
今天来介绍一篇谷歌工业应用文章,论文详细介绍了提升谷歌网盘推荐质量的工业经验,非常值得学习!
1、背景
本文介绍的是Google Drive中的Quick Access场景,该场景主要从庞大的网盘数据库中为用户推荐最可能想要获得的文件,其主页如下图所示:
Quick Access的主要推荐架构如下图所示:
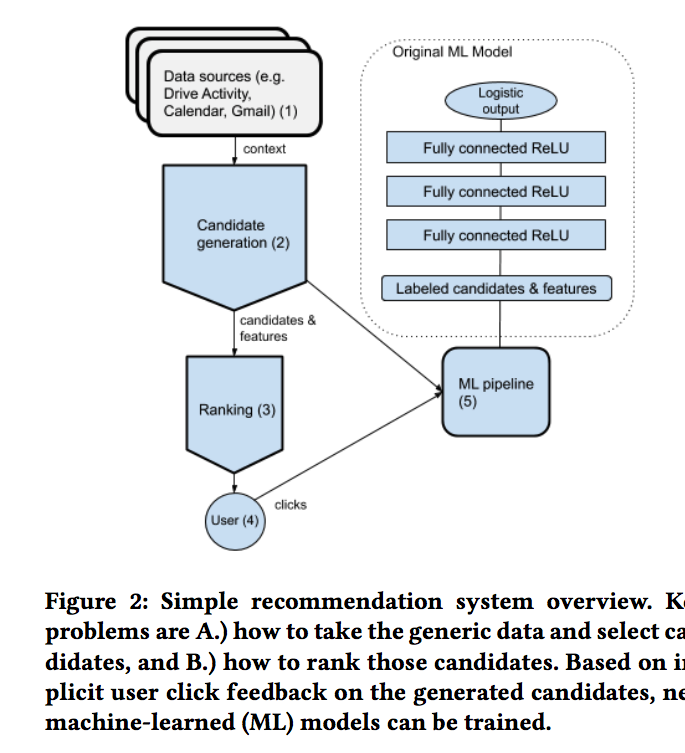
主要的推荐流程包括以下几步:
1)当一个用户来到谷歌网盘,开始收集对应的上下文信息,如用户过去几周在网盘上的行为、哪些文件被作为了Gmail邮件的附件、哪些文件被用户作为了会议日程的附件等
2)上一步收集的上下文信息转换为对应的上下文特征、候选集合以及候选集合中每个文件的特征,用于后续的排序阶段
3)机器学习模型对候选集合进行排序,并通过一些业务逻辑对排序结果进行完善,比如会对部分物品增加推荐理由,如这个文件是昨天你编辑过的,这些推荐理由同样会展示给用户
4)推荐结果展示给用户,此次交互会随着用户点击了网盘中任意一个文件而结束(不一定是Quick Access的推荐结果)。用户的点击数据会随实时数据流进行记录
5)基于用户的实时反馈,对机器学习模型进行更新和替换
以上就是对Quick Access的简单介绍,接下来介绍下提升推荐质量的一些工业经验。
2、工业经验
提升推荐质量主要从以下几方面展开:
1)改善召回候选集
2)改进深度学习模型的结构,不再使用简单的多层神经网络和Relu激活函数
3)提升模型的表达能力,比如,考虑位置偏置信息以及对训练数据进行清洗
4)特征工程
5)线上服务优化
2.1 召回阶段优化
最初召回阶段召回的候选集包括用户60天内有过动作的文件。为了减小召回阶段的召回数量,减少排序阶段的预估耗时,将召回候选集的上限限定在500个,同时仅使用用户近40天内的行为。为进一步减小预估耗时,同时处理部分用户40天内行为稀疏的问题,将召回上限限定在100个,同时使用用户60天内的行为。
经过这样的改进,线上耗时得到了明显的减少。tp50减少了3%,tp90减少了15%,tp99减少了24%。
除用户历史行为外,这里还使用启发式的方式合并入其他的候选集合,也带来了不同程度的线上效果的提升。如添加共享给用户的文件或在注释中提到的文件等等。
2.2 深度网络优化
