

图源:pixabay
原文来源:arXiv
作者:Elliot Meyerson、Risto Miikkulainen
「雷克世界」编译:嗯~阿童木呀、KABUDA
一般来说,深度多任务学习(Deep multitask learning)通过在相关任务中共享已学习结构从而提高性能表现。本文将深度多任务学习中的思想调整应用到一个只有单个任务可用的环境中。该方法被形式化为伪任务增强(pseudo-task augmentation),在此过程中,使用每个任务中的多个解码器对模型进行训练。伪任务对来自同一领域紧密相关的任务的训练效果进行模拟。在一组实验中,结果显示,伪任务增强可以提高单任务学习问题的性能表现。当与多任务学习进行结合时,性能就会得到进一步的改进,CelebA数据集上的最先进性能表现也涵盖在内,这些都表明伪任务增强和多任务学习具有互补价值。总而言之,伪任务增强是一种能够提高深度学习系统性能的广泛适用且有效的方法。
多任务学习(MTL)(Caruana于1998年提出)通过利用不同学习问题之间的关系来提高性能。近年来,MTL已扩展到了深度学习领域中,其中,它在诸如视觉、自然语言、语音、强化学习等应用、以及来自不同领域的看似无关的任务中的性能都得以改善。深度多任务学习依赖于来自多个数据集的训练信号,从而用以对跨任务间共享的深层结构进行训练。由于共享结构必须支持解决多个问题,因此它本质上是更为通用的,从而能够进行更好的泛化从而维持数据。
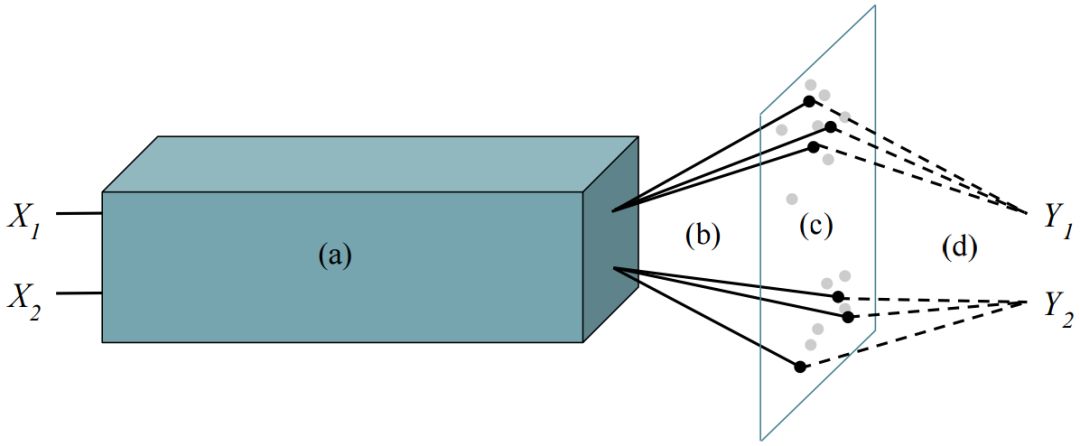
图1:用两个任务进行伪任务增强的一般设置:(a)基础模式,所有任务输入都通过完全共享的基础模型进行嵌入的;(b)多个解码器,每个任务都有多个解码器(实黑线),每个解码器都将嵌入投影到不同的分类层;(c)并行遍历模型空间,与解码器相连接的基础模型定义了任务模型。任务模型填充了模型空间,当前模型显示为黑点,以前的模型显示为灰点;(d)多个损失信号,每个当前任务模型都会收到明显的损失以计算其明显的梯度。一个与解码器相连接的任务以及其参数为基础模型定义了一个伪任务。
本文将深度MTL中的思想调整应用于单任务学习(STL)的情况,即当只有一个任务可用于训练时。该方法被形式化为伪任务增强(PTA),其中,单个任务具有多个不同的解码器,用于将共享结构的输出投影到任务预测中。通过训练共享结构以多种方式解决同一个问题,PTA会对来自同一个领域中不同但紧密相关的任务的训练效果进行模拟。理论证明显示了,具有多个伪任务的训练动态是如何严格地仅使用一个伪任务将训练纳入其中的,并且在实践中引入了一类用于控制伪任务的算法。
经过一系列的实验证明,PTA能够显著提高单任务环境中的性能表现。尽管PTA的多种不同变体能够以各种质量不同的方式遍历假任务的空间,但它们都表现出了显著的性能提升。实验结果还表明,当PTA与MTL相结合时,性能还可以得到进一步的改进,包括CelebA数据集上的的最先进性能表现。换句话说,虽然PTA可以被看作是MTL的一个基本案例,但是PTA和MTL在学习更为通用化的模型方面具有互补的价值。而结论就是伪任务增强是一种有效的、可靠的和具有广泛适用性的能够提高深度学习系统性能的方法。
训练多个深度模型
有多种方法可以利用多个深度模型之间的协同作用。我们可以将这些方法分为三种类型加以描述:(1)对多任务的模型进行联合训练的方法;(2)为单一任务的多个模型进行单独训练的方法;(3)对单一任务的多个模型进行联合训练的方法。可以说,(3)中的方法的发展统一了(1)和(2)的优点。

