
作者:Jason Brownlee
翻译:李嘉骐
校对:王晓颖
本文约4300字,建议阅读9分钟
本文介绍了机器学习中常用的数据准备技术。
标签:初学者 机器学习 数据准备 特征工程
机器学习项目中的预测性建模总是涉及某种形式的数据准备工作,如分类和回归。数据集所需的特定数据准备工作取决于数据的具体情况,比如变量类型,以及数据建模算法对数据的期望或要求。然而,有一组标准的数据准备算法可以应用于结构化数据(例如电子表格)。这些数据准备算法可以按类型归入到一个框架中,这个框架有助于比较和选择特定项目所用的技术。在本教程中,你将发现在预测性建模的机器学习任务中有一些常见的数据准备任务。在我的新书(https://machinelearningmastery.com/data-preparation-for-machine-learning/)中有30个分步教程和完整的Python源代码,你可以更深入的探索数据清洗、特性选择、数据转换、降维等内容。我们可以将数据准备定义为将原始数据转换为更适合建模的形式。然而,在预测性建模中的数据准备步骤前后还有一些重要的步骤,它们能够提示将要执行哪些数据准备工作。我们可以在任何给定项目的步骤之间来回跳转,但所有项目都有相同的一般性步骤;它们是:
我们关注的是数据准备步骤(步骤二),在机器学习项目的数据准备步骤中,你可以使用或探索一些常见或标准的任务。数据准备工作的类型取决于你所使用的数据,这可能和你所预料的一样。然而,当你处理多个预测性建模项目时,你会反复看到并用到相同类型的数据准备任务。数据清洗:识别和纠正数据中的错误。
特征选择:找出与任务最相关的输入变量。
数据转换:改变变量的尺度或分布。
特征工程:从可用数据中推导新变量。
降维:创建缩减数据维数的映射。
以上提供了一个粗略的框架,在使用结构化或表格数据的给定的项目中,我们可以利用这一框架来思考和引导不同的数据准备算法。数据清洗(https://machinelearningmastery.com/basic-data-cleaning-for-machine-learning/)包括修复“杂乱无章”的数据中的系统性问题或错误。最有用的数据清洗需要领域内的专业知识,涉及到识别和处理可能不正确的观察结果。有许多原因导致数据可能不正确,例如错误输入、损坏、重复等等。某一领域的专业知识可以帮助发现那些与预期的不同的明显错误,比如一个人身高200英尺。一旦发现杂乱、有噪声、损坏或错误的观测结果,就可以加以解决。这可能涉及删除行或列,或者用新值替换观测值。使用统计数据定义正常数据并识别异常值。
找出具有相同值或无差异的列并将其删除。
找出重复的数据行并将其删除。
将空值标记为缺失。
使用统计数据或学习模型估算缺失值。
数据清洗通常是在其他数据准备操作之前首先执行的操作。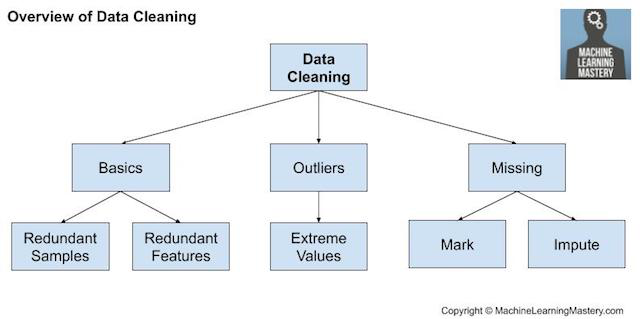
https://machinelearningmastery.com/basic-data-cleaning-for-machine-learning/特征选择是指选择与所预测的目标变量最相关的输入特征子集的技术。特征选择很重要,因为无关和冗余的输入变量会分散或误导学习算法,可能导致预测性能下降。此外,我们希望只使用预测所需的数据来开发模型,例如,去适应能够取得尽可能简单的性能良好的模型。特征选择技术通常分为使用目标变量(有监督)和不使用目标变量(无监督)两类。此外,有监督的技术可以进一步分为下面几种类型:模型拟合过程中自动选择特征(本身的),选择能使模型获得最佳性能的特征(封装器)和对每个输入特征评分并选择输出特征的子集(过滤器)。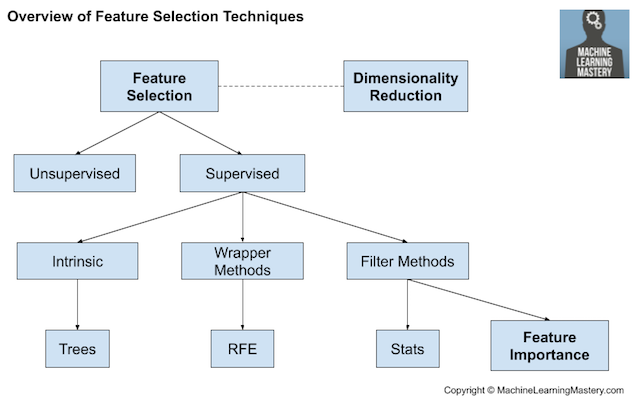
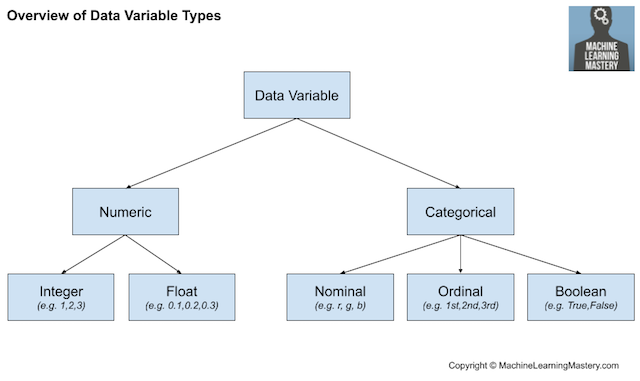
