转自:http://shibing.github.io/2016/11/18/nginx%E7%9A%84%E5%BB%B6%E8%BF%9F%E5%85%B3%E9%97%AD-lingering-close/
背景
最近业务方反馈线上 Nginx 经常会打出一些『奇怪』的 access 日志,奇怪之处在于这些日志的 request_time 值总是正好 upstream_response_time 的值大5秒,于是我就帮他们查看了一下导致这个问题的原因,本文记录一下最终调查的结论以及过程。
结论
首先给出产生该问题的原因,这样不愿意看细节的同学看完这段就可以结束阅读了。该问题是由 Nginx 的延迟关闭(lingering close)连接导致的。Nginx 为了能够平滑关闭连接,采用了延迟关闭,它的工作方式如下:Nginx 在给客户端发送完最后一个数据包后会首先关闭 TCP 连接的写端(TCP 是全双工协议,任何一端都即可读也可写),表示服务端不会再向客户端发送任何数据,但是不会立即关闭 TCP 连接的读端,而是等待一个超时,在超时到达后如果客户端还没有数据发来,Nginx 才会关闭TCP的读端,从而关闭整个连接,然后再输出日志。另一方面,Nginx 是在关闭连接后才输出日志,所以在输出日志之前响应早就发送给了用户,因此对业务几乎没有影响。但是这也会导致 requset_time 值变得不准确,使其失去统计意义,开启 Keep-Alive 可以部分解决这一问题。
问题追踪
首先我们先来了解一下 request_time 与 upstream_response_time 这两个值在 Nginx 中是怎么定义的,它们的含义在 Nginx 手册中描述如下:
从上面的定义可以看到, request_time 的值包含了接收用户请求数据、处理请求以及给用户发送响应这三部分的耗时,而 upstream_response_time 只是 Nginx 和上游服务交互的时间,在我们这里就是PHP 处理请求的时间。那么由于网络原因,request_time 大于甚至远大于upstream_response_time 都是很正常的,但是总是大5秒就很奇怪了。
Nginx 配置导致的么?
因为两者总是相差5秒,很容易让人想到可能是Nginx的配置文件中的某个参数导致了该问题,通过查看配置文件确实发现了一个可疑的配置项目:
1
| fastcgi_connect_timeout 5
|
这个配置表示将 Nginx 与 PHP-FPM 之间的连接超时设置为5秒,那么导致该问题的一个可能的原因就是当 Nginx 第一次尝试与 PHP-FPM 建立连接超时了,第二次尝试才连上,这样就会正好多出了一个5秒的连接超时时间。可是进一步查看日志发现,PHP 的请求处理日志早在 Nginx 日志之前5秒就打出来了,而且如果 Nginx 连接 PHP 超时是会输出 error 日志的,但是线上的 error 日志里面并没有连接超时的记录,所以这个原因很快被否决了。
Nagle 算法惹的祸?
既然配置文件中没有显式的配置会导致该问题,那么就有可能是 Nginx 的默认配置导致的,因此我搜索了一下源代码中与5有关的内容,希望能发现一些蛛丝马迹,结果发现了一段如下的注释:
1 2 3 4 5 6 7 8
| Therefore we use the TCP_NOPUSH option (similar to Linux's TCP_CORK) to postpone the sending - it not only sends a header and the first part of the file in one packet, but also sends the file pages in the full packets. But until FreeBSD 4.5 turning TCP_NOPUSH off does not flush a pending data that less than MSS, so that data may be sent with 5 second delay. So we do not use TCP_NOPUSH on FreeBSD prior to 4.5, although it can be used for non-keepalive HTTP connections.