Quick Access使用的排序模型最初的结构如下:

可以看到,最初的模型结构是简单的多层神经网络,而损失函数采用的是Logloss。在此基础上,通过如下几个方面的改进提升了推荐质量。
1)损失优化:最初使用的是logloss,同时使用AUC作为离线评估指标,但考虑到正负样本比例约为1:99,AUC在正负样本数分布不均匀情况下更加鲁棒 ,因此使用AUC-PR同时作为损失函数和评估指标。关于AUC-PR,可以参考论文《Scalable Learning of Non-Decomposable Objectives》和知乎文章https://zhuanlan.zhihu.com/p/69852955。使用AUC-PR损失函数,离线指标提升0.45%,线上准确率提升1%,点击率提升0.6%
2)Latent cross:Latent cross是应用在Youtube RNN-based推荐系统模型中的技术,可参考论文《Latent Cross: Making Use of Context in Recurrent Recommender Systems》。这种结构通过将部分特征输入到单独的模块中,来更高效的学习特征之间高阶的特征交互,其结构如下图所示:
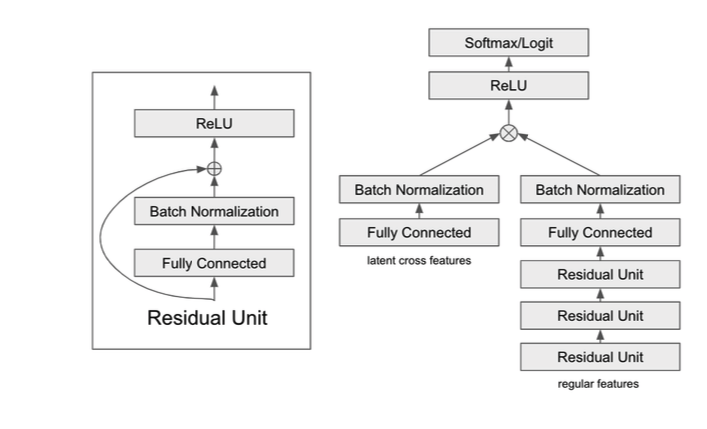
这里,latent cross features中的特征包括用户类型(类型1或者类型2)、平台(移动端或电脑端)和dayofweek。
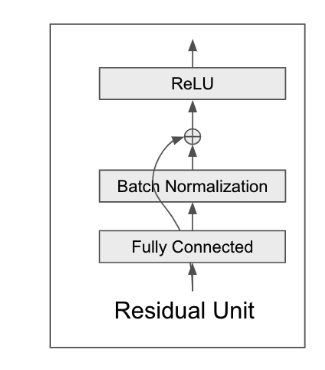
3)ResNet:残差块大家应该比较熟悉,是计算机视觉中非常受欢迎的一种网络结构。如下图所示:
4)Batch Normalization:BN大家也比较熟悉了,采用BN结构后,有效提升了收敛速度和测试集上的表现。值得一提的是,这里并没有加入input layer BN(第一层全连接层之前的BN),这主要是因为输入特征往往维度比较大,使用BN会使得训练时间大幅度提升,训练效率下降,因此在大规模推荐系统,输入特征比较多的时候,推荐去掉input layer BN。
5)Deep & Cross Network:最后一项是采用了DCN的结构,感觉这里不太像DCN的结构,更像是进一步应用了Latent cross,最终的模型结构如下图:

2.3 建模优化
接下来讲几点建模时的优化:
1)负样本采样:对负样本采样并没有带来线上效果的提升,如下图所示,当负样本采样个数从100减少至50%时,准确率下降了1.3%。

2)位置偏置:位置偏置是推荐系统中很常见的一类问题。这里采用论文《Recommending what video to watch next: a multitask ranking system》中处理位置偏置的方法。其结构如下:
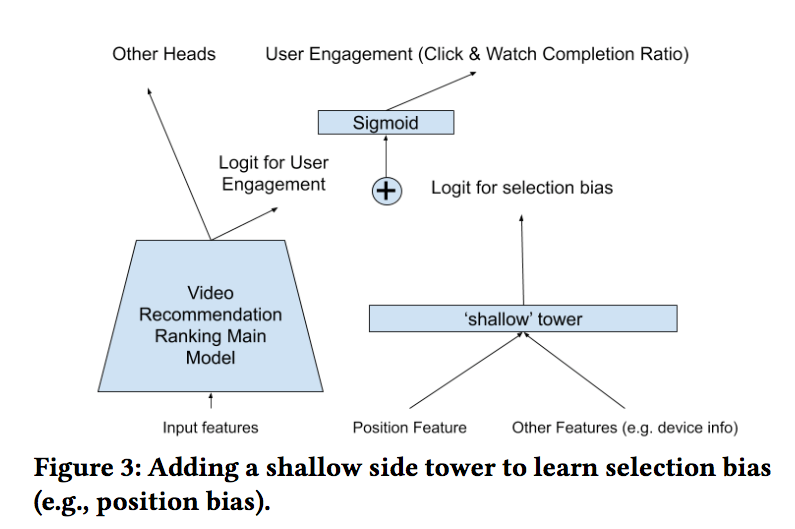
由于训练数据中一半的点击行为并不是来自Quick Access,上述方法也并没有得到很好的收益。
3)Training data integrity(训练数据完整性):这里,主要思考三方面的问题:
首先,当一个文件展示给用户很长时间之后,用户才产生点击行为,这种数据该如何处理?在训练数据中,超过10%的点击发生在用户打开网盘之后的1min以后,有超过5%的点击发生在用户打开网盘之后的5min以后。这些样本被称为“延迟点击”样本,通过实验发现,去除这些“延迟点击”的样本,并没有带来模型效果的提升。
其次,用户在Quick Access之外的点击样本如何处理?这里同样做了对比实验,一份样本包括了Quick Access和网盘其他区域的样本,一份样本只包括Quick Access的样本,并通过采样的方式保证两份样本的数量相同。实验结果表明,如果只使用Quick Access的样本,准确率有0.6%的下降,因此加入网盘其他区域的“探索性”样本,对模型训练是有帮助的,同时能够减轻反馈循环(feedback loop)现象。
最后,什么样的交互行为能够真正反映文档与用户的相关性呢?交互行为在谷歌网盘上大致可以分为两类:用户触发和非用户触发,用户触发包括用户阅读或者编辑文档,非用户触发包括客户端同步行为等等。非用户触发的行为并不能反映用户和文档的相关性,会带来显著的噪声,因此需要对这部分数据进行过滤(过滤规则文章中提到是启发式的规则,但具体没有细说,猜测可能是交互时长阈值),过滤后线上效果有了明显提升。