统计方法(比如相关性)常用于给输入特征评分。输入特征根据它们的得分进行排序,并选择最大评分对应的特征子集作为模型输入。统计指标的选择取决于输入变量的数据类型,也可以参考一些对于不同统计指标评估的综述。有关如何基于数据类型选取特征选择方法的概述,请参见教程:此外,在预测性建模项目中,我们可能会遇到不同的常见特征选择案例,例如:当输入变量数据类型混合出现时,可以使用不同的过滤方法。也可以使用适用于输入变量类型未知的包装器方法(如常用的RFE方法)。输入特征的相对重要性评分称为特征重要性。许多基于模型的技术使用模型输来辅助解释模型、解释数据集或选择用于建模的特征。https://machinelearningmastery.com/calculate-feature-importance-with-python/数据转换是不同技术的大集合,它们可能同样易于应用到输入和输出变量上。回想一下,数据可能是下面几种类型中的一种,比如数值型(numeric)或分类型(categorical),每种类型都有子类型,比如整数型(integer)和实数型(real-valued)属于数值型(numeric)数据,名义型(nominal)、序数型(ordinal)和布尔型(boolean)属于分类型(categorical)数据。
整数型:整数,不带小数部分。
实数型:浮点值。
序数型:具有排序的标签。
名义型:没有排序的标签。
布尔型:真(True)或假(False)。
我们可能希望在离散化过程中将数值变量转换为序数变量。或者,我们可以将分类变量编码为整数或布尔变量,这在大多数分类任务中都是必需的。离散化转换:将数值变量编码为序数变量。
序数变换:将分类变量编码为整数变量。
独热码转换:将分类变量编码为二进制变量。
对于实数型数值变量,它们在计算机中的表示方式https://en.wikipedia.org/wiki/Single-precision_floating-point_format意味着在0-1范围内比在更大范围内具有更高的分辨率。因此,可能需要将变量缩放到这个范围,称为规范化(normalization)。如果数据具有高斯概率分布,则将数据转换为平均值为零且标准差为1的标准高斯分布可能更有用。规范化转换:将变量缩放到0到1的范围。
标准化转换:将变量缩放为标准高斯分布。
例如,如果分布接近高斯分布,但是有偏的或移位的,则可以使用幂变换使其更接近高斯分布。另外,可以使用分位数变换来强制数据服从一个概率分布,比如使一个具有不常见分布的变量服从均匀分布或高斯分布。人们通常对每个变量分别做数据转换,因此,我们可能需要对不同的变量类型执行不同的数据转换。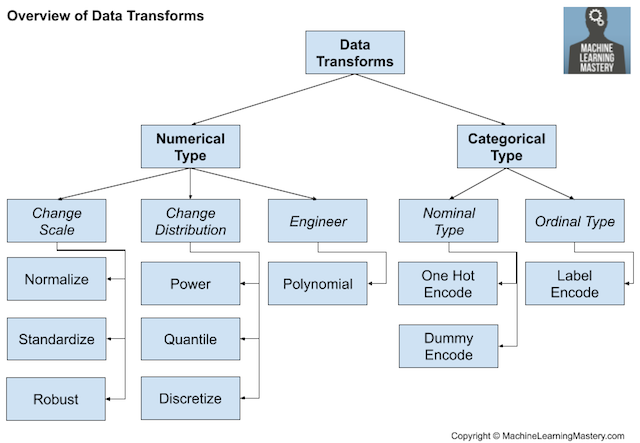
我们将来可能还希望对新数据进行转换。这可以通过将变换对象与基于所有可用数据训练的最终模型一起保存到文件中来实现。创建新特征高度依赖于数据和数据类型。因此通常需要领域内专家的协作,以帮助确定可以从数据中构建的新特征。这一特性使得将特征工程推广到一般方法是一个具有挑战的问题。从统计学中提取特征的一种常用方法是创建输入数字变量的副本并进行简单的数学运算,例如将求幂运算或与其他输入变量相乘,称为多项式特征。特征工程的主题是为单个观察添加更广泛的内容或分解一个复杂的变量,两者都是为了对输入数据提供一个更直接的观察视角。我喜欢把特征工程看作是一种数据转换,尽管把数据转换看作是一种特征工程同样合理。例如,两个输入变量可以定义一个二维区域,其中每行数据定义该空间中的一个点。这个想法可以扩展到任意数量的输入变量来创建大型多维空间。问题是这个空间的维数越大(例如,输入变量越多),数据集就越有可能稀疏,成为该空间的不具代表性的采样。这被称为维度诅咒。这种情况促进了特征选择的使用,然而另一种替代方案是创建数据到低维空间的投影,该投影仍然保留了原始数据最重要的属性。https://machinelearningmastery.com/dimensionality-reduction-for-machine-learning/它提供了一种替代特征选择的方法。与特征选择不同,投影数据中的变量与原始输入变量没有直接关系,这使得投影难以解释。这些技术的主要作用是它们消除了输入变量之间的线性依赖关系,例如相关变量。其他方法也可以实现降维,我们可以将其称为基于模型的方法,例如LDA和自动编码器。
