
一.思路分析
按照爬虫的基本规律:
1.找到目标
2.抓取目标
3.处理目标内容,获取有用的信息
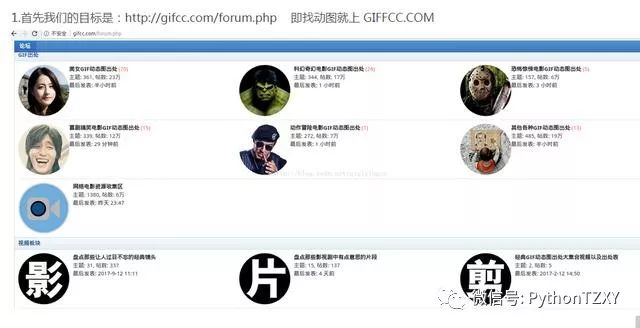
这个网站呢,是一个论坛式网站,里面分了几大类,反正试试各种动图。
我们的目标呢,就是找到这(收)些(藏)动(到)图(自)的(己)地(电)址(脑).

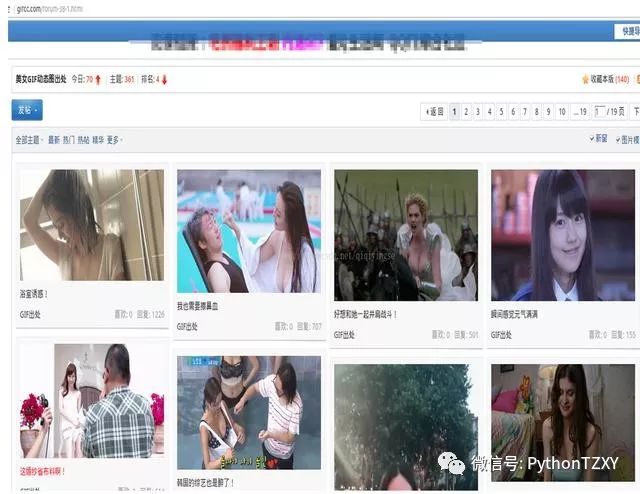

3.每一张动图的所在页面的规律
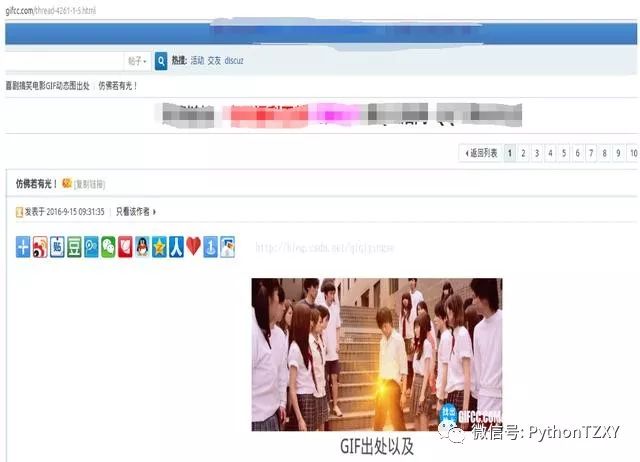
其实这个没啥规律,但是只要我们找到单个图片的地址,就没啥难处理的了.
二 开工动手