|
上面注释的大概意思是,在较老的 FreeBSD 的操作系统上,就算关闭了 TCP_NOPUSH 参数,如果一个包小于 MSS,依然有可能会被延迟5秒发送。TCP_NOPUSH 参数是用来控制 TCP 的 Nagle 算法的,该算法的具体内容可以查阅网上资料,其核心思想是将多个连续的小包累积成一个大包,然后一次性发送,这可以提升网络的利用率。Nginx 中还有一个配置项也与 Nagle 算法相关,那就是 TCP_NODELAY,它的含义与 TCP_NOPUSH 正好相反,表示关闭 TCP 的 Nagle 化,也就是内核收到数据后不管大小直接发送。这两个配置看似互斥,但是在实际应用中,我们却将它们都打开,因为 Nginx 可以通过配合使用这两个配置来最大效率的利用网络。配合方式如下:首先根据 TCP_NOPUSH开启 Nagle 算法,将数据累积到缓冲区中,当需要发送的数据都累积完成但是还没有达到 MSS 时,立即根据TCP_NODELAY 关闭 Nagel 算法,此时内核会一次性将缓冲区中的数据发出。总结为一句话就是:累积足够量的数据(NOPUSH)然后立即发出(NODELAY)。
我们线上的Linux内核版本是2.6.32,比较老了,所以我们猜想会不会也存在上面所说的这个问题,这时组内其他同学查看 Nginx 配置文件,发现 sendfile,TCP_NOPUSH 以及 TCP_NODELAY 这三个开关都打开了,但是 Keep-Alive 却没有打开,而 Nginx 手册中明确写到只有在开启 sendfile 的情况下 TCP_NOPUSH 才会生效,以及开启 Keep-Alive 的前提下 TCP_NODELAY 才会打开。换句话说,我们线上只开启了 TCP_NOPUSH,却没有开启 TCP_NODELAY,这就有可能导致包的延迟发送。因此我们联系了运维相关的同学,将 Keep-Alive 打开,也就是让 TCP_NODELAY 生效,然后观察日志,发现相差5秒的异常日志真的消失了。这时我们都以为问题的原因找到了。
真的是Nagle算法惹的祸么?
虽然开启 Keep-Alive 使 TCP_NODELAY 生效后,异常日志消失了,但是我心里依然有几个疑问,总觉得这不是导致问题的根本原因:
Nagle 算法是内核层面的,并不是Nginx实施的,也就是说累积包的过程是在内核中完成的,Nginx 只要把包写入到内核缓冲区后就会认为发送数据成功,然后直接记录日志,而不用等待这个累积的过程。
Nagle 算法中累积超时一般设置的是200毫秒,就是说如果200毫秒还没能凑到一个 MSS,也会直接将缓冲区的内容发送出去,与5秒相距甚远。
如果是 TCP_NODELAY 关闭导致的原因,那么在开启 Keep-Alive 然后显式将 TCP_NODELAY 关闭的情况下,也应该会打出奇怪日志,可是我在线下并没能复现这一假设。
真正的原因:socket lingering close
在几个猜想都不对后,觉得还是应该调试一下 Nginx 代码才能发现问题。因为担心直接 gdb 调试可能会导致 Nginx 的性能下降,以至于不能触发可以打出奇怪日志的条件,因此我想到了一个简单的变通方法:只要能获取计算 request_time 之前的所有函数调用栈,那么也就能够大致知道时间花在哪了。根据这个思路我修改了一下 Nginx 源代码,在获取时间的地方有意加了一个对内存的非法访问:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
| ngx_http_log_request_time(ngx_http_request_t *r, u_char *buf, ngx_http_log_op_t *op) { ngx_time_t *tp; ngx_msec_int_t ms; tp = ngx_timeofday(); ms = (ngx_msec_int_t) ((tp->sec - r->start_sec) * 1000 + (tp->msec - r->start_msec)); ms = ngx_max(ms, 0); //如果响应时间是5s,就触发下面的内存访问错误,从而产生一个core。 if (ms == 5000) { *(char *)(0) = 'N'; } return ngx_sprintf(buf, "%T.%03M", (time_t) ms / 1000, ms % 1000); }
|
采用修改后的代码,成功获取了一个 core ,根据 core 得到的调用栈如下:
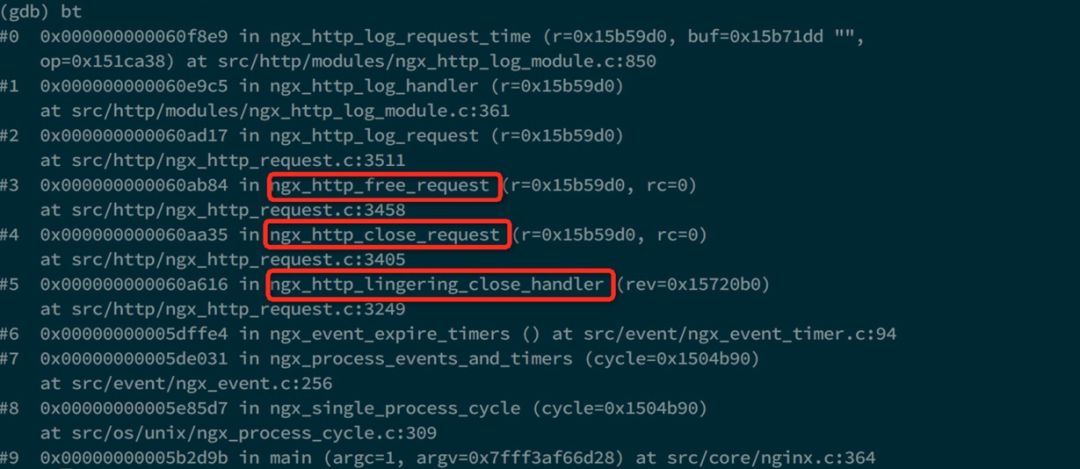
