
本文分享的论文是《COLD: Towards the Next Generation of Pre-Ranking System》
论文下载地址为:https://arxiv.org/abs/2007.16122
1、背景
大多数的推荐系统都遵从一种多阶段的级联结构,最为我们所熟知的就是YoutubeDNN论文中所提出的Match + Rank的两阶段结构,但在阿里的场景下,又增加了Pre-Ranking和ReRanking阶段,如下图所示:
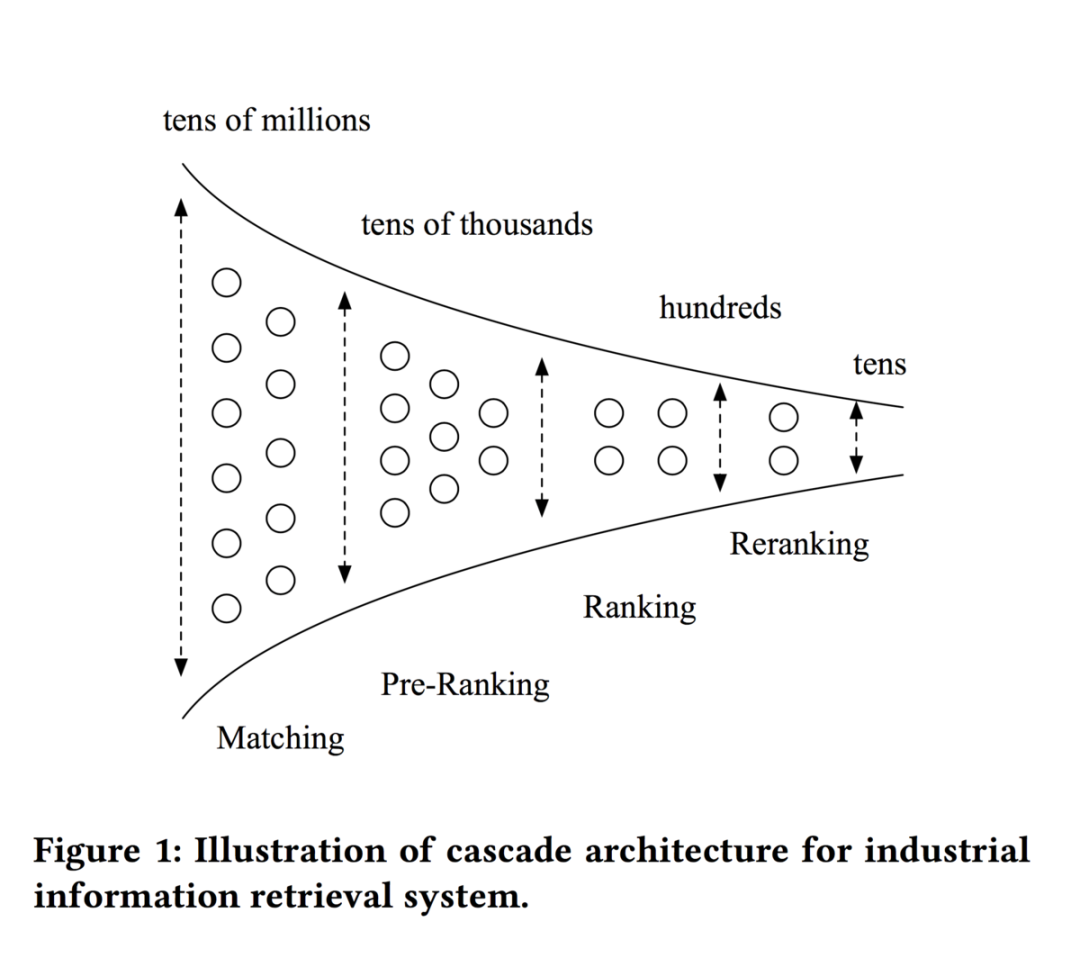
Reranking还是比较常见的阶段,比如加入一些策略打散提升推荐的多样性等。而Pre-Ranking确实是比较少见的。其模型大小/精度介于Matching和Ranking之间。不过我感觉不需要太过纠结于是哪个阶段,或者当作Matching阶段,主要学习的论文的思路就好。
Pre-Ranking阶段可以看作是Ranking阶段的简化版,其预估的候选集数量往往限制在千级别,耗时被限制在10-20毫秒。因此Pre-Ranking阶段的模型也需要轻量化模型来满足耗时的要求。
接下来,本文首先回顾一下Pre-Ranking系统的发展,以及面临的挑战,再介绍本文提出的计算成本感知的轻量级预排序系统COLD(Computing power cost-aware Online and Lightweight Deep pre-ranking system)。
2、预排序系统回顾
在介绍COLD之前,论文简单介绍了前三代的预排序系统,如下图所示:
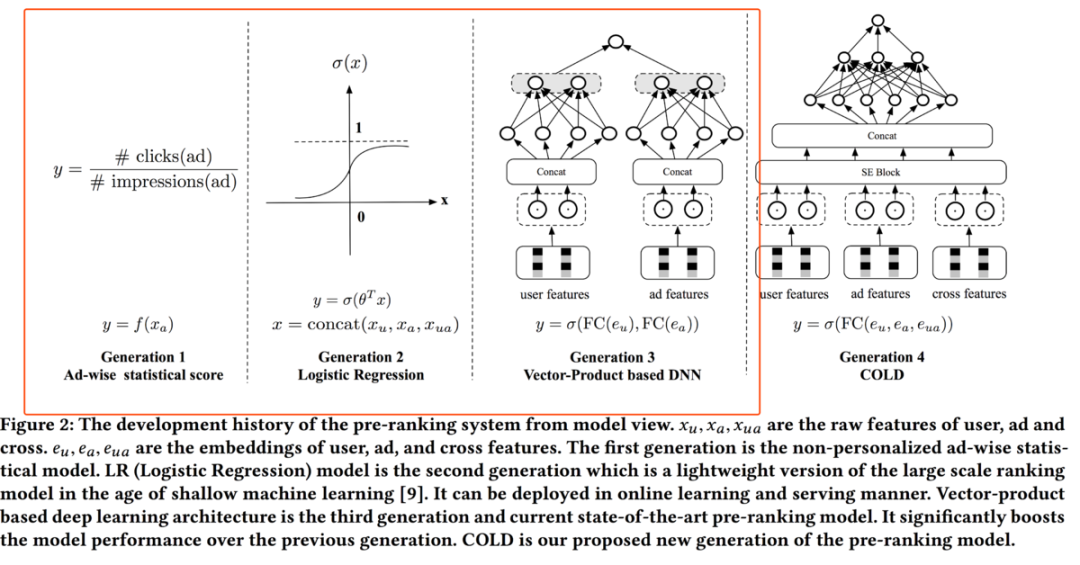