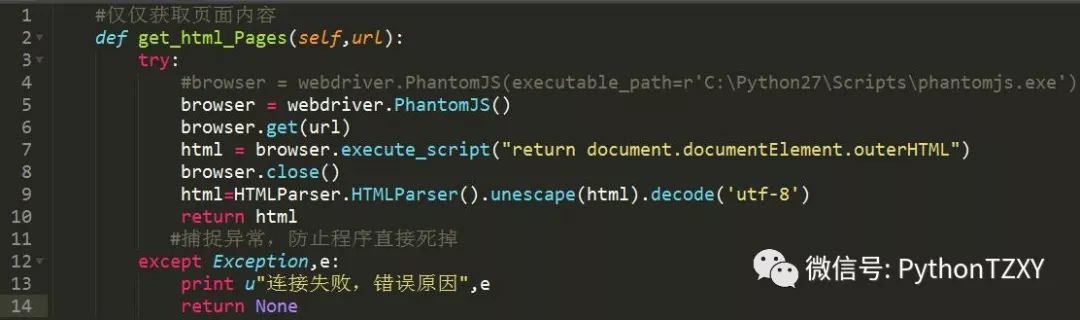
1.获取入口页面内容
即根据传入的URL,获取整个页面的源码

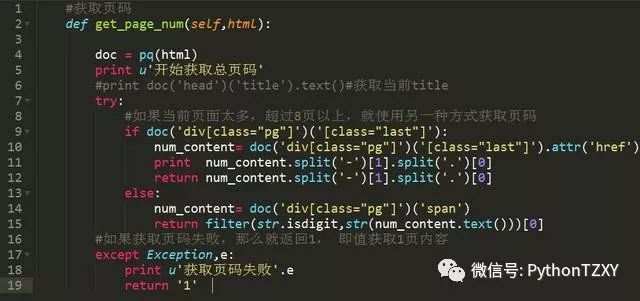

3-6 第三步到第六步一起来说
其实就是根据页码数,来进行遍历,获取到每一页的内容
然后得到每一页中的所有图片地址
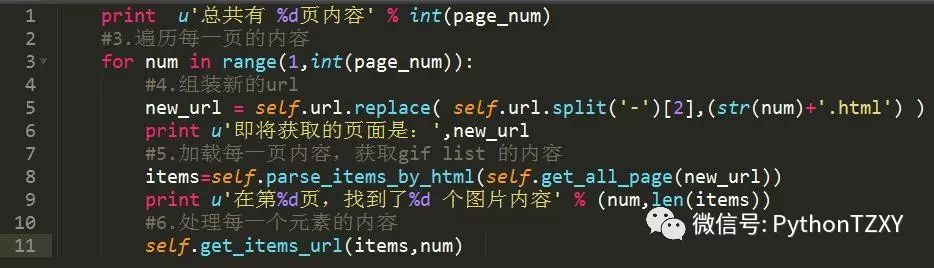
在进行获取每一页的内容的时候,需要重新组装页面地址。

有了新的地址,就可以获取当前页面的内容,并进行数据处理,得到每一张图片的地址列表

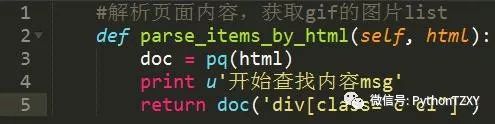
在获取到图片列表后,再次解析,获取每一张图片的URL
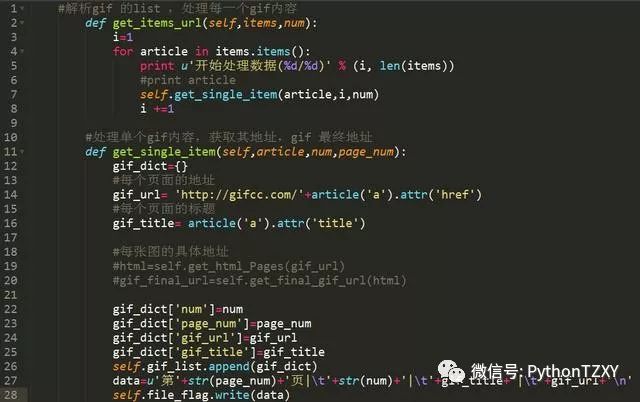
在这里,把数据整合一下,为将数据写入数据库做准备
7.将图片存到本地,以及将数据写入数据库
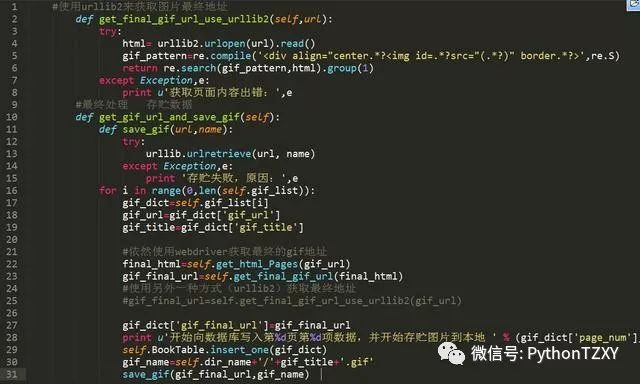

三 数据库的筛选
在完成了将数据放入到数据库的之后, 我想着可以直接通过调用数据库,将图片保存
(为什么有这个想法呢,因为我发现如果直接在主程序中存贮图片,它跑的太慢了,不如将数据都放到数据库中,之后专门调用数据库来贮存图片)
但是这里发现一个问题,数据中的内容挺多的,然后发现了好多内容是重复的,因此我们需要对数据库进行去重
关于数据去重的内容,其实我之前的文章已经写过了(写那篇文章的时候,这个爬虫已经完成了呢~)
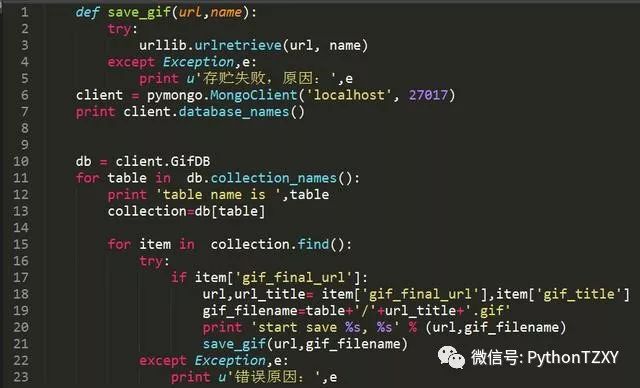
主要思路是针对某一个元素的数量进行操作,pymongo里面有一个方法是可以统计指定元素的数量的,如果当前元素只有一个,就不管,不是一个元素,就删除
核心代码如下:


完整代码
01_get_gif_url.py
02_delete_repeat_url_in_mongodb.py
谢谢阅读!!!