图4.伪任务轨迹。t-SNE(van der Maaten和Hinton于2008年提出)对IMDB上PTA-I、PTA-F、PTA-HGD运行的伪任务轨迹进行预测。每个形状对应于一个特定的解码器,每个点是在时期结束时长度为-129的权重向量的投影,不透明度会随着时间增长。这一行为符合我们对每种情况下会发生何种事情的直觉:(a)当解码器仅进行独立初始化时,它们的伪任务逐渐收敛。(b)仅有一个解码器被冻结时,未冻结的解码器需在其他解码器之间解决。(c)在使用贪心方法时,解码器在遍历伪任务空间时执行本地搜索。
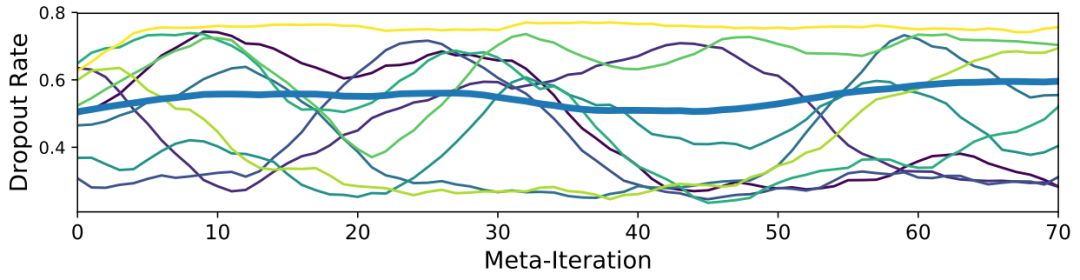
图5.CeleA dropout进度。蓝色的粗线条表示在PTA-HGD运行中,400个伪任务的平均droput进度。其余每一行都显示了一个特定任务进度,共有10个伪任务的平均值。所有线条均由长度为10的单调移动平均值绘制。进度的多样性表明系统正在利用PTAHGD的能力来调整特定任务的超参数进度。
实验表明,PTA具有广泛的适用性,并且可以提高各种单任务和多任务问题的性能。使用多个解码器对单个任务进行训练,便可以访问更广泛的模型。如果这些解码器是多样性的,且性能良好,那么共享结构就可以以多种方式解决相同问题,这是强智能(robust intelligence)的一个特征。在MTL环境中,独立控制每个任务的伪任务可以检测到不同特定任务的学习动态(如图5所示)。增加解码器的数量也可以增加跨任务解码器之间进行匹配的几率。

表1.Omniglot 50-任务结果。显示每个设置的所有任务的平均测试错误。总而言之,MTL的性能补充并提升了PTA的性能,PTA-F再次成为性能最优且最具鲁棒性的方法。
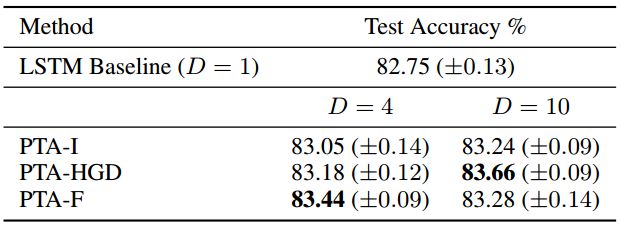
表2.IMDB结果。所有PTA方法都优于LSTM基线。当D=10时,PTA-HGD可以获得最佳性能。随着贪心算法(greedy algorithm)执行更广泛的搜索,该方法将解码器的数量从4个增长至10个,从而使其能力得到了极大提升。另一方面,PTA-F的性能随着解码器数量的增多而降低,这表明过多的冻结解码器可能会过度抑制F。
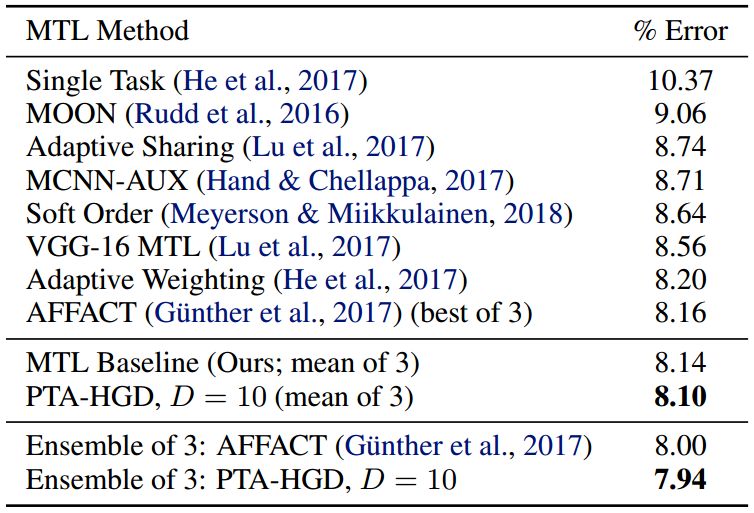
表3.CelebA结果。将PTA与CelebA的现有方法进行比较。测试错误在所有属性中取平均值。PTA-HGD优于其他所有方法,并在这一基础上构建了一个新的先进水平。