第一代系统使用的是非用户个性化的广告粒度的统计特征,如统计每个广告最近一段时间的点击率,点击率统计值可以被快速的更新,同时计算速度非常快。
第二代系统使用的是逻辑回归模型,是大规模排序系统的一个简化版本。LR模型能够进行快速的并行计算,同时能够做到实时更新。
第三代系统使用的是基于向量内积的模型,其模型结构可以分为独立的两部分,即用户侧和广告侧。用户相关特征输入到左边的部分,输出用户向量,广告相关特征输入到右边的部分,输出广告向量,随后二者通过进行内积计算,有时再经过sigmoid转换为0-1之间的值,作为排序分返回。基于向量内积的模型也是当前预排序系统主流的计算方式。
基于向量内积的模型通常对模型进行天级别更新,同时离线计算好用户和广告向量,存储在线上存储引擎(如Tair)中,当线上请求发生时,直接读取对应的用户和广告向量进行内积计算即可。其离线和线上服务框架如下图所示:
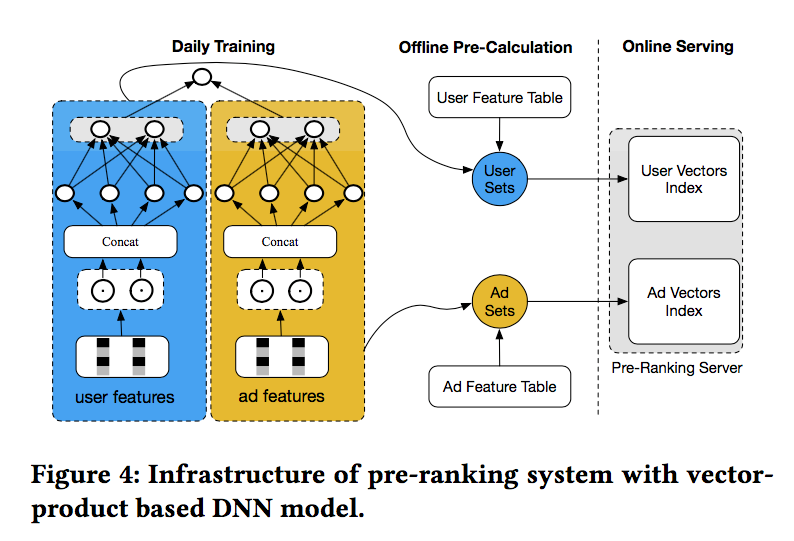
但基于向量内积的模型存在以下几方面的缺点:
1)模型的表达能力受限于向量内积的形式,不能融入用户-广告的交叉特征。
2)用户和广告的向量需要离线计算好,这通常需要几个小时,这导致用户/广告向量表示很难适应数据分布的偏移,无法做到实时更新。
下图展示了几代预训练系统中模型的的表达能力和更新频率之间的关系:
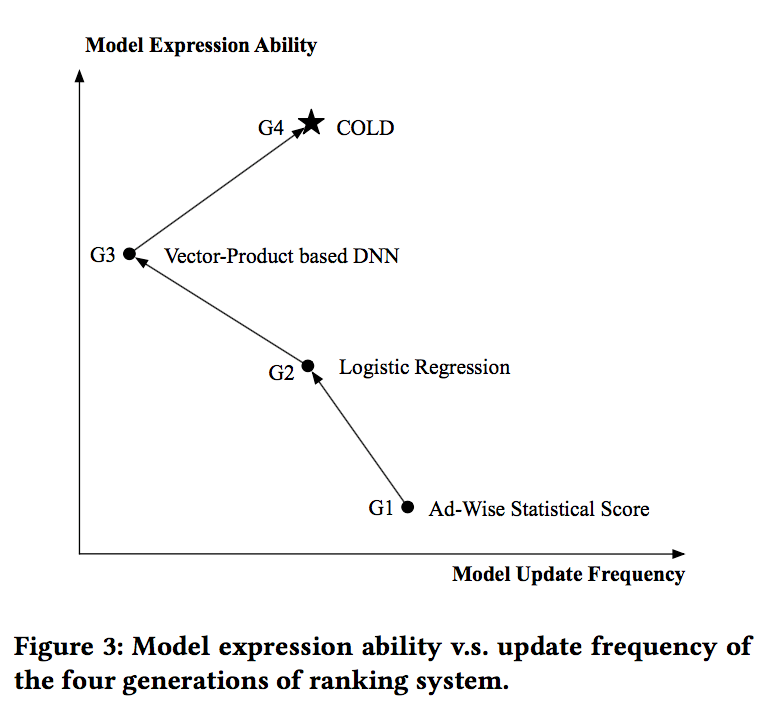
而本文将要介绍的COLD,相较于基于向量内积的模型,不仅在表达能力上有了一定的提升,同时在模型更新频率上,能够达到和LR相同的水平。
3、COLD介绍
在COLD中,使用深度神经网络来进行预测,如下图所示:

使用如上图所示的模型结构,其计算耗时必定会有所提升,那么如何对耗时进行控制呢?主要包括两方面:设计灵活的网络结构和使用工程优化方法加速模型的预测性能。
3.1 设计灵活的网络结构
如何获得轻量级的深度模型呢?常用的方法如网络剪枝、模型蒸馏、特征筛选、神经架构搜索(Neural Architecture Search)等。论文中选择的是特征筛选的方法,来平衡模型预测精度和预测耗时。
具体的,在Embeding层加入SE (Squeeze-and-Excitation) block 来进行特征筛选,关于SE block可以参考论文《Squeeze-and-Excitation Networks》(https://arxiv.org/abs/1709.01507),假设ei为第i个特征对应的embedding,则该特征的重要性计算公式如下:
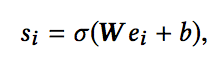
其中W和b都是可学习的参数。基于特征重要性,可以选择K个最重要的特征,输入到后续的多层神经网络中。
关于K的选择,是平衡了模型预测精度和预测耗时的结果。评估指标包括AUC、GAUC、QPS(Queries Per Seconds,每秒处理的请求数)、RT(return time)等
3.2 工程优化
接下来简单介绍一下论文中提及的工程优化方法。
1)全层次并行(Parallelism at AllLevel):并行化对于减少计算耗时是十分重要的,如对于用户的一次请求,会进行分解(拆包),比如一次请求要预估1000个广告,可以拆解成5个包,每个包包含200个广告,包之间进行并行计算。
