorflow具有更高级的API,也称为tf.learn。
via http://blog.csdn.net/xummgg/article/details/69214366
人工智能大数据与深度学习
搜索添加微信公众号:weic2c

长按图片,识别二维码,点关注
大数据挖掘DT数据分析
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注