控制伪任务轨迹的方法是PTA的核心。实验表明,尽管PTA的性能几乎总是优于基线,但改进的量可以根据控制方法的选择而变化(如图2和图3,表1和表2所示)。不同的方法表现出高度结构化但又存在差异的行为(如图4所示)。初始方法的成功表明,开发更复杂的方法是开展未来研究工作的一个有效途径,特别要强调,可选择上面所提到的三种方法中的第二种:为单一任务的多个模型进行单独训练,以更有效地控制伪任务轨迹。例如:考虑本文中评估的最复杂的方法:PTA-HGD。这种复制解码器权重和执行局部超参数搜索的方法可以被更智能地生成新模型的方法所取代(Bergstra等人于2011年, Snoek等人于 2012年,Miikkulainen等人于2017,Real等人于2017年,Zoph和Le于2017年提出)。这种方法特别适用于将PTA扩展到复杂的非线性解码器中,而不仅仅是本文所讨论的线性情况。最直接的非线性扩展是增加每个解码器的深度。然而,由于一组解码器所进行的是并行训练,因此使用更通用的神经构架搜索方法(Miikkulainen等人于2017年,Real等人于2017年,Zoph和Le于2017年提出)来搜索最佳解码器构架。虽然这些方法会极大地扩展伪任务空间,但伪任务轨迹呈现出高度结构化的行为表明,直接对伪任务空间建模也可以为控制策略提供有用的信息。
最后要说的是,尽管将单独的PTA模型集成在一起是有效果的,但在我们在初步测试中发现,用于评估的朴素集成解码器(等式6)并没有在单一最佳(等式5)情况下产生显著性能改进。这可能是由于最终模型之间存在很高的相关性所致,开发一种用于生成更为互补的解码器的PTA训练方法和集成这组解码器的有效方法,可以使性能得到进一步提升。
本文介绍了一种将深度MTL的思想应用于单任务学习的方法--伪任务增强法。通过训练共享结构以多种方式解决相同任务,伪任务增强模拟了与多个密切相关的任务的训练,从而产生类似于MTL中的性能改进。然而,这些方法是相辅相成的:将伪任务增强与MTL相结合可以进一步提高性能。因此,广泛适用的伪任务增强是提高深度学习性能的一种很有效的方法。总而言之,本文首次提出了一种基于任务内参数共享的高效模型搜索算法,在未来,还将进行进一步探索。
原文链接:https://arxiv.org/pdf/1803.04062.pdf
欢迎个人分享,媒体转载请后台回复「转载」获得授权,微信搜索「raicworld」关注公众号
中国人工智能产业创新联盟于2017年6月21日成立,超260家成员共推AI发展,相关动态:
中新网:中国人工智能产业创新联盟成立
ChinaDaily:China forms 1st AI alliance
工信部网站:中国人工智能产业创新联盟与贵阳市政府、英特尔签署战略合作备忘录
工信部网站:“2018数博会人工智能全球大赛启动暨开放创新平台上线”新闻发布会在京召开
 点击下图加入联盟
点击下图加入联盟

下载中国人工智能产业创新联盟入盟申请表

关注“雷克世界”后不要忘记置顶哟
我们还在搜狐新闻、雷克世界官网、腾讯新闻、网易新闻、一点资讯、天天快报、今日头条、雪球财经……
↓↓↓点击阅读原文查看中国人工智能产业创新联盟手册