根据调用栈可以看到,在打日志之前,依次调用了三个红色框中的函数,它们都是用来处理连接关闭的。也就是说,在短连接的情况下,Nginx 只有在关闭与客户端的连接后才会开始输出日志,而不是给客户端发送完数据后就打日志。那么这个关闭连接的过程的耗时就很有可能是request_time 比 upstream_response_time 多出来的时间。我们接下来再来具体通过源代码看一下 Nginx 关闭连接的过程,主要的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
| ngx_http_finalize_connection(ngx_http_request_t *r) { if (r->reading_body) { r->keepalive = 0; r->lingering_close = 1; } //如果开启了长连接且长连接未超时,那么走长连接处理相关的代码 if (!ngx_terminate && !ngx_exiting && r->keepalive && clcf->keepalive_timeout > 0) { ngx_http_set_keepalive(r); return; } //不再需要keepalive,即连接需要关闭,并且打开了lingering close,就通过lingering close的方式来关闭连接,也就是延迟关闭 if (clcf->lingering_close == NGX_HTTP_LINGERING_ALWAYS || (clcf->lingering_close == NGX_HTTP_LINGERING_ON && (r->lingering_close || r->header_in->pos < r->header_in->last || r->connection->read->ready))) { ngx_http_set_lingering_close(r); return; } ngx_http_close_request(r, 0); }
|
注意上面并不是 ngx_http_finalize_connection 函数的全部,我只是贴出了与问题相关的代码。可以看到 Nginx 在不需要维护长连接且开启了 lingering close 的时,会调用 ngx_http_set_lingering_close 来设置最终的关闭函数。单词 lingering 是延迟的意思,那么 lingering close 自然是延迟关闭的意思。熟悉 socket 编程的同学应该知道 socket 有一个选项叫 SO_LINGER,如果对一个套接字开启了该选项,那么在调用 close 或者 shutdown 关闭套接字时会一直阻塞到将缓冲区里的消息都发送完毕才能返回。开启该选项的主要作用是为了平滑关闭套接字,使服务具有更好的兼容性,更具体的内容大家可以网上查阅资料。前面说到如果直接在套接字上设置 SO_LINGER 属性,那么在关闭时可能会引起阻塞,可是我们又知道 Nginx 里的套接字都设置了非阻塞属性,这会导致未定义的行为,另外如果完全由操作系统来进行延迟关闭,可能并不能满足 Nginx 的需求,所以 Nginx 没有使用这种方法,而是自己实现了延迟关闭。首先看下 ngx_http_set_lingering_close 函数,它是用来对一个请求设置延迟关闭方法的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39
| ngx_http_set_lingering_close(ngx_http_request_t *r) { ngx_event_t *rev, *wev; ngx_connection_t *c; ngx_http_core_loc_conf_t *clcf; c = r->connection; clcf = ngx_http_get_module_loc_conf(r, ngx_http_core_module); rev = c->read; //获取连接的读事件 //设置读事件触发时的处理函数,也就是延时关闭连接函数 rev->handler = ngx_http_lingering_close_handler; //lingering_time用来控制总的延迟超时时间,比如在第一个lingering_timeout后,收到了数据,那么接下来还会再进行 //延迟关闭,然后再等待lingering_timeout,如此反复,但是总的时间不能超过lingering_time r->lingering_time = ngx_time() + (time_t) (clcf->lingering_time / 1000); //向事件循环中加入超时事件,超时时间是lingering_timeout, //也就是说在lingering_timeout时间后,ngx_http_lingering_close_handler会被调用 ngx_add_timer(rev, clcf->lingering_timeout); if (ngx_handle_read_event(rev, 0) != NGX_OK) { ngx_http_close_request(r, 0); return; } wev = c->write; wev->handler = ngx_http_empty_handler; if (wev->active && (ngx_event_flags & NGX_USE_LEVEL_EVENT)) { if (ngx_del_event(wev, NGX_WRITE_EVENT, 0) != NGX_OK) { ngx_http_close_request(r, 0); return; } } //关闭套接字的写端,也就是说只有读是延迟关闭的 if (ngx_shutdown_socket(c->fd, NGX_WRITE_SHUTDOWN) == -1) { ngx_connection_error(c, ngx_socket_errno, ngx_shutdown_socket_n " failed"); ngx_http_close_request(r, 0); return; } if (rev->ready) { ngx_http_lingering_close_handler(rev); } }
|
ngx_http_set_lingering_close 函数就是用过来设置延迟关闭函数的,关键的部分已经加了注释。可以看到 Nginx 主要通过 lingering_time 和 lingering_timeout 这两个参数来控制延迟关闭的时间,lingering_time 表示总的延迟时间,lingering_timeout 表示单次延迟时间。上面的这段代码会向 Nginx 的事件循环注册一个超时时间,超时的时间间隔是 lingering_timeout ,超时事件的处理函数是 ngx_http_lingering_close_handler,就是说一旦延迟时间到了,该函数就会被调用,它的主要内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56
| ngx_http_lingering_close_handler(ngx_event_t *rev) { ssize_t n; ngx_msec_t timer; ngx_connection_t *c; ngx_http_request_t *r; ngx_http_core_loc_conf_t *clcf; u_char buffer[NGX_HTTP_LINGERING_BUFFER_SIZE]; c = rev->data; r = c->data; ngx_log_debug0(NGX_LOG_DEBUG_HTTP, c->log, 0, "http lingering close handler"); if (rev->timedout) { ngx_http_close_request(r, 0); return; } //计算剩余的全部可用超时时间 timer = (ngx_msec_t) r->lingering_time - (ngx_msec_t) ngx_time(); //总延迟等待时间已经超过lingering_time了,那么不管怎么样都直接关闭连接 if ((ngx_msec_int_t) timer <= 0) { ngx_http_close_request(r, 0); return; } do { n = c->recv(c, buffer, NGX_HTTP_LINGERING_BUFFER_SIZE); ngx_log_debug1(NGX_LOG_DEBUG_HTTP, c->log, 0, "lingering read: %z", n); //延迟时间到了,且套接字发生了错误,或者对方关闭了套接字,那么将整个连接关闭 if (n == NGX_ERROR || n == 0) { ngx_http_close_request(r, 0); return; } } while (rev->ready); if (ngx_handle_read_event(rev, 0) != NGX_OK) { ngx_http_close_request(r, 0); return; } clcf = ngx_http_get_module_loc_conf(r, ngx_http_core_module); timer *= 1000; if (timer > clcf->lingering_timeout) { timer = clcf->lingering_timeout; } //运行到这里,说明超时时间内客户端发来了数据且还有超时时间可用,那么来再次注册延迟关闭事件,开始下一次的延迟关闭等待。 