4)分用户群训练模型:Google Drive的用户群主要有两类,那么在不同类别的用户群上,分别训练单独的模型,能不能带来更好的收益呢?这里使用User Group2的数据进行模型训练,在User Group1的预测上,该模型表现很差,但令人意外的是该模型在User Group2上的表现同样没有提升。对于全量数据训练的模型来说,使用latent cross的方式,对于一条数据,模型是能够区分用户属于Group1还是Group2的,并针对用户所属类别调整其预测结果。而训练单独的模型,则缺少了用户类别这一有用的信号。
2.4 特征工程
这一节主要讲一下提升推荐质量过程中,所提取的一些比较有效果的特征组:
1)协作/上传特征(Collaborator & upload features):该组特征表示一个文档是否被用户最近的协作者所分享,以及最近该文档文档上传时间戳特征。
2)文档元数据特征(File metadata features):该组特征包括用户是否对文档加星,用户是否有文档编辑权限,是否是用户最后修改的文档等等。
3)平台特征(Platform feature):该组特征表示请求的来源,包括网页端,IOS端扽等。
4)外部上下文特征(External Context features):该组特征包括对用户来说重要的联系人、文件和信息。
5)用户特征(User features):该组特征包括用户类别/用户时间特征(hour of day,day of week)/日历特征(用户下一次会议时间以及附件等)。
不同组特征对效果的提升是不同的,如下表所示:
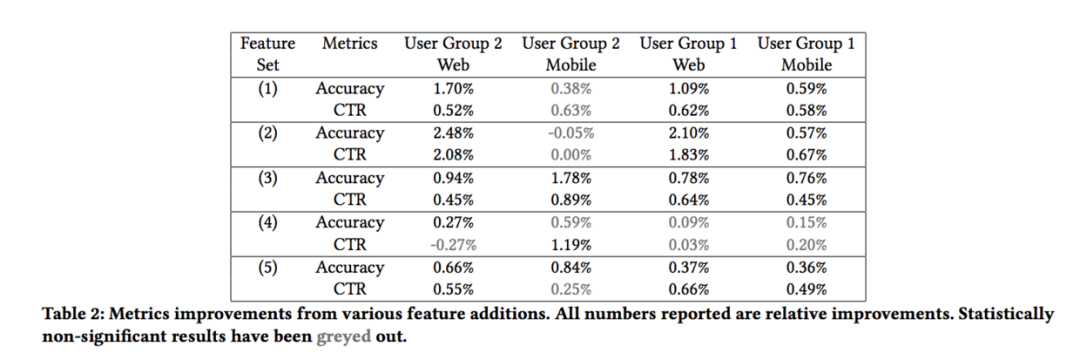
用很多特征从业务角度出发,理论上是能够带来效果提升的,但实际应用中却并非如此,主要可能的原因有以下几个方面:
1)新加入的特征是冗余的
2)对许多候选文件来说,并没有足够的反馈信息,特征是缺失的。
3)特征计算存在问题
2.5 线上服务优化
这一节主要讲为了减少线上耗时所做的一些优化,大致意思是后端计算与前端渲染并行。一些javascript的内容不太了解,所以对这块不再做过多介绍。
3、实验结果
在采用上述众多提升推荐质量的措施后,线上表现有了显著的提升:
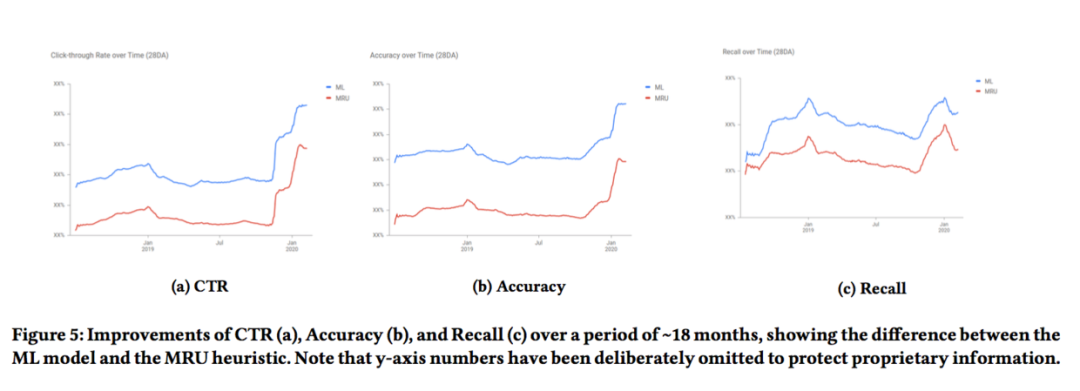
本文介绍了众多在提升谷歌网盘推荐质量上的经验,值得细细品味。感兴趣的同学可以抽空阅读一下原文,相信会有所收获。





