
本文作者认为,深度学习只是一种计算机视觉工具,而不是包治百病的良药,不要因为流行就一味地使用它。传统的计算机视觉技术仍然可以大显身手,了解它们可以为你省去很多的时间和烦恼;并且掌握传统计算机视觉确实可以让你在深度学习方面做得更好。这是因为你可以更好地理解深度学习的内部状况,并可执行预处理步骤改善深度学习结果。
本文的灵感同样来自论坛中的一个常见问题:
深度学习已经取代了传统的计算机视觉吗?
或是换种说法:
既然深度学习看起来如此有效,是否还有必要学习传统的计算机视觉技术?
这个问题很好。深度学习确实给计算机视觉和人工智能领域带来了革命性的突破。许多曾经看似困难的问题,现在机器可以比解决的比人类还好。图像分类就是最好的印证。确实,如从前所述,深度学习有责任将计算机视觉纳入行业版图。
但深度学习仍然只是计算机视觉的一个工具,且显然不是解决所有问题的灵丹妙药。因此,本文会对此进行详细阐述。也就是说,我将说明传统的计算机视觉技术为何仍十分有用,值得我们继续学习并传授下去。
本文分为以下几个部分/论点:
深度学习需要大数据
深度学习有时会做过了头
传统计算机视觉将会提升你的深度学习水平
进入正文之前,我认为有必要详细解释一下什么是「传统计算机视觉」,什么是深度学习,及其革命性。
背景知识
在深度学习出现以前,如果你有一项诸如图像分类的工作,你会进行一步叫做「特征提取」的处理。所谓「特征」就是图像中「有趣的」、描述性的、或是提供信息的小部分。你会应用我在本文中称之为的「传统计算机视觉技术」的组合来寻找这些特征,包括边缘检测、角点检测、对象检测等等。
在使用这些与特征提取和图像分类相关的技术时,会从一类对象(例如:椅子、马等等)的图像中提取出尽可能多的特征,并将其视为这类对象的「定义」(称作「词袋」)。接下来你要在其它图像中搜索这些「定义」。如果在另一个图像中存在着词袋中相当一部分的特征,那么这个图像就被归为包含那个特定对象(如椅子、马等等)的分类。
这种图像分类的特征提取方法的难点在于你必须在每张图像中选择寻找哪些特征。随着你试图区分的类别数目开始增长,比如说超过 10 或 20,这就会变得非常麻烦甚至难以实现。你要寻找角点?边缘?还是纹理信息?不同类别的对象最好要用不同种类型的特征来描述。如果你选择使用很多的特征,你就不得不处理海量的参数,而且还需要自己来微调。
深度学习引入了「端到端学习」这一概念,(简而言之)让机器在每个特定类别的对象中学习寻找特征,即最具描述性、最突出的特征。换句话说,让神经网络去发现各种类型图像中的潜在模式。
因此,借助端到端学习,你不再需要手动决定采用哪种传统机器视觉技术来描述特征。机器为你做好了这一切。《连线》杂志如此写道:
举例来说,如果你想教会一个 [深度] 神经网络识别一只猫,你不必告诉它去寻找胡须、耳朵、毛或是眼睛。你只需展示给它成千上万的猫的图像,它自然会解决这一问题。如果它总是会将狐狸误认为是猫,你也不用重写代码。你只需对它继续进行训练。
下图描述了特征提取(使用传统计算机视觉)和端到端学习之间的这种区别:
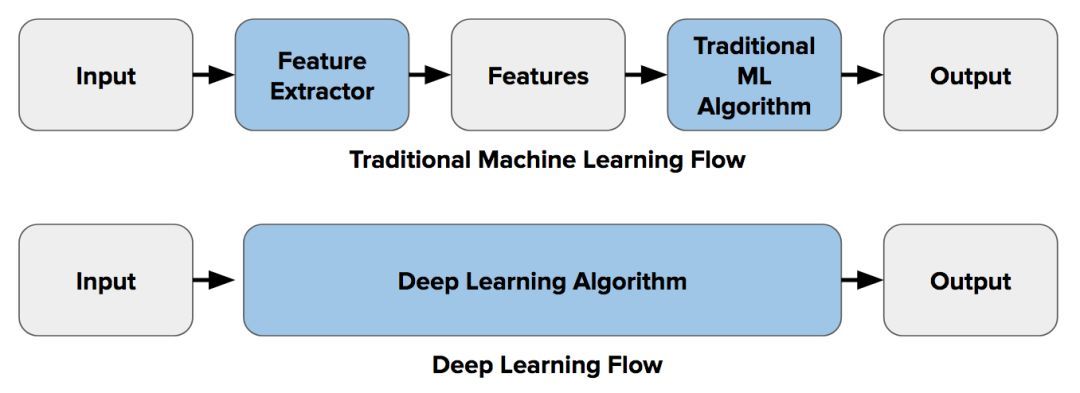
以上就是背景介绍。现在接着讨论为什么传统计算机视觉仍然必不可少,而且学习它仍大有裨益。
深度学习需要大量数据
首先,深度学习需要数据,许许多多的数据。前文提到过的著名图像分类模型的训练都基于庞大的数据集。排名前三的训练数据集分别是:
ImageNet——150 万图像,1000 个对象分类/类别;
COCO——250 万图像,91 个对象分类;