有时也可以使用流形学习算法,如Kohonen自组织映射和t-SNE。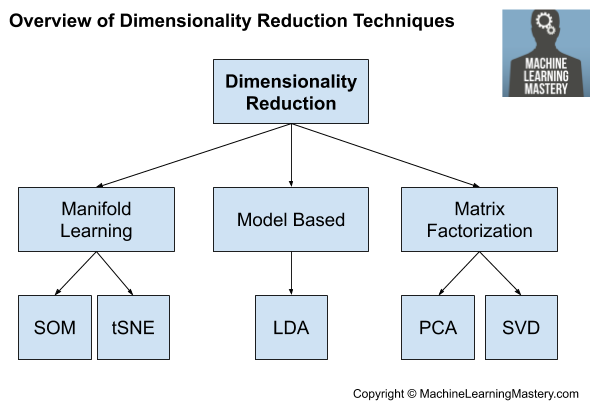
机器学习的降维介绍
https://machinelearningmastery.com/dimensionality-reduction-for-machine-learning/
如果你想深入了解数据准备,本节将提供更多相关资源。https://machinelearningmastery.com/how-to-prepare-data-for-machine-learning/https://machinelearningmastery.com/process-for-working-through-machine-learning-problems/https://machinelearningmastery.com/basic-data-cleaning-for-machine-learning/https://machinelearningmastery.com/feature-selection-with-real-and-categorical-data/https://machinelearningmastery.com/dimensionality-reduction-for-machine-learning/https://www.amazon.com/Feature-Engineering-Selection-Practical-Predictive-ebook/dp/B07VMP371H/ref=as_li_ss_tl?dchild=1&keywords=Feature+Engineering+and+Selection&qid=1587500100&s=books&sr=1-1&linkCode=sl1&tag=inspiredalgor-20&linkId=9175af861ca8c628251ac3b8818b740a&language=en_US
https://bit.ly/2VMhnat?cc=a928849b852590b3ab8fd8421dcfbc9d数据挖掘:实用机器学习工具和技术,第4版,2016年https://www.amazon.com/Data-Mining-Practical-Techniques-Management-ebook/dp/B01MG31RL3/ref=as_li_ss_tl?dchild=1&keywords=Data+Mining+-+Practical+Machine+Learning+Tools+and+Techniques&qid=1587500149&s=books&sr=1-1&linkCode=sl1&tag=inspiredalgor-20&linkId=e30319d53eeab541dbe12c798733766a&language=en_US
https://en.wikipedia.org/wiki/Data_preparationhttps://en.wikipedia.org/wiki/Data_cleansinghttps://en.wikipedia.org/wiki/Data_pre-processing在本教程中,你了解了在预测性建模机器学习任务中常见的数据准备任务。Tour of Data Preparation Techniques for Machine Learninghttps://machinelearningmastery.com/data-preparation-techniques-for-machine-learning/王晓颖( Shirley),UIUC毕业,目前在Coursera上自学Python课程,对AI,Python,数据分析以及Matplotlib等等都很感兴趣,希望能够认识更多厉害的人,保持学习的能力,接触新鲜的事物并从中学习,成为更好的自己。
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”拥抱组织