2)基于列的特征计算(Column based Computation):用户和广告的交叉特征需要实时计算,过去的做法通常是逐条的进行计算,即row based method,而论文采用的方法是Column based method,提升了计算效率。下图是二者的对比:

3)减小参数低精度(Low precision GPU calculation):在NVIDIA的T4 GPU上进行矩阵计算,FLOAT16类型的数据计算耗时要比FLOAT32类型的计算耗时小8倍以上,但是FLOAT16会损失一定的模型精度,同时对于一些特征来说,部分特征的大小超过了FLOAT16类型的表示范围。因此,论文提出了一种精度混合的方法。对于在FLOAT16类型的表示范围内的特征,使用FLOAT16精度,对于其他特征,一种是通过BN层这种有参数的方式来减小特征的范围,一种是linear_log(x)的无参数方法。linear_log(x)的计算如下:
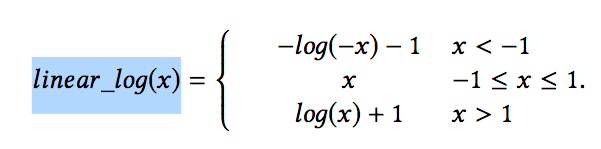
4、实验分析
好了,介绍完COLD,再简单看下实验结果,文章对比了COLD和基于向量内积的模型以及DIEN的效果,结果如下:

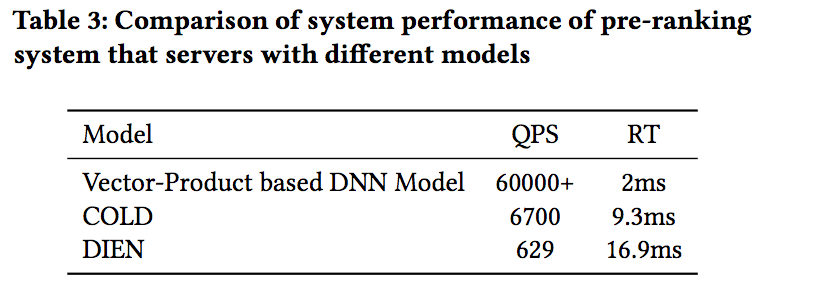
从离线精度指标来看,COLD的效果优于基于向量内积的模型,但差于DIEN,毕竟模型复杂度相较DIEN较差。从耗时来看,基于向量内积的模型性能最优,COLD性能稍差,但仍远好于DIEN模型。
好了,本文就介绍到这里了,介绍了不少模型轻量化的经验,在模型越来越复杂,同时对于耗时要求越来越高的情况下,这些经验都是十分宝贵的,感兴趣的同学可以阅读原文加以吸收!