ngx_add_timer(rev, timer); }
|
上面就是当延迟关闭事件超时后 Nginx 的处理过程,首先计算总的延迟超时时间还剩余多少,如果没有了,直接断开连接,这可以防止『等待-接收部分数据-等待-接收部分数据』的无限死循环。接下来 Nginx 尝试读取套接字,如果读出错或者对方关闭了连接或者依然没有数据读到,那么 Nginx 就将连接关闭,否则再次注册延迟超时事件,开始下一次的延迟关闭。根据上面的分析可以看到,在 Nginx 发送完数据包并进入延迟关闭连接流程后,如果客户端在 lingering_timeout 时间内没有进行任何操作,那么就会关闭与客户端的连接然后输出日志,这就会导致导致访问日志滞后 lingering_timeout 才输出。我们线上并没有对该参数进行配置,那么会采用默认值,正好是5秒,与实际情况吻合。另外如果使用长连接,Nignx 在请求结束后不需要关闭连接而直接输出日志,那么就不会有这个问题,这也就解释了为什么开启 Keep-Alive 后问题消失。
复现
知道了问题的原因复现就很简单了,只要在 Nginx 中设置 lingering_timeout 的值,然后观察日志中输出的时间差是不是发生相应的改变即可。比如将该值设置为7,会发现时间差为5的日志就消失了,而都变成了时间差为7的日志:
1 2 3 4 5 6 7
| [shibing@localhost sbin]$ tail -f ../logs/access.log | grep "request_time=7" 172.17.176.138 - - [17/Nov/2016:18:53:15 +0800] "GET /index.php HTTP/1.1" 200 3450 "-" "-" "-" request_time=7.001 upstream_time=0.000 header_time=0.000 172.17.176.138 - - [17/Nov/2016:18:53:15 +0800] "GET /index.php HTTP/1.1" 200 3450 "-" "-" "-" request_time=7.000 upstream_time=0.000 header_time=0.000 172.17.176.138 - - [17/Nov/2016:18:53:15 +0800] "GET /index.php HTTP/1.1" 200 3450 "-" "-" "-" request_time=7.001 upstream_time=0.001 header_time=0.001 172.17.176.138 - - [17/Nov/2016:18:53:15 +0800] "GET /index.php HTTP/1.1" 200 3450 "-" "-" "-" request_time=7.000 upstream_time=0.000 header_time=0.000 172.17.176.138 - - [17/Nov/2016:18:53:15 +0800] "GET /index.php HTTP/1.1" 200 3450 "-" "-" "-" request_time=7.000 upstream_time=0.000 header_time=0.000 172.17.176.138 - - [17/Nov/2016:18:53:15 +0800] "GET /index.php HTTP/1.1" 200 3450 "-" "-" "-" request_time=7.000 upstream_time=0.000 header_time=0.000
|
欢迎加入「运维帮地方群」,现在有北京地方群、上海地方群、深圳地方群、成都地方群、广州地方群、杭州地方群。入群请先加群秘书(长按识别下方二维码),加群秘书时请告知所在城市及公司。群秘书微信,扫描下方二维码。












