
当处理连续数值型数据时,将其分箱 (binarize) 成几个组对之后的数据分析是很有用的。本贴介绍的 qcut 就能做到这件事情。首先引入要用到的工具包:import pandas as pdimport numpy as npimport seaborn as snssns.set_style('whitegrid')
本贴中,我们使用的是 2018 年的销售数据。接下来用 info(), head(), tail() 几个函数来看看数据集的大小、行标签和列标签。raw_df = pd.read_excel('sales.xlsx')raw_df.info()
raw_df.head(3).append(raw_df.tail(3))
将其按 account number 和 name 分组,并对 ext price 加总得到:
df = raw_df.groupby(['account number', 'name'])['ext price'].sum().reset_index()df.inf()
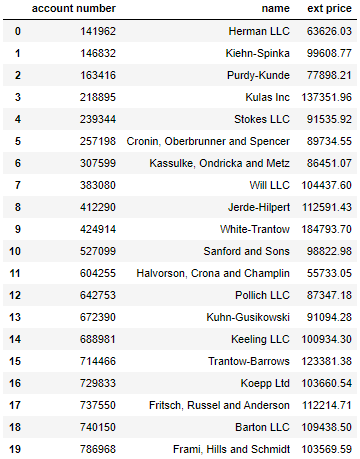
df['ext price'].plot(kind='hist');
从上图来看有 8 个桶 (buckets),即 20 个数组被分成了 8 组,接下来我们用 qcut 函数来重新等分组。
qcut
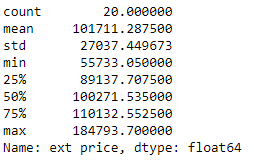
该函数名字里的 q 是 Quantile 的意思,顾名思义是按照分位数来分组的。看到分位数第一反应就是用 describe() 函数来显示出其值 (25%, 50%, 75% 对应的值)。
df['ext price'].describe()
最简单使用 qcut 的方法就是设置 q 值,下例用 4,就是将 ext price 列下的值分为 4 组,使得每组中的数据个数相等或相近。
pd.qcut(df['ext price'], q=4)
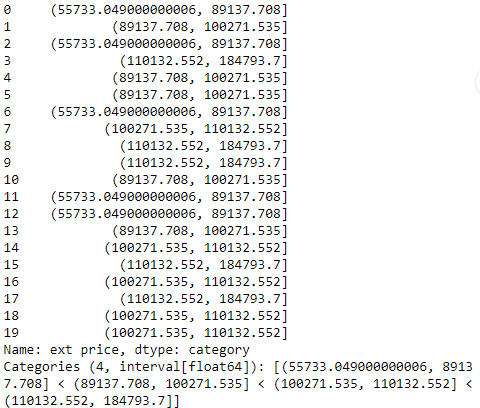
从上面结果可知,每一个 ext price 都被赋予一个 category 的区间,而总共有 4 个区间,因为我们设置 q = 4。
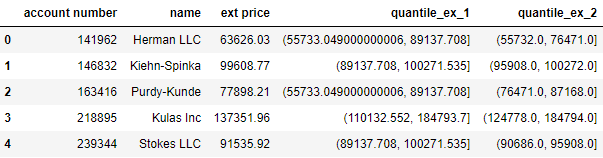
下面将 ext price 列下的值分别分为 4 组和 10 组,并在 10 组展示区间值时设置 precision = 0,只显示小数点后一位。
df['quantile_ex_1'] = pd.qcut(df['ext price'], q=4)df['quantile_ex_2'] = pd.qcut(df['ext price'], q=10, precision=0)df.head()
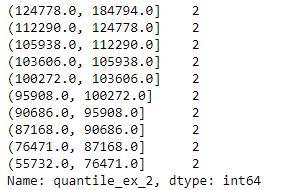
用 value_counts() 可看出分四组时每组有 5 个数据,分十组时每组有 2 个数据,的确把含 20 个数据的 df 等量分组了。
df['quantile_ex_1'].value_counts()

df['quantile_ex_2'].value_counts()
上面这种区间时的 category 对使用者不是很友好,这时可设置 labels 参数以赋予具体含义,比如用下面的“铜-银-金-铂金-钻石”这样的类别,代码如下:
bin_labels_5 = ['Bronze', 'Silver', 'Gold', 'Platinum', 'Diamond']df['quantile_ex_3'] = pd.qcut(df['ext price'], q=[0, .2, .4, .6, .8, 1], labels=bin_labels_5)df.head()
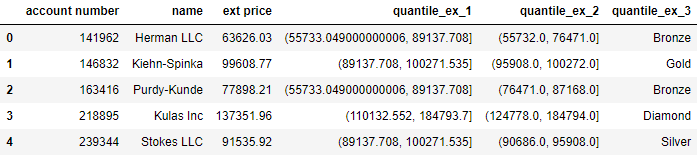
df['quantile_ex_3'].value_counts()

那可能又有人说了,如果想知道这些类别对应的数值分类区间呢?将 retbins 设置为 True 就行了。此外下面 q = [0, 0.2, 0.4, 0.6, 0.8, 1] 写法和 q = 5 是等价的,因为六个点分五份。
results, bin_edges = pd.qcut(df['ext price'], q=[0, .2, .4, .6, .8, 1], labels=bin_labels_5, retbins=True)
results_table = pd.DataFrame(zip(bin_edges, bin_labels_5), columns=['Threshold', 'Tier'])results_table
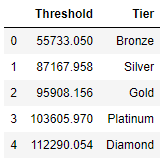
在机器学习中,最终还是需要将字符串格式的类别型变量转换成数值格式的连续型变量
,这时将 labels 设置为 False 即可。
df['quantile_ex_4'] = pd.qcut(df['ext price'], q=[0, .2, .4, .6, .8, 1], labels=False)df.head()

你学会用 qcut 了吗?
Stay Tuned!