PASCAL VOC——50 万图像,20 个对象分类。
但是一个训练不良的模型在你的训练数据之外很可能表现糟糕,因为机器并没有对于问题的洞察力,也就不能在没看到数据的情况下进行概括归纳。而且对你来说查看训练模型内部并进行手动调整又太过困难,因为一个深度学习模型内部拥有数以百万计的参数——每个参数在训练期间都会被调整。某种程度上说,一个深度学习模型就是一个黑箱。
传统的计算机视觉完全透明,允许你更好地评估判断你的解决方案是否在训练环境之外依然有效。你对问题的深入见解可以放进你的算法之中。并且如果任何地方出现故障,你也可以更轻易地弄清楚什么需要调整,在哪里调整。
深度学习有时做过了头
这大概是我最喜欢的支持研究传统计算机视觉技术的理由。
训练一个深度神经网络需要很长的时间。你需要专门的硬件(例如高性能 GPU)训练最新、最先进的图像分类模型。你想在自己还不错的笔记本上训练?去度个一周的假吧,等你回来的时候训练很可能仍未完成。
此外,如果你的训练模型表现不佳呢?你不得不返回原点,用不同的训练参数重做全部工作。这一过程可能会重复数百次。
但有时候所有这些完全没必要。因为传统计算机视觉技术可以比深度学习更有效率地解决问题,而且使用的代码更少。例如,我曾经参与的一个项目是检查每个通过传送带的罐子里是否有一个红勺子。现在你可以通过前文叙述的旷日持久的过程来训练一个深度神经网络去检测勺子,或者你也可以写一个简单的以红色为阈值的算法(将任何带有一定范围红色的像素都标记为白色,所有其它的像素标记为黑色),然后计算有多少白色的像素。简简单单,一个小时就可以搞定!
掌握传统的计算机视觉技术可能会为你节省大量的时间并减少不必要的烦恼。
传统计算机视觉会提升你的深度学习技巧
理解传统的计算机视觉实际上能帮你在深度学习上做得更好。
举例来说,计算机视觉领域最为普遍使用的神经网络是卷积神经网络。但什么是卷积?卷积事实上是一种被广泛使用的图像处理技术(比如,索贝尔边缘检测)。了解这一点可以帮助你理解神经网络内部究竟发生了什么,从而进行设计和微调以更好地解决你的问题。
还有一件事叫做预处理。你输入给模型的数据往往要经过这种处理,以便为接下来的训练做准备。这些预处理步骤主要是通过传统的计算机视觉技术完成的。例如,如果你没有足够的训练数据,你可以进行一个叫做数据增强的处理。数据增强是指对你训练数据集中的图像进行随机的旋转、移动、裁剪等,从而创造出「新」图像。通过执行这些计算机视觉操作,可以极大地增加你的训练数据量。
结论
本文阐述了为什么深度学习还没有取代传统计算机视觉技术,以及后者仍值得学习和传授。首先,本文将目光放在了深度学习往往需要大量数据才能表现良好这一问题上。有时并不具备大量数据,而传统计算机视觉在这种情况下可作为一种替代方案。第二,深度学习针对特定的任务偶尔会做过头。在这些任务中,标准的计算机视觉比起深度学习可以更为高效地解决问题,并且使用更少的代码。第三,掌握传统计算机视觉确实可以让你在深度学习方面做得更好。这是因为你可以更好地理解深度学习的内部状况,并可执行预处理步骤改善深度学习结果。
总而言之,深度学习只是一种计算机视觉的工具,而不是包治百病的良药。不要因为流行就一味地使用它。传统的计算机视觉技术仍然可以大显身手,了解它们可以为你省去很多的时间和烦恼。
原文链接:
http://zbigatron.com/has-deep-learning-superseded-traditional-computer-vision-techniques/








